В Cloudflare мы активно используем ClickHouse — систему управления аналитическими базами данных с открытым исходным кодом. Мы изменили дизайн одной из наших крупнейших таблиц ClickHouse, добавив столбец в ключ секционирования. Это изменение позволило установить индивидуальный срок хранения данных для каждого арендатора в таблице, обслуживающей сотни внутренних команд. Дизайн прошёл несколько раундов доработок и рецензирования с инженерами из разных команд, прежде чем мы остановились на финальном подходе. Но через несколько недель после развёртывания задания, формирующие большую часть счетов Cloudflare, стали упираться в жёсткий дневной дедлайн.
Все обычные подозреваемые выглядели чисто: ввод-вывод, память, количество прочитанных строк и частей. Всё, что мы обычно проверяем, когда запрос ClickHouse работает медленно, казалось нормальным. Проблема оказалась в конкуренции за блокировки при планировании запросов — то, что мы раньше никогда не искали.
Это история о том, как эта миграция выявила скрытое узкое место во внутреннем устройстве ClickHouse, и о патчах, которые мы написали для его исправления.
Настройка: аналитическая платформа петабайтного масштаба
Мы используем ClickHouse для хранения более ста петабайт данных в нескольких десятках кластеров. Чтобы упростить подключение для множества внутренних команд, в начале 2022 года мы построили систему под названием «Ready-Analytics».
Идея проста: вместо проектирования новых таблиц команды могут передавать данные в одну большую таблицу. Наборы данных различаются с помощью namespace, а каждая запись использует стандартную схему (например, 20 полей с плавающей точкой, 20 строковых полей, временная метка и indexID).
В ClickHouse способ сортировки данных критически важен для производительности запросов. Здесь и вступает в игру indexID. Это строковое поле, которое является частью первичного ключа, что означает, что данные каждого отдельного пространства имён могут быть отсортированы оптимальным образом для запросов, которые владельцы этого пространства имён ожидают выполнять. В итоге мы получаем первичный ключ, который выглядит так: (namespace, indexID, timestamp).
Эта система популярна, её используют сотни приложений. К декабрю 2024 года она выросла до более чем 2 ПиБ данных со скоростью приёма в миллионы строк в секунду. Но у неё был один критический недостаток: политика хранения данных.
Проблема: одна политика хранения, чтобы править всеми
Cloudflare использует ClickHouse много лет, ещё до появления в нём встроенных функций TTL (времени жизни). Поэтому мы построили собственную систему хранения на основе секционирования. Таблица Ready-Analytics была секционирована по дням, и наше задание по хранению просто удаляло разделы старше 31 дня.
Этот «единый для всех» 31-дневный срок хранения был серьёзным ограничением. Некоторым командам требовалось хранить данные годами из-за юридических или контрактных обязательств, тогда как другим нужно было всего несколько дней. Это ограничение означало, что такие сценарии использования не могли применять Ready-Analytics и должны были выбирать традиционную настройку, которая имеет гораздо более сложный процесс подключения.
Нам была нужна новая система, позволяющая индивидуальный срок хранения для каждого пространства имён.
Решение: новая схема секционирования
Мы рассмотрели два основных подхода:
-
Таблица для каждого пространства имён: Это естественным образом решило бы проблему хранения, но потребовало бы значительной новой автоматизации для управления тысячами таблиц по требованию.
-
Новый ключ секционирования: Мы могли бы изменить ключ секционирования с простого
(день)на(namespace, день).
Мы выбрали второй вариант. Это позволило бы нашей существующей системе хранения продолжать управлять разделами, но теперь с детализацией до пространства имён.
Мы знали, что это увеличит общее количество частей данных в таблице, но сделали ключевое предположение: поскольку каждый запрос фильтруется по конкретному пространству имён, количество частей, читаемых любым отдельным запросом, не должно измениться. Мы полагали, что это означает, что производительность останется прежней.

На рисунке показано, как мы изменили секционирование, что позволило нам недорого удалять данные для одного пространства имён.
Эта новая система также позволила нам построить сложный уровень управления хранилищем. Используя алгоритм максимально-минимальной справедливости, мы могли установить целевое использование диска (например, 90%) и автоматически «делить» доступное пространство. Пространства имён, использующие меньше своей справедливой доли, уступали неиспользованную ёмкость тем, кому нужно больше. Это позволило нам уверенно эксплуатировать наши кластеры при загрузке 90%.
Мы начали миграцию в январе 2025 года. Используя функцию таблицы Merge в ClickHouse, мы объединили старую и новую таблицы, записывая все новые данные в новую секционированную таблицу, пока старые данные вытеснялись.
Загадка: когда начинаются сбои в биллинге
Два месяца спустя, в конце марта 2025 года, наша команда по биллингу сообщила, что ежедневные задания по агрегации замедлились. Эти задания критичны по времени; если они не завершатся, счета не будут отправлены. Задания становились всё медленнее, и мы приближались к дедлайну.
Мы провели расследование, но ни один из обычных подозреваемых не подтвердился. Ввод-вывод был в норме. Память — в норме. Метрики отдельных запросов показывали, что они не читают больше данных или частей, чем раньше. Наше первоначальное предположение казалось верным, но система замедлялась до остановки.
Прошло несколько дней, прежде чем у нас появилась хотя бы теория. Наконец, мы построили график зависимости длительности запроса от общего количества частей в кластере. Корреляция была неоспоримой.
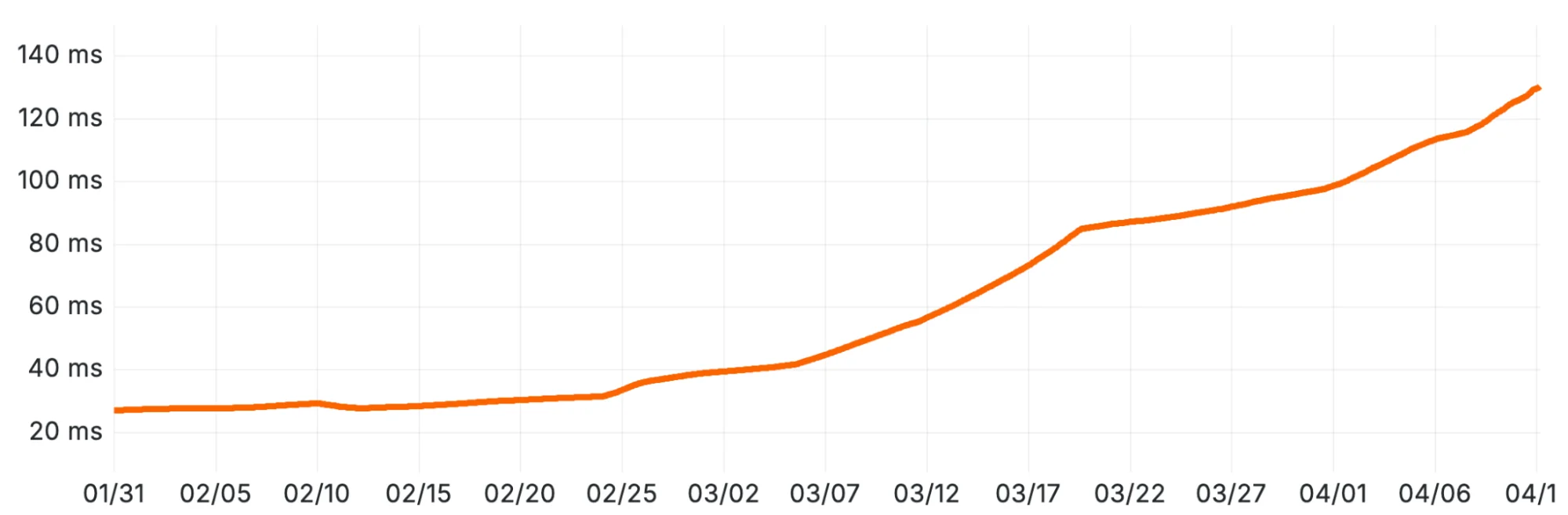
Средняя длительность SELECT-запросов в кластере ClickHouse Ready Analytics, демонстрирующая прогрессирующую деградацию производительности.
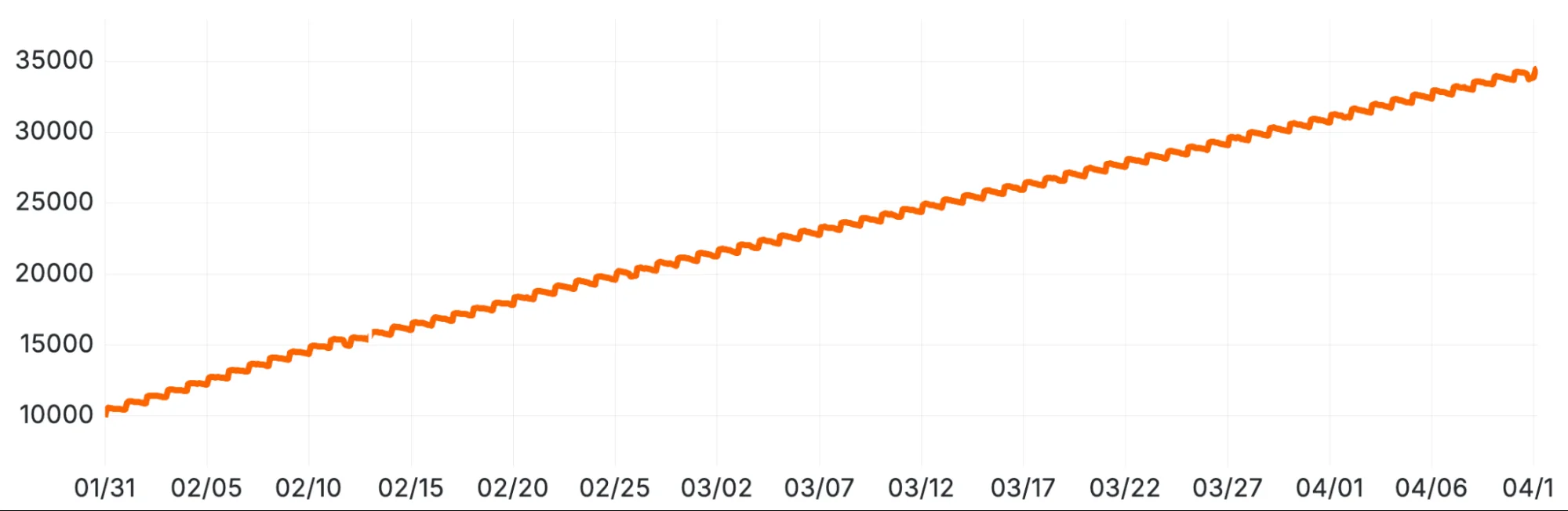
Линейный рост общего количества частей данных на реплику таблицы после внедрения новой схемы секционирования (namespace, день).
Но почему? Если мы не читали лишние части, почему их простое существование замедляло нас?
Расследование: охота за узкими местами с помощью флейм-графиков
Мы обратились к встроенной в ClickHouse таблице trace_log для генерации флейм-графиков. Это встроенная таблица, которая записывает трассы работающего сервера ClickHouse. Она содержит не только трассы выполняемого кода, но и связывает их с конкретными пользователями, идентификаторами запросов и другими метаданными, что позволяет при необходимости довольно точно фильтровать наборы событий. В нашем случае мы хотели посмотреть конкретно на листовые SELECT-запросы. Это было легко благодаря доступным метаданным в этой таблице.
Первый флейм-график на основе ЦП быстро подтвердил наши подозрения: огромное количество времени тратилось на планирование запроса. Это фаза перед выполнением, когда ClickHouse решает, какие части читать.
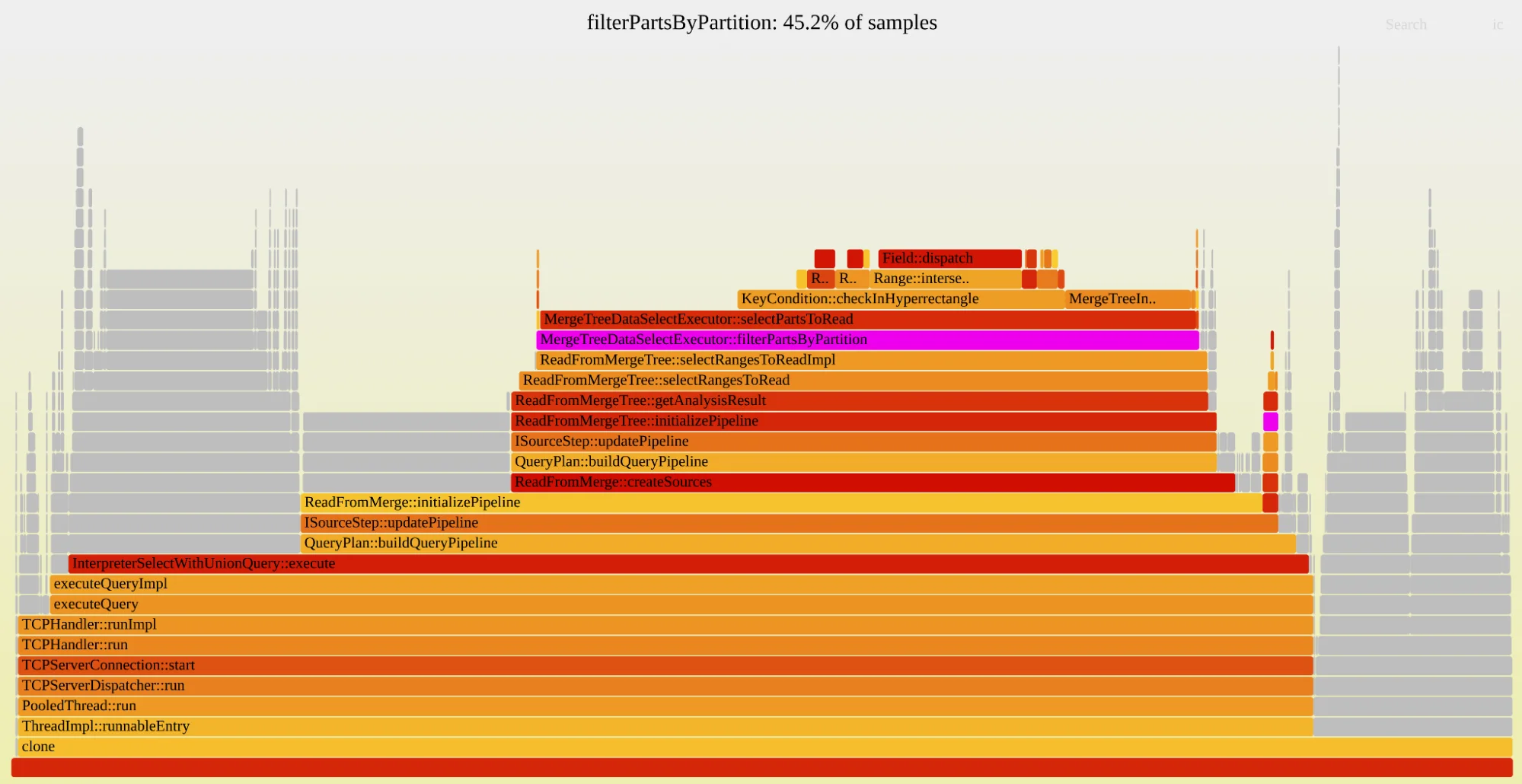
Флейм-график, показывающий, что 45% времени ЦП листовых запросов тратится на фильтрацию вектора частей по идентификатору раздела.
Флейм-график был ясен: 45% времени ЦП выборки тратилось на одну функцию под названием filterPartsByPartition.
Наша первая попытка исправления заключалась в небольшом патче именно для этого участка кода. Планировщик оценивает эвристики для сокращения частей, и мы полагали, что они оценивались не в оптимальном порядке для нашей таблицы. Наш патч изменил порядок, что дало небольшое улучшение на 5%. Мы были на правильном пути, но упустили реальную проблему.
Мы генерировали трассы «ЦП», которые семплируют только активные потоки. Мы переключились на трассы «Реальные», которые семплируют все потоки, включая неактивные или ожидающие. Новый флейм-график стал откровением.
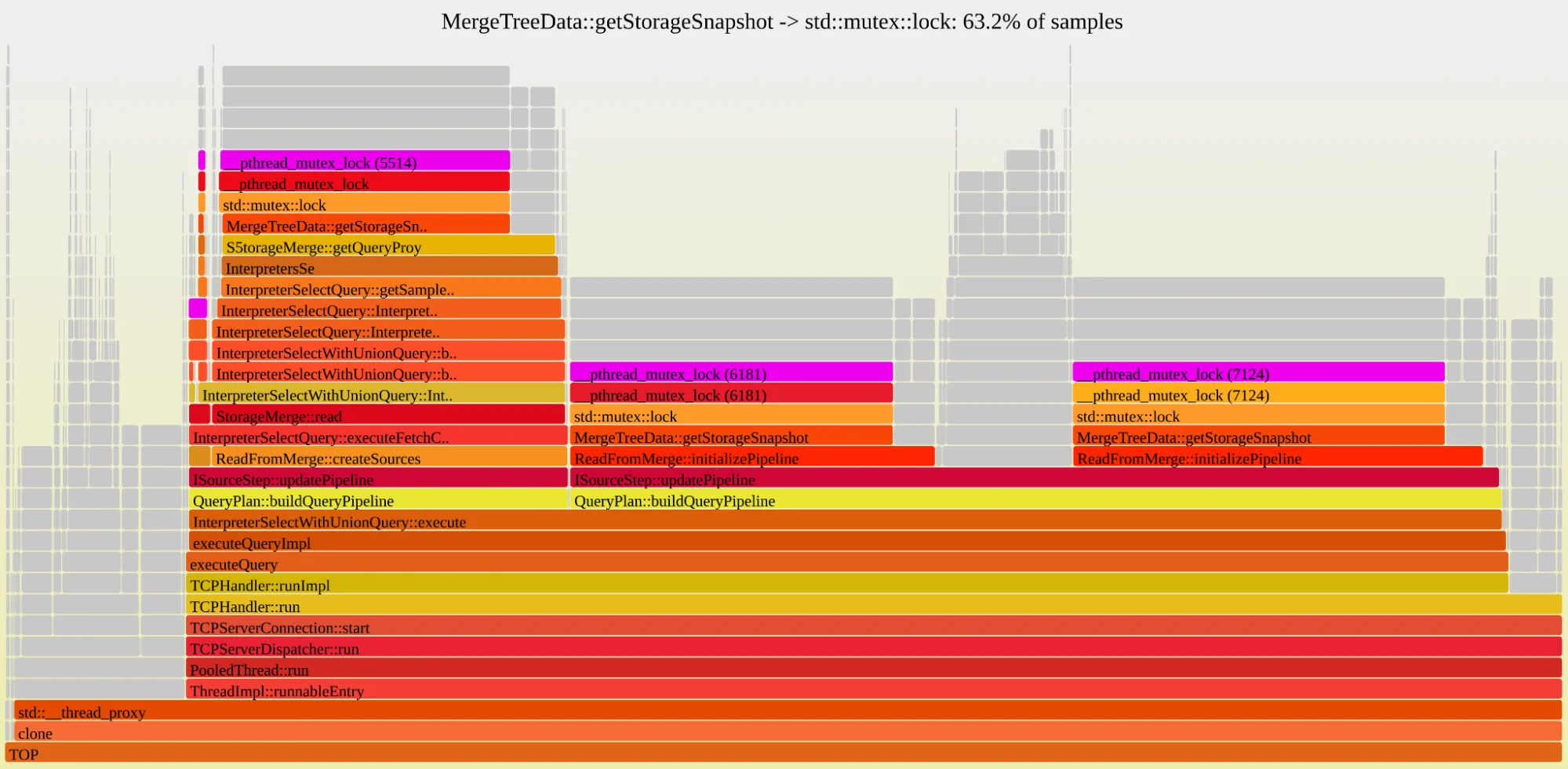
Флейм-график, показывающий, что более половины длительности листового запроса тратится на ожидание мьютекса, защищающего список активных частей.
Проблема заключалась не в работе, нагружающей ЦП, а в массовой конкуренции за блокировки. Более половины времени нашего запроса уходило на ожидание получения одного единственного мьютекса (MergeTreeData), который защищает список частей таблицы. Для планирования запроса каждый отдельный поток должен был:
-
Захватить эксклюзивную блокировку этого мьютекса.
-
Сделать полную копию списка всех частей в таблице.
-
Освободить блокировку.
-
Отфильтровать этот список до релевантных частей.
При десятках тысяч частей и сотнях одновременных запросов все они просто выстраивались в очередь по одному.
Исправления: три патча
Это понимание помогло нам спланировать серию оптимизаций для устранения этих горячих точек. Как и со всеми патчами, которые мы делаем для ClickHouse, мы стараемся делать их универсальными и в конечном итоге вносить в основную кодовую базу. Это упрощает нам поддержку нашего форка, а также означает, что сообщество тоже выигрывает от наших изменений!
Оптимизация 1: использование разделяемой блокировки
Планировщик запросов не изменяет список частей; он просто читает его. Ему не было необходимости использовать исключительную блокировку.
Исправление: Мы изменили код, чтобы вместо этого захватывать разделяемую блокировку (std::shared_lock). Это позволило всем планировщикам запросов входить в критическую секцию одновременно.
Результат: Массовое немедленное снижение времени выполнения запросов. Конкуренция за блокировку исчезла.
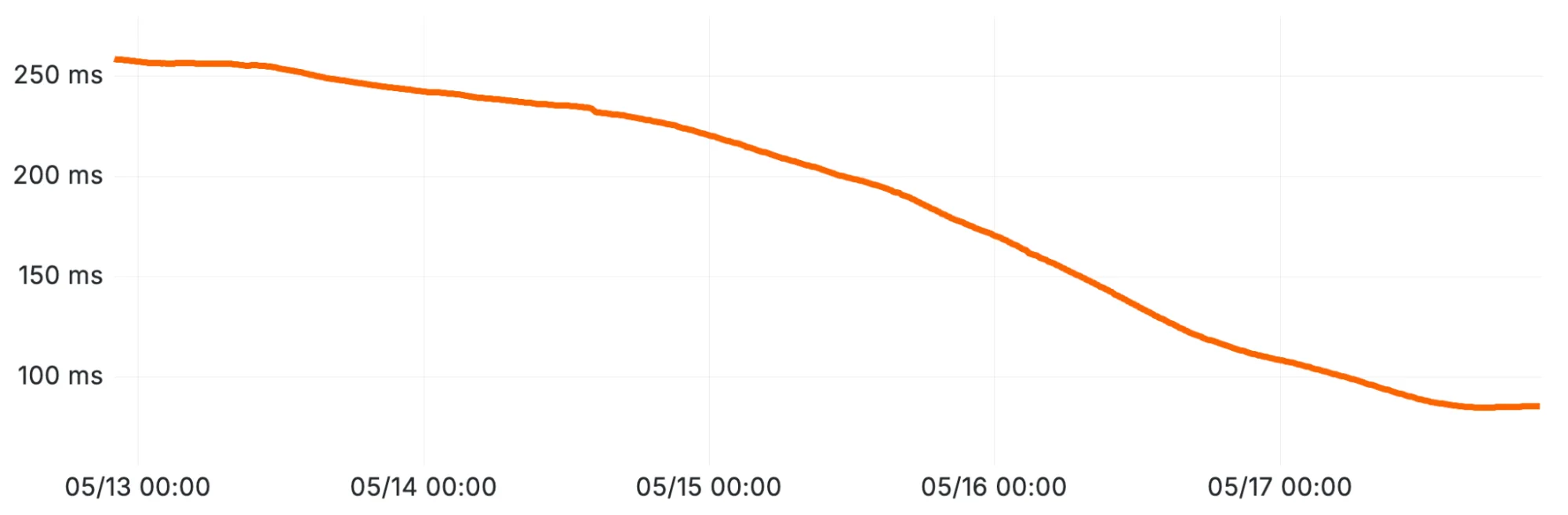
Немедленное влияние оптимизации разделяемой блокировки (Оптимизация 1) на среднюю длительность SELECT-запросов, демонстрирующее устранение конкуренции за блокировку.
Оптимизация 2: прекратить копирование вектора
Производительность значительно улучшилась, но всё ещё не вернулась к исходному уровню. Мы вернулись к логу трассировки и построили ещё один «реальный» флейм-граф.
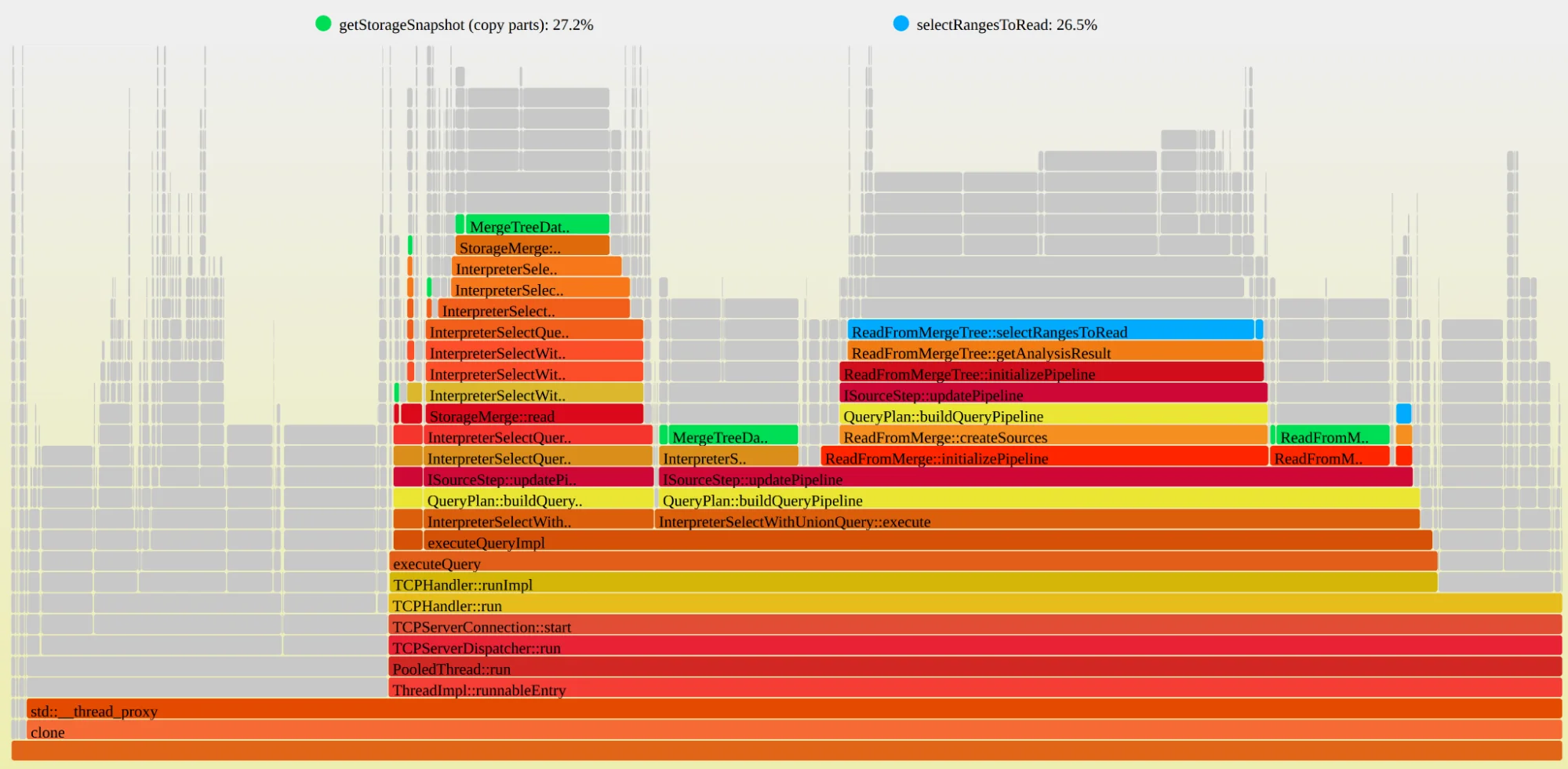
Флейм-граф, показывающий, что мы тратим четверть времени выполнения листового запроса на копирование вектора всех частей и ещё четверть на фильтрацию по нему (снова копирование).
Новый флейм-граф показал, что узкое место просто переместилось. Теперь время тратилось на копирование гигантского вектора частей, даже с разделяемой блокировкой. Интуитивно копирование вектора кажется дешёвым, но когда он содержит десятки тысяч элементов, и вы делаете это сотни раз в секунду, это накапливается.
Исправление: Мы полностью отложили копирование. Мы создали «разделяемую копию» списка частей. Операции только для чтения (например, планирование запросов) просто читают из этой копии. Любая операция, которая изменяет набор частей (например, новая вставка), перегенерирует кэш. Теперь планировщики копируют только отфильтрованный список действительно необходимых им частей.
Результат: Ещё одно значительное улучшение производительности.
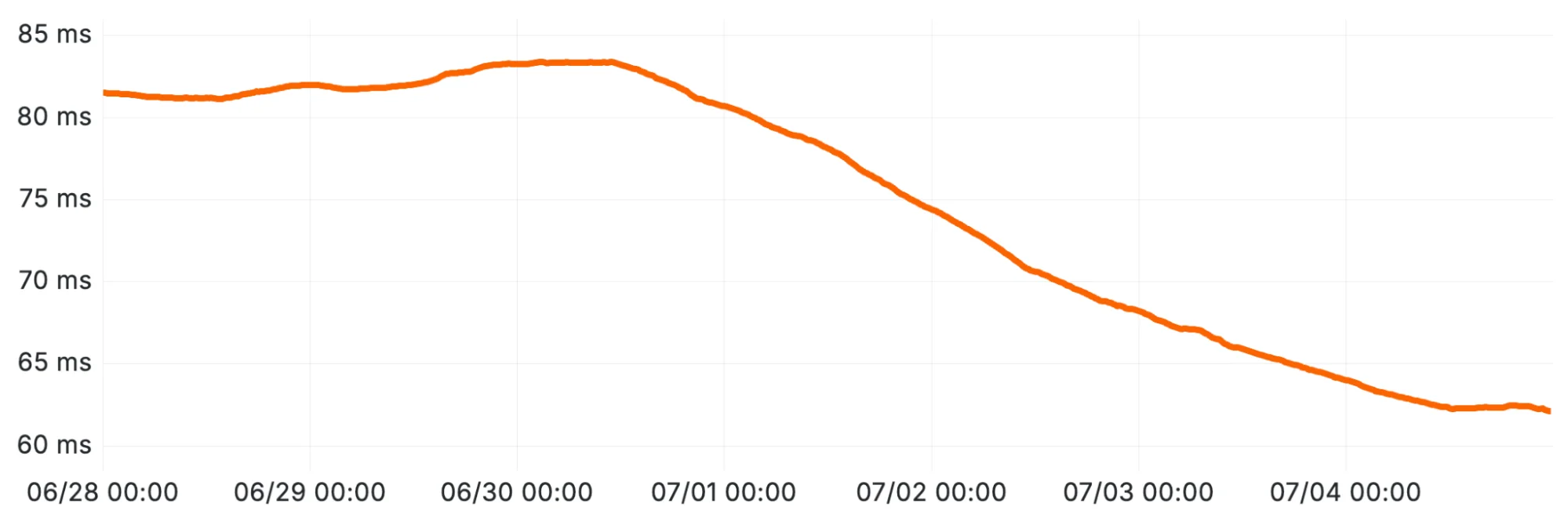
Дальнейшее улучшение производительности после внедрения оптимизации копирования вектора (Оптимизация 2).
Увидев эту огромную экономию внутри компании, мы решили предложить эти изменения сообществу. После нескольких небольших итераций по дизайну с мейнтейнерами из ClickHouse Inc., изменения были приняты в PR #85535. Они доступны с версии ClickHouse 25.11.
Оптимизация 3: бинарный поиск частей
Мы ещё не закончили. По мере роста количества частей производительность всё ещё ухудшается, но гораздо медленнее. Корреляция с количеством частей сохранилась. Вернувшись к этому через несколько месяцев, новый флейм-граф (выглядящий так же, как на Рисунке 3) показывает, что время тратится на путь фильтрации (тот, который мы пытались исправить в первую очередь). Этот код выполняет линейный проход по всем частям, оценивая предикаты для каждой. Через несколько месяцев мы вернулись к длительности выполнения SELECT, как до оптимизаций.
Но мы знаем, что этот список частей отсортирован по ключу партиционирования. Помните, что первая колонка ключа партиционирования — это namespace, по которому фильтрует подавляющее большинство запросов, поскольку он идентифицирует «арендатора». Как мы можем это использовать?
Исправление: Мы реализовали бинарный поиск на основе части namespace ID партиции. Это работает, потому что вектор отсортирован, поэтому можно отфильтровать множество записей, даже не просматривая их. Это особенно эффективно, поскольку namespace является первой частью этого ключа сортировки. После этого первого прохода бинарного поиска у нас остаётся гораздо меньший диапазон частей для проверки, и для них мы всё равно проходим по каждой, применяя ту же логику, что и раньше, чтобы исключить части на основе других условий.
Результат: После развёртывания этого патча в марте 2026 года время выполнения запросов снизилось на 50% (см. Рисунок 8). Что более важно, это наконец нарушает корреляцию времени выполнения запросов с количеством частей. К сожалению, это решение не очень хорошо обобщается для произвольных условий запроса (например, таких условий, как namespace in (5,10)). Мы рассматриваем более общие подходы, например расширение кэша условий запросов для покрытия фильтрации частей.
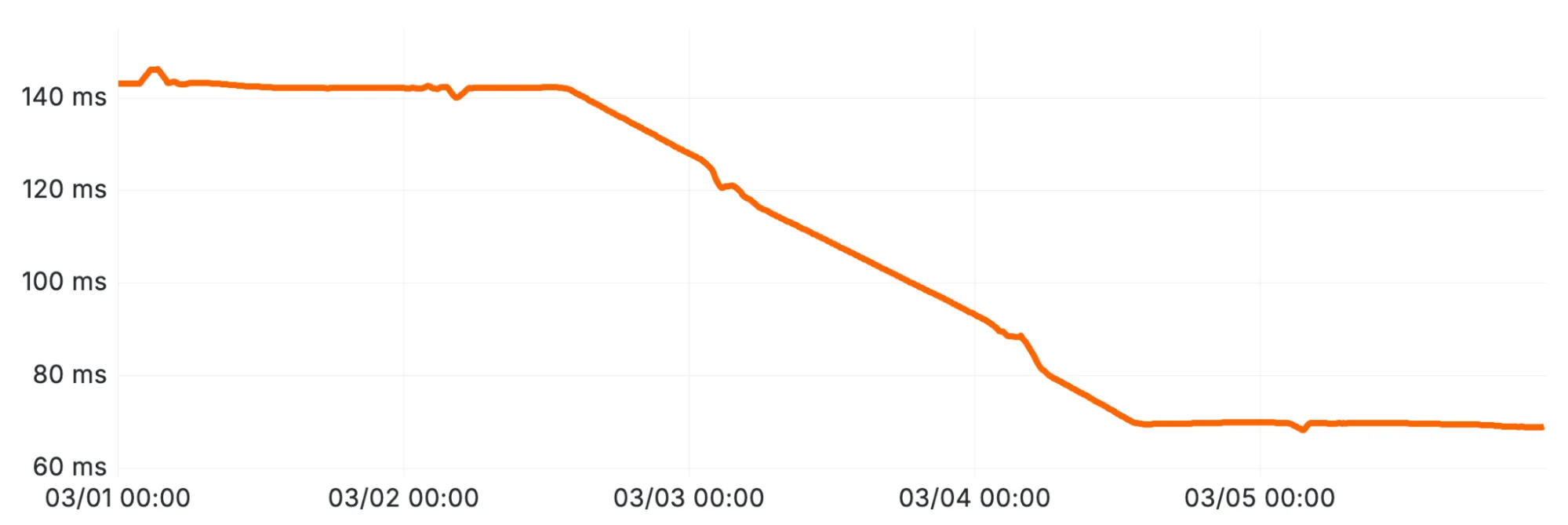
Устойчивое снижение задержки после внедрения бинарного поиска для отсечения частей (Оптимизация 3).
Неспокойное перемирие
Эти оптимизации разрешили непосредственный кризис с системой биллинга. Но этот путь выявил глубокие, неочевидные издержки нашего выбора партиционирования.
Другие проблемы остаются. В этом посте мы описали только проблемы, которые увеличивающееся количество частей вызвало для длительности наших SELECT, но это также создало проблемы для ZooKeeper, который отслеживает метаданные для всех частей в ClickHouse. Возможно, однажды мы расскажем историю о кластере ZooKeeper на 100 гигабайт.
Мы выиграли себе значительную передышку, но фундаментальный вопрос остаётся: была ли эта схема партиционирования правильным долгосрочным выбором? Или в конечном итоге нам придётся собраться с духом и перейти на другую архитектуру? Пока наши патчи работают, но этот опыт стал наглядным примером того, как даже хорошо спланированное изменение может стать жертвой неверных предположений.
Когда команда биллинга впервые сообщила об этой проблеме, у нас было 30 000 частей на реплику. Количество частей никогда не переставало расти, и год спустя мы достигли 160 тысяч частей на реплику, но время выполнения запросов оставалось стабильным благодаря оптимизациям, которые мы здесь сделали.