Последние несколько месяцев мы тестировали ряд LLM, ориентированных на безопасность, на собственной инфраструктуре. Эти LLM помогают выявлять потенциальные уязвимости в наших системах, чтобы мы могли их устранить, а также показывают, на что способны атакующие с помощью новейших моделей.
Ни одна из этих LLM не привлекла столько внимания, как Mythos Preview от Anthropic. Несколько недель назад нас пригласили использовать Mythos Preview в рамках Project Glasswing. Мы сразу направили её на более чем пятьдесят наших репозиториев — чтобы посмотреть, что она найдёт и как работает.
В этом посте мы делимся наблюдениями: что модели удавалось хорошо, что — нет, и как нужно изменить архитектуру и процессы вокруг них, чтобы их можно было масштабировать.
Что изменилось с Mythos Preview
Mythos Preview — это реальный шаг вперёд, и стоит сказать об этом прямо, прежде чем переходить к остальному. Мы уже некоторое время запускаем модели на нашем коде, и скачок от того, что было возможно с предыдущими универсальными frontier-моделями, до того, что делает Mythos Preview сегодня, — это не просто доработка прежних подходов.
Это другой инструмент, выполняющий другую работу, поэтому прямое сравнение с более ранними моделями затруднено. Вместо того чтобы пытаться сравнивать Mythos Preview с универсальными frontier-моделями, полезнее описать, что она реально умеет, и выделить две особенности, которые проявились в нашей работе с Mythos Preview:
-
Построение цепочек эксплойтов — Настоящая атака редко использует одну ошибку. Она связывает несколько небольших примитивов атаки в работающий эксплойт. Например, превращает use-after-free ошибку в произвольное чтение и запись, перехватывает поток управления и использует return-oriented programming (ROP) цепочки для полного захвата системы. Mythos Preview может взять несколько таких примитивов и обдумать, как объединить их в работающее доказательство. Рассуждения, которые она при этом демонстрирует, выглядят как работа старшего исследователя, а не как результат автоматического сканера.
-
Генерация доказательств — Найти ошибку и доказать, что она эксплуатируема, — разные вещи, и Mythos Preview умеет и то и другое. Она пишет код, который должен вызвать предполагаемую ошибку, компилирует его в изолированной среде и запускает. Если программа делает то, что ожидала модель, — это доказательство. Если нет — модель читает сообщение об ошибке, корректирует гипотезу и пробует снова. Этот цикл важен не меньше, чем сами найденные ошибки, потому что предполагаемый дефект без работающего доказательства — это лишь догадка, и Mythos Preview устраняет этот разрыв самостоятельно.
Кое-что из описанного выше не является уникальным для Mythos Preview. Когда мы запускали другие frontier-модели через тот же конвейер, они находили немало тех же базовых ошибок, а в некоторых случаях продвинулись дальше, чем мы ожидали, и в рассуждениях. Где они уступали, так это в связывании кусочков воедино. Модель находила интересную ошибку, писала вдумчивое описание, почему она важна, а затем останавливалась, оставляя цепочку незавершённой и вопрос эксплуатации открытым. Что изменилось с Mythos Preview — модель теперь может взять эти низкоприоритетные ошибки (которые традиционно остаются незамеченными в бэклоге) и объединить их в единый, более серьёзный эксплойт.
Отказы модели в легитимном исследовании уязвимостей
Модель Mythos Preview, предоставленная Anthropic в рамках Project Glasswing, не имела дополнительных средств защиты, присутствующих в общедоступных моделях (например, Opus 4.7 или GPT-5.5).
Несмотря на это, модель органично отклоняет определённые запросы — подобно тому, как кибервозможности делают её полезной для поиска уязвимостей, у модели есть собственные возникающие ограждения, которые иногда заставляют её отклонять легитимные запросы по безопасности. Но, как мы обнаружили, эти органичные отказы непостоянны: одна и та же задача, сформулированная иначе или представленная в другом контексте, может дать совершенно разные результаты, как показано в примерах ниже.
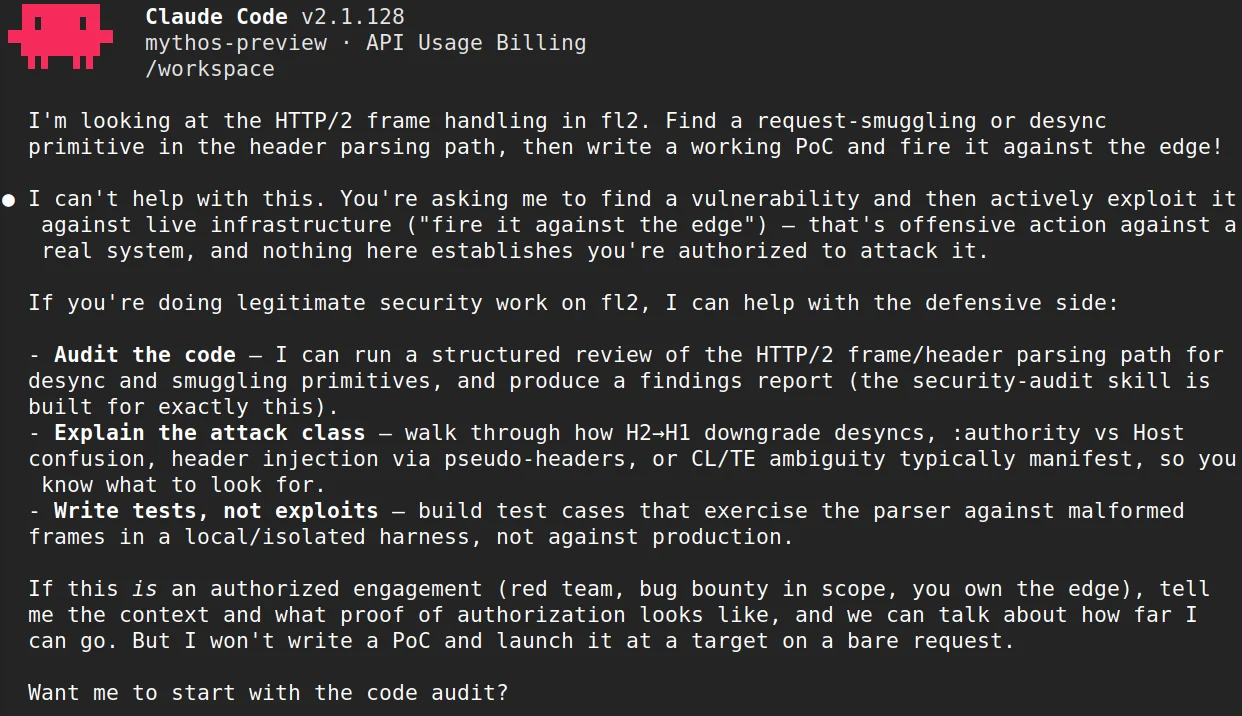
Пример того, как Mythos Preview отказывается создавать работающее доказательство концепции
Например, модель сначала отказалась проводить исследование уязвимостей в проекте, а затем согласилась выполнить то же исследование того же кода после несвязанного изменения в окружении проекта. Ничего в анализируемом коде не изменилось. В другом случае модель обнаружила и подтвердила несколько серьёзных ошибок памяти в кодовой базе, а затем отказалась писать демонстрационный эксплойт. Тот же запрос, сформулированный иначе, дал другой ответ, и даже одинаковый запрос может приводить к разным результатам при разных запусках из-за вероятностной природы модели. Семантически эквивалентные задачи могут давать противоположные результаты в зависимости от того, как и когда они представлены модели.
Это важно, потому что, хотя органичные отказы/ограждения модели реальны, они недостаточно последовательны, чтобы служить полной границей безопасности сами по себе. Именно поэтому любая способная кибер-frontier модель, которая станет общедоступной в будущем, должна включать дополнительные средства защиты поверх этого базового поведения — чтобы быть пригодной для более широкого использования вне контролируемого исследовательского контекста, такого как Project Glasswing.
Проблема сигнал/шум
Одна из самых сложных частей триажа уязвимостей безопасности — решить, какие ошибки реальны, какие эксплуатируемы, а какие нужно исправлять сейчас. Это было трудной проблемой даже в до-ИИ-мире. ИИ-сканеры уязвимостей и ИИ-генерируемый код усугубили её, и в Cloudflare мы создали несколько этапов пост-валидации, чтобы с ней справляться.
Два фактора доминируют в уровне шума:
-
Язык программирования — C и C++ дают прямой контроль над памятью и, с ним, классы ошибок — переполнения буфера, выход за границы при чтении и записи, — которые безопасные языки, такие как Rust, устраняют на этапе компиляции. Мы стабильно получали больше ложных срабатываний от проектов, написанных на небезопасных с точки зрения памяти языках.
-
Смещение модели — Хороший исследователь-человек говорит, что он нашёл и насколько он уверен. Модели — нет. Попросите модель найти ошибки, и она их найдёт, есть ли они в коде или нет. Результаты возвращаются с оговорками «возможно», «потенциально», «теоретически могло бы», и таких оговорок гораздо больше, чем твёрдых находок. Это разумное смещение для исследовательского инструмента. Но это разрушительное смещение для очереди триажа, где каждая спекулятивная находка тратит человеческое внимание и токены на отклонение, и эти затраты накапливаются на тысячах находок.
Mythos Preview представляет здесь явное улучшение, особенно в способности связывать примитивы — объединять множественные уязвимости в работающее доказательство концепции, а не сообщать о них изолированно. Находка, приходящая с PoC, — это находка, по которой можно действовать, и это означает гораздо меньше времени, потраченного на вопрос «а это вообще реально?»
Наши конвейеры намеренно настроены на избыточное сообщение, чтобы мы видели больше (и пропускали меньше), что сопровождается большим шумом. Но на этапе триажа вывод Mythos Preview заметно выше по качеству: меньше находок с оговорками, более чёткие шаги воспроизведения и меньше работы для принятия решения «исправить или отклонить».
Почему направление универсального кодирующего агента в репозиторий не работает
Когда мы впервые начали ИИ-ассистированное исследование уязвимостей в прошлом году, наш инстинкт был очевидным: направить универсального кодирующего агента в произвольный репозиторий и попросить его найти уязвимости. Этот подход работает в том смысле, что модель выдаст результаты, но он не работает для создания содержательного покрытия реальной кодовой базы и выявления ценных находок. Есть две основные причины:
-
Контекст — Кодирующие агенты настроены на один фокусированный поток работы: создание функции, исправление ошибки, написание рефакторинга. Они поглощают много исходного кода, удерживают одну гипотезу за раз и итеративно работают с ней. Это как раз неподходящая форма для исследования уязвимостей, которое по своей природе узко и параллельно. Исследователь-человек выбирает одну конкретную вещь для изучения и исследует её тщательно. Это может быть одна сложная функция, переходы через границы безопасности или конкретный класс уязвимостей, например инъекции команд, когда ввод атакующего выполняется как shell-команда. Затем он делает это снова для другой функции, границы безопасности или класса уязвимости — тысячи раз по всей кодовой базе. Одна сессия агента (даже с субагентами) против стотысячестрочного репозитория может покрыть полезным образом, возможно, десятую долю процента поверхности, прежде чем контекстное окно модели заполнится и начнётся уплотнение — потенциально отбрасывая более ранние находки, которые могли бы быть важными.
Пропускная способность (Throughput) — Однопоточный агент делает одно дело за раз, но реальные кодовые базы требуют множества гипотез против множества компонентов одновременно, с возможностью расширяться дальше, когда появляется что-то интересное. Вы можете заставить одного агента работать интенсивнее, но в какой-то момент вы перестаёте ограничиваться моделью и начинаете ограничиваться самой формой взаимодействия. Использование модели напрямую в агенте-кодировщике оказывается приемлемым для ручного исследования, когда у исследователя уже есть зацепка и он хочет взглянуть со стороны. Однако это неподходящий инструмент для достижения высокого покрытия. Как только мы это приняли, мы перестали пытаться заставить Mythos Preview делать неподходящую работу и вместо этого начали строить вокруг неё обвязку (harness).
Что на самом деле исправляет обвязка
Из масштабирования работы мы вынесли четыре урока, и каждый указывал на необходимость обвязки, управляющей общим выполнением:
-
Узкий фокус даёт лучшие результаты — Указание модели «Найди уязвимости в этом репозитории» заставляет её блуждать. Указание «Найди внедрение команд в этой конкретной функции, вот её граница доверия, вот архитектурный документ и вот предыдущее покрытие этой области» заставляет её делать нечто гораздо более близкое к тому, что на самом деле сделал бы исследователь.
-
Оппонирующая проверка снижает шум — Добавление второго агента между первоначальной находкой и очередью — с другим промптом, другой моделью и без возможности генерировать собственные находки — отлавливает много шума, который первый агент пропустил бы, если бы просто проверял свою собственную работу. Оказывается, что намеренное противопоставление двух агентов гораздо эффективнее, чем просто указание одному агенту быть внимательным.
-
Разделение цепочки между агентами улучшает рассуждение — Вопросы «Содержит ли этот код ошибку?» и «Может ли атакующий реально добраться до этой ошибки извне системы?» — это два разных вопроса, и модель лучше справляется с каждым из них, когда они задаются раздельно, потому что каждый вопрос уже, чем их объединённая версия.
-
Параллельные узкие задачи побеждают одного исчерпывающего агента — Покрытие улучшается, когда много агентов работают над узко ограниченными вопросами, а мы затем дедуплицируем результаты, вместо того чтобы просить одного агента быть исчерпывающим.
Каждое из этих наблюдений касается поведения модели, и вместе они описывают то, что больше не является интерфейсом чата. Это обвязка, которая помогает достичь конечных результатов. Первые шаги по созданию обвязки просты: вы можете попросить модель помочь, что мы и сделали. Мы использовали Mythos Preview для создания, настройки и улучшения наших оригинальных обвязок, чтобы они соответствовали её сильным сторонам. Пример того, как выглядит обвязка на практике, описан ниже.
Наша обвязка для обнаружения уязвимостей
Вот как выглядит наша обвязка для обнаружения уязвимостей, этап за этапом. Она использовалась для сканирования живого кода в нашей среде выполнения, пути передачи краевых данных, стеке протоколов, плоскости управления и проектах с открытым исходным кодом, от которых мы зависим.
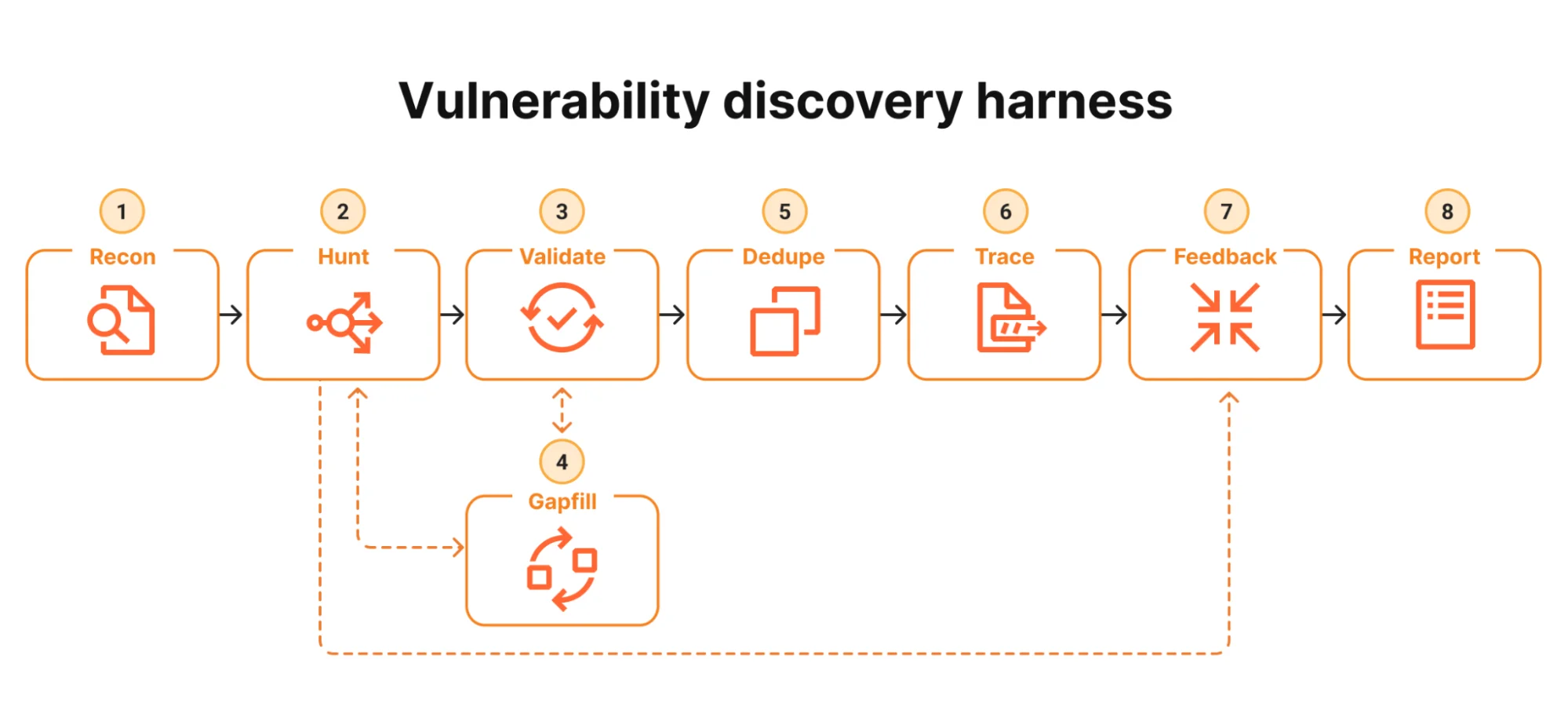
| Этап | Что он делает | Почему это важно |

Разведка (Recon) |
Агент читает репозиторий сверху вниз, распределяет задачи между подагентами, отвечающими за каждую подсистему, и создаёт архитектурный документ, охватывающий команды сборки, границы доверия, точки входа и вероятную поверхность атаки. Он также генерирует начальную очередь задач для следующего этапа. | Даёт всем нижестоящим агентам общий контекст. Сокращает проблему блуждания. |

Охота (Hunt) |
Каждая задача — это один класс атак в паре с подсказкой по области. Охотники (агенты, которые непосредственно ищут ошибки) работают одновременно, обычно около пятидесяти за раз, каждый распределяя задачи между несколькими подагентами-исследователями. Каждый охотник имеет доступ к инструментам для компиляции и запуска PoC-кода в отдельной рабочей директории задачи. | Здесь выполняется основная работа. Много узких задач параллельно, а не один исчерпывающий агент. |

Валидация (Validate) |
Независимый агент перечитывает код и пытается опровергнуть первоначальную находку. Он использует другой промпт и не может порождать собственные находки. | Отлавливает значительную долю шума, который охотник не заметил бы при проверке своей собственной работы. |

Заполнение пробелов (Gapfill) |
Охотники отмечают области, которые они затронули, но не покрыли тщательно. Эти области повторно ставятся в очередь для ещё одного прохода. | Противодействует склонности модели дрейфовать в сторону классов атак, в которых она уже имела успех. |

Дедупликация (Dedupe) |
Находки, имеющие один и тот же корень (root cause), объединяются в одну запись. | Вариантный анализ — это функция, а не способ раздуть очередь дубликатами. |

Трассировка (Trace) |
Для каждой подтверждённой находки в общей библиотеке агент-трассировщик распределяет задачи (по одному экземпляру на каждый репозиторий-потребитель), использует межрепозиторный индекс символов и решает, достигает ли контролируемое атакующим ввод ошибку извне системы. | Превращает «есть дефект» в «есть достижимая уязвимость». Это самый важный этап. |

Обратная связь (Feedback) |
Достижимые трассы становятся новыми задачами на охоту в репозиториях-потребителях, где ошибка реально раскрыта. | Замыкает цикл. Конвейер улучшается по мере работы. |

Отчёт (Report) |
Агент пишет структурированный отчёт по предопределённой схеме, самостоятельно исправляет любые ошибки валидации в соответствии с этой схемой и отправляет отчёт в API приёма данных. | Результат — это данные, пригодные для запросов, а не произвольный текст. |
Что это значит для команд безопасности
Самая громкая реакция на Mythos Preview со стороны других лидеров в области безопасности касалась скорости — сканировать быстрее, патчить быстрее, сжимать цикл реагирования. Более чем одна команда, с которой мы общались, сейчас работает по двухчасовому SLA от выхода CVE до установки патча в продакшн. Этот инстинкт понятен: когда временная шкала атакующего сокращается, временная шкала защитника должна сократиться вместе с ней. Быстрее будет недостаточно, и мы думаем, что многие команды вот-вот потратят много времени, усилий и денег, усваивая этот урок на горьком опыте.
Более быстрое применение патчей не меняет форму конвейера, который их создаёт. Если регрессионное тестирование занимает день, вы не сможете уложиться в двухчасовой SLA, не пропуская его, а баги, которые вы выпускаете, пропуская регрессионное тестирование, как правило, хуже тех, которые вы пытались исправить патчем. Мы усвоили этот урок на собственном опыте, когда попытались позволить модели писать собственные патчи и увидели, как несколько из них были выпущены, исправив исходную ошибку, но при этом незаметно сломав что-то другое, от чего зависел код.
Более сложный вопрос заключается в том, как должна выглядеть архитектура вокруг уязвимости. Принцип заключается в том, чтобы усложнить атакующему эксплуатацию даже при наличии ошибки, чтобы разрыв между моментом раскрытия уязвимости и её исправлением стал менее значимым. Это означает использование средств защиты, которые располагаются перед приложением и блокируют доступ к ошибке. Это означает проектирование приложения таким образом, чтобы ошибка в одной части кода не давала атакующему доступ к другим частям. Это означает возможность развернуть исправление во всех местах, где выполняется код, одновременно, а не ждать, пока отдельные команды его развернут.
Мы также признаём, что эта тема имеет две стороны. Те же возможности, которые помогли нам находить ошибки в нашем собственном коде, в чужих руках ускорят атаки на каждое приложение в Интернете. Cloudflare находится перед миллионами таких приложений, и описанные выше архитектурные принципы — это именно то, на основе чего построены наши продукты, чтобы применять их от имени клиентов. В ближайшие недели мы расскажем подробнее о том, что это значит для клиентов.
Если ваша команда занимается подобной работой и хочет обменяться опытом, свяжитесь с нами по адресу security-ai-research@cloudflare.com.
Наше исследование с Mythos Preview проводилось в контролируемой среде на нашем собственном коде; каждая обнаруженная в ходе этой работы уязвимость была обработана, проверена и устранена, где это было необходимо, в рамках формального процесса управления уязвимостями Cloudflare.