Измерение критически важно для понимания не только мира и вселенной, но и систем, которые мы проектируем и развертываем. Интернет не является исключением, однако проблемы измерения Интернета уникальны.
Интернет удивительно непрозрачен, что контринтуитивно, учитывая его открытую и многостороннюю модель. Он непрозрачен, потому что в конечном счете Интернет объединяет множество сетей и сервисов, каждый из которых принадлежит и управляется независимыми организациями, которые редко делятся информацией о своих системах или отчитываются о них. Каждая сеть может передавать и перенаправлять то, что производят другие системы, но каждая система полностью независима — что, если честно, и есть магия Интернета. Именно в этом непрозрачном, но критически важном контексте измерение Интернета должно существовать как научная практика со всей сопутствующей строгостью, повторяемостью и воспроизводимостью.
Измерение как научная практика может быть захватывающим — как из-за того, что оно делает правильно, так и из-за ошибок. Следующее утверждение отражает некоторые тонкости:
«5 из 6 ученых заявляют, что Русская рулетка безопасна.»
Утверждение абсурдно! Как бы мы ни смеялись, оно также логично. Очень легко спроектировать эксперимент, который приводит к вышеуказанному утверждению. Однако единственный способ, которым этот эксперимент мог бы увенчаться успехом, — если бы «исполнитель» — то есть тот, кто проводит эксперимент, — игнорировал бы каждый аспект науки об измерениях, который делает эту практику достоверной, как показано ниже.
-
Методология: цикл, состоящий из курации данных, моделирования и валидации. Здесь эксперимент (курация данных) мог бы преуспеть, только если бы каждому участнику мешали видеть травмы других. Что более важно, измерение не требуется, потому что исполнитель может рассчитать вероятности с помощью доступных чисел без эксперимента!
-
Этика: способ, которым мы измеряем, может иметь неоправданные, нежелательные последствия. Минимальный принцип — не навреди.
-
Репрезентативность: четкие и полные утверждения или визуализации должны быть как минимум информативными и в идеале — полезными для действий; в противном случае они могут вводить в заблуждение. Скажем, каждый участник ответил «да» на вопрос «вы в безопасности?». Они отвечают на другой вопрос, нежели «безопасна ли игра?»
В этом блоге мы рассмотрим каждый из вышеупомянутых аспектов измерения, опишем, как они проявляются в интернет-пространстве, и свяжем их с примерами из работы, которая будет представлена в течение недели. Давайте сначала начнем с некоторой предыстории.
Предисловие: Мотивирующий пример изнутри Cloudflare
Высококачественные измерения помогают выявлять, понимать и даже объяснять наш опыт, окружение и системы. Однако наблюдение в изоляции, без контекста, может быть опасно. Ниже представлен временной ряд из внутреннего графика HTTP-запросов из Львова, Украина, вплоть до вечера 28 февраля 2022 года:
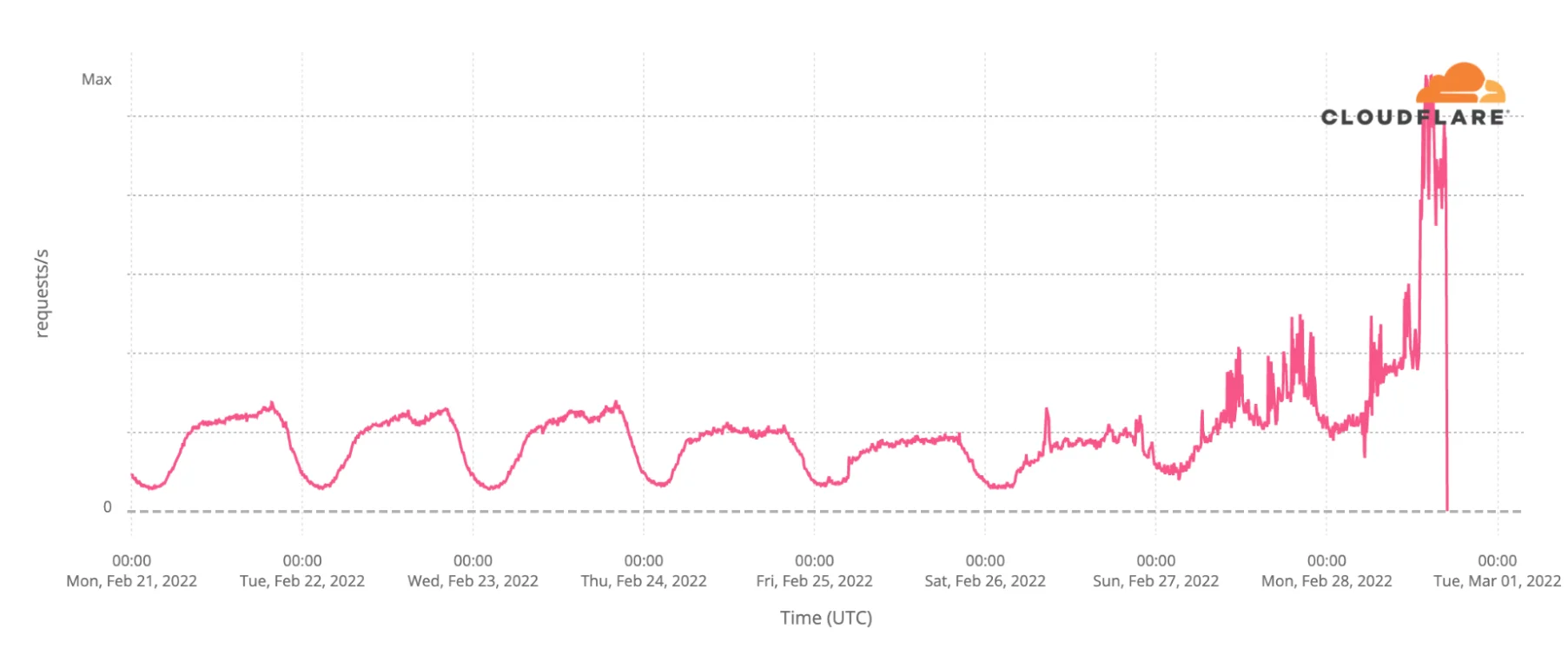
В тот день трафик из региона вырос в 3-4 раза. Для контекста: вторжение России в Украину началось четырьмя днями ранее. Мир пристально следил за событиями. Cloudflare не был исключением, помогая как отчитываться о сетевых эффектах, так и смягчать их.
Наблюдая этот аномальный всплеск, мы в Cloudflare могли бы ошибочно сообщить об увеличении как о потенциальной DoS-атаке. Однако были контр-признаки. Во-первых, системы защиты и смягчения DoS не зафиксировали атаку. Кроме того, профиль трафика был нетипичным для атаки, которая обычно исходит либо из одного источника в одном месте, либо из нескольких источников в нескольких местах. В данном случае увеличение произошло из нескольких исходных сетей, но в одном месте (Львов).
У Cloudflare были инструменты, чтобы избежать ошибочной отчетности, и позже мы правильно сообщили, что увеличение было вызвано массовым скоплением людей во Львове, городе с последним железнодорожным вокзалом на пути на запад из Украины. Но — и это важно в контексте измерений — ничто, видимое с точки зрения Cloudflare, не могло дать объяснение. В конечном счете, сотрудник увидел репортаж на BBC о массовом перемещении людей в той части Украины, что позволило нам лучше объяснить сдвиг в трафике.
Этот пример — важное напоминание всегда искать альтернативные объяснения. Он также показывает, как одни только наблюдения могут привести к неверным выводам из-за недостающей информации или непризнанных предубеждений. Но даже хорошие, непредвзятые данные могут быть неправильно поняты.
Словарь измерений и жаргон
В контексте измерений существует словарь общих слов с конкретными значениями, которые полезно знать, прежде чем погружаться в практику и примеры.
Активные и пассивные измерения
Они описывают «как». При активном измерении исполнитель инициирует некоторое действие, предназначенное для вызова ответа. Ответом могут быть данные, такие как задержка, возвращаемая пингом, или ответ DNS на запрос. Ответом может быть наблюдаемое изменение в механизме или системе, вызванное действием, например, специально сформированные пробные пакеты, которые провоцируют реакции и раскрывают промежуточные устройства (middleboxes).
При пассивном измерении исполнитель только наблюдает. Никаких действий не предпринимается. В результате ответ не вызывается; система и ее поведение остаются неизменными. Логи обычно составляются из пассивных наблюдений, и логи Cloudflare не являются исключением. Подавляющее большинство данных, показанных в Cloudflare Radar, получены из этих логов.
У каждого подхода есть свои компромиссы. Активные измерения целенаправленны и управляемы. Они также исключительно сложны (и часто дороги) для масштабирования и, как следствие, способны наблюдать только за теми частями системы, где они развернуты. И наоборот, пассивные измерения, как правило, более легковесны, но преуспевают только в том случае, если наблюдатель находится в нужном месте в нужное время.
По сути, эти два метода дополняют друг друга, и это делает их наиболее мощными при оркестровке, когда знания от одного подпитывают другой. Например, в наших собственных предыдущих попытках понять производительность CDN мы анализировали (пассивные) логи запросов, чтобы получить инсайты, что помогло проинформировать последующие (активные) пинги с использованием RIPE Atlas, которые мы использовали для подтверждения наших инсайтов и результатов. В обратном направлении наши усилия по (пассивному) обнаружению и пониманию сбоев соединения были основаны на большом массиве (активных) измерений в исследовательском сообществе для понимания масштабного вмешательства в соединения и, возможно, стали возможными только благодаря этому.
Чтобы узнать больше о взаимодействии активного и пассивного подходов, вы можете прочитать об опыте исследователя, который был подготовлен для глубокого погружения в обширные массивы данных Cloudflare благодаря инсайтам из предыдущих активных измерений в исследовательском сообществе.
Прямые и косвенные измерения
Можно получить представление о чем-то, не наблюдая это напрямую. Рассмотрим, например, пропускную способность пути, более известную как bandwidth (ширина полосы пропускания). Распространенный метод прямого наблюдения за пропускной способностью — запуск speed test (теста скорости). Это простой тест, но у него есть две проблемы.
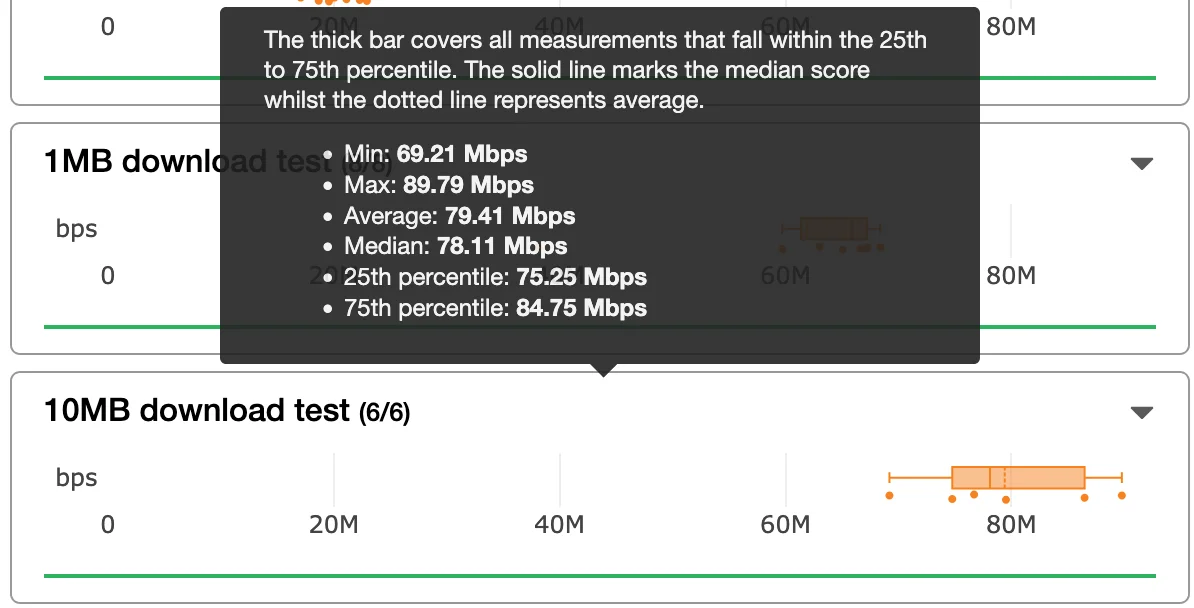
Первая заключается в том, что он работает, потребляя как можно больше пропускной способности (что создает этическую дилемму, к которой мы вернемся позже). Вторая заключается в том, что он фактически измеряет пропускную способность (throughput) от отправителя к получателю, которая является доступной пропускной способностью (или, альтернативно, остаточной емкостью) узкого места (bottleneck link). Если два теста скорости используют одно узкое место, то каждый может наблюдать пропускную способность, составляющую ½ от фактической. Доказательство — в цифрах, как видно ниже, где наблюдения за тестом скорости варьируются от 69 до 85 Мбит/с — это диапазон +/- почти 20% от медианы, и далеко не фиксированное значение!
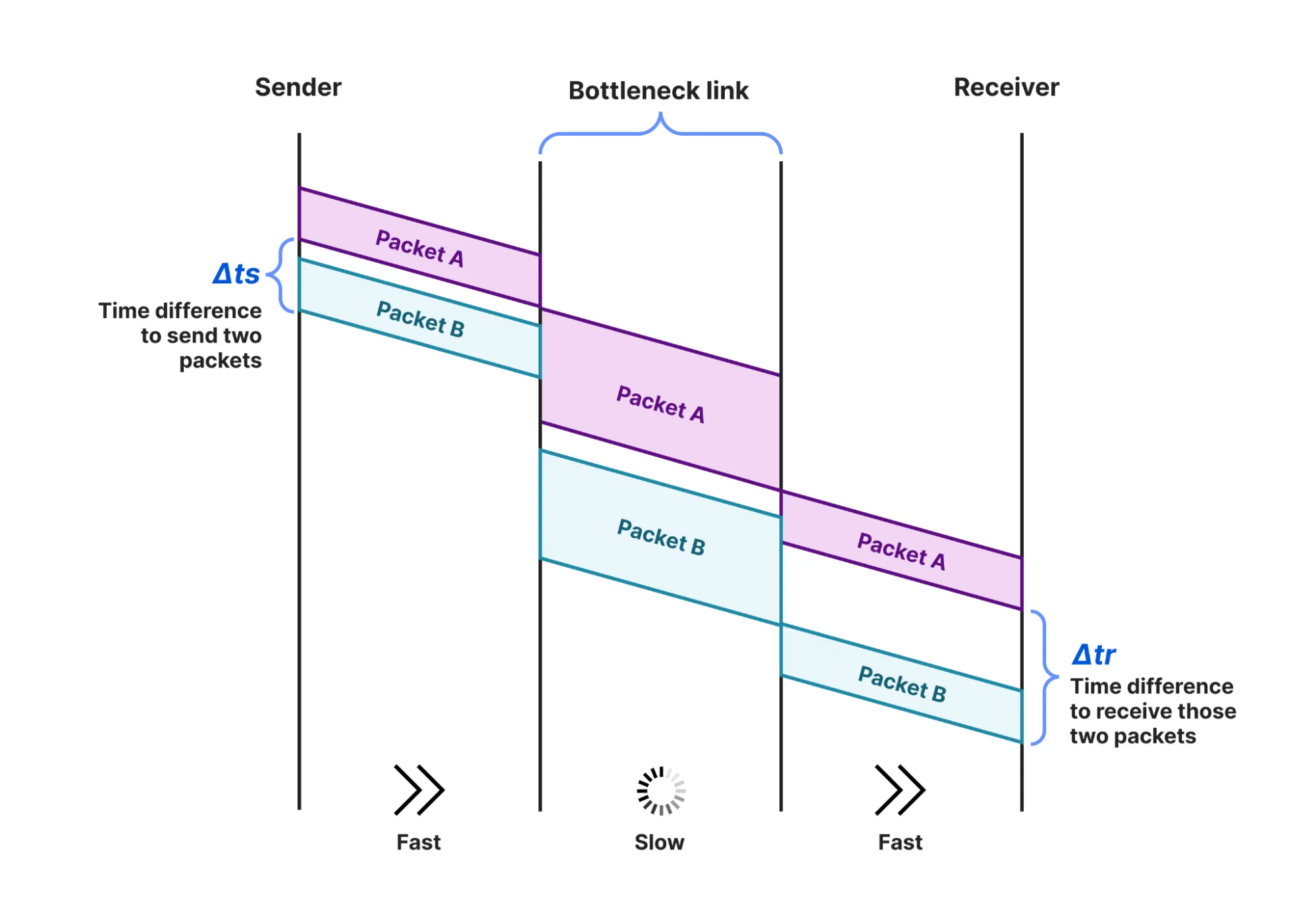
Вместо этого существует альтернатива тестам скорости — косвенный метод возрастом более 25 лет, называемый packet pair (пакетная пара) или packet train (пакетный поезд). Он работает путем первоначальной передачи пар пакетов без задержки между ними и записи времени их передачи, а затем записи времени их прибытия. Изменение между временем передачи и прибытия двух пакетов дает указание на пропускную способность узкого места. Повторите зондирование пакетными парами и, с помощью некоторого статистического анализа, появляется хорошая оценка истинной пропускной способности узкого места. Вместо того чтобы напрямую наблюдать пропускную способность, проталкивая и подсчитывая байты во времени, техника пакетной пары использует время между двумя пакетами, чтобы косвенно рассчитать — или вывести — метрику.
Жизненный цикл (сетевых) измерений
Измерения наиболее эффективны, когда они приводят к разумным прогнозам. Иногда прогнозы подтверждают наше понимание мира и систем, которые мы в него внедряем. В других случаях прогнозы раскрывают что-то новое. В любом случае, прогнозные измерения возникают при следовании простой схеме: курирование данных, построение модели на основе данных, затем валидация модели (в идеале) другими данными. Вместе это создает жизненный цикл измерений.

В идеале процесс измерения охватывает весь жизненный цикл от начала до конца, но крайне ценные вклады и достижения могут быть сделаны и в рамках каждого этапа по отдельности. Отдельные высококачественные наборы данных настолько сложно курировать, что каждый из них может быть самостоятельным вкладом. То же самое относится к методам моделирования или инструментам валидации. Измерения охватывают экспертные области и выигрывают от разнообразных наборов навыков.
Давайте рассмотрим каждый шаг по порядку, начиная с курирования данных.
Курирование данных
Наиболее распространенная и знакомая практика измерений — часто синонимичная самим измерениям — это сбор и курирование данных. Данные сами по себе могут быть увлекательными и полезными; Cloudflare Radar является ярким тому доказательством! Простой подсчет во многих контекстах помогает нам понять наши среды и поместить их в контекст.
Сбор и курирование данных потребляют больше энергии, времени и ресурсов, чем моделирование или валидация. Объяснение подразумевается циклической схемой измерений: валидация требует предшествующей модели, а модели строятся с использованием данных. Нет данных — нет модели, нет валидации, нет инсайтов, прогнозов или обучения. Качество каждого шага в цикле зависит от качества предыдущего шага — высококачественные данные являются краеугольным камнем в практике измерений. Большой адронный коллайдер и Космический телескоп Джеймса Уэбба — прекрасные примеры того, сколько мы можем и должны делать — они работают неуклонно в pursuit высококачественных данных. Подобные «всегда включенные» инструменты в сообществе интернет-измерений гораздо менее гламурны, но не менее важны. CAIDA и RIPE Atlas — всего лишь два примера давно существующих проектов, которые собирают телеметрию и курируют наборы данных.
Не обманывайтесь: Сбор и курирование высококачественных данных — это сложно.
К счастью, «высококачественные» не означает идеальные; это означает репрезентативные. Например, если мы измеряем расстояние или время, точность должна отражать истинное значение. Большие популяции можно разумно изучать, используя гораздо меньшее количество образцов. Например, наша глобальная оценка вмешательства в соединения выявила ценные инсайты с выборкой 1 из 10 000 (или 0,0001%). Низкая частота дискретизации работает в Cloudflare отчасти благодаря огромному разнообразию клиентов Cloudflare, что привлекает трафик для всех видов контента и целей. Позже на этой неделе мы расскажем в блог-посте, как неидеальные сигналы, используемые для нахождения выборки около 180 000 carrier-grade NAT в логах запросов Cloudflare, «достаточно хороши», чтобы идентифицировать более 12 000 000 других, которые нельзя наблюдать напрямую.
Другое важное и, возможно, контринтуитивное заблуждение заключается в том, что больше данных естественным образом раскрывает больше деталей и ответов на больше вопросов. Как пишет Рам Сундаран в гостевом посте, иногда шума так много, что нахождение ответов в больших наборах данных может казаться маленьким чудом.
Моделирование
Модели могут быть концептуальными и описывать аспекты среды или системы. Наиболее полезные могут быть выражены в виде простых утверждений о нашем понимании или наших предположениях. По сути, они инкапсулируют гипотезу, которую можно проверить. Например, мы можем полагать или предполагать, что интернет-провайдер или сеть обычно предпочтет прямой бесплатный пиринговый путь к CDN, а не транзитные сетевые пути, которые влекут затраты, даже если прямой путь длиннее. Это формирует модель, которую можно проверить.

Прогнозные модели выходят за границы нашего понимания, чтобы помочь идентифицировать, объяснить или понять аспекты систем, которые не очевидны, не наблюдаемы напрямую или их трудно определить. Прогнозные модели часто используют статистические методы, чтобы, например, идентифицировать лежащие в основе стохастические процессы или создавать классификаторы машинного обучения. Более распространенное использование статистических инструментов — это характеристика самих курированных данных. Удивительно мощные модели могут быть простыми распределениями вероятностей со средними значениями, медианами, дисперсией и показателями достоверности.
Один аспект Интернета, который привлек много внимания, — это то, как сети в Интернете выбирают подключение к другим сетям. Понимание того, как формируется и растет Интернет, важно для моделирования, но также помогает предсказать способы, которыми сети могут выходить из строя. Уравнение слева ниже взято из модели Барабаши-Альберта (B-A), ранней модели, которая предполагает преференциальное соединение или, более привычными словами, «богатые становятся богаче».
В своей простейшей версии новая сеть в модели BA выбирает подключение к существующей сети с вероятностью, пропорциональной количеству соединений существующих сетей. Более поздние модели отказались от «интеллектуальных» механизмов выбора. Уравнение справа ниже основано на размерах сетей, более общем механизме, аналогичном тому, как формируются небесные тела во Вселенной.

Иногда знание того, какой инструмент использовать и когда, само по себе является навыком. Один из таких примеров — применение ML и AI к проблемам, которые решаются более простыми и прозрачными механизмами. Этот гостевой блог, например, объясняет, что ML был исключен для понимания аномального поведения TCP, потому что TCP строго специфицирован, что предполагало возможность полного перечисления различных последовательностей пакетов — и это подтвердилось.
Понимание предметной области часто критически важно для нашей способности строить точные модели. Машинное обучение, например, — полезный инструмент для осмысления больших неструктурированных данных, но может быть удивительно мощным при наличии некоторой экспертизы в предметной области. Наша работа, представленная позже на этой неделе по обнаружению мультипользовательских IP-адресов, предоставляет один такой пример. В частности, мы стремились обнаружить устройства carrier-grade NAT (CGNAT). Они уникальны среди крупномасштабных мультипользовательских IP-адресов, потому что, в отличие от VPN и прокси, пользователи не выбирают использование CGNAT и не осознают их существование.
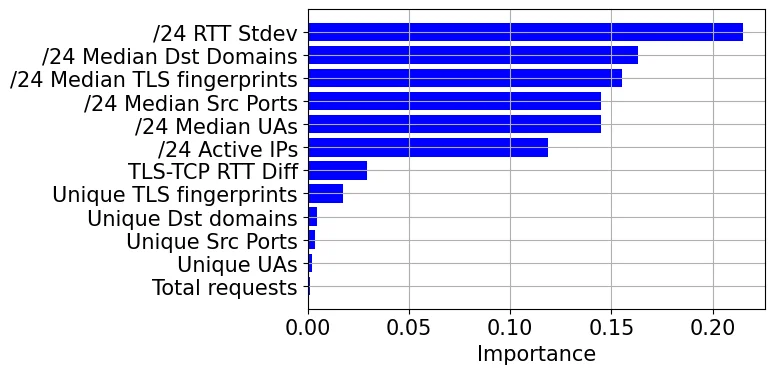
Модели ML успешно идентифицировали мультипользовательские IP-адреса, но различение CGNAT оказалось трудным, пока мы не применили знания предметной области. Например, CGNAT обычно развертываются в диапазоне смежных IP-адресов (например, в блоке /24) и, как показано ниже, оказались очень важным признаком в модели.
Валидация
Фаза валидации почти единолично определяет ценность всего процесса измерения, проверяя выходные данные модели на соответствие данным. Если модель делает прогнозы, которые отражаются в данных, то модель имеет валидность. Прогнозы, которые противоречат или конфликтуют с данными валидации, указывают на то, что либо модель ошибочна, либо смещена курированными данными.
Валидация — это то место, где отличное измерение может развалиться — в основном одним из двух способов. Во-первых, так же, как на начальной фазе курирования данных, данные для валидации должны быть репрезентативными для популяции. Например, было бы ошибкой курировать данные о трафике в дневное время, построить модель на основе этих данных, а затем провести валидацию, используя данные о ночном трафике. Также нет смысла использовать данные QUIC для валидации измерений, скажем, TCP (если только гипотеза измерения не состоит в том, что у них есть общие атрибуты). Всегда необходимо следить за тем, чтобы измерение не могло быть искажено различиями между данными валидации и исходными данными.
Валидация также рискует ввести в заблуждение при использовании самих курированных данных напрямую. Безусловно, этот подход смягчает различия между наборами данных. Однако единственный вывод, который можно сделать при валидации на тех же данных, — это то, что модель разумно описывает данные, а не то, что эти данные представляют. Рассмотрим, например, машинное обучение. В своей основе машинное обучение — это измерение, поскольку оно следует жизненному циклу: курировать данные, (подать их в алгоритм машинного обучения для) построения модели, затем проверить выходные данные на соответствие данным. Ранней распространенной практикой в сообществе машинного обучения было разделение одного набора данных на 70% для обучения и 30% для валидации. Это настройка, которая приводит к более высокой вероятности положительной оценки модели, которая не оправдана и потенциально вводит в заблуждение. Лучший случай для модели ML, обученной на наборе данных, который усиливает или опускает важные характеристики, — это модель, отражающая эти смещения, что становится потенциальным источником алгоритмического смещения.
Естественно, мы больше доверяем моделям, которые подтверждают свою валидность на независимых данных. Набор данных для валидации может описывать те же атрибуты из другого источника, например, модели, построенные на основе пассивных данных журналов RTT и проверенные по активным пингам. Альтернативно, модели могут проверяться с использованием совершенно других данных или сигналов, таких как подтверждение вмешательства в соединение с помощью распределений и значений заголовков, которые игнорировались при построении модели.
Этика сетевых измерений
Важность этики в сетевых измерениях трудно переоценить. Легко воспринимать сетевые измерения как безрисковые, удаленные от людей и мало на них влияющие — восприятие, далекое от истины. Вспомните тесты скорости и технику пар пакетов для оценки пропускной способности, описанные выше. В тесте скорости участник оценивает пропускную способность, потребляя всю доступную емкость узкого места, которая может находиться или не находиться в его собственной сети. Стоимость потребления ресурсов может лечь на других и, безусловно, снижает потенциальную производительность сети для ее пользователей. Риски такого типа измерения пропускной способности побудили к разработке техники пар пакетов, которая использует всего несколько пар пакетов и немного математики для вывода пропускной способности — правда, с некоторой координацией между отправителем и получателем.
Передовые практики в сетевых измерениях требуют тщательного анализа рисков и последствий до проведения измерений. Это может показаться обременительным, но этические соображения часто стимулируют творчество и являются причиной появления новых методик. Поиск альтернатив внедрению JavaScript — вот что побудило собственные усилия Cloudflare по оценке производительности других CDN с использованием пассивных данных. Для получения дополнительной информации см. «Этические соображения в статьях о сетевых измерениях», опубликованные в Communications of the ACM (2016).
Визуализация и представление данных
Визуализация и представление данных бесценны на каждом этапе жизненного цикла измерений. Представления должны, как минимум, улучшать наше понимание; в идеале они также делают последующие действия понятными. Утверждения без контекста — это плохие представления. Например, «на 30% больше шансов» звучит значительно, но не имеет ценности без точки отсчета — 30% от 0,5% вероятно вызывают меньше беспокойства, чем 30% от 20%.
Одним из примеров представления является заявление Cloudflare о «близости»: Cloudflare находится «примерно в 50 мс от 95% интернет-населения мира». Это утверждение encapsulates «опрос» наших логов: среди всех соединений с каждого IP-адреса, подключающегося к Cloudflare, половина минимального RTT является «худшим приближением» задержки от IP-адреса до Cloudflare; в 95% случаев minRTT/2 составляет 50 мс или меньше.
Между тем, визуализации могут быть настолько мощными, что приводят к вводящим в заблуждение выводам — эта концепция будет prominently featured позже на этой неделе в записи блога об оценках устойчивости маршрутизации. Один пример на эту тему приведен ниже, с двумя гистограммами, которые упорядочивают отдельные штаты США по количеству узлов взаимосвязи в каждом штате, от наибольшего к наименьшему. Слева штаты упорядочены по исходному количеству узлов; штат на первом месте имеет более 140 узлов взаимосвязи. Справа исходные количества нормализованы (в данном случае поделены на) население каждого штата.
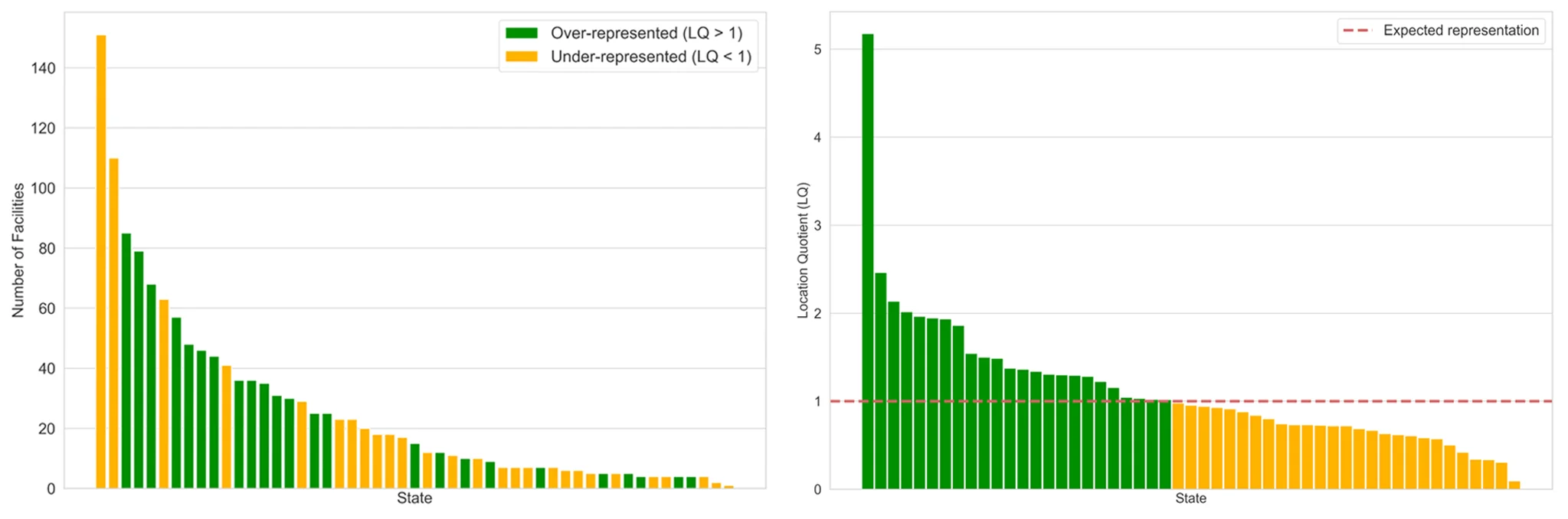
Эти представления демонстрируют, что наши модели формируются и могут быть дезинформированы тем, как мы оцениваем данные. В данном случае мы намеренно опустили названия штатов на оси X, потому что они отвлекают. Вместо этого каждый столбец окрашен, чтобы показать, находится ли он выше (зеленый) или ниже (желтый) медианного значения количества узлов на человека на правом графике. Что сразу становится очевидным, так это то, что два штата с наибольшим количеством узлов оказываются ниже медианы, т.е. они находятся в нижней половине штатов при упорядочивании по количеству узлов на человека.
Иногда визуализация может быть настолько мощной, что не оставляет сомнений. Изображение ниже — мой личный фаворит, потому что оно дает веские доказательства того, что данные и модели были правильными. В этой визуализации каждый столбец представляет один тип аномалии соединения, который мы наблюдали. Внутри каждого столбца вхождения аномалии пропорционально разделены по стране, из которой было инициировано соединение. В качестве примера посмотрите на крайний левый столбец для аномалий SYN→∅ (тип таймаута). Он показывает, что соединения из Китая, Индии, Ирана и Соединенных Штатов доминировали в этом конкретном типе аномалий. Организация визуализации таким образом ставила данные на первое место, что помогло смягчить любые предубеждения, которые у нас могли быть относительно объяснений, основных механизмов или местоположений.
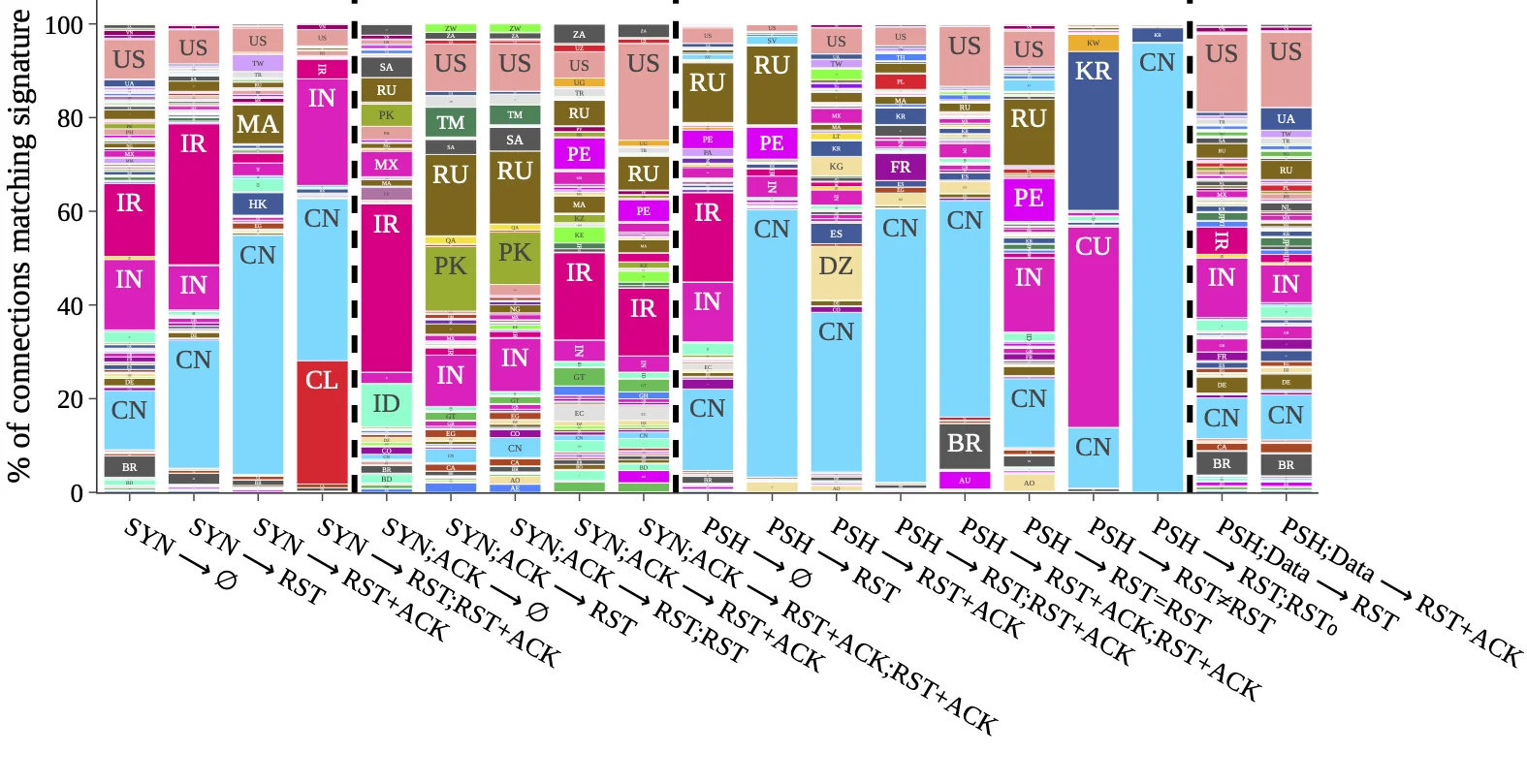
Упорядочивая аномалии таким образом, визуализация немедленно ответила на один вопрос: «Являются ли сбои ожидаемым поведением?» Если бы они были ожидаемыми или нормальными для Интернета в целом, то аномалии появлялись бы в примерно схожих пропорциях, а не столь различающихся. Визуализация стала сильной валидацией (но не единственной) нашего подхода и интуиции — и в результате открыла новые пути для исследований.
Что дальше?
Cloudflare продолжает глубоко размышлять о новых и инновационных способах использования доступных (пассивных) данных и приветствует идеи. Измерения помогают нам понять Интернет, от которого мы все зависим, который ценим и любим, и это общеотраслевое endeavor.