Сервис Images, написанный на Rust и работающий на Workers, запущен на каждой машине в периферийной сети Cloudflare. Для обработки клиентских соединений мы используем hyper — открытую HTTP-библиотеку для Rust.
В прошлом году мы представили привязку Images, которая позволяет создавать собственные программные рабочие процессы для обработки удаленных изображений в Workers. В конце 2025 года мы переработали архитектуру привязки, чтобы обеспечить более прямое и локальное соединение между средой выполнения Workers и сервисом Images.
Вскоре после внедрения мы получили сообщения о том, что запросы на преобразование через привязку завершаются с ошибкой — но только периодически и только для больших изображений. Что еще более странно, ответы на эти запросы возвращали статус 200 без каких-либо ошибок в логах. Данные изображения просто обрезались: ответ, который должен был быть размером два мегабайта, приходил размером в несколько сотен килобайт.
Мы потратили шесть недель на поиск практически невидимой ошибки — состояния гонки, возникающего только при определенных условиях — в библиотеке hyper, которая влияла на то, как привязка Images возвращает обработанные данные изображения клиенту. В итоге для исправления потребовалось четыре строки кода.
Прыжки, передачи и hyper
Когда разработчики создают приложения на Cloudflare, они составляют полнофункциональные приложения из набора платформенных сервисов, доступных Workers через привязки. Привязки предоставляют прямые API-интерфейсы к ресурсам Платформы разработчика, таким как вычисления, хранение, AI-инференс и обработка медиа.
Привязка Images отделяет оптимизацию изображений от доставки; вы можете транскодировать, компоновать или манипулировать изображениями, не возвращая результат в виде HTTP-ответа. Она также позволяет применять параметры оптимизации в любом порядке, а не следовать фиксированной последовательности, задаваемой URL-интерфейсом. Здесь worker может передавать данные изображения напрямую в API Images, объединять операции в цепочку и получать обработанный результат в виде потока:
const result = await env.IMAGES
.input(image)
.transform({ width: 800, rotate: 90 })
.output({ format: "image/avif" });
return result.response();На высоком уровне так данные изображения перемещаются через наши различные сервисы:
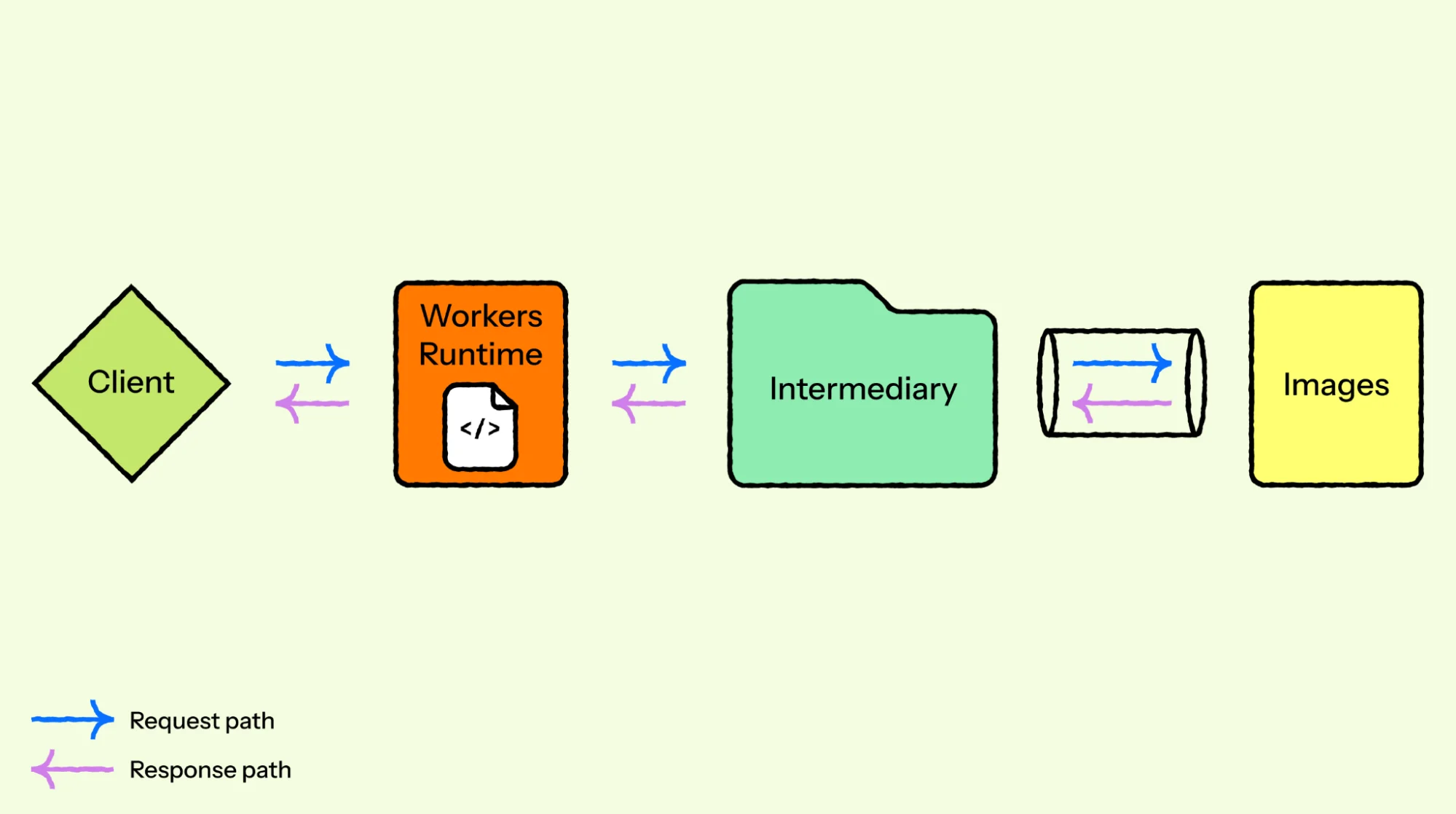
Канал представляет собой сокетное соединение между посредником и Images, где данные передаются от одного процесса к другому через буфер ядра.
Привязка взаимодействует с Images через сокетное соединение, управляемое средой выполнения Workers. Сокетное соединение — это канал связи между двумя процессами. Каждый конец сокета имеет буферы, управляемые ядром операционной системы; эти буферы являются временными областями хранения, где данные находятся после записи одной стороной, но до их чтения другой стороной.
Hyper управляет соединением на стороне сервиса Images, читая входящие запросы из сокета и записывая ответы обратно в него.
Когда запрос использует привязку Images, сервис Images читает входные данные, выполняет запрошенные операции оптимизации и кодирует результат. Затем он передает все закодированное изображение в hyper как единый блок в памяти.
Hyper записывает эти данные ответа в свой собственный внутренний буфер. На этом этапе hyper считает работу по кодированию завершенной, поскольку у него есть все байты, которые нужно отправить. Следующий шаг — сбросить свой внутренний буфер в исходящий буфер сокета, перемещая данные от сервиса Images к посреднику на другом конце.
Если читатель на другом конце быстрый, то hyper может сбросить все за один проход — в исходящем буфере будет место, потому что читатель потребляет данные по мере их поступления. Как только все данные отправлены, hyper выдает команду shutdown на сокете, сигнализируя, что соединение завершено и больше данных не будет записано. Но если читатель медленнее (даже на несколько миллисекунд), то исходящий буфер заполняется, и hyper необходимо ждать, пока не появится место для продолжения записи.
Переход на локальное
Весь входящий трафик в сети Cloudflare проходит через FL — внутренний сервис-посредник, который выполняет функции безопасности и производительности и направляет запросы к соответствующим бэкендам. Когда мы впервые запустили привязку, данные изображений передавались от среды выполнения Workers через FL к сервису Images.
Этот путь был естественным для нашего первого релиза и следовал той же архитектуре, что и наш URL-интерфейс. Однако со временем эта связь с FL стала ограничением: каждое изменение привязки должно было следовать циклу релизов FL.
В декабре 2025 года команда Images заменила FL новым сервисом-посредником — внутренней привязкой worker, которая работает на той же машине. В исходной архитектуре данные перемещались через FL по сетевым сокетам; этот путь нес накладные расходы полного конвейера обработки FL, такие как DNS-запросы и маршрутизация.
Внутренняя привязка заменила их на Unix-сокеты для прямого соединения сервисов на одной машине, минуя FL и накладные расходы сетевого стека. Это сделало путь запроса к Images быстрее и дало команде независимый контроль над релизами привязки.
В течение нескольких дней после внедрения мы получили первый отчет от клиента.
200 OK (не OK)
Первый признак проблемы поступил от клиента с нестандартной настройкой: два уровня обработки изображений, где один конвейер был вложен в другой.
Сначала их worker использовал привязку Images для компоновки нескольких больших исходных изображений из R2 — фоновое изображение в формате JPEG плюс слои PNG-оверлеев — в одно объединенное изображение JPEG. Затем они дополнительно сжимали, транскодировали и изменяли размер результата через URL-интерфейс.
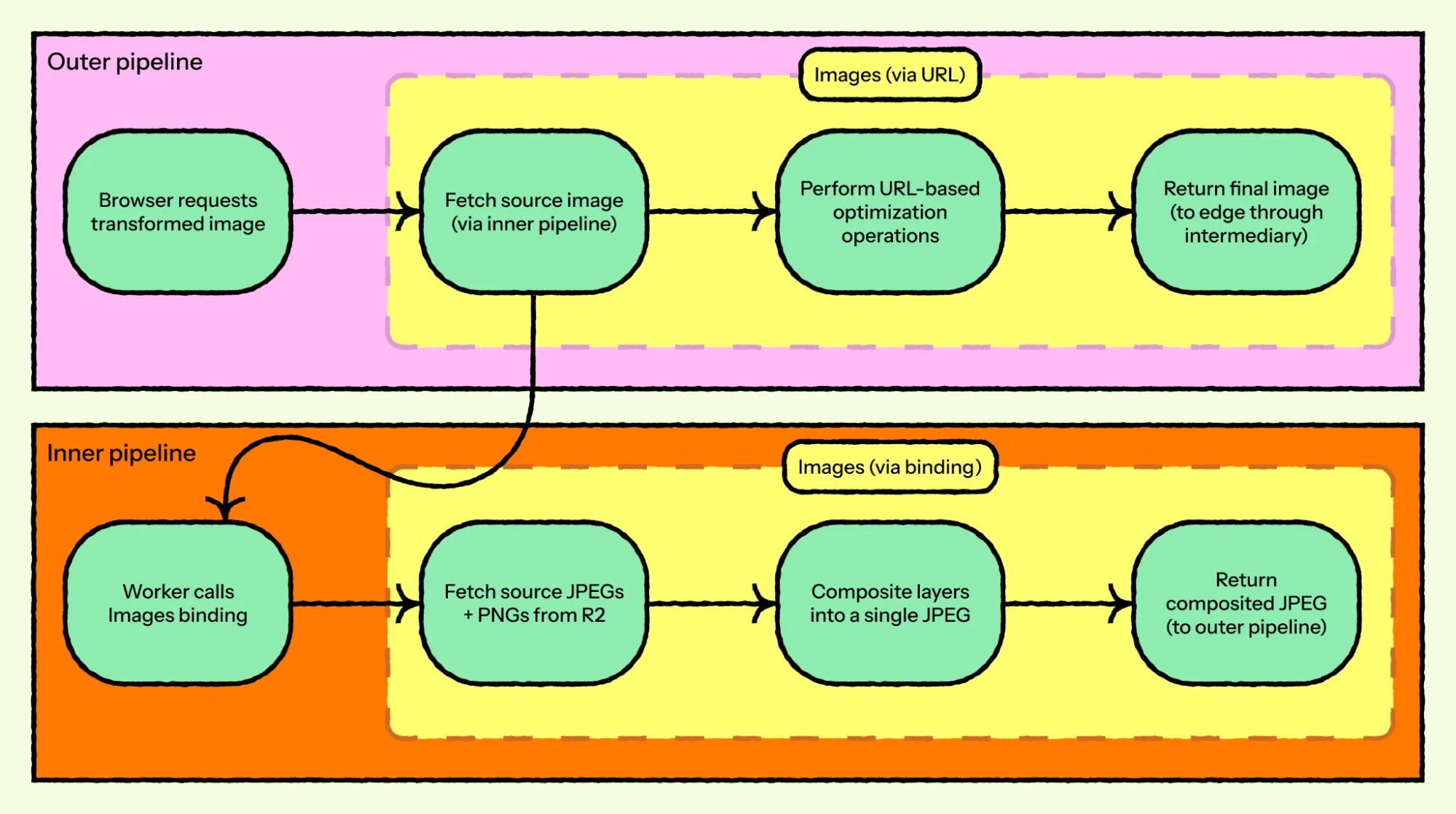
Ошибка возникала на пути возврата внутреннего конвейера, где ответ усекался до того, как достигал внешнего конвейера.
Внутренний конвейер (привязка преобразования) отвечал за компоновку. Внешний конвейер (URL-преобразование) отвечал за оптимизацию доставки, такую как масштабирование и преобразование формата. Многоуровневый подход означал, что когда внутренний конвейер молча возвращал усеченный ответ, единственная видимая ошибка появлялась на один уровень выше:
error reading a body from connection: end of file before message length reachedВнешний конвейер получал HTTP 200 от внутреннего с заголовком Content-Length, обещающим несколько мегабайт. Фактическое тело составляло лишь долю от этого: в одном запросе из ожидаемых 3,3 МБ прибыло только ~200 КБ. Ошибка всплыла во внешнем конвейере, но усечение могло произойти в привязке, сервисе-посреднике, сервисе Images или где-то между ними.
Когда браузер получает усеченное изображение, результат виден. В зависимости от формата изображение либо отображается частично (например, с отсутствующей нижней половиной или серым цветом), либо вообще не декодируется, вместо этого отображая битое изображение.
Отладка в темноте
Отсюда мы двигались внутрь по пути запроса, тестируя каждый уровень, чтобы изолировать место возникновения усечения. Некоторые из этих усилий зашли в тупик; другие оставили подсказки, которые сузили поиск:
-
Создание воспроизведения. Мы создали worker, имитирующий вложенную настройку клиента, а затем удаляли слои, пока не смогли вызвать ошибку с помощью одной только привязки. Небольшой скрипт позволял отправлять запросы пакетами. В одном из первых запусков 19 из 25 запросов завершились ошибкой. Количество данных, которые действительно прибывали — примерно 200 КБ — было подозрительно близко к размеру буфера сокета в продакшене. Это подтвердило, что проблема не связана с конфигурацией клиента, и дало нам надежный способ вызывать ошибку по требованию.
-
Исследование тайм-аутов. На раннем этапе мы подозревали, что усечение может быть связано с поведением тайм-аута (то есть соединение закрывалось после истечения лимита времени). Эта теория не подтвердилась, так как усечение не было связано с продолжительностью запроса.
-
Обновление версии hyper. Когда ошибка была впервые зарегистрирована, мы использовали версию 0.14.x, в то время как последняя версия hyper была около 1.8.x. Мы протестировали версии hyper 0.14, 1.7 и 1.8 на всякий случай, если самый очевидный ответ был правильным (и самым простым). Но ошибка появлялась в каждой версии, что означало, что исправления выше по цепочке не было.
-
Воспроизведение локально. Мы запускали локальные интеграционные тесты на macOS и виртуальной машине с Debian. Даже при значительной нагрузке наши локальные запросы ни разу не вызывали сбоя. Прямые curl-запросы к связующему сокету и воспроизведение захваченных запросов всегда работали. Ошибка проявлялась только на полном production-пути при реальной конкурентности и наличии реального клиента Workers runtime на другом конце сокета. Это привело нас к подозрению на сам runtime.
-
Исключение Workers runtime. Мы изучили HTTP-клиент, который Workers runtime использует для связи с Images через связующий сокет. Ни один из трейсов с обеих сторон соединения не показал системных вызовов, указывающих на неожиданное закрытие или преждевременное завершение. Мы заметили, что клиент работал корректно, и множество других сервисов использовали тот же клиент без проблем.
-
Распределённая трассировка. Проверив трейсы запросов от начала до конца, мы подтвердили, что усечённое тело уже присутствовало до того, как оно достигало внешнего слоя трансформации в настройках клиента. Это сузило проблему до внутреннего конвейера — пути связывания через сервис Images.
-
Инструментирование промежуточного сервиса. Мы добавили инструментирование в промежуточный сервис для измерения размеров тела перед пересылкой данных ответа. Тела уже были усечены к моменту выхода из сервиса Images, поэтому промежуточный сервис был исключён.
-
Более глубокая трассировка внутри сервиса Images. На уровне сервиса запрос был обработан, изображение корректно закодировано, и ответ отправлен с HTTP
200.
Единственным постоянным сигналом было то, что ошибка зависела от времени: она проявлялась только на production-пути, при реальной конкурентности и только для больших изображений.
Зерно истины
Инструменты отладки на уровне приложения говорили лишь о том, что система, по её мнению, делала. Но, согласно системе, всё было в порядке: трассировка утверждала, что ответ отправлен; журналы не сообщали об ошибках, и сервис Images возвращал 200 на каждый запрос.
Чтобы увидеть, что система делала на самом деле, мы подключили strace к сервису Images. strace записывает системные вызовы, которые процесс совершает к ядру, что могло показать нам, какие именно байты были записаны, когда был вызван shutdown и отправлял ли клиент какой-либо сигнал завершения.
Настройка трассировки была деликатной. strace работает, перехватывая системные вызовы по мере их выполнения, что добавляет небольшие временные накладные расходы на каждый из них. Фильтрация по узкому набору системных вызовов сводила эти накладные расходы к минимуму. Однако расширение фильтра замедляло процесс ровно настолько, чтобы сдвинуть время между сбросом и проверкой shutdown — и ошибка полностью исчезала. Это само по себе подтвердило нашу теорию о том, что проблема чувствительна к времени.
Используя воспроизводящий воркер, мы вызвали ошибку и сравнили вывод системных вызовов для успешных и неудачных запросов.
В успешном запросе ответ записывается частями по мере того, как позволяет буфер сокета, а shutdown вызывается только после отправки всех данных. Например, это может выглядеть так:
sendto(42, "HTTP/1.1 200 OKrnContent-Length: 14991808rn...", ...) = 219264
sendto(42, "xffxd8xffxe0...", 292352) = 292352
// ... продолжает запись, пока буфер не опустеет ...
sendto(42, "...", 292352) = 292352
shutdown(42, SHUT_WR) = 0Когда мы воспроизводили ошибку, неудачный запрос выглядел так:
sendto(42, "HTTP/1.1 200 OKrnContent-Length: 14991808rn...", ...) = 219264
shutdown(42, SHUT_WR) = 0Здесь выполняется только одна запись — ровно столько, чтобы хватило на заголовки и крошечную часть тела, после чего сразу вызывается shutdown. Из ответа размером 14,9 МБ было отправлено только около 219 КБ. Оставшиеся ~14,8 МБ данных изображения никогда не покинули внутренний буфер hyper, и никакого сигнала завершения от клиента между записью и shutdown не было. Вместо этого сервис Images преждевременно закрыл соединение по собственной инициативе, искренне полагая, что он закончил.
Неудачные запросы подтвердили, что ошибка была состоянием гонки, которое срабатывало время от времени. Успех или неудача запроса зависели от того, перекрывались ли операции сброса и shutdown, а это менялось от запроса к запросу. Когда буфер был всё ещё полон в тот самый момент, когда hyper решал, что соединение завершено, данные терялись.
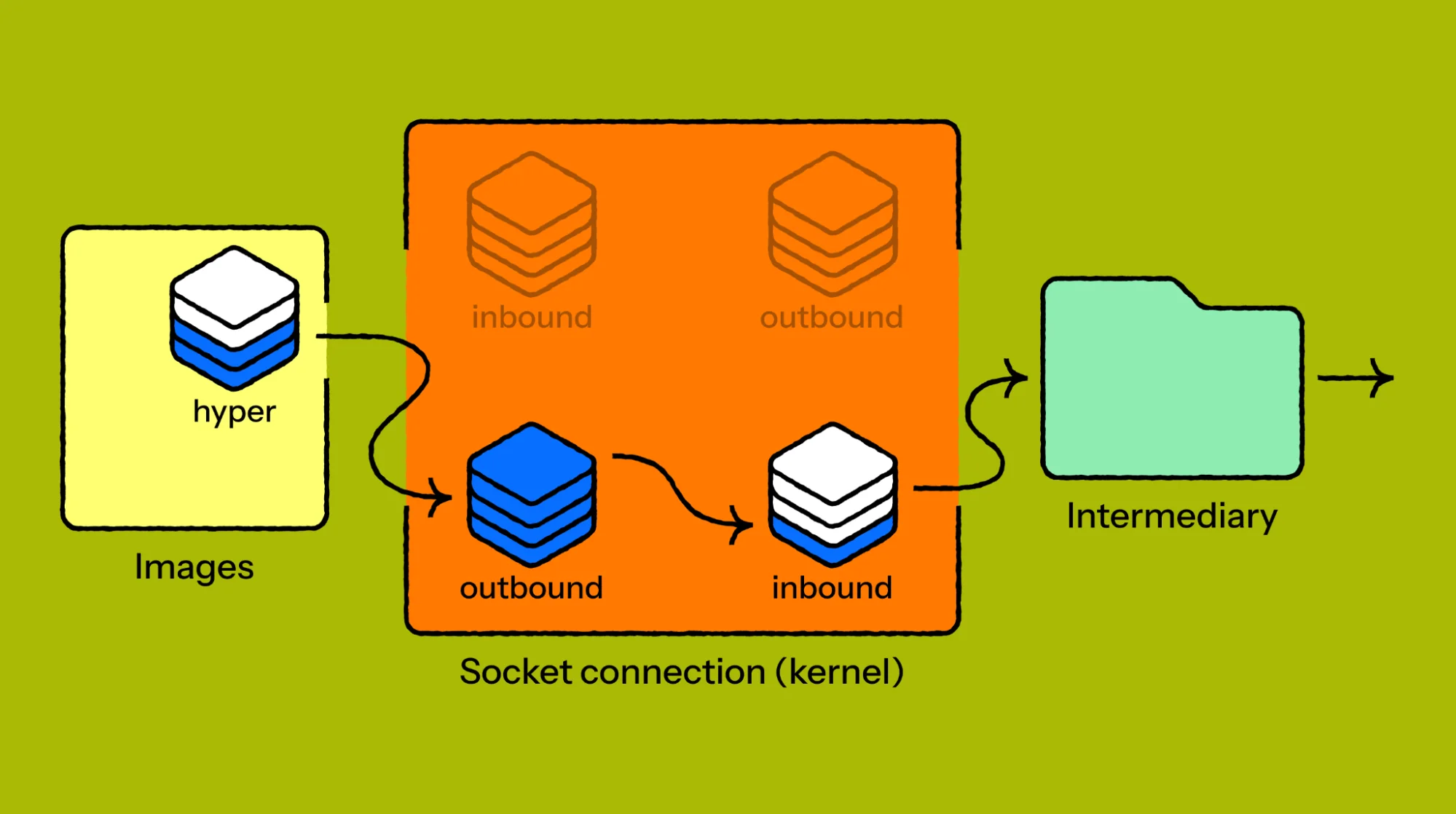
Когда читатель потребляет данные медленнее, чем hyper записывает, исходящий буфер заполняется. Если hyper закрывает соединение до того, как буфер опустеет, до посредника доходит лишь часть ответа; эти неполные данные передаются обратно в Workers runtime и клиенту.
Декабрьская реархитектура не внесла эту ошибку; она присутствовала в hyper годами, на протяжении нескольких мажорных версий. Но новый посредник изменил того, кто читает на стороне ответа сокета. Наша рабочая гипотеза состоит в том, что FL, предыдущий посредник, потреблял данные достаточно быстро, так что буфер сокета редко заполнялся во время ответа. Новый читатель читал с такой скоростью, что иногда буфер заполнялся при больших ответах.
Эти несколько миллисекунд обратного давления, вызванные улучшением, которое ускорило всё остальное, оказались достаточными, чтобы выявить дефект, который прятался на виду.
Внутри диспетчерского цикла
Жизненный цикл HTTP/1 соединения в hyper управляется конечным автоматом в файле dispatch.rs. Он выполняет цикл, который читает запросы, записывает ответы, сбрасывает буфер записи в сокет и решает, когда завершить работу. В упрощённом виде:
fn poll_loop(&mut self, cx: &mut Context<'_>) -> Poll<Result<(), Error>> {
loop {
let _ = self.poll_read(cx)?;
let _ = self.poll_write(cx)?;
let _ = self.poll_flush(cx)?;
if !self.conn.wants_read_again() {
return Poll::Ready(Ok(()));
}
}
}Если точнее, то let _ перед poll_flush — это и есть место, где живёт ошибка.
В Rust let _ = expr отбрасывает результат выражения, включая Poll::Pending — сигнал о том, что сброс ещё не завершён. В буфере сброса всё ещё могут находиться мегабайты данных, но цикл об этом никогда не узнаёт.
Когда запрос терпит неудачу, последовательность событий выглядит так:
-
Сервис Images завершает кодирование изображения и передаёт весь ответ hyper как единый блок в памяти.
-
Hyper записывает блок в свой внутренний буфер и помечает состояние записи как
Writing::Closed. С точки зрения кодирования работа сделана — больше нечего кодировать. -
Hyper вызывает
poll_flush, чтобы переместить буферизованные данные в сокет. В нашем предыдущем примере сокет принял около 219 КБ. Оставшиеся ~14,8 МБ остаются в буфере hyper. Сокет полон, поэтому ядро возвращаетPoll::Pending. -
poll_loopотбрасываетPoll::Pendingс помощьюlet _. -
Он проверяет
wants_read_again(). Полный запрос уже получен, поэтому возвращаетсяfalse. -
poll_loopвозвращаетPoll::Ready(Ok(())), сигнализируя, что цикл завершён, хотя сброс не завершён. -
Срабатывает
poll_shutdown(). Выполняется системный вызовSHUT_WR. -
Клиент получает 219 КБ и EOF (конец файла), указывающий, что соединение закрыто, хотя он ожидает 14,9 МБ.
На втором шаге hyper помечает операцию записи как завершённую сразу после буферизации тела ответа (т.е. когда кодирование закончено), а не после его фактического сброса. В большинстве случаев сброс выполняется за один проход, и это различие незаметно. В редких случаях, когда буфер сокета полон, сбросу приходится ждать — хотя hyper не ждёт. Байты всё ещё находятся в буфере hyper, ожидая сброса в сокет. Hyper продолжает и закрывает соединение, пока эти данные всё ещё в буфере.
Это также объясняет, почему curl никогда не вызывал ошибку. Curl читает данные так быстро, как они поступают: буфер сокета никогда не заполняется, сброс всегда выполняется немедленно, и отброшенное возвращаемое значение безвредно. Production-путь с читателем, который иногда приостанавливался на несколько миллисекунд, был единственной конфигурацией, где буфер заполнялся в самый неподходящий момент.
Не забудьте сбросить
После нескольких недель расследования само исправление было концептуально простым. Hyper должен был проверять, действительно ли сброс завершён, прежде чем двигаться дальше.
Наш воспроизводящий воркер подтвердил, что ошибка существует, но не мог сказать, почему конкретный запрос завершился неудачей. Прежде чем писать исправление, нам нужен был тест, который мог бы вызвать точные условия сокета внутри hyper.
Мы знали условия, вызывающие ошибку: сокет, который принимает один фрагмент данных и затем блокируется. Чтобы протестировать контролируемый сценарий, мы создали собственную обёртку вокруг TCP-потока, которая имитировала полный буфер сокета. Обёртка принимала 8 КБ при первой записи, а затем возвращала Poll::Pending при каждой последующей записи, имитируя читателя, который перестал опустошать буфер.
Тест отправил ответ размером 500 КБ через это ограниченное соединение и проверил, вызывала ли hyper shutdown, пока 492 КБ всё ещё находились в буфере. Без исправления — вызывала. С исправлением — подождала.
Изначально мы применили исправление в диспетчерском цикле hyper. Вместо того чтобы отбрасывать результат poll_flush, мы проверяли, завершён ли сброс:
let flush_result = self.poll_flush(cx)?;
if flush_result.is_pending() {
return Poll::Pending;
}
if !self.conn.wants_read_again() {
return Poll::Ready(Ok(()));
}Если сброс не завершён, цикл возвращает Poll::Pending асинхронной среде выполнения. Среда ожидает, пока сокет не станет доступным для записи, затем пробуждает задачу для продолжения сброса. Соединение закрывается только после отправки всех данных.
Когда мы развернули это исправление, мы заметили, что каждый байт был записан, а shutdown вызывался только после того, как буфер действительно опустел. Заказчик, сообщивший о проблеме первым, также подтвердил, что проблема исчезла.
Хотя наше первоначальное решение работало, диспетчерский цикл не был подходящим местом для исправления. Преждевременный возврат Poll::Pending мог замедлить другие операции на том же соединении за счёт уменьшения частоты опроса чтений, вызывая нежелательное обратное давление. Это также неправильно обрабатывало keepalive-соединения, где одно соединение обрабатывает несколько запросов последовательно — они должны оставаться пригодными для повторного использования, даже пока предыдущий ответ всё ещё сбрасывается. Ни одна из этих проблем не затронула наш конкретный сервис (где keepalive отключён), но обе могли повлиять на других пользователей hyper, если бы исправление было передано в основную кодовую базу.
Мы проследили жизненный цикл соединений hyper и нашли более целенаправленный подход. Вместо изменения поведения диспетчерского цикла мы применили исправление в точке, где фактически вызывается shutdown. Перед закрытием сокета hyper должен сначала сбросить все оставшиеся данные из своего буфера:
pub(crate) fn poll_shutdown(
&mut self,
cx: &mut Context<'_>,
) -> Poll<io::Result<()>> {
ready!(self.poll_flush(cx)?);
Pin::new(&mut self.io).poll_shutdown(cx)
}Это оставляет диспетчерский цикл без изменений. Добавляется сброс только в той точке, где в противном случае произошла бы потеря данных — непосредственно перед shutdown.
Что осталось с нами
Ни один из инструментов на уровне приложения не выявил ошибок, сбоев или записей в журнале, которые дали бы полезные подсказки. Наблюдаемость на уровне приложения может иметь слепые зоны для ошибок, находящихся ниже уровня его осведомлённости.
Сбой происходил периодически, масштабировался с размером ответа, не воспроизводился простыми инструментами вроде curl и исчезал, когда мы наблюдали за системой более внимательно. Эти сигналы указывали на ошибку, зависящую от времени, на уровне соединения, а не в логике приложения.
Прорыв произошёл благодаря использованию инструментов на уровне ядра с strace — единственного уровня, который записывает, что на самом деле произошло на сокете. Лежащая в основе ошибка находилась в нескольких миллисекундах между частичным сбросом и преждевременным shutdown — окно, которое открылось только после того, как мы сделали систему быстрее.
Мы объединили наше исправление и детерминированный тест в hyperium/hyper через PR #4018. Оно будет доступно в одном из будущих релизов hyper, гарантируя, что любой сервис, использующий реализацию HTTP/1 от hyper, не потеряет данные ответа из-за того же состояния гонки.
Тем временем мы используем внутренний форк с применённым патчем. Это исправление стабилизировало архитектуру привязки, создав надёжную основу для расширения её функциональности.
Привязка Images изначально охватывала только преобразования удалённых изображений. Ранее в этом месяце мы объявили, что привязка Images теперь поддерживает операции с размещёнными изображениями, предоставляя разработчикам унифицированный способ создания мультимедийных приложений на Cloudflare.
Читайте подробнее о работе привязки в нашей документации.