Cloudflare недавно объявила о нашей цели нанять 1111 стажеров в 2026 году — это эквивалентно примерно 25% нашей штатной рабочей силы. Это означает бесчисленные возможности для разработки и внедрения рабочего кода в продакшен. Это также создает новые возможности для измерения аспектов Интернета, которые в противном случае трудно наблюдать — и еще сложнее понять.
Измерения — это сложно, даже в Cloudflare, несмотря на огромный объем данных, генерируемых нашим трафиком (большая часть которого публикуется через Cloudflare Radar). Распространенное заблуждение, которое мы часто слышим: «У Cloudflare так много данных, что у них должны быть все ответы». Наличие огромного количества данных — это прекрасно, но это также означает гораздо больше шума для фильтрации и много дополнительной работы, чтобы исключить альтернативные объяснения.
Рам Сундара Раман был стажером в Cloudflare в 2022 году, когда получал степень PhD. Сейчас он доцент в Калифорнийском университете в Санта-Круз, и мы пригласили его обратно, чтобы он поделился своими инсайтами о работе с данными в Cloudflare.
Проект Рама — отличный пример того, как инсайты, которые исследователи принесли из своего университетского исследовательского центра, могут заложить основу для ценного проекта в Cloudflare — в данном случае, обнаружения и объяснения сбоев подключения у клиентов. Один совет для потенциальных стажеров: если вы подаете заявку и думаете об идеях работы с данными и измерениями в Cloudflare, хороший вопрос для размышления — имеет ли, как или почему ваша идея значение для Cloudflare. Мы любим слушать ваши идеи!
Без дальнейших церемоний, представляем Рама. Мы надеемся, что его инсайты будут такими же информативными и освежающими для будущих стажеров — и практиков — как и для нас здесь, в Cloudflare.
Инсайты из данных в крупном масштабе могут быть просто маленьким чудом
от Рама Сундара Рамана, доцента компьютерных наук и инженерии, UC Santa Cruz
До прихода в Cloudflare в качестве исследовательского стажера летом 2022 года я работал над множеством проблем исследования сетевой безопасности и конфиденциальности как аспирант в Мичиганском университете. Мой предыдущий опыт включал активные измерения, в которых тщательно созданные зонды передавались для обнаружения и количественной оценки проблем безопасности, таких как перехват HTTPS и подмена соединений. Эти атаки, выполняемые мощными сетевыми промежуточными устройствами между пользователями и интернет-серверами, могут блокировать интернет-контент и услуги для многочисленных пользователей в различных регионах, а также снижать их безопасность. Например, атака "человек посередине" при перехвате HTTPS в Казахстане в 2019 году была обнаружена в 7-24% всех измерений, которые мы провели в стране.
Обнаружение таких атак является сложной задачей. Основные механизмы разнообразны, с географическими и временными вариациями — и они полностью непрозрачны. Более того, в Интернете нет технических механизмов для сообщения пользователям, когда их трафик манипулируется, а третьи стороны редко, если вообще когда-либо, прозрачны с пострадавшими пользователями.
Моя работа по активным измерениям до Cloudflare помогла решить эти проблемы. Вместе с моим научным руководителем и командой в Мичиганском университете я помог разработать Censored Planet, одну из крупнейших обсерваторий активного интернет-цензуры, обнаруживающую подмену соединений в более чем 200 странах. Однако активные измерения сталкиваются с барьерами масштаба, ресурсов и реального взгляда. Например, Censored Planet может измерять блокировку и подмену соединений только для 2000 самых популярных веб-сайтов просто из-за ограничений по времени и ресурсам.
Работая над такими проектами, как Censored Planet, я часто смотрел на крупных сетевых операторов или облачных провайдеров и думал: «Если бы у меня были данные, которые они собирают, я мог бы решить эту проблему так легко. У них глобальный взгляд на реальный трафик почти из каждой сети, и, вероятно, достаточно ресурсов и телеметрии для масштабирования анализа до такого уровня данных. Насколько сложно может быть использовать эти данные, например, для обнаружения, когда промежуточные устройства вмешиваются?»
Как мы узнали из нашего исследования, опубликованного на ACM SIGCOMM'23 — это может быть очень сложно.
Мои взгляды на цензуру эволюционировали как прямой результат моего опыта в Cloudflare, который научил меня, что обнаружение в масштабе сложно, даже с данными крупного масштаба. Исследование, которое я провел во время стажировки, помогло выявить, что сетевые промежуточные устройства блокируют или иным образом вмешиваются в определенные соединения не только в ограниченных местах, но и в различных масштабах по всему миру.
Проект стажировки, построенный на реальных инсайтах с использованием продакшен-данных
В этом исследовании мы опирались на инсайты, собранные более широким сообществом активных измерений, а именно на то, что промежуточные устройства вмешиваются в TCP-соединения Интернета, отбрасывая пакеты или внедряя RST-пакеты, чтобы вызвать прерывание соединений. Те же инсайты показали, что паттерны отбрасывания пакетов и RST детерминированы — и, как результат, потенциально обнаруживаемы. Такова гибкость активных измерений: создайте пользовательский запрос или «зонд», который вызывает ответ от окружения. Однако такой целевой подход было бы сложно масштабировать и поддерживать, даже для Cloudflare: Какие зонды следует создавать? Куда их следует отправлять? Какую мотивацию имел бы Cloudflare даже пытаться, если риск пропустить так много так высок?
Целью моей стажировки было посмотреть, можем ли мы вместо этого перевернуть подход: быть пассивным вместо активного. Все, что делает Cloudflare, должно быть как масштабируемым, так и устойчивым. Однако было совершенно неясно, можно ли построить систему, ограниченную пассивным наблюдением, даже если события подмены можно обнаружить. Требование было ясным: наблюдать и использовать только данные, которые приходят в Cloudflare естественным образом. Никакого смешивания с другими наборами данных, никаких запусков наших собственных активных измерений. Любое из этого сделало бы жизнь проще: мы могли бы контролировать переменные, возможно, даже получить объективную истину, которая помогла бы нам подтвердить наши наблюдения. Но где же здесь веселье? Кроме того, у Cloudflare есть все данные в любом случае... верно?
Да, возможно — если они соответствующим образом выборны, могут быть надежно извлечены и правильно интерпретированы.
Вот полезный инсайт: я часто слышал, как люди говорят, что поиск промежуточных устройств, которые подменяют интернет-соединения с помощью активных измерений, похож на поиск иголки в стоге сена — редкий, капризный и трудно закрепляемый. Когда мы начали смотреть на эту проблему через призму пассивного набора данных Cloudflare, мы быстро осознали, что все еще ищем ту же иголку — и в некотором смысле, теперь ее стало еще сложнее найти.
Это потому, что как пассивные наблюдатели мы теряем способность выбирать, где искать. Также, стог сена теперь простирается через континенты, миллионы пользователей и — я не преувеличиваю — тысячи способов, как соединения могут устанавливаться и разрываться. Нам не только пришлось идентифицировать подмену из миллионов точек реальных данных, но и делать это с данными, полными препятствий и ловушек. Это было похоже на работу с невидимыми ловушками и их спусковыми механизмами.
Ловушки и спусковые механизмы крупномасштабных пассивных данных
Было несколько проблем, которые я по-настоящему понял только столкнувшись с ними. Начнем с очевидной: масштаб.
Во-первых, был избыток крупномасштабных наборов данных, в основном связанных с входящими соединениями в Cloudflare. Например, на время моей стажировки Cloudflare обслуживала более 45 миллионов HTTP-запросов в секунду по всему миру, в более чем 285 центрах обработки данных. Cloudflare также получает TCP-соединения на свой DNS-сервер 1.1.1.1. Мы также исследовали данные Network Error Logging (NEL). Обычно в исследовании измерений мы имеем дело с проблемой слишком малого масштаба. Здесь у нас была обратная проблема: слишком много хорошего. На практике каждый из этих наборов данных имел свои собственные независимые методы выборки, что делало практически невозможным их совместное использование. Более того, наборы данных, такие как NEL, смещены, поскольку только некоторые клиенты поддерживают его, и только некоторые веб-сайты включают его. После оценки этих смещений NEL не прошел в финальный отбор.
Для управления масштабом мы создали специальные правила IPTABLES для логирования и хранения входящих TCP-соединений во всех точках присутствия Cloudflare — на каждом сервере в каждом из 285 дата-центров. Однако из-за чрезвычайно большого масштаба данных нам пришлось ограничиться работой с равномерно случайной выборкой одного из каждых 10 000 соединений. Для каждой выборки мы логировали только первые 10 входящих пакетов каждого соединения. Это означало, что мы не могли обнаружить определенные редкие типы подмены или любую подмену, происходящую позже в потоке, после первых 10 пакетов.
Тем не менее, в этих ограничениях нам удалось разработать сигнатуры подмены — отличительные паттерны пакетов, которые раскрывают, когда промежуточные устройства вмешиваются. Однако разработка этих сигнатур была чем угодно, но не простой, из-за второго спускового механизма: зашумленные данные.
Трудно представить, что мы могли бы предвидеть все различные источники шума. Например, разрешение хронометража в записях событий составляло миллисекунды, но множество пакетов могло прибывать за одну миллисекунду, что означало, что мы не могли доверять порядку регистрации пакетов. В конечном итоге мы узнали, что некоторый трафик атак типа «отказ в обслуживании», а также сканирование портов могут до жути походить на события вмешательства, а определённые «лучшие практики», разработанные для улучшения Интернета, такие как Happy Eyeballs, превратились в особенности, которые мешали нашему обнаружению. Мы потратили много времени на анализ этих источников шума и итерации наших сигнатур, чтобы понять их. Мы принимали события за вмешательство только в том случае, если они подтверждались другими источниками доказательств, которые мы определили, включая, но не ограничиваясь, непоследовательными изменениями в поле Time-To-Live (TTL) IP-заголовка.
Это подводит меня к нашей последней ловушке: отсутствию достоверных данных.
Без активных, контролируемых экспериментов нам было бы чрезвычайно сложно подтвердить, когда то, что мы обнаружили, действительно было вмешательством, а не одним из тысячи других явлений в Интернете. К счастью, благодаря удивительной работе многих исследователей в области измерения цензуры, мы смогли распознать по крайней мере некоторые известные сигналы и паттерны в данных, и они помогли нам подтвердить многие случаи вмешательства.
Было гораздо больше ловушек. Но ключевым осознанием для меня стало следующее: хотя у провайдеров много данных, которые могут рассказать вам о вещах, невероятно сложно понять, о какой именно вещи, в каком количестве и о чём именно. Крупные операторы инфраструктуры видят отфильтрованное, выборочное и часто частичное представление об Интернете. Например,
-
Такие сервисы, как Cloudflare, могут видеть только то, какие соединения были затронуты и откуда они были инициированы, но не кто совершил вмешательство;
-
Иногда было возможно понять, какие домены были заблокированы, но не всегда, потому что необходимые пакеты могут быть отброшены до того, как попадут в Cloudflare;
-
Как пассивный наблюдатель, можно видеть только активность пользователей, которая была затронута, а не то, что могло быть затронуто.
Для компании, которая обрабатывает двузначный процент веб-сайтов и сервисов Интернета, это были удивительные — но понятные — ограничения. Может показаться, что эта задача невозможна, но это не так. Она просто сложнее, чем я ожидал. Несмотря ни на что, мы нашли способы извлечь смысл из хаоса. Например, мы тщательно и кропотливо перечислили все распространённые последовательности пакетов, наблюдаемые Cloudflare, и выделили из них те, которые могут указывать на вмешательство, на основе предыдущих работ. Более того, мы использовали такие сигналы, как поле TTL, упомянутое выше, в качестве подтверждающих доказательств того, что эти сигнатуры пакетов действительно показывают вмешательство.
Всё это складывается в простой, но важный вывод: крупные инфраструктурные провайдеры не всеведущи. Глобальный обзор может быть мощным, но он не автоматически превращается в лёгкие наблюдения. Вы можете иметь все данные мира и всё равно с трудом отличать промежуточный узел (middlebox), фильтр безопасности, сбитое с толку устройство IoT и даже обычных пользователей, закрывающих вкладки и браузеры.
Но эта дихотомия также является красотой этой проблемной области. Работа с неидеальными данными заставляет нас быть креативными, находить паттерны в шуме и разрабатывать методы, которые работают, несмотря на недостающее. И нет, прежде чем вы спросите, вы не можете просто применить машинное обучение к этой проблеме, да и не нужно — даже со всем шумом протоколы чётко специфицированы, что означает, что паттерны можно легко перечислить, но их всё равно нужно обсуждать вручную.
Проект стажировки, построенный на реальных инсайтах с использованием рабочих данных
Используя наши пакетные выборки и 19 сигнатур вмешательства, мы наблюдали характерное поведение вмешательства в сотнях сетей, включая возможность отслеживать большие всплески уровней вмешательства (Рисунок 1). И это сработало, потому что, несмотря на ограниченность данных, сети Cloudflare позволили нам увидеть реальные эффекты вмешательства. Кроме того, благодаря неустанным усилиям Люка Валенты и команды Cloudflare Radar, данные нашего проекта постоянно публикуются на Cloudflare Radar (Рисунок 2).
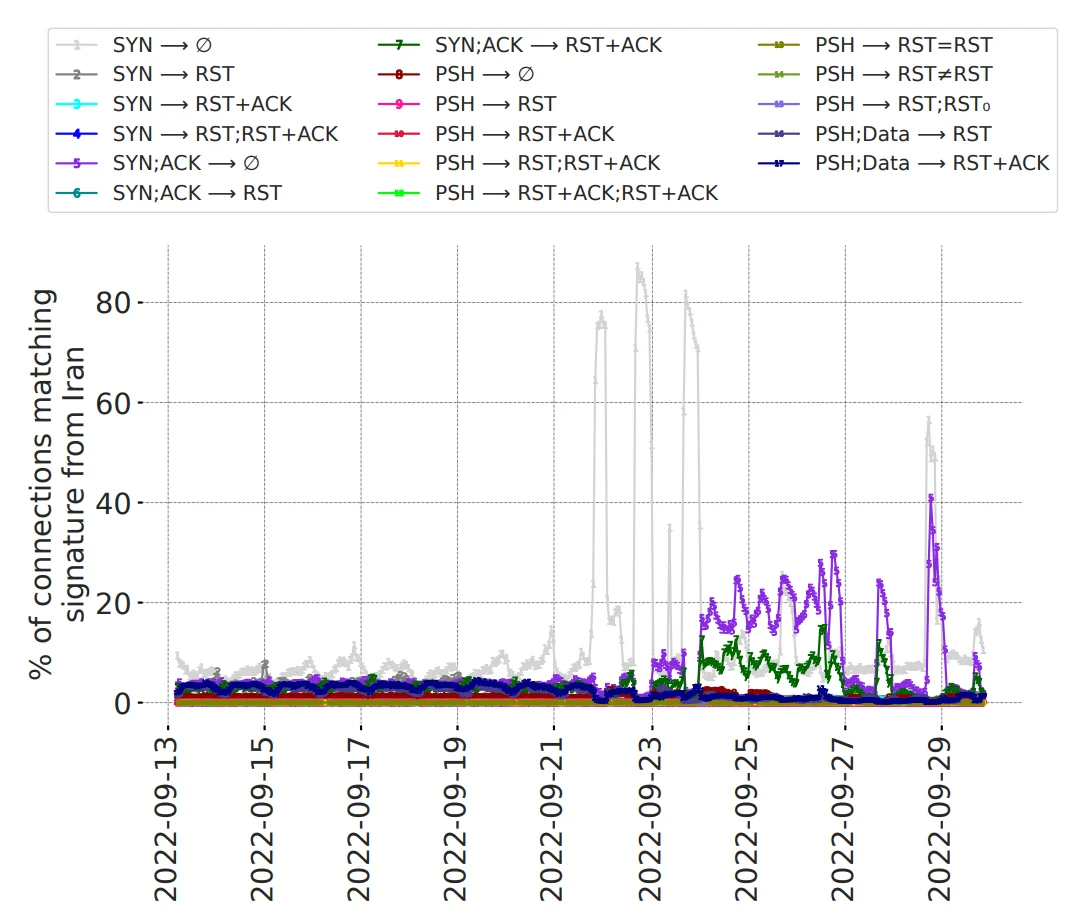
Рисунок 1: Рост частоты срабатывания наших 19 сигнатур вмешательства в период общенациональных протестов в Иране в конце 2022 года.
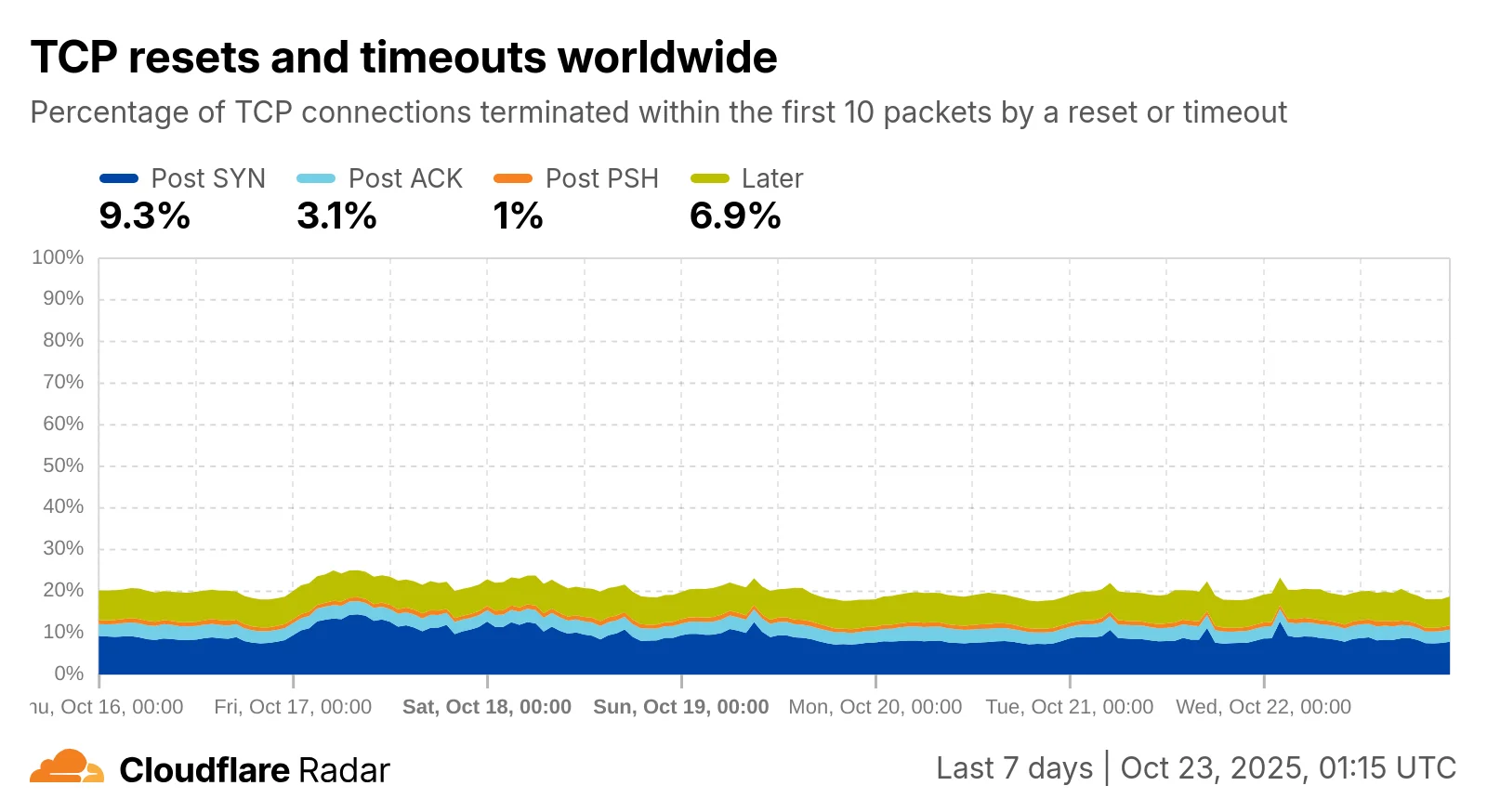
Рисунок 2: Данные нашего исследования вмешательства в соединения доступны в реальном времени на Radar.
В будущем, однако, я считаю, что решение подобных задач потребует комбинации пассивного зондирования и активных проб, использования масштаба провайдеров, подобных Cloudflare, вместе с целевыми, контролируемыми измерениями, чтобы нарисовать полную картину вмешательства в Интернете. Моя команда в RANDLab Калифорнийского университета в Санта-Крузе (UCSC) и исследовательская группа Censored Planet продолжают работать над этой проблемой, в частности, задаваясь вопросом, как мы можем автоматически идентифицировать вмешательство, когда происходят атаки или меняются сети.