То, как мы взаимодействуем с Интернетом, меняется. Не так давно заказ пиццы означал посещение веб-сайта, переход по меню и ввод платежных данных. Вскоре вы сможете просто попросить свой телефон заказать пиццу, соответствующую вашим предпочтениям. Программа на вашем устройстве или на удаленном сервере, которую мы называем ИИ-агентом, посетит веб-сайт и выполнит необходимые шаги от вашего имени.
Конечно, агенты могут делать гораздо больше, чем заказывать пиццу. Вскоре мы сможем использовать их для покупки билетов на концерты, планирования отпусков или даже написания, проверки и слияния пул-реквестов. Хотя некоторые из этих задач в конечном итоге будут выполняться локально, сейчас большинство из них работают на мощных ИИ-моделях, работающих в крупнейших дата-центрах мира. По мере роста популярности агентного ИИ мы ожидаем значительного увеличения трафика с этих ИИ-платформ и соответствующего снижения трафика из более традиционных источников (например, с вашего телефона).
Это изменение в паттернах трафика заставило нас задуматься о том, как обеспечить онлайн-присутствие и безопасность наших клиентов в эпоху ИИ. С одной стороны, характер запросов меняется: веб-сайты, оптимизированные для человеческих посетителей, должны будут справляться с более быстрыми и потенциально более жадными агентами. С другой стороны, ИИ-платформы вскоре могут стать значительным источником атак, исходящих от злонамеренных пользователей самих платформ.
К сожалению, существующие инструменты для управления таким (неправильным) поведением, вероятно, слишком грубы для управления этим переходом. Например, когда Cloudflare обнаруживает, что запрос является частью известного шаблона атаки, часто лучшим курсом действий является блокировка всех последующих запросов из того же источника. Когда источником является платформа ИИ-агентов, это может означать непреднамеренную блокировку всех пользователей той же платформы, даже честных, которые просто хотят заказать пиццу. Мы начали решать эту проблему в начале этого года. Но по мере роста популярности агентного ИИ мы считаем, что Интернету потребуются более детализированные механизмы управления агентами без воздействия на честных пользователей.
В то же время мы твердо верим, что любой такой механизм безопасности должен быть разработан с приватностью пользователя в основе. В этом посте мы опишем, как использовать анонимные учетные данные (AC) для создания этих инструментов. Анонимные учетные данные помогают операторам веб-сайтов применять широкий спектр политик безопасности, такие как ограничение скорости пользователей или блокировка конкретного злонамеренного пользователя, без необходимости идентифицировать любого пользователя или отслеживать его по запросам.
Анонимные учетные данные разрабатываются в IETF для предоставления стандарта, который может работать across веб-сайтами, браузерами, платформами. Это все еще на ранних стадиях, но мы верим, что эта работа сыграет критическую роль в обеспечении безопасности и приватности Интернета в эпоху ИИ. Мы будем участвовать в этом процессе по мере работы над реальным развертыванием. Это все еще ранние дни. Если вы работаете в этой области, мы надеемся, что вы последуете за нами и также внесете свой вклад.
Давайте создадим небольшого агента
Чтобы помочь нам обсудить, как ИИ-агенты влияют на веб-серверы, давайте создадим агента сами. Наша цель — иметь агента, который может заказать пиццу из ближайшей пиццерии. Без агента вы бы открыли браузер, выяснили, какая пиццерия находится nearby, просмотрели меню и сделали выбор, добавили любые дополнения (двойной пепперони) и перешли к оплате своей кредитной картой. С агентом это тот же поток — за исключением того, что агент открывает и управляет браузером от вашего имени.
В традиционном потоке на всем пути присутствует человек, и каждый шаг имеет четкое намерение: перечислить все пиццерии в пределах 3 км от моего текущего местоположения; выбрать пиццу из меню; ввести данные кредитной карты; и так далее. Агент, с другой стороны, должен вывести каждое из этих действий из промпта "закажи мне пиццу".
В этом разделе мы создадим простую программу, которая принимает промпт и может делать исходящие запросы. Вот пример простого Воркера, который принимает конкретный промпт и генерирует ответ соответственно. Вы можете найти код на GitHub:
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
const out = await env.AI.run("@cf/meta/llama-3.1-8b-instruct-fp8", {
prompt: `I'd like to order a pepperoni pizza with extra cheese.
Please deliver it to Cloudflare Austin office.
Price should not be more than $20.`,
});
return new Response(out.response);
},
} satisfies ExportedHandler<Env>;В этом контексте LLM предоставляет свой лучший ответ. Он дает нам план и инструкции, но не выполняет действие от нашего имени. Вы и я способны взять список инструкций и действовать в соответствии с ним, потому что у нас есть агентность и мы можем влиять на мир. Чтобы позволить нашему агенту взаимодействовать с большей частью мира, мы дадим ему контроль над веб-браузером.
Cloudflare предлагает услугу Browser Rendering, которая может напрямую интегрироваться в нашего Воркера. Давайте сделаем это. Следующий код использует Stagehand, фреймворк автоматизации, который упрощает управление браузером. Мы передаем ему экземпляр удаленного браузера Cloudflare, а также клиент для Workers AI.
import { Stagehand } from "@browserbasehq/stagehand";
import { endpointURLString } from "@cloudflare/playwright";
import { WorkersAIClient } from "./workersAIClient"; // wrapper to convert cloudflare AI
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
const stagehand = new Stagehand({
env: "LOCAL",
localBrowserLaunchOptions: { cdpUrl: endpointURLString(env.BROWSER) },
llmClient: new WorkersAIClient(env.AI),
verbose: 1,
});
await stagehand.init();
const page = stagehand.page;
await page.goto("https://mini-ai-agent.cloudflareresearch.com/llm");
const { extraction } = await page.extract("what are the pizza available on the menu?");
return new Response(extraction);
},
} satisfies ExportedHandler<Env>;Вы можете получить доступ к этому коду самостоятельно по адресу https://mini-ai-agent.cloudflareresearch.com/llm. Вот ответ, который мы получили 10 октября 2025 года:
Margherita Classic: $12.99
Pepperoni Supreme: $14.99
Veggie Garden: $13.99
Meat Lovers: $16.99
Hawaiian Paradise: $15.49Используя API скриншотов браузерного рендеринга, мы также можем проверить, что делает агент. Вот как браузер отображает страницу в примере выше:
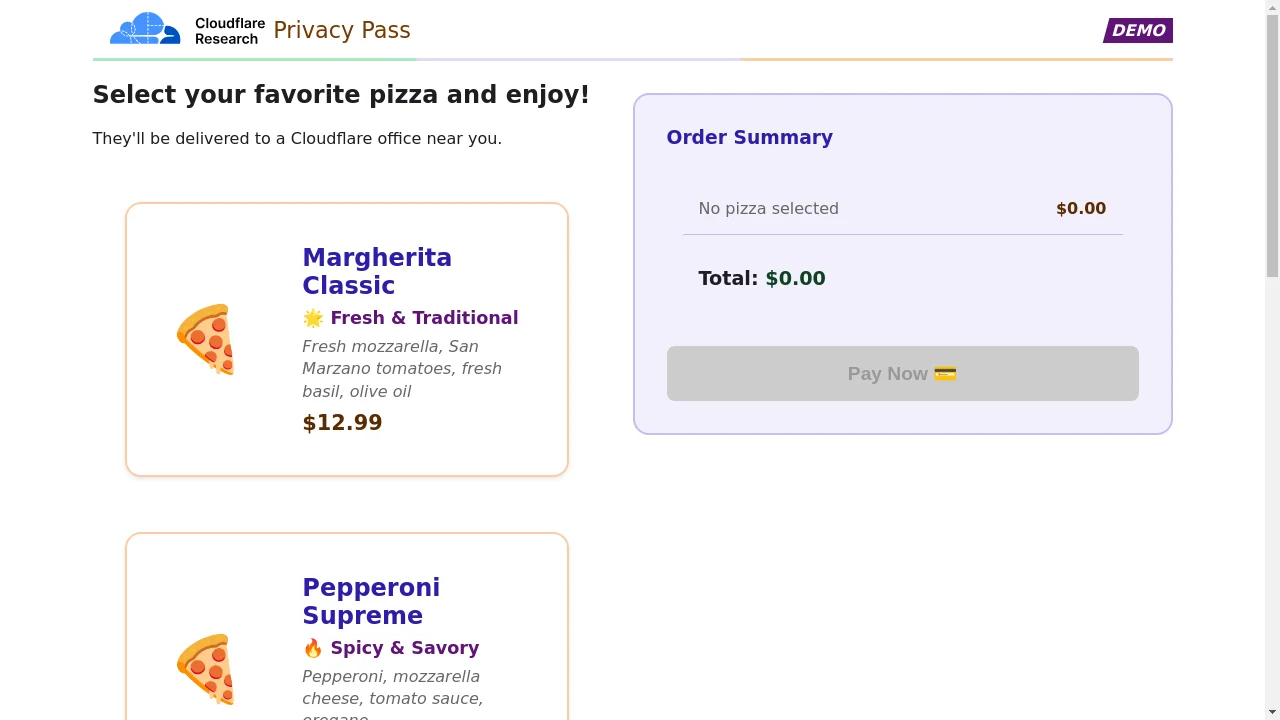
Stagehand позволяет нам идентифицировать компоненты на странице, такие как page.act(“Click on pepperoni pizza”) и page.act(“Click on Pay now”). Это упрощает взаимодействие между разработчиком и браузером.
Чтобы пойти дальше и поручить агенту выполнить весь поток автономно, мы должны использовать соответствующим образом названный агент режим Stagehand. Эта функция еще не поддерживается Cloudflare Workers, но приведена ниже для полноты.
import { Stagehand } from "@browserbasehq/stagehand";
import { endpointURLString } from "@cloudflare/playwright";
import { WorkersAIClient } from "./workersAIClient";
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
const stagehand = new Stagehand({
env: "LOCAL",
localBrowserLaunchOptions: { cdpUrl: endpointURLString(env.BROWSER) },
llmClient: new WorkersAIClient(env.AI),
verbose: 1,
});
await stagehand.init();
const agent = stagehand.agent();
const result = await agent.execute(`I'd like to order a pepperoni pizza with extra cheese.
Please deliver it to Cloudflare Austin office.
Price should not be more than $20.`);
return new Response(result.message);
},
} satisfies ExportedHandler<Env>;Мы видим, что вместо пошаговых инструкций агенту предоставляется контроль. Чтобы фактически произвести оплату, ему потребуется доступ к методу оплаты, такому как виртуальная кредитная карта.
В промпте была некоторая тонкость, так как мы ограничили местоположение офисом Cloudflare в Остине. Это потому, что пока агент отвечает нам, он должен понимать наш контекст. В этом случае агент работает из края Cloudflare, удаленного от нас местоположения. Это implies, что мы вряд ли заберем пиццу из этого дата-центра, если бы ее когда-либо доставили.
Чем больше возможностей мы предоставляем агенту, тем больше у него способность создать некоторые нарушения. Вместо того чтобы кому-то приходилось делать 5 кликов с медленной скоростью 1 запрос в 10 секунд, у них была бы программа, работающая в дата-центре, возможно, делающая все 5 запросов за секунду.
Этот агент прост, но теперь представьте тысячи таких — одни безвредные, другие нет — работающих на скоростях дата-центра. Это вызов, с которым столкнутся источники.
Защита источников
Для взаимодействия людей с онлайн-миром им нужен веб-браузер и некоторые периферийные устройства для управления поведением этого браузера. Агенты — это другой способ управления браузером, поэтому может возникнуть соблазн подумать, что с точки зрения источника на самом деле мало что меняется. Действительно, самое очевидное изменение с точки зрения источника — это лишь то, откуда поступает трафик:
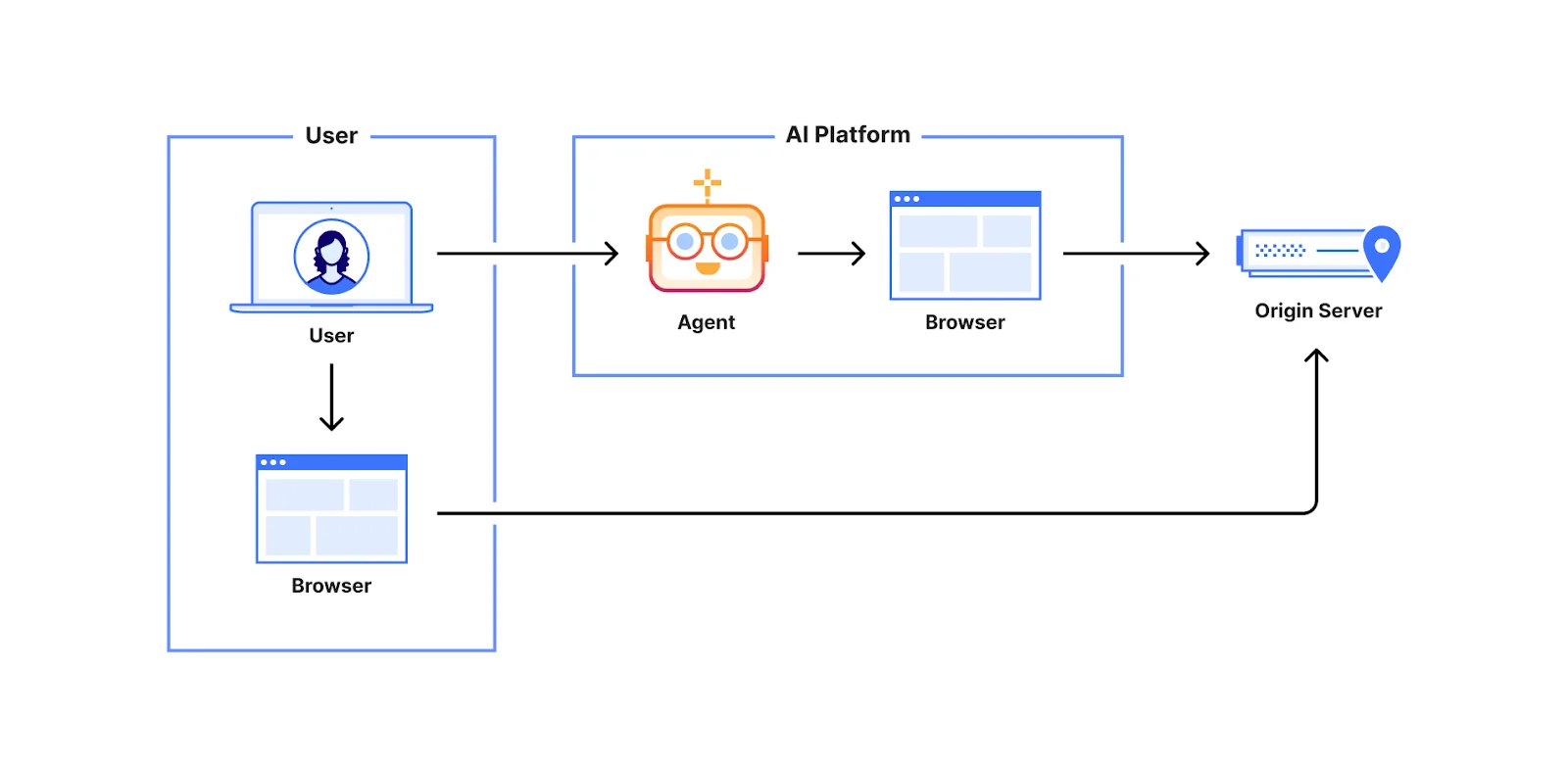
Причина, по которой это изменение значимо, связана с инструментами, которые сервер использует для управления трафиком. Веб-сайты обычно стараются быть как можно более разрешительными, но им также необходимо управлять ограниченными ресурсами (пропускной способностью, процессором, памятью, хранилищем и т.д.). Есть несколько основных способов сделать это:
-
Глобальная политика безопасности: Сервер может замедлить, использовать CAPTCHA или даже временно блокировать запросы от всех пользователей. Эта политика может применяться ко всему сайту, к конкретному ресурсу или к запросам, классифицированным как часть известного или вероятного шаблона атаки. Такие механизмы могут быть развернуты в ответ на наблюдаемый всплеск трафика, как при DDoS-атаке, или в ожидании всплеска легитимного трафика, как в Зоне ожидания.
-
Стимулы: Серверы иногда пытаются стимулировать пользователей использовать сайт, когда доступно больше ресурсов. Например, цена на сервере может быть ниже в зависимости от местоположения или времени запроса. Это можно реализовать с помощью Сниппета Cloudflare.
Хотя оба инструмента могут быть эффективны, они также иногда наносят значительный сопутствующий ущерб. Например, ограничение скорости для конечной точки входа на веб-сайте может помочь предотвратить атаки подбора учетных данных, но оно также ухудшает пользовательский опыт для тех, кто не является атакующим. Прежде чем прибегать к таким мерам, серверы сначала попытаются применить политику безопасности (будь то ограничение скорости, CAPTCHA или прямая блокировка) к отдельным пользователям или группам пользователей.
Однако, чтобы применить политику безопасности к отдельным лицам, серверу нужен какой-то способ их идентификации. Исторически это делалось с помощью комбинации IP-адресов, User-Agent, учетной записи, привязанной к идентификатору пользователя (если доступно), и других отпечатков. Как и большинство поставщиков облачных услуг, Cloudflare имеет специальное предложение для ограничений скорости на пользователя, основанное на таких эвристиках.
Создание отпечатков в основном работает. Однако оно распределено неравномерно. На мобильных устройствах пользователям особенно трудно решать CAPTCHA, при использовании VPN они чаще подвергаются блокировке со стороны сервисов, а при использовании режима чтения они могут испортить свой отпечаток, что предотвратит отрисовку страницы.
Точно так же агентный ИИ только усугубляет ограничения создания отпечатков. Не только больше трафика будет сосредоточено в меньшем диапазоне исходных IP-адресов, но и сами агенты будут работать на одном и том же программном и аппаратном обеспечении, что затрудняет различение добросовестных и злонамеренных пользователей.
Помочь может Аутентификация Веб-Ботов, которая позволила бы агентам идентифицировать себя перед источником, указывая, какой платформой они управляются. Однако мы не хотели бы распространять этот механизм — предназначенный для идентификации самой платформы — на идентификацию отдельных пользователей платформ, так как это создало бы неприемлемый риск для конфиденциальности этих пользователей.
Нам нужен какой-то способ реализации средств контроля безопасности для отдельных пользователей без их идентификации. Но как? Протокол Privacy Pass предлагает частичное решение.
Privacy Pass и его ограничения
Сегодня одним из самых заметных случаев использования Privacy Pass является ограничение скорости запросов от пользователя к источнику, как мы уже обсуждали. Протокол работает примерно следующим образом. Клиенту выдается некоторое количество токенов. Каждый раз, когда он хочет сделать запрос, он погашает один из своих токенов перед источником; источник пропускает запрос только в том случае, если токен свежий, т.е. источник ранее его никогда не видел.
Чтобы использовать Privacy Pass для ограничения скорости на пользователя, необходимо ограничить количество токенов, выдаваемых каждому пользователю (например, 100 токенов на пользователя в час). Чтобы ограничить скорость ИИ-агента, эту роль будет выполнять ИИ-платформа. Чтобы получить токены, пользователь должен войти в систему на платформе, и эта платформа позволит пользователю получить токены от эмитента. ИИ-платформа выполняет роль аттестатора в терминологии Privacy Pass. Аттестатор — это сторона, гарантирующая свойство ограничения скорости на пользователя. ИИ-платформа, как аттестатор, заинтересована в обеспечении этого распределения токенов, так как ставит на кон свою репутацию: если она позволит выпустить слишком много токенов, эмитент может перестать ей доверять.

Протоколы выпуска и погашения разработаны так, чтобы обладать двумя свойствами:
-
Токены неподделываемы: только эмитент может выпускать действительные токены.
-
Токены не связываемы: ни одна из сторон, включая эмитента, аттестатора или источник, не может определить, какому пользователю был выдан токен.
Эти свойства могут быть достигнуты с помощью криптографического примитива, называемого схемой слепой подписи . В обычной схеме подписи подписывающая сторона использует свой закрытый ключ для создания подписи сообщения. Позже проверяющая сторона может использовать открытый ключ подписывающей стороны для проверки подписи. Схемы слепой подписи работают аналогично, за исключением того, что сообщение для подписи ослепляется так, что подписывающая сторона не знает, какое сообщение она подписывает. Клиент «ослепляет» сообщение, которое нужно подписать, и отправляет его серверу, который затем вычисляет ослепленную подпись для ослепленного сообщения. Клиент получает окончательную подпись, снимая ослепление с подписи.
Именно так стандартизированные протоколы выпуска Privacy Pass определены в RFC 9578:
- Выпуск: Пользователь генерирует случайное сообщение $k$, которое мы называем аннулятором. Конкретно, это просто случайная 32-байтовая строка. Затем он ослепляет аннулятор и отправляет его эмитенту. Эмитент отвечает слепой подписью. Наконец, пользователь снимает ослепление с подписи, чтобы получить $sigma$, подпись для аннулятора $k$. Токеном является пара $(k, sigma)$.
- Погашение: Когда пользователь предъявляет $(k, sigma)$, источник проверяет, что $sigma$ является действительной подписью для аннулятора $k$ и что $k$ свежий. Если оба условия выполняются, то он принимает токен и пропускает запрос.
Слепые подписи просты, дешевы и идеально подходят для многих приложений. Однако у них есть некоторые ограничения, которые делают их непригодными для нашего случая использования.
Во-первых, стоимость связи протокола выпуска слишком высока. Для каждого выпущенного токена пользователь отправляет 256-байтовый ослепленный аннулятор, а эмитент отвечает 256-байтовой слепой подписью (при условии использования RSA-2048). Это дополнительные 0,5 КБ связи на запрос или 500 КБ на каждые 1000 запросов. Это управляемо, как мы видели в предыдущем эксперименте с Privacy Pass, но не идеально. В идеале пропускная способность была бы сублинейной относительно ограничения скорости, которое мы хотим обеспечить. Альтернативой слепым подписям с меньшим временем вычислений являются Обфусцированные Псевдослучайные Функции (VOPRF), но пропускная способность все еще асимптотически линейна. Мы обсуждали их ранее, так как они послужили основой для ранних развертываний Privacy Pass.
Во-вторых, слепые подписи нельзя использовать для ограничения скорости на основе источника. В идеале, при выдаче клиенту $N$ токенов, клиент мог бы использовать не более $N$ токенов на любом сервере-источнике, который может проверить валидность токена. Однако клиент не может безопасно использовать один и тот же токен на нескольких серверах, потому что серверы смогут связать эти использования с одним и тем же клиентом. Необходим некоторый механизм для того, что мы назовем поздней привязкой к источнику: преобразование токена для использования на конкретном источнике таким образом, чтобы это было не связано с другими использованиями того же токена.
В-третьих, после выпуска токен нельзя отозвать: он остается действительным до тех пор, пока действителен открытый ключ эмитента. Это делает невозможным для источника заблокировать конкретного пользователя, если он обнаружит атаку или если его токены будут скомпрометированы. Источник может заблокировать проблемный запрос, но пользователь может продолжать делать запросы, используя оставшийся запас токенов.
Анонимные учетные данные и будущее Privacy Pass
Как отмечено Чаумом в 1985 году, система анонимных учетных данных позволяет пользователям получать учетные данные от эмитента, а затем доказывать владение этими учетными данными не связанным образом, не раскрывая никакой дополнительной информации. Кроме того, возможно продемонстрировать, что с учетными данными связаны некоторые атрибуты.
Один из способов представить анонимные учетные данные — это своего рода слепая подпись с некоторыми дополнительными возможностями: поздняя привязка (привязка токена к источнику после выпуска), многократное предъявление (генерация нескольких токенов из одного ответа эмитента) и срок действия, отличный от смены ключа (валидность токена не зависит от валидности криптографического ключа эмитента). В процессе использования Privacy Pass клиент предъявляет серверу раскрытое сообщение и подпись. Для принятия использования сервер должен проверить подпись. В системе AC клиент предъявляет только часть сообщения. Чтобы сервер принял запрос, клиент должен доказать серверу, что он знает валидную подпись для всего сообщения, не раскрывая его полностью.
Описанный выше процесс, следовательно, включал бы этот дополнительный шаг предъявления.

Обратите внимание, что токены, сгенерированные с помощью слепых подписей или VOPRF, могут быть использованы только один раз, поэтому их можно рассматривать как токены одноразового использования. Однако существует тип анонимных учетных данных, который позволяет использовать токены многократно. Для этого эмитент выдает учетные данные пользователю, который впоследствии может получить не более N токенов одноразового использования. Таким образом, пользователь может отправлять несколько запросов ценой одной сессии выпуска.
В таблице ниже описано, как слепые подписи и анонимные учетные данные предоставляют функции, представляющие интерес для ограничения скорости.
|
Функция |
Слепая подпись |
Анонимные учетные данные |
|
Стоимость выпуска |
Линейная сложность: выпуск 10 подписей в 10 раз дороже выпуска одной подписи |
Сублинейная сложность: подписание 10 атрибутов дешевле 10 отдельных подписей |
|
Возможность доказательства |
Только доказывают, что сообщение было подписано |
Позволяют эффективно доказывать частичные утверждения (т.е. атрибуты) |
|
Управление состоянием |
Бессостояние |
С состоянием |
|
Атрибуты |
Без атрибутов |
Публичное (например, время истечения) и приватное состояние |
Давайте посмотрим, как работает простая схема анонимных учетных данных. Сообщение клиента состоит из пары $(k, C)$, где $k$ — это обнулитель, а $C$ — это счетчик, представляющий оставшееся количество раз, которое клиент может получить доступ к ресурсу. Значение счетчика контролируется сервером: когда клиент использует свои учетные данные, он предъявляет и обнулитель, и счетчик. В ответ сервер проверяет, что подпись сообщения действительна и что обнулитель свежий, как и раньше. Дополнительно сервер также
-
проверяет, что счетчик больше нуля; и
-
уменьшает счетчик, выпуская новые учетные данные для обновленного счетчика и свежего обнулителя.
Для реализации этой функциональности можно было бы использовать слепую подпись. Однако, хотя обнулитель можно скрыть, как и раньше, необходимо было бы обрабатывать счетчик в открытом тексте, чтобы сервер мог проверить его валидность (Шаг 1) и обновить его (Шаг 2). Это создает очевидный риск для конфиденциальности, поскольку сервер, контролирующий счетчик, может использовать его для связывания нескольких предъявлений одним и тем же клиентом. Например, когда вы обращаетесь, чтобы купить пиццу с пепперони, источник может присвоить вам специальное значение счетчика, что облегчает создание цифрового отпечатка при вашем втором обращении. К счастью, существуют анонимные учетные данные, разработанные для устранения такого рода пробелов в конфиденциальности.
Приведенная выше схема является упрощенной версией Anonymous Credit Tokens (ACT), одной из схем анонимных учетных данных, рассматриваемых для принятия рабочей группой Privacy Pass в IETF. Ключевой особенностью ACT является его состоятельность: при успешном использовании сервер перевыпускает новые учетные данные с обновленными значениями обнулителя и счетчика. Это создает петлю обратной связи между клиентом и сервером, которую можно использовать для выражения различных политик безопасности.
По design, невозможно предъявить учетные данные ACT многократно одновременно: первое предъявление должно быть завершено, чтобы перевыпущенные учетные данные можно было предъявить в следующем запросе. Параллелизм является ключевой особенностью Anonymous Rate-limited Credential (ARC), другой схемы, обсуждаемой в рабочей группе Privacy Pass. ARC можно предъявлять в нескольких параллельных запросах вплоть до лимита предъявлений, определенного при выпуске.
Еще одной важной особенностью ARC является поддержка поздней привязки к источнику: когда клиенту выдается ARC с лимитом предъявлений $N$, он может безопасно использовать свои учетные данные для предъявления до $N$ раз любому источнику, который может проверить учетные данные.
Это всего лишь примеры соответствующих функций некоторых анонимных учетных данных. Некоторые приложения могут выиграть от их подмножества; другим могут потребоваться дополнительные функции. К счастью, и ACT, и ARC могут быть построены из небольшого набора криптографических примитивов, которые можно легко адаптировать для других целей.
Строительные блоки для анонимных учетных данных
ARC и ACT имеют два общих примитива: алгебраические MAC, которые обеспечивают ограниченные вычисления над скрытым сообщением; и доказательства с нулевым разглашением (ZKP) для доказательства валидности части сообщения, не раскрытой серверу. Давайте рассмотрим каждый из них подробнее.
Алгебраические MAC
Код аутентификации сообщения (MAC) — это криптографический тег, используемый для проверки подлинности сообщения (что оно исходит от заявленного отправителя) и целостности (что оно не было изменено). Алгебраические MAC построены на математических структурах, таких как групповые действия. Алгебраическая структура придает им некоторую дополнительную функциональность, одной из которых является гомоморфизм, позволяющий легко скрывать фактическое значение MAC. Добавление случайного значения к алгебраическому MAC скрывает значение.
В отличие от слепых подписей, и ACT, и ARC являются только приватно проверяемыми, что означает, что и эмитент, и источник должны иметь закрытый ключ эмитента. Взяв в качестве примера Cloudflare, это означает, что учетные данные, выданные Cloudflare, могут быть использованы только источником, находящимся за Cloudflare. Публично проверяемые варианты обоих возможны, но с дополнительной стоимостью.
Доказательства с нулевым разглашением для линейных отношений
Доказательства с нулевым разглашением (ZKP) позволяют нам доказать, что утверждение истинно, не раскрывая точного значения, которое делает утверждение истинным. ZKP конструируется доказывающей стороной таким образом, что его может сгенерировать только тот, кто действительно обладает секретом. Проверяющая сторона может затем выполнить быструю математическую проверку этого доказательства. Если проверка пройдена, проверяющая сторона убеждена, что исходное утверждение доказывающей стороны действительно. Ключевое свойство заключается в том, что само доказательство — это просто данные, подтверждающие утверждение; оно не содержит никакой другой информации, которую можно было бы использовать для восстановления исходного секрета.
Для ARC и ACT мы хотим доказать линейные соотношения секретов. В ARC пользователю нужно доказать, что разные токены связаны с одним и тем же исходным секретным учетным данным. Например, пользователь может сгенерировать доказательство, показывающее, что токен запроса был получен из действительного выданного учетного данных. Система может проверить это доказательство, чтобы подтвердить, что токены законно связаны, при этом никогда не узнавая лежащий в основе секретный учетный данные, который их связывает. Это позволяет системе проверять действия пользователя, гарантируя его конфиденциальность.
Доказательство простых линейных соотношений можно расширить для доказательства ряда мощных утверждений, например, что число находится в диапазоне. Например, это полезно для доказательства того, что у вас положительный баланс на счете. Чтобы доказать, что ваш баланс положительный, вы доказываете, что можете представить свой баланс в двоичной форме. Допустим, у вас может быть не более 1024 кредитов на счете. Чтобы доказать, что ваш баланс ненулевой, когда он, например, равен 12, вы одновременно доказываете две вещи: во-первых, что у вас есть набор двоичных битов, в данном случае 12=(1100)2, и во-вторых, что линейное уравнение с использованием этих битов (8*1 + 4*1 + 2*0 + 1*0) правильно суммируется в ваш общий зафиксированный баланс. Это убеждает верификатора в том, что число корректно построено, без раскрытия точного значения. Так это работает для степеней двойки, но это можно легко расширить на произвольные диапазоны.
Математическая структура алгебраических MAC позволяет легко выполнять ослепление и вычисление. Эта структура также позволяет легко доказывать, что MAC был вычислен с использованием закрытого ключа, без раскрытия самого MAC. Кроме того, ARC может использовать ZKP для доказательства того, что одноразовый номер ранее не использовался. В отличие от этого, ACT использует ZKP для доказательства того, что у нас осталось достаточно баланса на нашем токене. Баланс вычитается гомоморфно с использованием дополнительной групповой структуры.
Сколько всё это стоит?
Анонимные учетные данные обеспечивают большую гибкость и потенциально могут снизить затраты на передачу данных по сравнению со слепыми подписями в определенных приложениях. Чтобы выявить такие приложения, нам необходимо измерить конкретные затраты на передачу данных для этих новых протоколов. Кроме того, нам нужно понять, как их использование ЦП сравнивается со слепыми подписями и oblivious pseudorandom functions (OPRF).
Мы измеряем время, которое каждый участник тратит на каждом этапе некоторых схем AC. Мы также сообщаем размер сообщений, передаваемых по сети. Для ARC, ACT и VOPRF мы будем использовать ristretto255 в качестве простой группы и SHAKE128 для хеширования. Для Blind RSA мы будем использовать 2048-битный модуль и SHA-384 для хеширования.
Каждый алгоритм был реализован на Go поверх библиотеки CIRCL. Мы планируем открыть исходный код, как только спецификации ARC и ACT начнут стабилизироваться.
Давайте рассмотрим наиболее широко используемое развертывание в Privacy Pass: Blind RSA. Время погашения невелико, и большая часть затрат ложится на сервер во время выпуска. Затраты на передачу данных в основном постоянны и составляют порядка 256 байт.
| Blind RSA RFC9474(RSA-2048+SHA384) |
1 Токен | ||
|---|---|---|---|
| Время | Размер сообщения | ||
| Выпуск | Клиент (Ослепление) | 63 мкс | 256 Б |
| Сервер (Вычисление) | 2.69 мс | 256 Б | |
| Клиент (Завершение) | 37 мкс | 256 Б | |
| Погашение | Клиент | – | 300 Б |
| Сервер | 37 мкс | – |
При рассмотрении VOPRF время проверки на сервере немного выше, чем для Blind RSA, но затраты на передачу данных и выпуск намного быстрее. Время вычисления на сервере в 10 раз быстрее для 1 токена и более чем в 25 раз быстрее при использовании амортизированного выпуска токенов. Затраты на передачу данных на токен также более привлекательны, с размером сообщения как минимум в 3 раза меньше.
| VOPRF RFC9497(Ristretto255+SHA512) |
1 Токен | 1000 амортизированных выпусков | |||
|---|---|---|---|---|---|
| Время | Размер сообщения | Время (на токен) |
Размер сообщения (на токен) |
||
| Выпуск | Клиент (Ослепление) | 54 мкс | 32 Б | 54 мкс | 32 Б |
| Сервер (Вычисление) | 260 мкс | 96 Б | 99 мкс | 32.064 Б | |
| Клиент (Завершение) | 376 мкс | 64 Б | 173 мкс | 64 Б | |
| Погашение | Клиент | – | 96 Б | – | |
| Сервер | 57 мкс | – |
Это делает токены VOPRF привлекательными для приложений, требующих большого количества токенов, которые могут допустить несколько более высокую стоимость погашения и которым не нужна публичная проверяемость.
Теперь давайте посмотрим на цифры для схем анонимных учетных данных ARC и ACT. Для обеих схем мы измеряем время выпуска учетных данных, которые могут быть предъявлены не более $N=1000$ раз.
| Выпуск Генерация учетных данных |
ARC | ACT | ||
|---|---|---|---|---|
| Время | Размер сообщения | Время | Размер сообщения | |
| Клиент (Запрос) | 323 мкс | 224 Б | 64 мкс | 141 Б |
| Сервер (Ответ) | 1349 мкс | 448 Б | 251 мкс | 176 Б |
| Клиент (Завершение) | 1293 мкс | 128 Б | 204 мкс | 176 Б |
| Погашение Предъявление учетных данных |
ARC | ACT | ||
| Время | Размер сообщения | Время | Размер сообщения | |
| Клиент (Предъявление) | 735 мкс | 288 Б | 1740 мкс | 1867 Б |
| Сервер (Проверка/Возврат) | 740 мкс | – | 1785 мкс | 141 Б |
| Клиент (Обновление) | – | – | 508 мкс | 176 Б |
Как и следовало ожидать, затраты на передачу данных и время работы сервера намного ниже, чем при пакетном выпуске как с Blind RSA, так и с VOPRF. Например, выпуск 1000 токенов VOPRF занимает 99 мс (99 мкс на токен) против 1.35 мс для выпуска одного учетного данных ARC, который позволяет 1000 предъявлений. Это примерно в 70 раз быстрее. Компромисс заключается в том, что предъявление обходится дороже как для клиента, так и для сервера.
А как насчет ACT? Как и в случае с ARC, мы ожидаем, что затраты на передачу данных при выпуске растут гораздо медленнее по отношению к выпущенным кредитам. Наша реализация это подтверждает. Однако есть некоторые интересные различия в производительности между ARC и ACT: выпуск для ACT намного дешевле, чем для ARC, но с погашением ситуация обратная.
В чём дело? Ответ во многом связан с тем, что каждой стороне нужно доказывать с помощью ZKP на каждом этапе. Например, во время погашения ACT клиент доказывает серверу (с нулевым разглашением), что его счетчик $C$ находится в желаемом диапазоне, т.е. $0 leq C leq N$. Размер доказательства имеет порядок $log_{2} N$, что объясняет больший размер сообщения. В текущей версии погашение ARC не включает доказательства диапазона, но доказательство диапазона может быть добавлено в будущей версии. В то же время утверждения, которые клиенту и серверу нужно доказывать во время выпуска ARC, немного сложнее, чем для предъявления ARC, что объясняет разницу во времени выполнения там.
Преимущество анонимных учетных данных, как обсуждалось в предыдущих разделах, заключается в том, что выпуск нужно выполнять только один раз. Когда сервер оценивает свою стоимость, он учитывает стоимость всех выпусков и стоимость всех проверок. В настоящее время, учитывая только стоимость учетных данных, серверу дешевле выпускать и проверять токены, чем проверять презентацию анонимных учетных данных.
Преимущество многоразовых анонимных учетных данных заключается в том, что вместо генерации $N$ токенов эмитентом основная часть вычислений перекладывается на клиентов. Это более целенаправленно. Поздняя привязка к источнику позволяет им работать с несколькими источниками/пространствами имен, доказательство диапазона позволяет отделить срок действия от смены ключа, а возврат средств обеспечивает динамическое ограничение частоты запросов. Их текущие применения определяются скорее ограничениями схем на основе одноразовых токенов, чем дополнительной эффективностью, которую они предоставляют. Это кажется перспективной областью для изучения и выяснения, возможно ли сократить разрыв.
Управление агентами с помощью анонимных учетных данных
Управление агентами, вероятно, потребует функций как от ARC, так и от ACT.
ARC уже имеет большую часть необходимой нам функциональности: он поддерживает ограничение частоты запросов, эффективен с точки зрения связи и поддерживает позднюю привязку к источнику. Его главный недостаток заключается в том, что после выпуска учетных данных ARC их нельзя отозвать. Злонамеренный пользователь всегда может сделать до N запросов к любому желаемому источнику.
Мы можем разрешить ограниченную форму отзыва, сочетая ARC со слепыми подписями (или VOPRF). Каждая презентация учетных данных ARC сопровождается токеном Privacy Pass: при успешной презентации клиенту выдается еще один токен Privacy Pass, который он может использовать при следующей презентации. Чтобы отозвать учетные данные, сервер просто не перевыпускает токен:
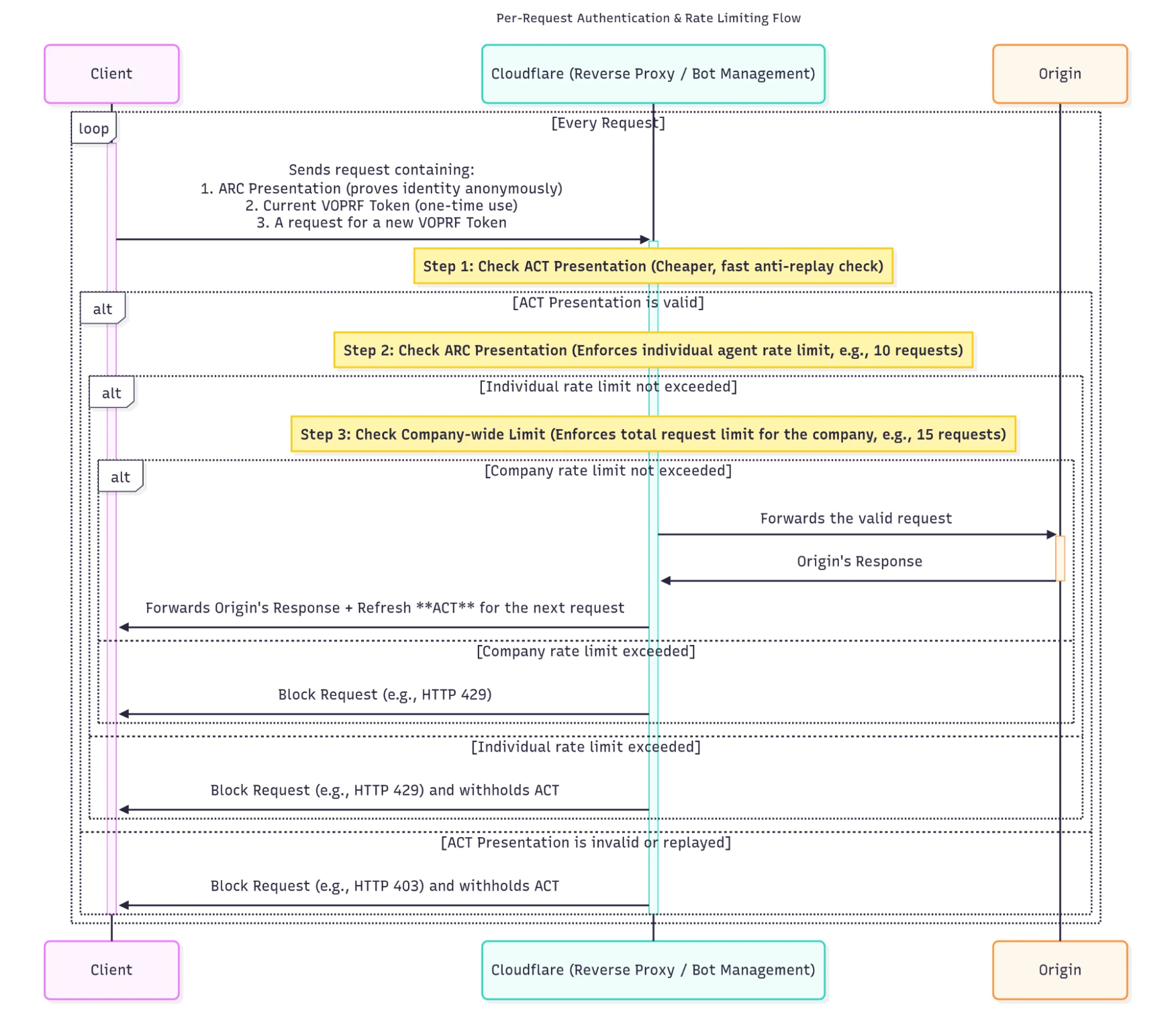
Эта схема уже вполне полезна. Однако у нее есть некоторые важные ограничения:
-
Параллельная презентация между источниками невозможна: клиент должен дождаться успешного выполнения запроса к одному источнику, прежде чем он сможет инициировать запрос ко второму источнику.
-
Отзыв является глобальным, а не для каждого источника, что означает, что учетные данные отзываются не только для источника, которому они были предъявлены, но и для любого источника, которому их можно предъявить. Мы подозреваем, что в некоторых случаях это будет нежелательно. Например, источник может захотеть отозвать доступ, если запрос нарушает его политику
robots.txt; но тот же запрос мог быть принят другими источниками.
Более фундаментальное ограничение этой конструкции заключается в том, что решение об отзыве может быть принято только на основании одного запроса — того, в котором были предъявлены учетные данные. Может быть рискованно блокировать пользователя на основании одного запроса; на практике шаблоны атак могут проявляться только через множество запросов. Состоятельность ACT позволяет реализовать по крайней мере rudimentary форму такой защиты. Рассмотрим следующую схему:
-
Выпуск: Клиенту выдается ARC с лимитом презентаций $N=1$.
-
Презентация:
-
Когда клиент впервые предъявляет свои учетные данные ARC источнику, сервер выдает ACT с действительным начальным состоянием.
-
Когда клиент предъявляет ACT с действительным состоянием (например, счетчик кредитов больше 0), источник либо:
-
отказывается выпускать новый ACT, тем самым отзывая учетные данные. Это делается только в случае высокой уверенности, что запрос является частью атаки; или
-
выдает новый ACT с обновленным состоянием, уменьшая кредит ACT на объем ресурсов, потребленных при обработке запроса.
-
-
Безобидные запросы не сильно (или вообще не) изменяют состояние, но подозрительные запросы могут повлиять на состояние таким образом, что пользователь гораздо быстрее приблизится к своему лимиту частоты запросов.
Демонстрация
Чтобы увидеть, как эта идея работает на практике, рассмотрим рабочий пример, использующий Model Context Protocol. Демо ниже построено с использованием MCP Tools. Инструменты — это расширения, которые может вызывать ИИ-агент для расширения своих возможностей. Их не нужно интегрировать во время выпуска в MCP-клиенте. Это обеспечивает хороший и простой путь для прототипирования анонимных учетных данных.
Инструменты предоставляются сервером через совместимый с MCP интерфейс. Подробности о том, как построить такие MCP-серверы, можно увидеть в предыдущем блоге.
В нашем контексте с пиццерией это могло бы выглядеть как пиццерия, предлагающая вам ваучер. Каждый ваучер дает вам 3 куска пиццы. В качестве макета дизайна, интеграция в приложение для чата могла бы выглядеть следующим образом:

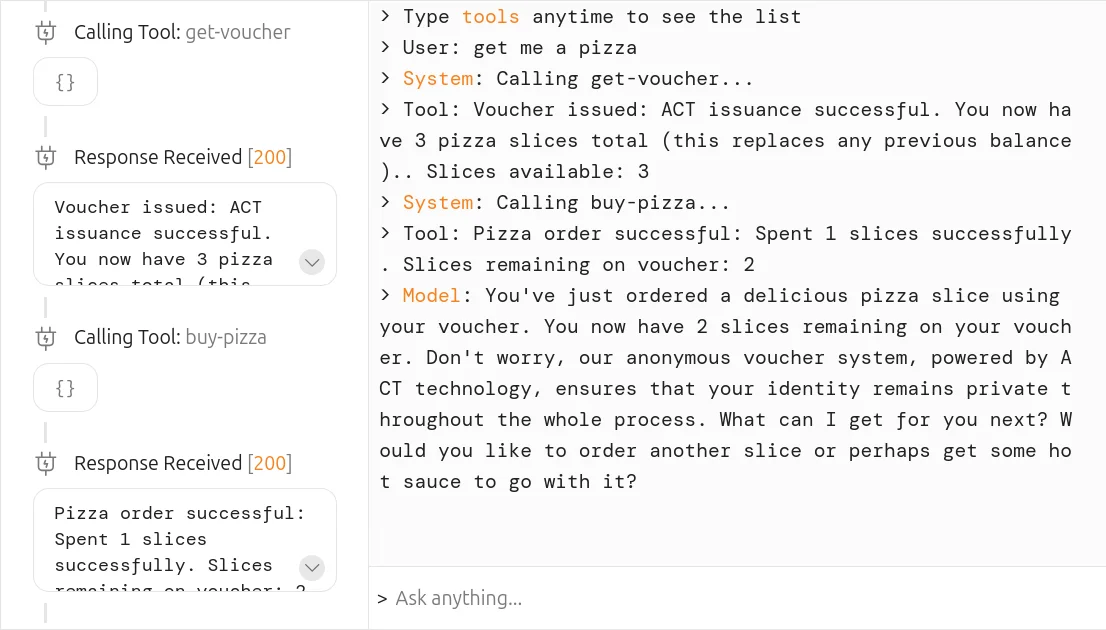
Первая панель показывает все инструменты, предоставляемые MCP-сервером. Вторая демонстрирует взаимодействие, выполняемое агентом при вызове этих инструментов.
Чтобы понять, как такой поток будет реализован, давайте напишем MCP-инструменты, предложим их на MCP-сервере и вручную оркестрируем вызовы с помощью MCP Inspector.
MCP-сервер должен предоставлять два инструмента:
-
act-issue, который выдает ACT, действительный для 3 запросов. Здесь используется более ранняя версия черновика IETF, которая имеет некоторые ограничения. -
act-redeemвыполняет презентацию локальных учетных данных и получает наше меню пиццы.
Сначала мы запускаем act-issue. На этом этапе мы могли бы попросить агента запустить OAuth-флоу, получить доступ к внутренней конечной точке аутентификации или вычислить доказательство работы.
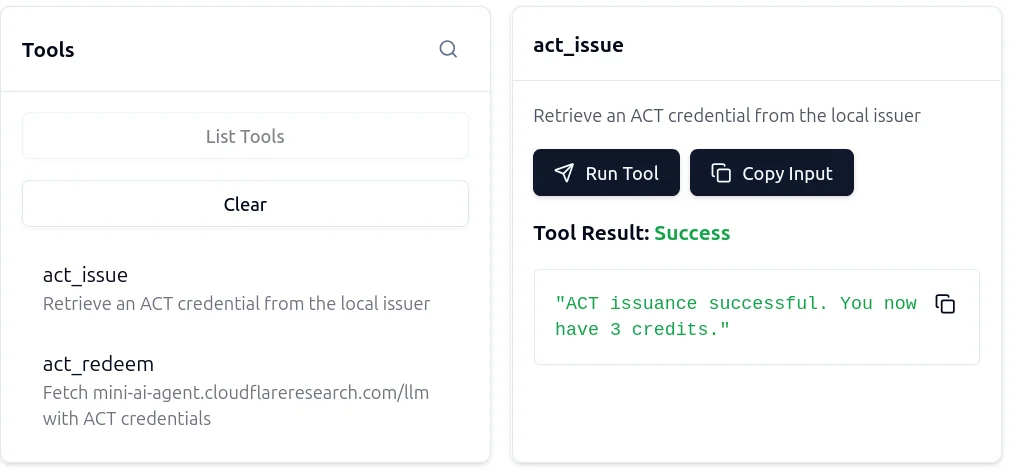
Это дает нам 3 кредита для использования против источника. Затем мы запускаем act-redeem
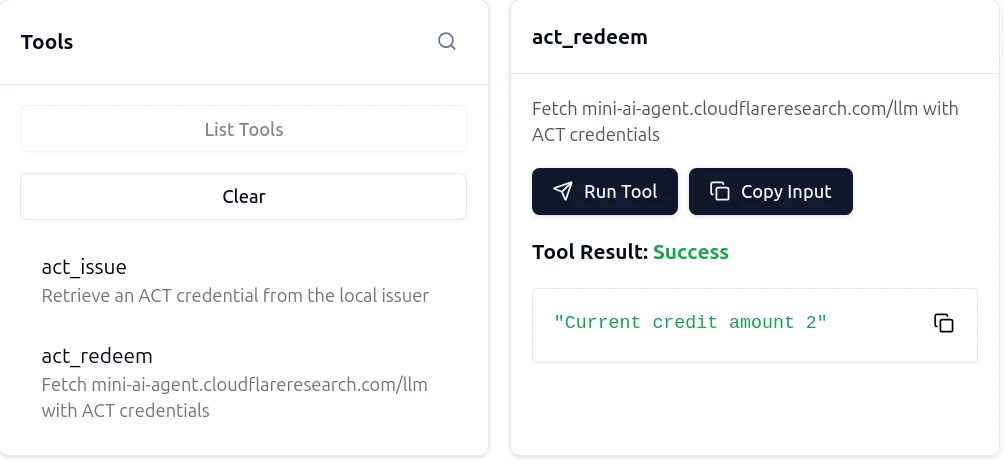
И вот. Если мы запустим act-redeem еще раз, мы увидим, что у нас на один кредит меньше.
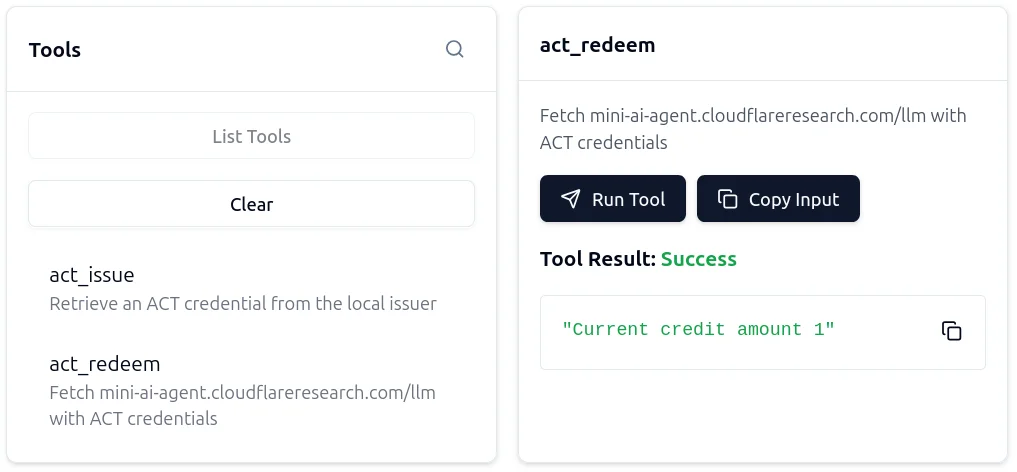
Вы можете протестировать это сами, вот доступные исходные коды. MCP-сервер написан на Rust для интеграции с библиотекой ACT rust. Клиент на основе браузера работает аналогично, проверьте его.
Дальнейшее развитие
В этом посте мы представили конкретный подход к ограничению частоты запросов трафика агентов. Он полностью контролируется клиентом и построен для защиты конфиденциальности пользователя. Он использует emerging стандарты для анонимных учетных данных, интегрируется с MCP и может быть легко развернут на Cloudflare Workers.
Мы на правильном пути, но остаются вопросы. Как мы уже упоминали, заметным ограничением как ARC, так и ACT является то, что они являются только приватно проверяемыми. Это означает, что эмитент и источник должны иметь общий закрытый ключ для выпуска и проверки учетных данных соответственно. Вероятно, существуют сценарии развертывания, для которых это невозможно. К счастью, для таких случаев может быть путь вперед с использованием криптографии на основе спариваний, как в спецификации подписей BBS, которая проходит путь через IETF. Мы также исследуем последствия для постквантовой эры в параллельном посте.
Если вы являетесь платформой для агентов, разработчиком агентов или браузером, весь наш код доступен на GitHub для ваших экспериментов. Cloudflare активно работает над проверкой этого подхода для реальных случаев использования.
Спецификация и обсуждение происходят в рамках IETF и W3C. Это гарантирует, что протоколы создаются открыто и при участии экспертов. Улучшения еще предстоит внести, чтобы прояснить правильный компромисс между производительностью и конфиденциальностью, и даже стратегию развертывания в открытой сети.