Работа с данными в потоках является основополагающей для создания приложений. Чтобы сделать потоковую передачу повсеместной, был разработан Стандарт WHATWG Streams (неформально известный как "Web streams") с целью создания общего API для работы в браузерах и на серверах. Он появился в браузерах, был принят Cloudflare Workers, Node.js, Deno и Bun и стал основой для таких API, как fetch(). Это значительное достижение, и люди, которые его проектировали, решали сложные проблемы в рамках ограничений и инструментов, доступных в то время.
Но после многих лет работы с Web streams — их реализации как в Node.js, так и в Cloudflare Workers, отладки проблем в продакшене для клиентов и сред выполнения, а также помощи разработчикам в преодолении слишком многих распространённых ошибок — я пришёл к выводу, что стандартный API имеет фундаментальные проблемы с удобством использования и производительностью, которые невозможно легко исправить лишь постепенными улучшениями. Проблемы не являются багами; это последствия проектных решений, которые могли иметь смысл десять лет назад, но не соответствуют тому, как разработчики на JavaScript пишут код сегодня.
В этом посте исследуются некоторые фундаментальные проблемы, которые я вижу в Web streams, и предлагается альтернативный подход, построенный вокруг примитивов языка JavaScript, демонстрирующий, что возможно нечто лучшее.
В тестах эта альтернатива может работать от 2 до 120 раз быстрее, чем Web streams, в каждой среде выполнения, где я её тестировал (включая Cloudflare Workers, Node.js, Deno, Bun и все основные браузеры). Улучшения обусловлены не хитрыми оптимизациями, а принципиально другими проектными решениями, которые более эффективно используют современные возможности языка JavaScript. Я не стремлюсь принизить предыдущую работу; я хочу начать разговор о том, что может прийти дальше.
Исходные предпосылки
Стандарт Streams разрабатывался между 2014 и 2016 годами с амбициозной целью предоставить "API для создания, композиции и потребления потоков данных, которые эффективно сопоставляются с низкоуровневыми примитивами ввода-вывода." До Web streams веб-платформа не имела стандартного способа работы с потоковыми данными.
В то время у Node.js уже был собственный API для потоков, который также был портирован для работы в браузерах, но WHATWG решила не использовать его в качестве отправной точки, учитывая, что её устав обязывает учитывать только потребности веб-браузеров. Серверные среды выполнения приняли Web streams позже, после того как Cloudflare Workers и Deno появились с поддержкой Web streams из коробки, а совместимость между средами выполнения стала приоритетом.
Дизайн Web streams предшествовал появлению асинхронных итераторов в JavaScript. Синтаксис for await...of появился только в ES2018, спустя два года после первоначального утверждения стандарта Streams. Это время означало, что API изначально не могло использовать то, что в итоге стало идиоматичным способом потребления асинхронных последовательностей в JavaScript. Вместо этого спецификация ввела собственную модель получения читателя/писателя, и это решение повлияло на каждый аспект API.
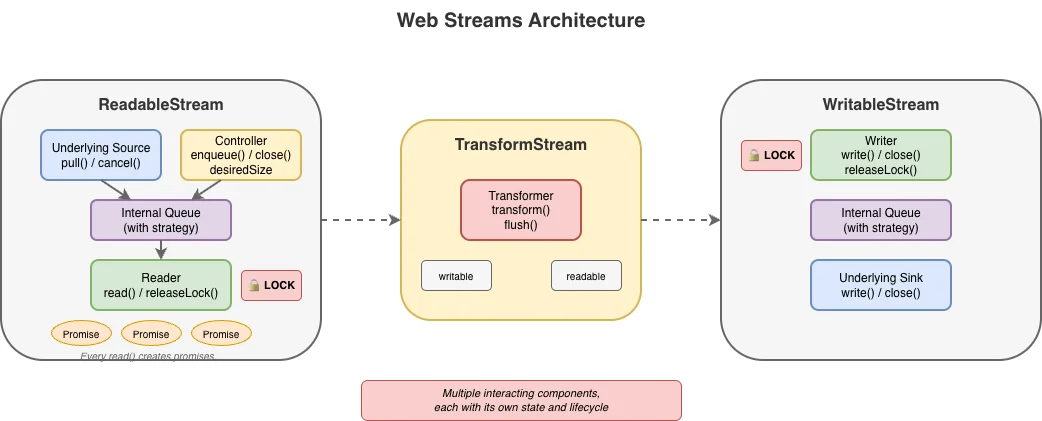
Излишняя формальность для обычных операций
Самая распространённая задача при работе с потоками — чтение их до завершения. Вот как это выглядит с Web streams:
// Сначала получаем читатель, который даёт эксклюзивную блокировку
// на поток...
const reader = stream.getReader();
const chunks = [];
try {
// Затем мы повторно вызываем read и ожидаем (await) возвращённое
// обещание, чтобы получить порцию данных или сигнал о завершении.
while (true) {
const { value, done } = await reader.read();
if (done) break;
chunks.push(value);
}
} finally {
// В конце мы снимаем блокировку с потока
reader.releaseLock();
}Вы можете предположить, что этот шаблон присущ потоковой передаче по своей природе. Это не так. Получение читателя, управление блокировкой и протокол { value, done } — всё это лишь проектные решения, а не требования. Это артефакты того, как и когда была написана спецификация Web streams. Асинхронная итерация существует именно для обработки последовательностей, поступающих с течением времени, но асинхронной итерации ещё не существовало, когда писалась спецификация потоков. Эта сложность — чисто накладные расходы API, а не фундаментальная необходимость.
Рассмотрим альтернативный подход, учитывая, что Web streams теперь поддерживают for await...of:
const chunks = [];
for await (const chunk of stream) {
chunks.push(chunk);
}Это лучше, поскольку шаблонного кода стало намного меньше, но проблема решена не полностью. Асинхронная итерация была добавлена поверх API, который для неё не проектировался, и это заметно. Такие возможности, как BYOB (принеси свой собственный буфер), недоступны через итерацию. Подспудная сложность с читателями, блокировками и контроллерами всё ещё здесь, просто скрыта. Когда что-то идёт не так или когда требуются дополнительные возможности API, разработчики снова погружаются в дебри оригинального API, пытаясь понять, почему их поток "заблокирован", почему releaseLock() не сработал, как ожидалось, или выискивая узкие места в коде, который они не контролируют.
Проблема с блокировками
Web streams используют модель блокировок, чтобы предотвратить чередование чтений несколькими потребителями. Когда вы вызываете getReader(), поток блокируется. В заблокированном состоянии ничего другое не может читать из потока напрямую, направлять его через pipe или даже отменять — только код, который фактически удерживает читатель.
Это звучит разумно, пока вы не увидите, как легко всё ломается:
async function peekFirstChunk(stream) {
const reader = stream.getReader();
const { value } = await reader.read();
// Ой — забыли вызвать reader.releaseLock()
// И читатель больше не доступен, когда мы возвращаемся
return value;
}
const first = await peekFirstChunk(stream);
// TypeError: Cannot obtain lock — поток навсегда заблокирован
for await (const chunk of stream) { /* никогда не выполнится */ }Забыв о releaseLock(), вы навсегда ломаете поток. Свойство locked сообщает, что поток заблокирован, но не говорит почему, кем или даже остаётся ли блокировка ещё пригодной для использования. Перенаправление через pipe (pipeTo) внутренне захватывает блокировки, делая потоки непригодными для использования во время операций pipe способами, которые не являются очевидными.
Семантика освобождения блокировок при наличии ожидающих чтений также годами была неясной. Что происходит, если вы вызвали read(), но не ожидали (await) его, а затем вызвали releaseLock()? Спецификация недавно была уточнена — ожидающие чтения должны отменяться при освобождении блокировки, — но реализации различались, и код, полагавшийся на предыдущее неопределённое поведение, может ломаться.
Тем не менее, важно признать, что сама по себе блокировка — это не плохо. Она действительно служит важной цели — обеспечить корректное и упорядоченное потребление или производство данных приложениями. Ключевая сложность заключается в исходной ручной реализации с использованием API, таких как getReader() и releaseLock(). С появлением автоматического управления блокировками и читателями с помощью асинхронных итерируемых объектов, работа с блокировками с точки зрения пользователя стала намного проще.
Для разработчиков реализаций модель блокировок добавляет изрядное количество нетривиальной внутренней бухгалтерии. Каждая операция должна проверять состояние блокировки, необходимо отслеживать читателей, а взаимодействие между блокировками, отменой и состояниями ошибок создаёт матрицу граничных случаев, которые должны быть корректно обработаны.
BYOB: сложность без ощутимой выгоды
BYOB (принеси свой собственный буфер) был разработан, чтобы позволить разработчикам повторно использовать буферы памяти при чтении из потоков — важная оптимизация, предназначенная для сценариев с высокой пропускной способностью. Идея здравая: вместо выделения новых буферов для каждой порции данных вы предоставляете свой буфер, и поток его заполняет.
На практике (и да, всегда можно найти исключения) BYOB редко используется с какой-либо измеримой пользой. API значительно сложнее, чем обычное чтение, он требует отдельного типа читателя (ReadableStreamBYOBReader) и других специализированных классов (например, ReadableStreamBYOBRequest), тщательного управления жизненным циклом буфера и понимания семантики отсоединения (detachment) ArrayBuffer. Когда вы передаёте буфер в BYOB-чтение, буфер становится отсоединённым — переданным потоку — и вы получаете обратно другое представление (view), потенциально над другой областью памяти. Эта модель на основе передачи (transfer) подвержена ошибкам и сбивает с толку:
const reader = stream.getReader({ mode: 'byob' });
const buffer = new ArrayBuffer(1024);
let view = new Uint8Array(buffer);
const result = await reader.read(view);
// 'view' теперь должен быть откреплен и непригоден к использованию
// (это не всегда так в каждой реализации)
// result.value — это НОВОЕ представление, возможно, в другой памяти
view = result.value; // Необходимо переприсвоитьBYOB также нельзя использовать с асинхронными итерациями или TransformStreams, поэтому разработчики, желающие чтения без копирования, вынуждены возвращаться к ручному циклу чтения.
Для реализаторов BYOB добавляет значительную сложность. Поток должен отслеживать ожидающие запросы BYOB, обрабатывать частичные заполнения, корректно управлять откреплением буферов и координировать действия между читателем BYOB и базовым источником. Web Platform Tests для читаемых байтовых потоков включают специальные тестовые файлы только для крайних случаев BYOB: открепленные буферы, некорректные представления, порядок ответов-после-постановки-в-очередь и многое другое.
BYOB в итоге оказывается сложным как для пользователей, так и для реализаторов, но на практике используется мало. Большинство разработчиков придерживаются чтения по умолчанию и принимают накладные расходы на выделение памяти.
Большинство пользовательских реализаций кастомных экземпляров ReadableStream обычно не утруждают себя всей церемонией, необходимой для корректной реализации поддержки как чтения по умолчанию, так и BYOB в одном потоке – и не без причины. Это сложно сделать правильно, и большую часть времени потребляющий код, как правило, будет откатываться на путь чтения по умолчанию. Пример ниже показывает, что должна делать «правильная» реализация. Она большая, сложная и подвержена ошибкам, и это не тот уровень сложности, с которым типичный разработчик хочет иметь дело:
new ReadableStream({
type: 'bytes',
async pull(controller: ReadableByteStreamController) {
if (offset >= totalBytes) {
controller.close();
return;
}
// Сначала проверьте запрос BYOB
const byobRequest = controller.byobRequest;
if (byobRequest) {
// === ПУТЬ BYOB ===
// Потребитель предоставил буфер — мы ДОЛЖНЫ заполнить его (или часть)
const view = byobRequest.view!;
const bytesAvailable = totalBytes - offset;
const bytesToWrite = Math.min(view.byteLength, bytesAvailable);
// Создаем представление в буфере потребителя и заполняем его
// не критично, но безопаснее, когда bytesToWrite != view.byteLength
const dest = new Uint8Array(
view.buffer,
view.byteOffset,
bytesToWrite
);
// Заполняем последовательными байтами (наш «источник данных»)
// Здесь может быть что угодно, что записывает в представление
for (let i = 0; i < bytesToWrite; i++) {
dest[i] = (offset + i) & 0xFF;
}
offset += bytesToWrite;
// Сигнализируем, сколько байт мы записали
byobRequest.respond(bytesToWrite);
} else {
// === ПУТЬ ЧТЕНИЯ ПО УМОЛЧАНИЮ ===
// Нет запроса BYOB — выделяем и ставим в очередь чанк
const bytesAvailable = totalBytes - offset;
const chunkSize = Math.min(1024, bytesAvailable);
const chunk = new Uint8Array(chunkSize);
for (let i = 0; i < chunkSize; i++) {
chunk[i] = (offset + i) & 0xFF;
}
offset += chunkSize;
controller.enqueue(chunk);
}
},
cancel(reason) {
console.log('Stream canceled:', reason);
}
});Когда среда выполнения предоставляет байтовый ReadableStream из самой себя, например, как body fetch Response, часто гораздо проще для самой среды выполнения предоставить оптимизированную реализацию чтения BYOB, но они все равно должны быть способны обрабатывать как стандартные, так и BYOB шаблоны чтения, и это требование привносит изрядную долю сложности.
Обратное давление: хорошо в теории, сломано на практике
Обратное давление – возможность медленного потребителя сигнализировать быстрому производителю замедлиться – это концепция первого класса в Web streams. В теории. На практике у модели есть серьезные недостатки.
Основной сигнал – desiredSize на контроллере. Он может быть положительным (требует данных), нулевым (на пределе емкости), отрицательным (превышена емкость) или null (закрыт). Производители должны проверять это значение и останавливать постановку в очередь, когда оно не положительное. Но нет ничего, что бы это обеспечивало: controller.enqueue() всегда успешно, даже когда desiredSize глубоко отрицательный.
new ReadableStream({
start(controller) {
// Ничто не мешает вам сделать это
while (true) {
controller.enqueue(generateData()); // desiredSize: -999999
}
}
});Реализации потоков могут и игнорируют обратное давление; а некоторые определенные спецификацией функции явно нарушают его. tee(), например, создает две ветки из одного потока. Если одна ветка читает быстрее другой, данные накапливаются во внутреннем буфере без ограничения. Быстрый потребитель может вызвать неограниченный рост памяти, пока медленный потребитель догоняет, и нет способа настроить это или отказаться, кроме как отменить медленную ветку.
Web streams действительно предоставляют четкие механизмы для настройки поведения обратного давления в виде опции highWaterMark и настраиваемых расчетов размера, но их так же легко игнорировать, как и desiredSize, и многие приложения просто не обращают на них внимания.
Те же проблемы существуют на стороне WritableStream. У WritableStream есть highWaterMark и desiredSize. Существует промис writer.ready, на который производители данных должны обращать внимание, но часто не делают этого.
const writable = getWritableStreamSomehow();
const writer = writable.getWriter();
// Производители должны ждать writer.ready
// Это промис, который, когда разрешается, указывает, что
// внутреннее обратное давление writable очищено и
// можно записывать больше данных
await writer.ready;
await writer.write(...);Для реализаторов обратное давление добавляет сложность, не предоставляя гарантий. Механизм для отслеживания размеров очереди, вычисления desiredSize и вызова pull() в нужное время должен быть реализован корректно. Однако, поскольку эти сигналы являются рекомендательными, вся эта работа на самом деле не предотвращает проблемы, которые должно решать обратное давление.
Скрытая стоимость промисов
Спецификация Web streams требует создания промисов во множестве точек, часто на горячих путях и часто невидимых для пользователей. Каждый вызов read() не просто возвращает промис; внутри реализация создает дополнительные промисы для управления очередью, координации pull() и сигнализации обратного давления.
Эти накладные расходы обусловлены зависимостью спецификации от промисов для управления буферами, завершения операций и сигналов обратного давления. Хотя часть из них зависит от реализации, многое неизбежно, если следовать спецификации как написано. Для высокочастотной потоковой передачи – кадров видео, сетевых пакетов, данных в реальном времени – эти накладные расходы значительны.
Проблема усугубляется в конвейерах. Каждый TransformStream добавляет еще один уровень механизма промисов между источником и приемником. В спецификации не определены синхронные быстрые пути, поэтому даже когда данные доступны немедленно, механизм промисов все равно работает.
Для реализаторов такая промис-ориентированная архитектура ограничивает возможности оптимизации. Спецификация требует определенного порядка разрешения промисов, что затрудняет пакетирование операций или пропуск ненужных асинхронных границ без риска тонких нарушений соответствия. Существует множество скрытых внутренних оптимизаций, которые реализаторы делают, но они могут быть сложными и трудными для правильной реализации.
Пока я писал этот пост в блоге, Мальте Убл из Vercel опубликовал свой собственный пост в блоге, описывающий некоторые исследовательские работы, которые Vercel проводила по улучшению производительности реализации Web streams в Node.js. В том посте они обсуждают ту же фундаментальную проблему оптимизации производительности, с которой сталкивается каждая реализация Web streams:
"Или рассмотрим pipeTo(). Каждый чанк проходит через полную цепочку Promise: read, write, проверка обратного давления, повтор. Объект результата {value, done} выделяется для каждого чтения. Распространение ошибок создает дополнительные ветви Promise.
Ничто из этого не является неправильным. Эти гарантии важны в браузере, где потоки пересекают границы безопасности, где семантика отмены должна быть герметичной, где вы не контролируете оба конца конвейера. Но на сервере, когда вы передаете React Server Components через три преобразования чанками по 1 КБ, стоимость складывается.
Мы провели бенчмаркинг нативного pipeThrough WebStreams: 630 МБ/с для чанков 1 КБ. Node.js pipeline() с таким же сквозным преобразованием: ~7 900 МБ/с. Это разница в 12 раз, и отличие почти полностью состоит из накладных расходов на выделение Promise и объектов." - Мальте Убл, https://vercel.com/blog/we-ralph-wiggumed-webstreams-to-make-them-10x-faster
В рамках своего исследования они подготовили набор предлагаемых улучшений для реализации веб-потоков в Node.js, которые позволят исключить промисы в определённых путях выполнения кода. Это может дать значительный прирост производительности — до 10 раз, что лишь подтверждает тезис: промисы, хоть и полезны, добавляют существенные накладные расходы. Как один из основных сопровождающих Node.js, я с нетерпением жду возможности помочь Мальте и ребятам из Vercel воплотить их предложенные улучшения!
В недавнем обновлении Cloudflare Workers я внес аналогичные изменения во внутренний конвейер данных, что позволило сократить количество создаваемых JavaScript-промисов в определённых сценариях приложения до 200 раз. Результатом стало улучшение производительности в этих приложениях на несколько порядков.
Реальные проблемы
Истощение ресурсов из-за неиспользованных тел
Когда fetch() возвращает ответ, тело представляет собой ReadableStream. Что произойдёт, если вы только проверите статус, но не потребите или не отмените тело? Ответ варьируется в зависимости от реализации, но распространённым исходом становится утечка ресурсов.
async function checkEndpoint(url) {
const response = await fetch(url);
return response.ok; // Тело никогда не потребляется и не отменяется
}
// В цикле это может исчерпать пулы соединений
for (const url of urls) {
await checkEndpoint(url);
}Такая практика приводила к исчерпанию пула соединений в приложениях Node.js, использующих undici (встроенную в Node.js реализацию fetch()), и аналогичные проблемы возникали в других средах выполнения. Поток сохраняет ссылку на базовое соединение, и без явного потребления или отмены соединение может висеть до сборки мусора — которая при нагрузке может произойти недостаточно быстро.
Проблема усугубляется API, которые неявно создают ветви потоков. Методы Request.clone() и Response.clone() выполняют неявную операцию tee() над потоком тела — деталь, которую легко упустить. Код, который клонирует запрос для логирования или логики повторных попыток, может неосознанно создавать разветвлённые потоки, требующие независимого потребления, тем самым умножая нагрузку по управлению ресурсами.
Безусловно, подобные проблемы являются ошибками реализации. Утечка соединения определённо была тем, что undici нужно было исправить в своей собственной реализации, но сложность спецификации не облегчает решение таких проблем.
"Клонирование потоков в реализации fetch() Node.js сложнее, чем кажется. Когда вы клонируете тело запроса или ответа, вы вызываете tee() — которая разделяет один поток на две ветви, и обе необходимо потребить. Если один потребитель читает быстрее другого, данные буферизуются в памяти без ограничений, ожидая медленную ветвь. Если вы не потребляете обе ветви должным образом, происходит утечка базового соединения. Координация, требуемая между двумя читателями, разделяющими один источник, делает лёгким случайный сбой исходного запроса или исчерпание пулов соединений. Это простой вызов API со сложной внутренней механикой, которую трудно реализовать правильно." - Маттео Колина, Ph.D. - Сооснователь и CTO Platformatic, Председатель Технического руководящего комитета Node.js
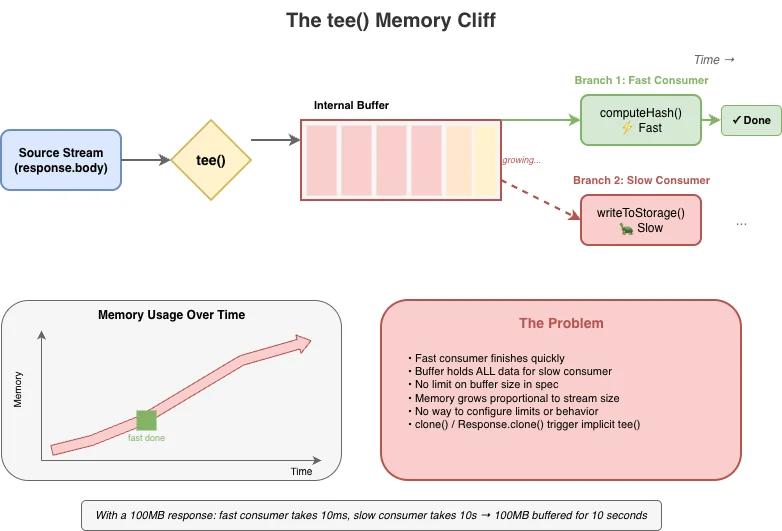
Падение с обрыва памяти tee()
tee() разделяет поток на две ветви. Это кажется простым, но реализация требует буферизации: если одна ветвь читается быстрее другой, данные должны где-то храниться, пока медленная ветвь не догонит.
const [forHash, forStorage] = response.body.tee();
// Вычисление хеша быстрое
const hash = await computeHash(forHash);
// Запись в хранилище медленная — тем временем весь поток
// может быть забуферизован в памяти, ожидая этой ветви
await writeToStorage(forStorage);Спецификация не устанавливает лимиты буфера для tee(). И, справедливости ради, спецификация позволяет реализациям выбирать любой способ реализации внутренних механизмов для tee() и других API, пока соблюдаются наблюдаемые нормативные требования спецификации. Но если реализация выбирает реализацию tee() именно тем способом, который описан в спецификации потоков, то tee() будет иметь встроенную проблему управления памятью, которую трудно обойти.
Разработчикам реализаций пришлось разрабатывать собственные стратегии борьбы с этим. Firefox изначально использовал подход на основе связного списка, который приводил к росту памяти O(n) пропорционально разнице в скорости потребления. В Cloudflare Workers мы выбрали реализацию модели общего буфера, где сигнал обратного давления передаётся от самого медленного потребителя, а не от самого быстрого.
Пробелы в передаче обратного давления в Transform
TransformStream создаёт пару readable/writable с логикой обработки между ними. Функция transform() выполняется при записи, а не при чтении. Обработка трансформации происходит активно по мере поступления данных, независимо от того, готов ли какой-либо потребитель. Это приводит к ненужной работе при медленных потребителях, а сигнализация обратного давления между двумя сторонами имеет пробелы, которые могут вызвать неограниченную буферизацию под нагрузкой. Ожидается, что согласно спецификации, поставщик данных, подвергаемых трансформации, следит за сигналом writer.ready на записываемой стороне трансформации, но довольно часто производители просто игнорируют его.
Если операция transform() трансформации синхронна и всегда немедленно ставит выходные данные в очередь, она никогда не передаёт обратное давление обратно на записываемую сторону, даже когда последующий потребитель медленный. Это следствие дизайна спецификации, которое многие разработчики полностью упускают из виду. В браузерах, где есть только один пользователь и обычно активно лишь небольшое количество потоковых конвейеров в любой момент времени, такая "подводная мина" часто не имеет последствий, но она оказывает серьёзное влияние на производительность на стороне сервера или на грани в средах выполнения, обслуживающих тысячи одновременных запросов.
const fastTransform = new TransformStream({
transform(chunk, controller) {
// Синхронная постановка в очередь — это никогда не создаёт обратного давления
// Даже если буфер читаемой стороны полон, это сработает
controller.enqueue(processChunk(chunk));
}
});
// Пропускаем быстрый источник через трансформацию к медленному приёмнику
fastSource
.pipeThrough(fastTransform)
.pipeTo(slowSink); // Буфер растёт без ограниченийЧто должны делать TransformStreams, так это проверять обратное давление на контроллере и использовать промисы для передачи его обратно писателю:
const fastTransform = new TransformStream({
async transform(chunk, controller) {
if (controller.desiredSize <= 0) {
// Ждать, пока обратное давление как-то исчезнет
}
controller.enqueue(processChunk(chunk));
}
});Однако сложность здесь в том, что у TransformStreamDefaultController нет механизма промиса готовности, как у Writer; поэтому реализации TransformStream пришлось бы реализовывать механизм опроса для периодической проверки, когда controller.desiredSize снова станет положительным.
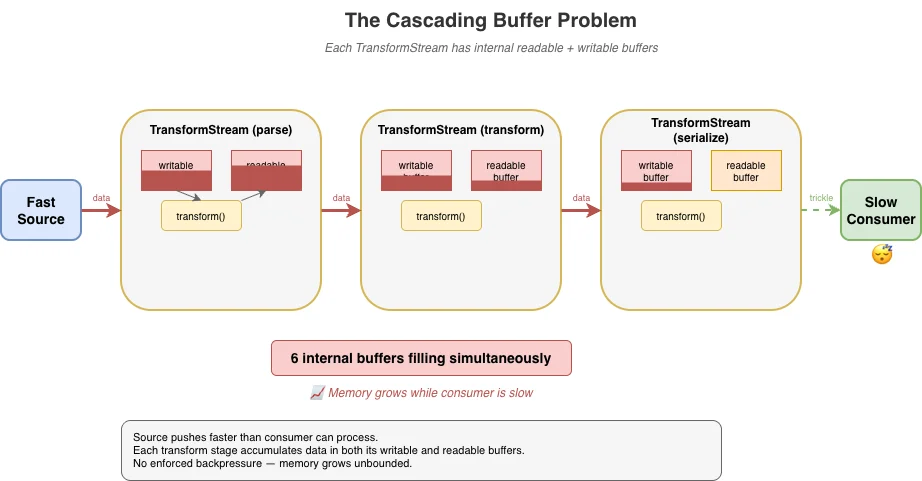
Проблема усугубляется в конвейерах. Когда вы связываете несколько трансформаций — например, разбор, преобразование, затем сериализацию — каждый TransformStream имеет свои собственные внутренние буферы для чтения и записи. Если разработчики реализаций строго следуют спецификации, данные каскадом проходят через эти буферы в ориентированной на push манере: источник проталкивает в трансформацию A, которая проталкивает в трансформацию B, которая проталкивает в трансформацию C, при этом каждая накапливает данные в промежуточных буферах, прежде чем конечный потребитель даже начал вытягивать. При трёх трансформациях у вас может быть шесть внутренних буферов, заполняющихся одновременно.
Ожидается, что разработчики, использующие API потоков, будут помнить об использовании опций вроде highWaterMark при создании источников, трансформаций и записываемых назначений, но часто они либо забывают, либо просто игнорируют это.
source
.pipeThrough(parse) // буферы заполняются...
.pipeThrough(transform) // больше буферов заполняется...
.pipeThrough(serialize) // ещё больше буферов...
.pipeTo(destination); // потребитель ещё не началРазработчики реализаций нашли способы оптимизировать конвейеры трансформаций, сворачивая идентичные трансформации, замыкая ненаблюдаемые пути, откладывая выделение буферов или переключаясь на нативный код, который вообще не запускает JavaScript. Deno, Bun и Cloudflare Workers успешно реализовали оптимизации "нативного пути", которые помогают устранить большую часть накладных расходов, а недавнее исследование Vercel fast-webstreams работает над аналогичными оптимизациями для Node.js. Но сами оптимизации добавляют значительную сложность и всё ещё не могут полностью избежать присущей TransformStream ориентированной на push модели.
Срыв сборки мусора (GC thrashing) при серверном рендеринге
Потоковый серверный рендеринг (SSR) — особенно болезненный случай. Типичный SSR-поток может рендерить тысячи небольших HTML-фрагментов, каждый из которых проходит через механизм потоков:
// Каждый компонент помещает в очередь небольшой фрагмент
function renderComponent(controller) {
controller.enqueue(encoder.encode(`<div>${content}</div>`));
}
// Сотни компонентов = сотни вызовов enqueue
// Каждый из них запускает внутреннюю механику промисов
for (const component of components) {
renderComponent(controller); // Создаются промисы, выделяются объекты
}Каждый фрагмент означает создание промисов для вызовов read(), промисов для координации обратного давления, выделение промежуточных буферов и результирующих объектов { value, done } – большинство из которых почти мгновенно становятся мусором.
Под нагрузкой это создает давление на сборщик мусора (GC), которое может разрушить пропускную способность. Движок JavaScript тратит значительное время на сбор недолговечных объектов вместо полезной работы. Задержки становятся непредсказуемыми, поскольку паузы GC прерывают обработку запросов. Я видел рабочие нагрузки SSR, где сборка мусора составляла значительную часть (до 50% и более) от общего времени ЦП на запрос. Это время, которое можно было бы потратить на фактический рендеринг контента.
Ирония в том, что потоковый SSR призван повысить производительность за счет инкрементальной отправки контента. Но накладные расходы механизма потоков могут свести на нет эти преимущества, особенно для страниц со множеством мелких компонентов. Разработчики иногда обнаруживают, что буферизация всего ответа на самом деле быстрее, чем потоковая передача через Web Streams, что полностью обесценивает первоначальную цель.
Беговая дорожка оптимизаций
Для достижения приемлемой производительности каждая крупная среда выполнения прибегла к нестандартным внутренним оптимизациям для Web Streams. Node.js, Deno, Bun и Cloudflare Workers разработали свои собственные обходные пути. Это особенно верно для потоков, подключенных к системному вводу-выводу, где большая часть механизмов ненаблюдаема и может быть сокращена.
Поиск таких возможностей для оптимизации сам по себе может быть значительной задачей. Это требует сквозного понимания спецификации, чтобы определить, какие поведения наблюдаемы, а какие можно безопасно опустить. Даже в этом случае часто неясно, соответствует ли данная оптимизация спецификации. Разработчикам реализаций приходится принимать субъективные решения о том, какую семантику можно ослабить без нарушения совместимости. Это создает огромное давление на команды разработчиков сред выполнения, которые вынуждены становиться экспертами по спецификациям только для достижения приемлемой производительности.
Эти оптимизации сложно реализовать, они часто подвержены ошибкам и приводят к несоответствию поведения в разных средах выполнения. Оптимизация "Direct Streams" в Bun сознательно и наблюдаемо использует нестандартный подход, полностью обходя большую часть механизмов спецификации. IdentityTransformStream в Cloudflare Workers предоставляет быстрый путь для сквозных преобразований, но является специфичным для Workers и реализует поведение, не являющееся стандартным для TransformStream. У каждой среды выполнения есть свой набор трюков, и естественная тенденция ведет к нестандартным решениям, потому что часто это единственный способ сделать что-то быстрым.
Эта фрагментация вредит переносимости. Код, который хорошо работает в одной среде выполнения, может вести себя иначе (или плохо) в другой, даже если использует "стандартные" API. Бремя сложности для разработчиков реализаций значительно, а тонкие различия в поведении создают трение для разработчиков, пытающихся писать кроссплатформенный код, особенно для тех, кто поддерживает фреймворки, которые должны эффективно работать во многих средах выполнения.
Также необходимо подчеркнуть, что многие оптимизации возможны только в тех частях спецификации, которые ненаблюдаемы для пользовательского кода. Альтернатива, такая как "Direct Streams" от Bun, — это сознательное отклонение от наблюдаемого поведения, определенного в спецификации. Это означает, что оптимизации часто кажутся "неполными". Они работают в одних сценариях, но не в других, в одних средах выполнения, но не в других, и т.д. Каждый такой случай добавляет к общей неустойчивой сложности подхода Web Streams, поэтому большинство разработчиков реализаций редко прилагают значительные усилия для дальнейшего улучшения своих реализаций потоков после прохождения тестов на соответствие.
Разработчикам реализаций не придётся преодолевать эти препятствия. Когда вы обнаруживаете, что вам нужно ослабить или обойти семантику спецификации только для достижения разумной производительности, это признак того, что с самой спецификацией что-то не так. Хорошо спроектированный потоковый API должен быть эффективным по умолчанию, а не требовать от каждой среды выполнения изобретать свои собственные люки для побега.
Бремя соответствия
Сложная спецификация создает сложные крайние случаи. Web Platform Tests для потоков охватывают более 70 файлов с тестами, и хотя всестороннее тестирование — это хорошо, показательно то, что именно нужно тестировать.
Рассмотрим некоторые из более сложных тестов, которые реализации должны проходить:
-
Защита от прототипного загрязнения: Один тест изменяет
Object.prototype.then, чтобы перехватывать разрешения промисов, а затем проверяет, что операцииpipeTo()иtee()не просачивают внутренние значения через цепочку прототипов. Это проверяет свойство безопасности, которое существует только потому, что насыщенная промисами внутренняя структура спецификации создает поверхность для атаки. -
Отклонение памяти WebAssembly: BYOB-чтения должны явно отклонять ArrayBuffers, основанные на памяти WebAssembly, которые выглядят как обычные буферы, но не могут быть переданы. Этот крайний случай существует из-за модели открепления буферов в спецификации — более простому API не нужно было бы его обрабатывать.
-
Регрессия сбоев из-за конфликтов в машине состояний: Один тест специально проверяет, что вызов
byobRequest.respond()послеenqueue()не приводит к сбою среды выполнения. Эта последовательность создает конфликт во внутренней машине состояний —enqueue()выполняет ожидающее чтение и должен аннулироватьbyobRequest, но реализации должны корректно обрабатывать последующийrespond(), а не повреждать память, чтобы покрыть весьма вероятную возможность того, что разработчики используют сложный API неправильно.
Это не надуманные сценарии, придуманные авторами тестов на пустом месте. Они являются следствием дизайна спецификации и отражают реальные ошибки.
Для разработчиков реализаций прохождение набора тестов WPT означает обработку запутанных крайних случаев, с которыми большинство прикладного кода никогда не столкнется. Тесты кодируют не только "счастливый путь", но и полную матрицу взаимодействий между читателями, писателями, контроллерами, очередями, стратегиями и механизмом промисов, который связывает их все.
Более простой API означал бы меньше концепций, меньше взаимодействий между концепциями и меньше крайних случаев, которые нужно правильно реализовать, что привело бы к большей уверенности в том, что реализации действительно ведут себя согласованно.
Вывод
Web Streams сложны как для пользователей, так и для разработчиков реализаций. Проблемы со спецификацией — это не баги. Они возникают при использовании API именно так, как он задуман. Это не проблемы, которые можно решить исключительно за счет постепенных улучшений. Это следствия фундаментальных дизайнерских решений. Чтобы улучшить ситуацию, нам нужны другие основы.
Лучший потоковый API возможен
После многократной реализации спецификации Web Streams в разных средах выполнения и личного ознакомления с болевыми точками, я решил, что пришло время исследовать, как мог бы выглядеть лучший, альтернативный потоковый API, если бы он проектировался сегодня с чистого листа.
Далее следует proof of concept: это не готовый стандарт, не готовую к производству библиотеку, и даже не обязательно конкретное предложение о чем-то новом, а скорее отправная точка для обсуждения, демонстрирующая, что проблемы Web Streams не являются неотъемлемой частью потоковой передачи как таковой; они являются следствием конкретных дизайнерских решений, которые могли быть приняты иначе. Менее важно, является ли этот конкретный API правильным ответом, чем то, вызывает ли он продуктивную дискуссию о том, что нам на самом деле нужно от потокового примитива.
Что такое поток?
Прежде чем углубляться в дизайн API, стоит спросить: что такое поток?
По своей сути, поток — это просто последовательность данных, которая поступает с течением времени. У вас нет всех данных сразу. Вы обрабатываете их по мере поступления.
Возможно, каналы Unix (pipes) — это самое чистое выражение этой идеи:
cat access.log | grep "error" | sort | uniq -cДанные текут слева направо. Каждая ступень читает ввод, выполняет свою работу, записывает вывод. Нет необходимости получать считыватель канала, нет контроллера для управления. Если последующая ступень медленная, предыдущие ступени также естественным образом замедляются. Обратное давление неявно заложено в модели, а не является отдельным механизмом, который нужно изучать (или игнорировать).
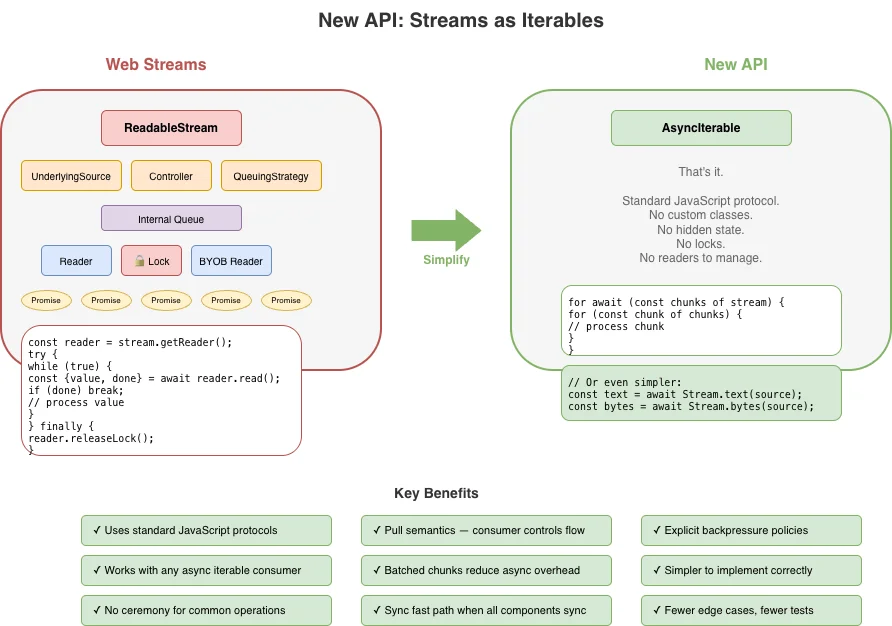
В JavaScript естественным примитивом для "последовательности вещей, которые поступают с течением времени" уже является встроенная в язык концепция: асинхронный итерируемый объект (async iterable). Вы потребляете его с помощью for await...of. Вы прекращаете потребление, прекращая итерацию.
Вот интуиция, которую новый API стремится сохранить: потоки должны ощущаться как итерация, потому что они ею и являются. Сложность веб-потоков – ридеры, райтеры, контроллеры, блокировки, стратегии очередей – затемняет эту фундаментальную простоту. Лучший API должен делать простой случай простым и добавлять сложность только там, где она действительно необходима.
Принципы проектирования
Я построил концептуальную альтернативу, основываясь на другом наборе принципов.
Потоки – это итерируемые объекты.
Никакого специального класса ReadableStream со скрытым внутренним состоянием. Читаемый поток – это просто AsyncIterable<Uint8Array[]>. Вы потребляете его с помощью for await...of. Не нужно захватывать ридеры, не нужно управлять блокировками.
Сквозные преобразования по запросу (Pull-through)
Преобразования не выполняются, пока потребитель не запросит данные. Нет eager evaluation (жадных вычислений), нет скрытой буферизации. Данные передаются по требованию от источника, через преобразования, к потребителю. Если вы прекратите итерацию, обработка остановится.
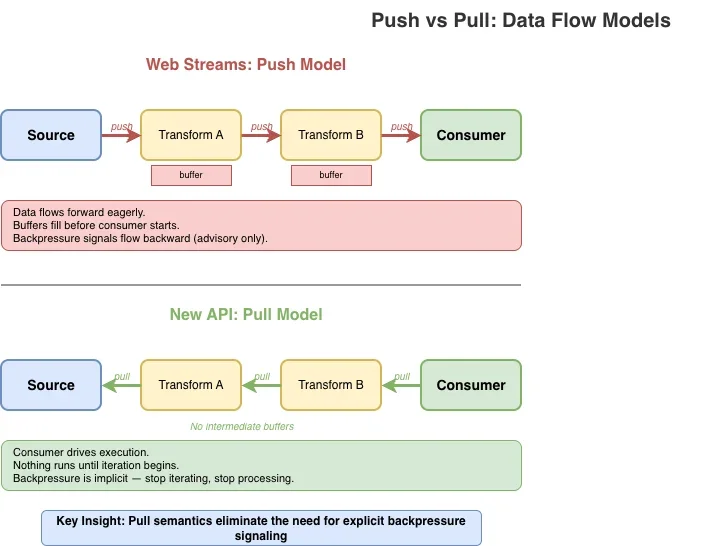
Явное обратное давление
Обратное давление по умолчанию строгое. Когда буфер заполнен, операции записи отклоняются, а не молча накапливаются. Вы можете настроить альтернативные политики – блокировать, пока не освободится место, отбрасывать самые старые или самые новые данные – но этот выбор должен быть явным. Больше никакого скрытого роста потребления памяти.
Пакетные чанки
Вместо того чтобы возвращать один чанк за итерацию, потоки возвращают Uint8Array[]: массивы чанков. Это распределяет асинхронные накладные расходы на несколько чанков, уменьшая создание промисов и задержки микрозадач в критических участках кода.
Только байты
API работает исключительно с байтами (Uint8Array). Строки автоматически кодируются в UTF-8. Нет дихотомии "поток значений" и "поток байтов". Если вы хотите передавать произвольные JavaScript-значения, используйте асинхронные итерируемые объекты напрямую. Хотя API использует Uint8Array, он рассматривает чанки как непрозрачные данные. Нет частичного потребления, нет паттернов BYOB, нет операций на уровне байтов внутри самой механики потоков. Чанки поступают, чанки выходят, неизменные, если преобразование явно их не модифицирует.
Синхронные быстрые пути важны
API признаёт, что синхронные источники данных и необходимы, и распространены. Приложение не должно быть вынуждено всегда принимать производительностные издержки асинхронного планирования просто потому, что это единственный предоставленный вариант. В то же время смешивание синхронной и асинхронной обработки может быть опасным. Синхронные пути должны всегда быть опцией и всегда быть явными.
Новый API в действии
Создание и потребление потоков
В веб-потоках создание простой пары производитель/потребитель требует TransformStream, ручного кодирования и осторожного управления блокировками:
const { readable, writable } = new TransformStream();
const enc = new TextEncoder();
const writer = writable.getWriter();
await writer.write(enc.encode("Hello, World!"));
await writer.close();
writer.releaseLock();
const dec = new TextDecoder();
let text = '';
for await (const chunk of readable) {
text += dec.decode(chunk, { stream: true });
}
text += dec.decode();Даже эта относительно чистая версия требует: TransformStream, ручной TextEncoder и TextDecoder, и явного освобождения блокировки.
Вот эквивалент с новым API:
import { Stream } from 'new-streams';
// Создаём push-поток
const { writer, readable } = Stream.push();
// Записываем данные — обратное давление применяется
await writer.write("Hello, World!");
await writer.end();
// Потребляем как текст
const text = await Stream.text(readable);Readable-объект – это просто асинхронный итерируемый объект. Вы можете передать его любой функции, которая ожидает такой объект, включая Stream.text(), которая собирает и декодирует весь поток.
Writer имеет простой интерфейс: write(), writev() для пакетной записи, end() для сигнала завершения и abort() для ошибок. По сути, это всё.
Writer – это не конкретный класс. Любой объект, реализующий write(), end() и abort(), может быть writer'ом, что упрощает адаптацию существующих API или создание специализированных реализаций без наследования. Нет сложного протокола UnderlyingSink с колбэками start(), write(), close(), and abort() , которые должны координироваться через контроллер, чей жизненный цикл и состояние независимы от WritableStream, к которому он привязан.
Вот простой writer в памяти, который собирает все записанные данные:
// Минимальная реализация writer'а — просто объект с методами
function createBufferWriter() {
const chunks = [];
let totalBytes = 0;
let closed = false;
const addChunk = (chunk) => {
chunks.push(chunk);
totalBytes += chunk.byteLength;
};
return {
get desiredSize() { return closed ? null : 1; },
// Асинхронные варианты
write(chunk) { addChunk(chunk); },
writev(batch) { for (const c of batch) addChunk(c); },
end() { closed = true; return totalBytes; },
abort(reason) { closed = true; chunks.length = 0; },
// Синхронные варианты возвращают boolean (true = принято)
writeSync(chunk) { addChunk(chunk); return true; },
writevSync(batch) { for (const c of batch) addChunk(c); return true; },
endSync() { closed = true; return totalBytes; },
abortSync(reason) { closed = true; chunks.length = 0; return true; },
getChunks() { return chunks; }
};
}
// Используем его
const writer = createBufferWriter();
await Stream.pipeTo(source, writer);
const allData = writer.getChunks();Нет базового класса для наследования, нет абстрактных методов для реализации, нет контроллера для координации. Просто объект с нужной структурой.
Сквозные преобразования по запросу
В рамках нового дизайна API преобразования не должны выполнять никакой работы, пока данные не потребляются. Это фундаментальный принцип.
// Ничего не выполняется, пока не начнётся итерация
const output = Stream.pull(source, compress, encrypt);
// Преобразования выполняются по мере итерации
for await (const chunks of output) {
for (const chunk of chunks) {
process(chunk);
}
}Stream.pull() создаёт ленивый пайплайн. Преобразования compress и encrypt не запускаются, пока вы не начнёте итерировать output. Каждая итерация по запросу проталкивает данные через пайплайн.
Это фундаментально отличается от pipeThrough() веб-потоков, который начинает активно перекачивать данные из источника в преобразование, как только вы настраиваете пайплайн. Семантика pull означает, что вы контролируете, когда происходит обработка, и остановка итерации останавливает обработку.
Преобразования могут быть stateless (без состояния) или stateful (с состоянием). Stateless-преобразование – это просто функция, которая принимает чанки и возвращает преобразованные чанки:
// Stateless-преобразование — чистая функция
// Получает чанки или null (сигнал завершения)
const toUpperCase = (chunks) => {
if (chunks === null) return null; // Конец потока
return chunks.map(chunk => {
const str = new TextDecoder().decode(chunk);
return new TextEncoder().encode(str.toUpperCase());
});
};
// Используем напрямую
const output = Stream.pull(source, toUpperCase);Stateful-преобразования – это простые объекты с функциями-членами, которые сохраняют состояние между вызовами:
// Stateful transform — a generator that wraps the source
function createLineParser() {
// Helper to concatenate Uint8Arrays
const concat = (...arrays) => {
const result = new Uint8Array(arrays.reduce((n, a) => n + a.length, 0));
let offset = 0;
for (const arr of arrays) { result.set(arr, offset); offset += arr.length; }
return result;
};
return {
async *transform(source) {
let pending = new Uint8Array(0);
for await (const chunks of source) {
if (chunks === null) {
// Flush: yield any remaining data
if (pending.length > 0) yield [pending];
continue;
}
// Concatenate pending data with new chunks
const combined = concat(pending, ...chunks);
const lines = [];
let start = 0;
for (let i = 0; i < combined.length; i++) {
if (combined[i] === 0x0a) { // newline
lines.push(combined.slice(start, i));
start = i + 1;
}
}
pending = combined.slice(start);
if (lines.length > 0) yield lines;
}
}
};
}
const output = Stream.pull(source, createLineParser());Для преобразований, которым требуется очистка при прерывании, добавьте обработчик прерывания:
// Stateful transform with resource cleanup
function createGzipCompressor() {
// Hypothetical compression API...
const deflate = new Deflater({ gzip: true });
return {
async *transform(source) {
for await (const chunks of source) {
if (chunks === null) {
// Flush: finalize compression
deflate.push(new Uint8Array(0), true);
if (deflate.result) yield [deflate.result];
} else {
for (const chunk of chunks) {
deflate.push(chunk, false);
if (deflate.result) yield [deflate.result];
}
}
}
},
abort(reason) {
// Clean up compressor resources on error/cancellation
}
};
}Для реализующих сторон: здесь нет протокола Transformer с методами start(), transform(), flush() и координацией контроллера, передаваемой в класс TransformStream, у которого есть собственные скрытые механизмы конечных автоматов и буферизации. Преобразования — это просто функции или простые объекты: гораздо проще реализовать и тестировать.
Явные политики обратного давления
Когда ограниченный буфер заполняется и производитель хочет записать больше, есть лишь несколько вариантов действий:
-
Отклонить запись: отказаться принимать больше данных
-
Ждать: заблокироваться, пока не появится место
-
Отбросить старые данные: удалить уже буферизованное, чтобы освободить место
-
Отбросить новые данные: отбросить входящие данные
Вот и всё. Любой другой ответ — это либо вариация этих вариантов (например, "изменить размер буфера", что на самом деле просто откладывает выбор), либо предметно-ориентированная логика, которой не место в общем примитиве потоков. Веб-потоки в настоящее время по умолчанию всегда выбирают "Ждать".
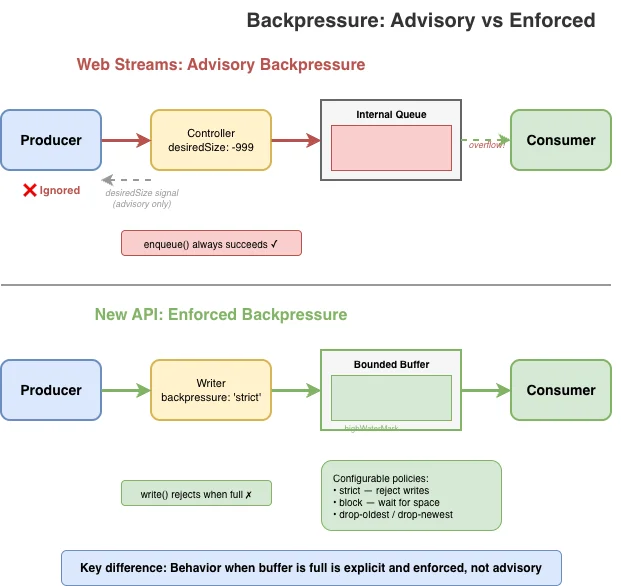
Новый API заставляет явно выбрать одну из этих четырёх политик:
-
strict(по умолчанию): Отклоняет запись, когда буфер заполнен и слишком много записей ожидают обработки. Ловит шаблоны "запись-и-забыть", где производители игнорируют обратное давление. -
block: Запись ожидает, пока в буфере не появится место. Используйте, когда доверяете производителю правильно ожидать завершения записи. -
drop-oldest: Удаляет самые старые буферизованные данные, чтобы освободить место. Полезно для живых лент, где устаревшие данные теряют ценность. -
drop-newest: Отбрасывает входящие данные при заполнении буфера. Полезно, когда вы хотите обработать то, что уже есть, не будучи перегруженными.
const { writer, readable } = Stream.push({
highWaterMark: 10,
backpressure: 'strict' // или 'block', 'drop-oldest', 'drop-newest'
});Больше не нужно надеяться, что производители будут сотрудничать. Выбранная вами политика определяет, что произойдёт при заполнении буфера.
Вот как ведёт себя каждая политика, когда производитель пишет быстрее, чем потребитель читает:
// strict: Ловит записи по принципу "запись-и-забыть", игнорирующие обратное давление
const strict = Stream.push({ highWaterMark: 2, backpressure: 'strict' });
strict.writer.write(chunk1); // ок (не ожидается)
strict.writer.write(chunk2); // ок (заполняет слоты буфера)
strict.writer.write(chunk3); // ок (в очереди на ожидание)
strict.writer.write(chunk4); // ок (буфер ожидания заполняется)
strict.writer.write(chunk5); // ошибка! слишком много ожидающих записей
// block: Ждать места (неограниченная очередь ожидания)
const blocking = Stream.push({ highWaterMark: 2, backpressure: 'block' });
await blocking.writer.write(chunk1); // ок
await blocking.writer.write(chunk2); // ок
await blocking.writer.write(chunk3); // ждёт, пока потребитель прочитает
await blocking.writer.write(chunk4); // ждёт, пока потребитель прочитает
await blocking.writer.write(chunk5); // ждёт, пока потребитель прочитает
// drop-oldest: Удалить старые данные, чтобы освободить место
const dropOld = Stream.push({ highWaterMark: 2, backpressure: 'drop-oldest' });
await dropOld.writer.write(chunk1); // ок
await dropOld.writer.write(chunk2); // ок
await dropOld.writer.write(chunk3); // ок, chunk1 удалён
// drop-newest: Отбросить входящие данные при заполнении
const dropNew = Stream.push({ highWaterMark: 2, backpressure: 'drop-newest' });
await dropNew.writer.write(chunk1); // ок
await dropNew.writer.write(chunk2); // ок
await dropNew.writer.write(chunk3); // тихо отброшенЯвные паттерны для множественных потребителей
// Share with explicit buffer management
const shared = Stream.share(source, {
highWaterMark: 100,
backpressure: 'strict'
});
const consumer1 = shared.pull();
const consumer2 = shared.pull(decompress);Вместо tee() со скрытым неограниченным буфером вы получаете явные примитивы для множественных потребителей. Stream.share() основан на подписке: потребители "тянут" из общего источника, и вы настраиваете лимиты буфера и политику обратного давления заранее.
Также есть Stream.broadcast() для сценариев с множественными потребителями, основанных на "проталкивании". Оба заставляют задуматься о том, что происходит, когда потребители работают с разной скоростью, потому что это реальная проблема, которую не следует скрывать.
Разделение синхронного/асинхронного
Не все задачи потоковой обработки связаны с вводом-выводом. Когда источник находится в памяти, а преобразования — чистые функции, асинхронная механика добавляет накладные расходы без пользы. Вы платите за координацию "ожидания", которая не приносит выгоды.
Новый API имеет полные параллельные синхронные версии: Stream.pullSync(), Stream.bytesSync(), Stream.textSync() и так далее. Если ваш источник и преобразования полностью синхронны, вы можете обработать весь конвейер без единого промиса.
// Async — когда источник или преобразования могут быть асинхронными
const textAsync = await Stream.text(source);
// Sync — когда все компоненты синхронны
const textSync = Stream.textSync(source);Вот полный синхронный конвейер – сжатие, преобразование и потребление с нулевыми асинхронными накладными расходами:
// Synchronous source from in-memory data
const source = Stream.fromSync([inputBuffer]);
// Synchronous transforms
const compressed = Stream.pullSync(source, zlibCompressSync);
const encrypted = Stream.pullSync(compressed, aesEncryptSync);
// Synchronous consumption — no promises, no event loop trips
const result = Stream.bytesSync(encrypted);Весь конвейер выполняется в одном стеке вызовов. Не создаётся промисов, не происходит планирования в очереди микрозадач, и нет нагрузки на сборщик мусора (GC) от недолговечной асинхронной механики. Для задач, ограниченных производительностью CPU, таких как разбор, сжатие или преобразование данных в памяти, это может быть значительно быстрее, чем эквивалентный код веб-потоков — который бы навязывал асинхронные границы даже когда каждый компонент синхронен.
У веб-потоков нет синхронного пути. Даже если ваш источник имеет готовые данные, а ваше преобразование — чистая функция, вы всё равно платите за создание промисов и планирование микрозадач при каждой операции. Промисы прекрасны для случаев, когда ожидание действительно необходимо, но оно не всегда необходимо. Новый API позволяет оставаться в синхронной среде, когда это вам нужно.
Соединение разрыва между этим подходом и веб-потоками
Подход на основе асинхронных итераторов обеспечивает естественный мост между этой альтернативной парадигмой и веб-потоками. При переходе от ReadableStream к этому новому подходу, простая передача readable на вход работает как и ожидается, когда ReadableStream настроен на отдачу байтов:
const readable = getWebReadableStreamSomehow();
const input = Stream.pull(readable, transform1, transform2);
for await (const chunks of input) {
// process chunks
}При адаптации к ReadableStream требуется немного больше работы, поскольку альтернативный подход отдаёт пакеты чанков, но слой адаптации так же прост и понятен:
async function* adapt(input) {
for await (const chunks of input) {
for (const chunk of chunks) {
yield chunk;
}
}
}
const input = Stream.pull(source, transform1, transform2);
const readable = ReadableStream.from(adapt(input));Как это решает реальные проблемы, упомянутые ранее
Непотреблённые тела (unconsumed bodies): Pull-семантика означает, что ничего не происходит, пока вы не начнёте итерацию. Никакого скрытого удержания ресурсов. Если вы не потребляете поток, нет фоновых механизмов, удерживающих соединения открытыми.
-
Провал в памяти от
tee():Stream.share()требует явной настройки буфера. Вы заранее выбираетеhighWaterMarkи политику противодавления (backpressure): больше никакого незаметного неограниченного роста, когда потребители работают на разных скоростях. -
Пробелы в противодавлении у преобразований (Transform backpressure gaps): Pull-through преобразования выполняются по требованию. Данные не каскадируют через промежуточные буферы; они текут только тогда, когда потребитель "тянет". Остановите итерацию — остановится и обработка.
-
Трэш сборщика мусора (GC thrashing) в SSR: Пакетные чанки (
Uint8Array[]) амортизируют накладные расходы асинхронности. Синхронные конвейеры черезStream.pullSync()полностью исключают аллокации промисов для CPU-нагруженных задач.
Производительность
Выбранный дизайн имеет последствия для производительности. Вот бенчмарки из референсной реализации этой возможной альтернативы в сравнении с веб-потоками (Node.js v24.x, Apple M1 Pro, усреднено по 10 запускам):
|
Сценарий |
Альтернатива |
Веб-потоки |
Разница |
|
Маленькие чанки (1KB × 5000) |
~13 ГБ/с |
~4 ГБ/с |
~3× быстрее |
|
Крошечные чанки (100B × 10000) |
~4 ГБ/с |
~450 МБ/с |
~8× быстрее |
|
Асинхронная итерация (8KB × 1000) |
~530 ГБ/с |
~35 ГБ/с |
~15× быстрее |
|
Цепочка из 3× преобразований (8KB × 500) |
~275 ГБ/с |
~3 ГБ/с |
~80–90× быстрее |
|
Высокочастотные (64B × 20000) |
~7.5 ГБ/с |
~280 МБ/с |
~25× быстрее |
Результат для цепочки преобразований особенно впечатляет: семантика pull-through устраняет промежуточную буферизацию, которая осложняет работу конвейеров веб-потоков. Вместо того чтобы каждый TransformStream жадно заполнял свои внутренние буферы, данные по требованию текут от потребителя к источнику.
Теперь, если быть честным, Node.js ещё не приложил значительных усилий для полной оптимизации производительности своей реализации веб-потоков. Вероятно, есть значительный простор для улучшения результатов производительности Node.js с помощью прикладных усилий по оптимизации критических участков. Тем не менее, запуск этих бенчмарков в Deno и Bun также показывает значительное улучшение производительности с этим альтернативным подходом на основе итераторов по сравнению с их реализациями веб-потоков.
Бенчмарки в браузерах (Chrome/Blink, усреднено по 3 запускам) также показывают стабильный прирост:
|
Сценарий |
Альтернатива |
Веб-потоки |
Разница |
|
Отправка чанков по 3KB |
~135 тыс. оп/с |
~24 тыс. оп/с |
~5–6× быстрее |
|
Отправка чанков по 100KB |
~24 тыс. оп/с |
~3 тыс. оп/с |
~7–8× быстрее |
|
Цепочка из 3 преобразований |
~4.6 тыс. оп/с |
~880 оп/с |
~5× быстрее |
|
Цепочка из 5 преобразований |
~2.4 тыс. оп/с |
~550 оп/с |
~4× быстрее |
|
Потребление через bytes() |
~73 тыс. оп/с |
~11 тыс. оп/с |
~6–7× быстрее |
|
Асинхронная итерация |
~1.1 млн оп/с |
~10 тыс. оп/с |
~40–100× быстрее |
Эти бенчмарки измеряют пропускную способность в контролируемых сценариях; реальная производительность зависит от вашего конкретного случая использования. Разница между приростом в Node.js и в браузере отражает различные пути оптимизации, которые каждая среда выбирает для веб-потоков.
Стоит отметить, что эти бенчмарки сравнивают чистую реализацию нового API на TypeScript/JavaScript с нативными (JavaScript/C++/Rust) реализациями веб-потоков в каждой среде выполнения. Референсная реализация нового API не подвергалась работам по оптимизации производительности; весь прирост полностью обусловлен дизайном. Нативная реализация, вероятно, показала бы дальнейшее улучшение.
Полученный выигрыш иллюстрирует, как сочетаются фундаментальные проектные решения: пакетная обработка амортизирует накладные расходы асинхронности, семантика pull устраняет промежуточную буферизацию, и свобода для реализаций использовать синхронные быстрые пути, когда данные доступны немедленно, — всё это вносит вклад.
"Мы многое сделали для улучшения производительности и согласованности в потоках Node, но есть что-то уникально мощное в том, чтобы начать с чистого листа. Подход новых потоков принимает современные реалии сред выполнения без груза наследия, и это открывает дверь к более простой, производительной и последовательной модели потоков." - Роберт Надь, член TSC Node.js и контрибьютор потоков Node.js
Что дальше
Я публикую это, чтобы начать обсуждение. Что я сделал правильно? Что упустил? Есть ли варианты использования, которые не вписываются в эту модель? Как бы выглядел путь миграции для этого подхода? Цель — собрать отзывы от разработчиков, которые почувствовали на себе сложности веб-потоков и имеют мнение о том, как должен выглядеть лучший API.
Попробуйте сами
Референсная реализация для этого альтернативного подхода уже доступна и находится по адресу https://github.com/jasnell/new-streams.
-
Справка по API: Полную документацию смотрите в API.md
-
Примеры: В директории samples есть рабочий код для распространённых паттернов
Я приветствую issues, обсуждения и pull requests. Если вы столкнулись с проблемами веб-потоков, которые я не охватил, или видите пробелы в этом подходе, дайте мне знать. Но, повторюсь, идея здесь не в том, чтобы сказать "Давайте все использовать эту блестящую новую штуку!"; а в том, чтобы начать обсуждение, которое выходит за рамки текущего статус-кво веб-потоков и возвращается к базовым принципам.
Веб-потоки были амбициозным проектом, который принёс потоковую передачу на веб-платформу, когда ничего другого не существовало. Люди, которые его проектировали, сделали разумный выбор с учётом ограничений 2014 года — до async iteration, до многих лет производственного опыта, который выявил крайние случаи.
Но с тех пор мы многому научились. JavaScript эволюционировал. Потоковый API, спроектированный сегодня, может быть проще, больше соответствовать языку и более явным в отношении важных вещей, таких как противодавление (backpressure) и поведение с множеством потребителей.