Cloudflare обрабатывает более миллиарда событий каждую секунду. Наша сеть охватывает более 330 городов в 120+ странах. За каждым HTTP-запросом, каждым вызовом Worker, каждой операцией чтения R2 стоят данные, и их много.
Долгие годы эти данные были не очень доступны. Они хранились в десятках производственных баз данных, кластерах ClickHouse, потоках Kafka, бакетах Google Cloud, наборах данных BigQuery и длинном хвосте пайплайнов. Чтобы ответить на простой вопрос вроде «Сколько доменов, зарегистрированных сегодня, входят в топ-100 по трафику?», аналитику Cloudflare нужно было знать, в какой системе спрашивать, какие учетные данные использовать, на каком языке писать запрос и являются ли просматриваемые данные семплированными, свежими или устаревшими на семь дней. В результате было трудно извлечь обоснованные инсайты из данных.
Чтобы решить эту проблему, мы создали два внутренних инструмента: Town Lake — единую платформу аналитики данных Cloudflare, и Skipper — AI-агента данных, работающего поверх нее. Town Lake — это единый SQL-интерфейс ко всему, что знает Cloudflare, а Skipper — это то, как любой сотрудник Cloudflare может задавать вопросы на простом английском и получать правильные, проверяемые ответы за секунды.
Это история о том, как мы создали оба инструмента.
Форма проблемы
Если вы когда-либо работали в компании, пережившей период гиперроста, вы знаете, как выглядит разрастание данных. У нас было несколько конкретных симптомов:
-
Слишком много разрозненных систем. Инженеру продукта, желающему изучить проблему клиента, возможно, придется запрашивать Postgres для метаданных учетной записи, ClickHouse для событий аналитики, BigQuery для сводок использования, R2 для сырых логов и топики Kafka для сигналов в реальном времени. Каждая система имела свои учетные данные, свой язык и свою политику хранения.
-
Семплированные данные. Это нормально для дашбордов, но не работает для таких областей, как биллинг. Наш пайплайн аналитики производит даунсемплинг для обработки более 700 млн событий в секунду. Это правильное поведение, когда нужно загрузить дашборд аналитики, но совершенно неправильное, когда вы пытаетесь вычислить использование, необходимое для выставления счета.
-
Внешние зависимости для внутренних данных. Части нашего предыдущего стека внутренней отчетности работали от внешних вендоров. Помимо стоимости, у нас была жесткая внешняя зависимость от другого облака для некоторых критически важных данных.
-
Никто не мог найти данные. Даже если у вас были все нужные учетные данные, нужно было знать, что правильная таблица для «Биллинговая Workers запросы по аккаунту» находится в конкретном кластере ClickHouse, в конкретной схеме, соединена с конкретной таблицей измерений Postgres, и что для соединения требуется неочевидная трансляция ID клиента. Было слишком много неписаных знаний.
У нас была и культурная проблема: исторически инфраструктура данных рассматривалась как бэк-офисная функция, обслуживающая бизнес, а не как критически важная инфраструктура сама по себе.
Чего мы хотели
Мы хотели создать одно место, где любой сотрудник компании с соответствующими разрешениями и необходимостью знать мог бы получить ответы на вопросы о Cloudflare: «Покажи топ-100 клиентов по выручке за последний квартал», «Перечисли все события оценки ML в Bot Management с оценкой > 0,9 за последние 48 часов с определенного ASN», «Найди топ-100 тикетов поддержки по биллингу от клиентов, потративших >$100» и т.д.
Мы хотели, чтобы это место предоставляло свежие, точные, несемплированные данные для запросов, которым это нужно (например, биллинг или расследования безопасности), и быстрые, семплированные данные для запросов, которым это не нужно (например, дашборды или исследование).
Мы хотели встроенную безопасность и управление, с автоматическим обнаружением личной информации (PII) и блокировкой чувствительных таблиц по умолчанию. Весь доступ должен быть аудируемым и иметь временные разрешения, чтобы пользователи могли получать доступ к данным только тогда, когда они активно работают над задачами, требующими этого.
Мы хотели, чтобы он был построен на собственной платформе Cloudflare: R2 для хранения, Workers для вычислений, Cloudflare Access для аутентификации, Workflows для оркестрации. Если мы собирались сделать крупную инвестицию в нашу инфраструктуру данных, она должна была быть построена на тех же продуктах, которые мы продаем клиентам.
И в конечном итоге мы хотели интерфейс, не требующий знания SQL. Цель состояла в том, чтобы дать возможность любому сотруднику компании с соответствующими разрешениями и необходимостью знать просматривать поток данных, проходящий через нашу сеть, а не только аналитикам.
Именно это последнее требование и стало Skipper.
Town Lake, платформа
По своей сути архитектура нашей платформы данных — это data lakehouse: движок запросов, который читает из объектного хранилища, с метаданным слоем, заставляющим хранилище вести себя как база данных. Мы называем его Town Lake, в честь одноименного водохранилища в Остине, штат Техас.
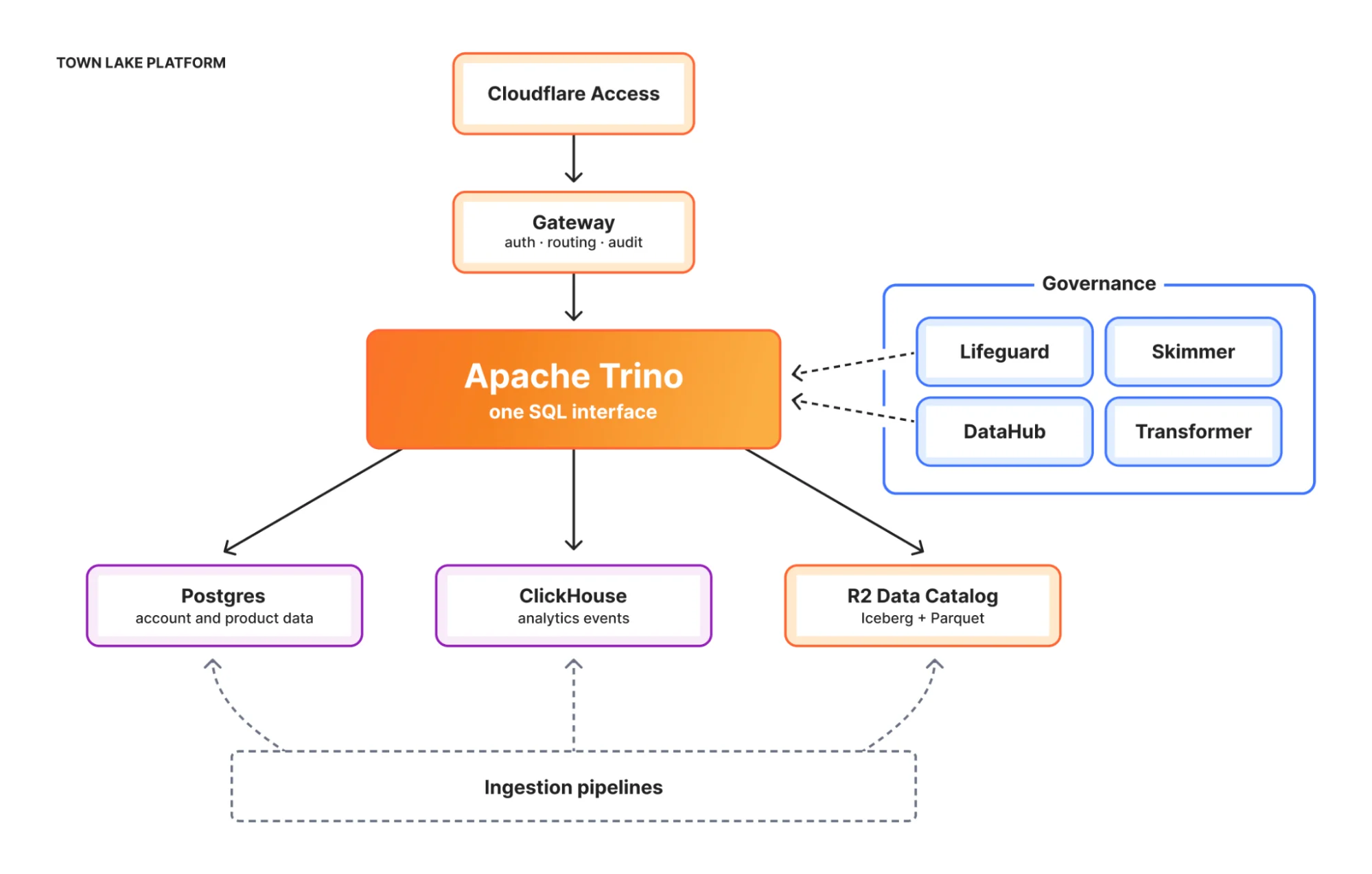
Его важнейшие компоненты:
Движок запросов. Мы выбрали Apache Trino: один SQL-запрос может объединить таблицу Postgres, таблицу ClickHouse и таблицу Iceberg на R2 без необходимости материализовать промежуточные результаты в другой системе. Запрос «какие 100 самых платящих клиентов по запросам Workers на этой неделе» компилируется в план, который проталкивает фильтры в ClickHouse, присоединяет измерение аккаунтов в Postgres и ранжирует по биллинговым сводкам в R2, и все это за один раз.
R2 Data Catalog, наш управляемый сервис Apache Iceberg, где хранятся холодные и теплые данные. Iceberg дает нам эволюцию схемы, путешествия во времени, эволюцию партиций и возможность уплотнять данные по мере их старения. Использование поминутно за прошлую неделю становится почасовым, почасовое за прошлый квартал — ежедневным и т.д. Стоимость хранения снижается по мере устаревания, а данные остаются запрашиваемыми. Parquet-файлы в R2 намного дешевле по сравнению с хранением тех же данных в OLAP-базе данных.
DataHub — это наш каталог метаданных. Каждая таблица, столбец, владелец, ребро происхождения и глоссарийный термин находятся там. Когда пользователь спрашивает «что в townlake.dim.accounts», DataHub предоставляет ответ, включая описание таблицы, описания столбцов, команду-владельца, вышестоящие таблицы, которые питают ее, и нижестоящие таблицы, которые ее потребляют.
Lifeguard — это наша служба контроля доступа: она хранит правила доступа в D1, динамически извлекает членство пользователей и групп из нашей внутренней системы управления доступом и создает комбинированную JSON-политику, которую Trino читает через HTTP. Lifeguard также передает базовую информацию о доступе Skipper и Gateway, поэтому пользователи блокируются на входе, а не во время выполнения запроса.
Skimmer — это сканер обнаружения PII. Он работает непрерывно, семплирует строки из каждого столбца каждой таблицы и использует Workers AI для классификации, содержит ли каждый столбец PII. Он делает это в два прохода: сначала быстрый классификатор по столбцам; затем, если что-то помечено, агентный второй проход, который получает полный контекст таблицы и может напрямую запросить Trino для проверки. Результаты поступают в DataHub и в белый список Lifeguard для проверки с участием человека.
Transformer — это наш ELT-движок (извлечение, загрузка, трансформация), построенный на Workflows. Пользователи определяют направленный ациклический граф (DAG) SQL-трансформаций с YAML-заголовком (целевая таблица, режим материализации, зависимости, расписание). Transformer компилирует граф и запускает его на Trino, с состоянием, управляемым Durable Objects, определениями, хранящимися в R2, и историей запусков в D1.
Ingestion — это мост из операционных систем в озеро. Оркестратор работает как долгоживущее Kubernetes-развертывание, читает конфиги пайплайнов и порождает короткоживущие задачи воркеров для извлечения из Postgres или ClickHouse, преобразования в Parquet и загрузки в R2 в виде таблиц Iceberg. Каждый пайплайн работает либо как полная замена, либо как инкрементальное добавление.
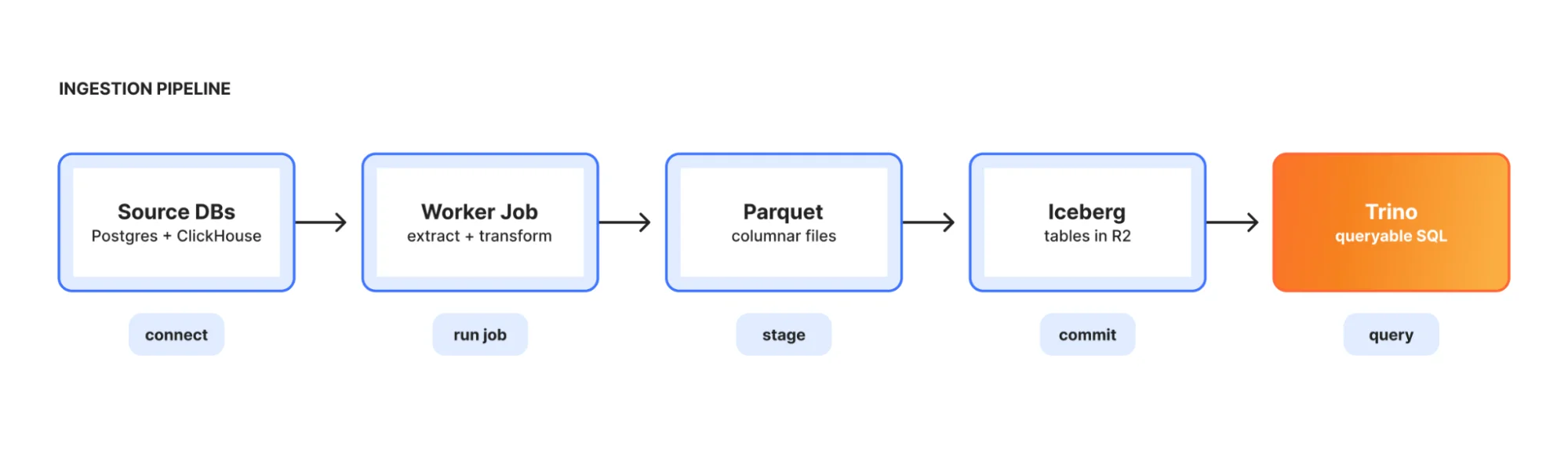
Закрыто по умолчанию: управление через конструкцию
Реальная проблема при создании единой платформы данных заключается в том, что вы только что создали большую поверхность для чувствительных данных. Традиционный ответ на это: открыто по умолчанию, ограничивать по исключению. Разрешить доступ ко всему, затем аудировать и блокировать чувствительные таблицы, когда кто-то заметит.
Town Lake применяет противоположный подход. Таблицы недоступны для запросов, пока не будут проверены. Когда новая база данных подключается к Trino или создается новая таблица, Skimmer сканирует ее, классифицирует столбцы и регистрирует ее в центральном белом списке как ожидающую. Пока рецензент не одобрит таблицу и конкретные столбцы внутри нее, пользователи не могут выполнять к ней запросы. Это звучит болезненно, и так бы и было, если бы не две вещи.
Во-первых, это автоматизировано. Классификатор Skimmer достаточно хорош: он выявляет очевидные PII (электронные письма, IP-адреса, имена, номера телефонов) и длинный хвост неочевидных чувствительных данных (токены API, соответствующие определенным префиксам, непрозрачные идентификаторы, которые можно отследить до пользователей). Рецензенты видят, что было обнаружено, и либо одобряют, переопределяют или отклоняют. Большинство проверок занимают секунды.
Во-вторых, рабочий процесс построен на самообслуживании. Если вы запрашиваете таблицу, к которой у вас нет доступа, сообщение об ошибке — не «доступ запрещён», а «эту таблицу нужно проверить, нажмите здесь, чтобы запросить проверку». Skipper, ИИ-агент, даже предложит подходящую RBAC-группу и даст прямую ссылку на неё.
Мы разделяем обнаружение схемы и доступ к данным. Пользователи могут видеть, какие таблицы существуют, но непроверенные колонки скрыты от DESCRIBE и SHOW COLUMNS, а также от SELECT *. Это тонкое различие имеет значение: новая непроверенная колонка не нарушает работу существующих дашбордов, построенных на одобренной таблице.
Персональные данные (PII) подключаются по выбору для каждой сессии. По умолчанию Trino скрывает чувствительные колонки до того, как они попадут на экран. Если вам на законных основаниях нужны неотредактированные PII (например, для расследования мошенничества), вы переключаете бит в сессии, проверяются ваши разрешения, и редактирование снимается. Каждое переключение и каждый запрос логируются.
Skipper: ИИ-агент данных
Одного только движка запросов сегодня недостаточно. SQL всё ещё является барьером, как и знание того, какую из десятков тысяч таблиц следует запрашивать — нужно знать каноническую схему.
Skipper — это наше видение разговорного ИИ-агента, который переходит от вопроса на естественном языке к проверенному ответу, опираясь на реальные данные компании, код и институциональные знания. Мы построили его поверх Town Lake и нашей платформы разработчика: Workers, Workers AI, Durable Objects, D1, R2, Workflows, KV.
Интерфейс — это окно чата. Задайте вопрос:
Покажи топ-10 клиентов по стоимости хранилища R2 за последние 30 дней и изменение по сравнению с предыдущими 30 днями.
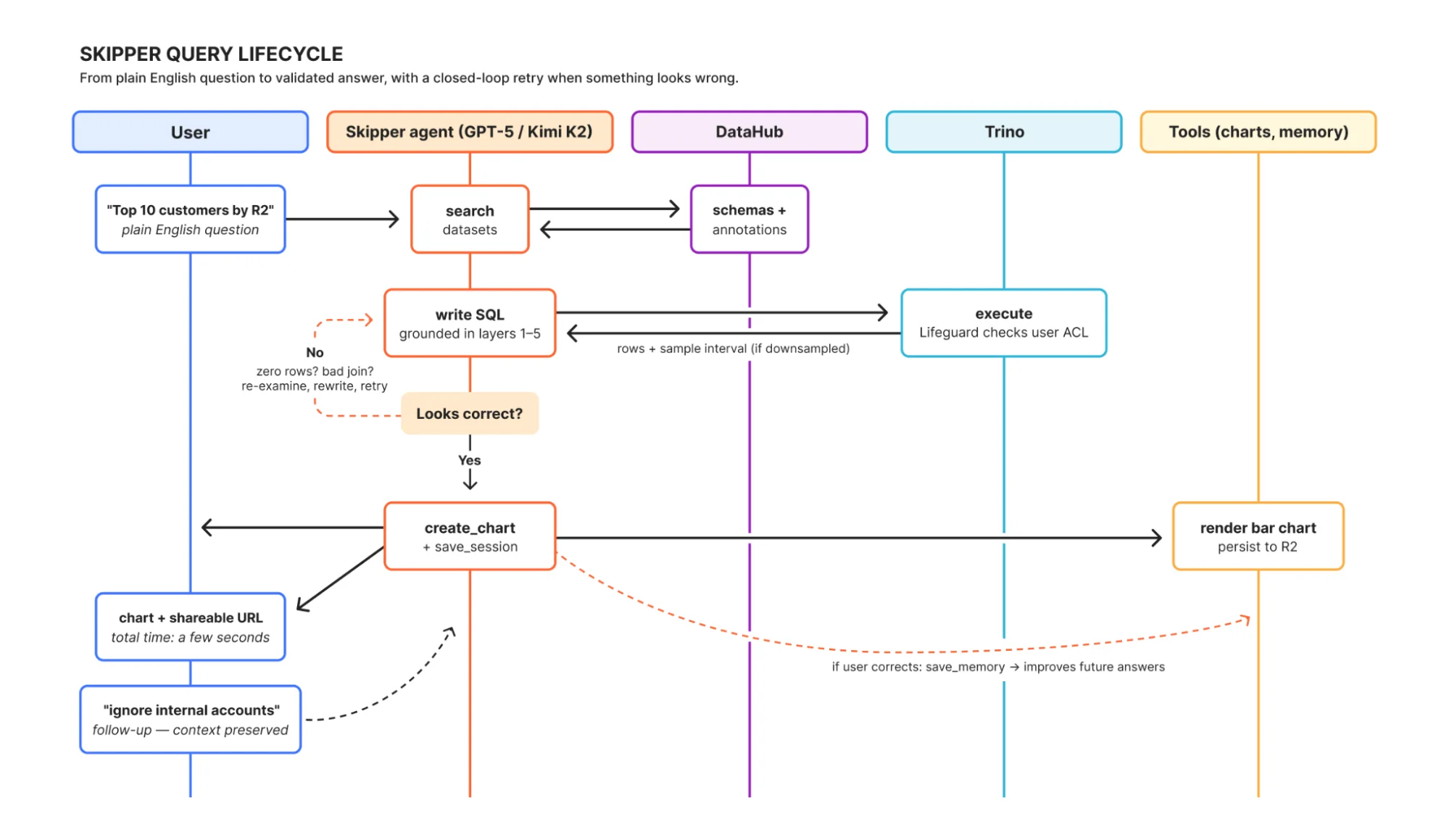
Skipper находит нужные таблицы (поиск в DataHub), получает их схемы и происхождение, пишет SQL, отправляет его в Trino, опрашивает результаты и показывает таблицу или график. Уточните:
Теперь разбей по регионам и игнорируй внутренние аккаунты Cloudflare.
Он сохраняет контекст, уточняет запрос и выполняет его заново. Если что-то выглядит не так (например, соединение не дало строк или фильтр исключил то, что вы ожидали), Skipper исследует проблему, корректирует и пробует снова в режиме рассуждений с обратной связью. Самым сложным было обеспечить правильный контекст.
Skipper также может упаковывать графики в дашборды, которыми можно делиться внутри компании и встраивать в другие внутренние приложения. У него также есть инструменты для построения графов трансформации через Transformer и для проверки доступа и разрешений через Lifeguard.
Skipper встречает пользователей там, где они находятся. Все эти инструменты доступны через Worker, поддерживаемый встроенной агентской обвязкой на базе Workers AI. С другой стороны, многие наши внутренние пользователи работают через локальные агентские потоки, и инструменты Skipper также доступны через MCP-сервер.
Уровни контекста
LLM, получив SQL-подсказку и список имён таблиц, может галлюцинировать соединения, неправильно использовать колонки и уверенно выдать абсолютно неверное число. Мы узнали это на горьком опыте во время ранних экспериментов. Решение — несколько уровней обоснованного контекста, из которых модель может черпать информацию во время извлечения.
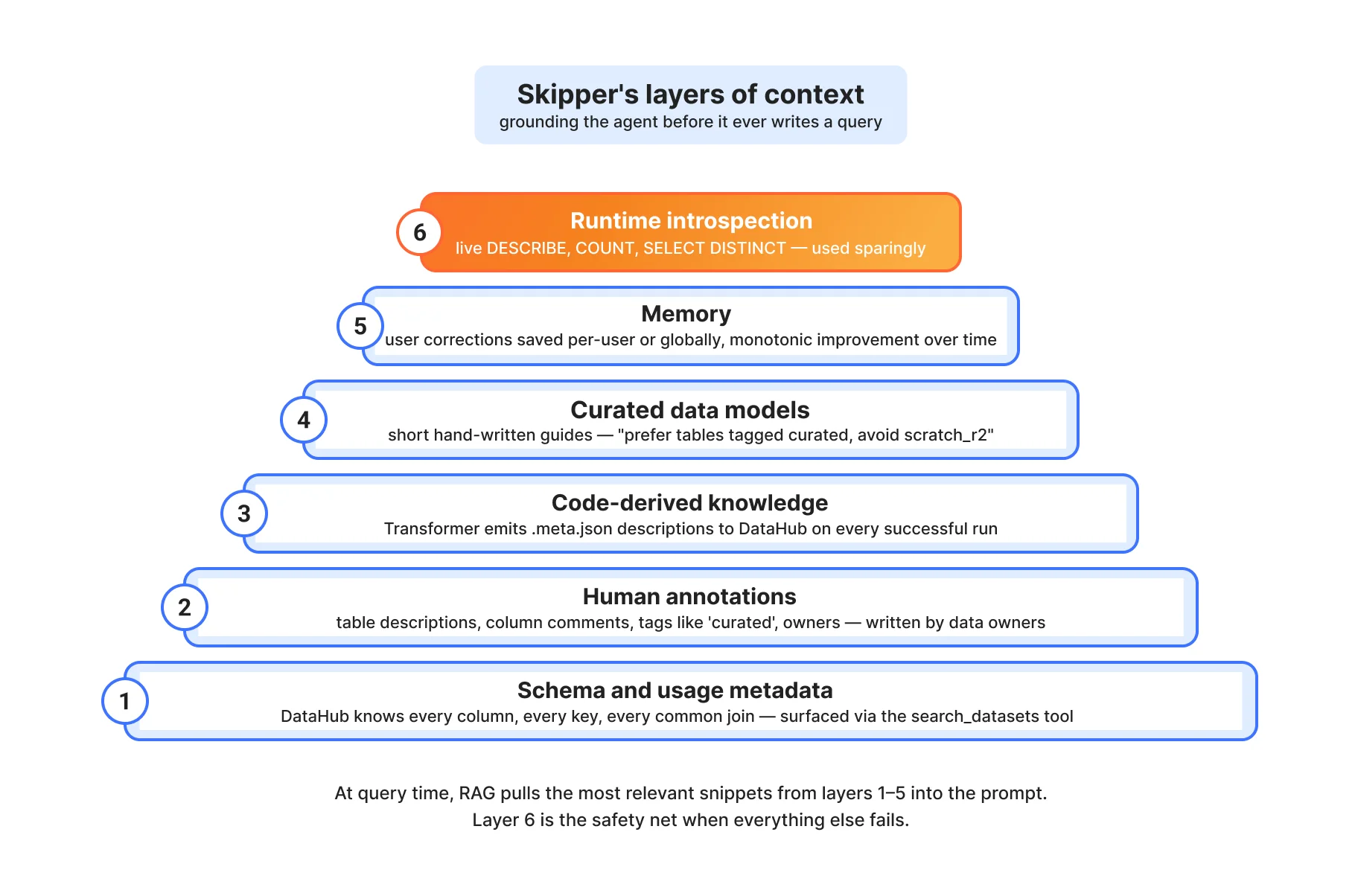
Уровень 1: Схема и метаданные использования. DataHub знает каждую колонку, каждый тип, каждый первичный ключ, каждый внешний ключ для каждой таблицы. Он также знает, какие таблицы часто соединяются вместе, основываясь на исторических шаблонах запросов. Инструменты Skipper search_datasets и get_entity_details предоставляют это напрямую.
Уровень 2: Аннотации человека. Когда команда, владеющая dim.accounts, пишет описание вроде "Сущность уровня аккаунта. Одна строка на account_id. Каждый аккаунт принадлежит ровно одному клиенту (через внешний ключ customer_id)", это описание живёт в DataHub и попадает в контекст Skipper. Теги, такие как curated, отмечают проверенные таблицы, которым Skipper должен отдавать предпочтение перед черновиками.
Уровень 3: Знание, полученное из кода. Наиболее ценный контекст часто находится не в каталоге, а в SQL, который создаёт таблицу. Конвейер Transformer генерирует для каждого узла документацию .meta.json и отправляет её в DataHub после каждого успешного запуска. Поэтому, когда Skipper смотрит на fct.billings_allocated, он видит не только схему, но и то, что это предварительно объединённая таблица фактов, построенная из dim.accounts, dim.customers и seed.product_classification, а колонка alloc_amount вычисляется как billed_amount / 12 для годовых; billed_amount для месячных. Это именно тот нюанс, который отличает правильный ответ от уверенно неправильного.
Уровень 4: Курируемые модели данных. Мы поддерживаем небольшой набор страниц «модели данных»: короткие документы, написанные человеком, которые описывают, как думать о выставлении счетов, клиентах, аккаунтах и зонах. "Предпочитай таблицы с тегом 'curated'. Избегай scratch_r2 и таблиц с тегом 'internal'. Ищи с терминами модели данных (например, 'billing product revenue'), а не на естественном языке." Эти страницы доступны как MCP-ресурсы, которые агент может извлечь, когда вопрос совпадает.
Уровень 5: Интроспекция во время выполнения. Когда всё остальное не помогает, Skipper может выполнить живые запросы к Trino: DESCRIBE table, SELECT DISTINCT col LIMIT 20, SELECT COUNT(*). Он использует их экономно, так как контекст во время выполнения дорог, но это страховочная сеть, которая делает всю систему надёжной.
Skipper как MCP: Code Mode
Стоит выделить одну конкретную деталь реализации, поскольку это уникальное решение, характерное для Cloudflare.
Когда вы создаёте ИИ-агента с инструментами, стандартный шаблон — определить инструменты в подсказке, позволить модели вызывать их один за другим, разобрать ответ, выполнить и вернуть результаты. Это нормально, но многословно: рабочий процесс с пятью инструментами — это пять циклов «туда-обратно» с моделью, и каждый раз нужно заново устанавливать контекст.
Для нашего MCP-сервера мы используем Code Mode. Вместо определения 30 отдельных инструментов мы предоставляем два: search и execute. Модель пишет фрагмент JavaScript, который программно вызывает весь наш набор инструментов:
const datasets = await skipper.search_datasets({ query: "billing product revenue" })
const queryId = await skipper.start_query({ sql: "SELECT ..." })
const results = await skipper.fetch_results({ queryId, mode: "inject" })
return skipper.create_chart({ chartType: "bar", data: results.rows, ... })Этот JavaScript выполняется в изолированном Dynamic Worker через WorkerLoader. Модель может выражать сложные многошаговые рабочие процессы за один цикл «туда-обратно» на языке, который она уже очень хорошо знает. Это быстрее, дешевле, а создаваемые рабочие процессы можно проверять как код.
Модель безопасности — это модель данных
Всё, что делает Skipper, выполняется от имени вызывающего пользователя. Если у вас нет доступа к таблице, Skipper не сможет выполнить по ней запрос. Если вы запрашиваете PII, проверяются ваши разрешения. Если сохранённый запрос опубликован для коллеги, его доступ проверяется в момент просмотра, а не сохранения, поскольку членство в группах меняется.
У общих дашбордов есть своя особенность. Их можно встроить в любой внутренний инструмент Cloudflare с помощью одного placeholder-блока div и тега script:
<div data-skipper-dashboard="dash-123"></div>
<script src="https://skipper.cloudflare.com/embed.js" async></script>Iframe автоматически подстраивается по размеру содержимого. Политика безопасности содержимого (CSP) frame-ancestors блокирует встраивание из любого места за пределами корпоративного домена. Cloudflare Access по-прежнему защищает содержимое iframe, поэтому неаутентифицированный зритель увидит в iframe страницу входа Access, а не данные. Для зрителей, не являющихся владельцами, проверяется доступ к базовым таблицам: если у них нет доступа, их направляют в нужную группу для запроса.
Что это даёт: действительно быстрые ответы
Выставление счетов. Это был первоначальный вариант использования. Наш дашборд Billable Usage Dashboard, клиентский дашборд, который показывает пользователям с оплатой по факту точную сумму к оплате, работает на конвейере учёта, источником истины которого является набор таблиц Iceberg в R2, запрашиваемых через Trino. API дашборда получает те же компактные строки (date, account_id, metric_name, usage), которые использует система выставления счетов, поэтому число на дашборде совпадает с числом в счете.
Запросы, связанные с выставлением счетов, составляют 53% всех запросов, обрабатываемых Town Lake: 91 760 запросов от 324 различных сотрудников Cloudflare за недавний период измерений. Устаревшие SQL-запросы на 200–300 строк, которые раньше вычисляли агрегаты доходов по клиентам, теперь стали запросами на пять строк.
Бизнес-аналитика. Вопрос «топ-100 клиентов по выручке» теперь выполняется в Skipper примерно за три секунды. Столько же занимает вопрос «сколько доменов, зарегистрированных сегодня, входят в топ-100». Как и большинство вопросов, связанных с данными, по которым мы раньше создавали тикеты в Jira.
Аналитика безопасности. Наша команда управления ботами использует Town Lake для запросов ML-событий с оценкой > 0.9 за последние 48 часов с фильтрацией по ASN и географии. Исследователи угроз создали на его основе собственный набор инструментов для запросов. Отдел доверия и безопасности извлекает сигналы для борьбы со злоупотреблениями.
Поддержка клиентов. «Поиск 100 самых популярных тикетов в поддержку по биллингу от клиентов, потративших >$100», раньше занимал несколько дней. Теперь это запрос в Skipper.
Что мы узнали
Некоторые вещи нас удивили.
Меньше подсказок — лучше. Ранние версии Skipper имели сложные, предписывающие системные подсказки: «Сначала используйте search_datasets. Затем используйте get_entity_details. Затем, при необходимости, используйте list_schema_fields...» Качество ухудшилось. Модель хорошо рассуждает об аналитических рабочих процессах; ей не нужен микро-менеджмент. Мы заменили предписывающие подсказки на высокоуровневые руководства и позволили модели выбирать свой собственный путь. Результаты улучшились.
Пересечение инструментов — это яд. Изначально мы предоставляли каждый вариант каждого инструмента: три разных инструмента «fetch results», два инструмента «search», несколько инструментов «list». Модель путалась и вызывала не тот. Мы объединили. Теперь fetch_results имеет параметр mode (inject / display / both) вместо трех отдельных инструментов. У каждого инструмента есть единственная причина для существования.
Код, а не метаданные, передаёт смысл. Самые большие успехи в точности были достигнуты, когда мы начали импортировать фактический SQL, создающий таблицу, а не только её схему. Столбец customer_type со значениями contract, paygo, free выглядит одинаково в любом контексте, но SQL говорит вам, что customer_type по умолчанию равен paygo, когда данные Salesforce отсутствуют. Такой контекст никогда не содержится в описаниях столбцов.
Память важнее, чем мы ожидали. Существует длинный хвост исправлений, которые выглядят как «вы должны фильтровать X так» или «игнорируйте таблицы с тегом Y». Без слоя памяти агент каждый раз заново открывает и переучивает их в каждом разговоре. С ним он становится монотонно лучше в решении повторяющихся вопросов, которые команда действительно задаёт.
Скучная инфраструктура — это самая сложная часть. Trino + Iceberg — не новая технология. Трудная работа заключается в скучных вещах: контроль доступа на уровне строк, белый список таблиц по умолчанию закрытый, аудит запросов, временные учетные данные, обнаружение PII, идемпотентная загрузка, эволюция схемы. Это то, что делает платформу данных безопасной для реального использования.
Что дальше
Мы расширяем поверхность агента. Skipper уже интегрируется как MCP-сервер в любую IDE, которая это поддерживает. Следующий шаг — более глубокая интеграция с нашими внутренними системами чатов и тикетов, чтобы «спросить у данных» стало естественным первым шагом для любого, кто отлаживает инцидент, определяет объём проекта или проверяет гипотезу на адекватность.
Мы активно инвестируем в конвейер Transformer. Цель — чтобы любая команда в Cloudflare могла создать подобранный набор данных с помощью нескольких SQL-файлов и описания .meta.json, развернуть его как Workflow, автоматически запланировать и отслеживать, и чтобы он отображался в DataHub и Skipper без дополнительной работы. Идея — самообслуживаемая инженерия данных, аналогичная самообслуживаемой разработке ПО.
R2 SQL, бессерверный распределённый аналитический движок запросов Cloudflare, становится с каждым днём всё более надёжным. По мере расширения его функциональности мы планируем перенести на него многие части рабочего процесса Town Lake.