Мы увеличили лимиты использования, повысили производительность и надёжность Browser Run, перестроив его на основе Containers от Cloudflare.
Теперь вы можете запускать до 60 браузеров в минуту через привязку Workers и одновременно выполнять до 120 — в 4 раза больше предыдущего лимита. Кроме того, время отклика быстрых действий сократилось более чем на 50%. Вам не нужно ничего менять: эти улучшения уже работают. Более того, мы выпускаем исправления и новые функции быстрее, чем раньше. Читайте далее, чтобы узнать, как мы это сделали, и увидеть данные.
Напомните: что такое Browser Run?
Browser Run позволяет разработчикам программно управлять безголовыми экземплярами браузеров, работающими в глобальной сети Cloudflare, и взаимодействовать с ними. Это полезно для сквозного тестирования веб-приложений, безопасного исследования подозрительных URL-адресов, а также для использования возможностей браузеров по лёгкому рендерингу PDF-документов и других быстрых действий, таких как создание скриншотов и извлечение контента. В последнее время это стало критически важным инструментом для взаимодействия AI-агентов с вебом. Мы строим Browser Run как основную платформу для ответственного использования автоматизированных браузеров в больших масштабах с надёжной безопасностью.
Перерастаем нашу двухъярусную кровать
До внедрения Cloudflare Containers мы использовали общую инфраструктуру с Browser Isolation (BISO). Хотя технически они похожи, большие образы контейнеров BISO замедляли запуск и разработку. Что ещё важнее, браузеры BISO не имели оптимального глобального распределения, что снижало отказоустойчивость и увеличивало задержку. Кроме того, длительные стабильные сессии типичных пользователей BISO конфликтовали с короткими и неравномерными нагрузками Browser Run, создавая узкие места в масштабировании и задержки доступности.
К счастью, после долгой внутренней разработки Cloudflare выпустила открытую бета-версию Containers с поддержкой Durable Object (DO) в прошлом году, и мы были готовы к пробному внедрению, которое в итоге принесло пользу обеим продуктовым платформам. Как и большинство успешных продуктовых платформ, мы стремимся создавать решения на собственной платформе везде, где это возможно, чтобы почувствовать и устранить любые болевые точки раньше внешних клиентов.
Миграция: Containers
Мы начали постепенную миграцию, вставив Worker в пути входящих запросов, чтобы предоставить небольшой группе пользователей браузеры на базе Container наряду с браузерами от BISO. Такая двойная поддержка во время разработки была ключевой: она позволила нам сравнить производительность, изолировать ошибки реализации и в конечном итоге убедиться в преимуществах подхода на основе Container.
Увеличивая внедрение, мы сначала использовали браузеры Container для всех наших конечных точек быстрых действий, затем для подключений через привязку браузера Workers для бесплатных аккаунтов, а затем для аккаунтов с оплатой по мере использования, чтобы проверить стабильность, прежде чем развернуть их для всех оставшихся контрактных клиентов, обеспечив переход, не требующий от наших клиентов никаких действий или повторного развёртывания существующих workers.
Проблемы: узкие места производительности и масштабирования
С нашей стороны, однако, мы столкнулись с новым набором проблем, осваивая незнакомый, нестабильный интерфейс платформы Containers на ранней стадии, который был скуден на документацию, скуден на наблюдаемость и скуден на коллег в пересекающемся часовом поясе. Однако наша обратная связь собственным командам в роли Клиента Ноль означала, что мы могли обеспечить тесный цикл обратной связи, приводящий к существенным улучшениям, которые приносят пользу и нашим внешним клиентам. Тем не менее, изначально было много трения, которое нужно было преодолеть, большинство из чего было ожидаемо для закрытой бета-версии в активной разработке. Другие препятствия были присущи новой технической среде.
Например, как только наши браузеры смогли работать глобально, наша архитектура должна была адаптироваться. Containers с поддержкой DO создают Durable Object как можно ближе к входящему запросу, но подключённый Container может запуститься на другом конце мира. Это хорошо работает для одноразовых сообщений вроде "запусти моё приложение", но когда вы устанавливаете WebSocket между ними и обмениваетесь десятками сообщений для запроса скриншота, эти дополнительные миллисекунды, пересекающие земной шар, начинают накапливаться.
Наше решение? Создать региональные пулы предварительно прогретых браузерных контейнеров на базе DO, чтобы ограничить максимальное расстояние (и, следовательно, максимальную задержку) между DO и контейнерами. Когда поступает запрос, мы выбираем пару DO-контейнер, наиболее близкую к пользователю в пределах этого региона. Это обеспечивает низкую задержку на обоих участках: от пользователя до DO и от DO до контейнера. Это добавляет несколько дополнительных движущихся частей в нашу общую архитектуру, но мы решили, что это стоит того, если у нас есть наблюдаемость глобального состояния каждого браузера, чтобы мы могли распределять и перераспределять мощность в соответствии с изменяющимся спросом. Идеальный вариант использования для Workers KV… до определённого момента.
Спрос на наши безголовые браузеры неуклонно рос с начала прошлого года. Короче говоря, разработчики AI-агентов обнаружили Browser Run и быстро довели объёмы запросов до уровня, превышающего нашу существующую мощность. Мы быстро достигли пределов того, как быстро мы могли регулировать ёмкость пула для обслуживания этого нового спроса с помощью масштабируемого подхода. Итоговая согласованность KV примерно за 30 секунд стала узким местом на нашем критическом пути запросов. Вы можете проверить KV, увидеть контейнер как "доступный", но к тому времени, когда вы направите к нему запрос (через 30 секунд), он уже занят. Эта задержка создаёт состояния гонки и избыточное выделение браузеров, что серьёзно ограничивает скорость, с которой мы можем масштабироваться для удовлетворения всплесков спроса.
Миграция с KV на D1 + Queues
Ранее мы хранили состояние каждого контейнера в KV. Это означало, что мы могли получать состояние с задержкой в минуту из-за TTL кэша (недавно KV изменила минимальный TTL кэша на 30 секунд, но даже это значение всё ещё слишком велико).
Мы решили перенести состояние контейнера в экземпляры D1 вместо этого. Транзакционная природа D1 хорошо подходит для этого. Как только мы назначаем браузер пользователю, он становится исключительно его. Браузеры не являются общими ресурсами. Транзакции SQLite обеспечивают атомарное назначение и предотвращают состояния гонки, когда два запроса могут одновременно запросить один и тот же браузер.
Вот упрощённая версия нашего запроса на получение браузера:
WITH candidate_pool AS (
-- логика выбора пула кандидатов на основе задержки и других правил
)
UPDATE containers
SET status = 'picked'
WHERE sessionId IN (
SELECT sessionId
FROM candidate_pool
ORDER BY RANDOM()
LIMIT ?5
)
RETURNING dataМы храним шарды D1 по местоположениям, и учитывая, что у нас может быть несколько тысяч запущенных контейнеров, и каждый контейнер должен обновлять своё состояние каждые 5 секунд, мы постоянно сталкивались с проблемой: мы перегружали базу данных. Например, если каждая запись занимает 1 мс, мы можем записывать не более 1000 раз, что при одной строке на запись означает, что мы могли бы иметь только 5000 контейнеров, прежде чем перегрузить базу данных.
Однако, если мы объединим эти записи в пакеты, мы сможем получить гораздо более высокие значения, поскольку пакетные записи ненамного длиннее отдельных, поэтому мы можем увеличить пропускную способность на порядки. В нашем случае мы используем пакеты по 100 строк, что означает, что теперь мы можем обновлять максимум 500 000 контейнеров на одно местоположение. Этот запас означает, что планирование емкости больше не является узким местом.
В настоящее время наш P95 для пакетной записи составляет 0,1 мс!
Для пакетной записи мы используем Queues: каждые 5 секунд каждый контейнер вычисляет своё состояние и добавляет его в очередь своего местоположения. Затем мы настраиваем потребителя worker с размером пакета 100 и таймаутом пакета 1 секунда:
{
...
"queues": {
"consumers": [
{
"queue": "production-core-containers-queue-weur",
"max_batch_size": 100,
"max_batch_timeout": 1,
"max_retries": 1,
},
...
]
...
}
}С этой конфигурацией мы достигаем приемлемого времени задержки значительно ниже 2 секунд. Тем не менее, очереди могут всё ещё вызывать устаревшее состояние. Когда это происходит, каждый регион переключается на назначенный резервный регион, пока основная очередь не догонит.
Дополнительные преимущества для быстрых действий
С выделенной инфраструктурой мы теперь могли обновлять образ контейнера браузера без нежелательных побочных эффектов или раздувания для других продуктов, таких как BISO. Это открыло возможность оптимизировать быстрые действия, такие как скриншоты и извлечение контента. Ранее наши рабочие устанавливали WebSocket для удаленного браузера и отправляли инструкции по одной: открыть страницу, перейти по URL, подождать загрузки и сделать скриншот. Каждый шаг должен был быть завершен до начала следующего.
Однако теперь мы отправляем все параметры в одном HTTP-запросе напрямую в контейнер, и весь поток выполняется внутри без каких-либо пересылок между рабочим и браузером.
Результаты: значительное повышение производительности и увеличение лимитов
Мы наблюдали резкое снижение среднего времени ответа быстрых действий, так как пользователи могут получать необходимое из сессии браузера быстрее: меньше времени ожидания готовности браузеров и более быстрая обработка их сообщений DevTools Protocol.
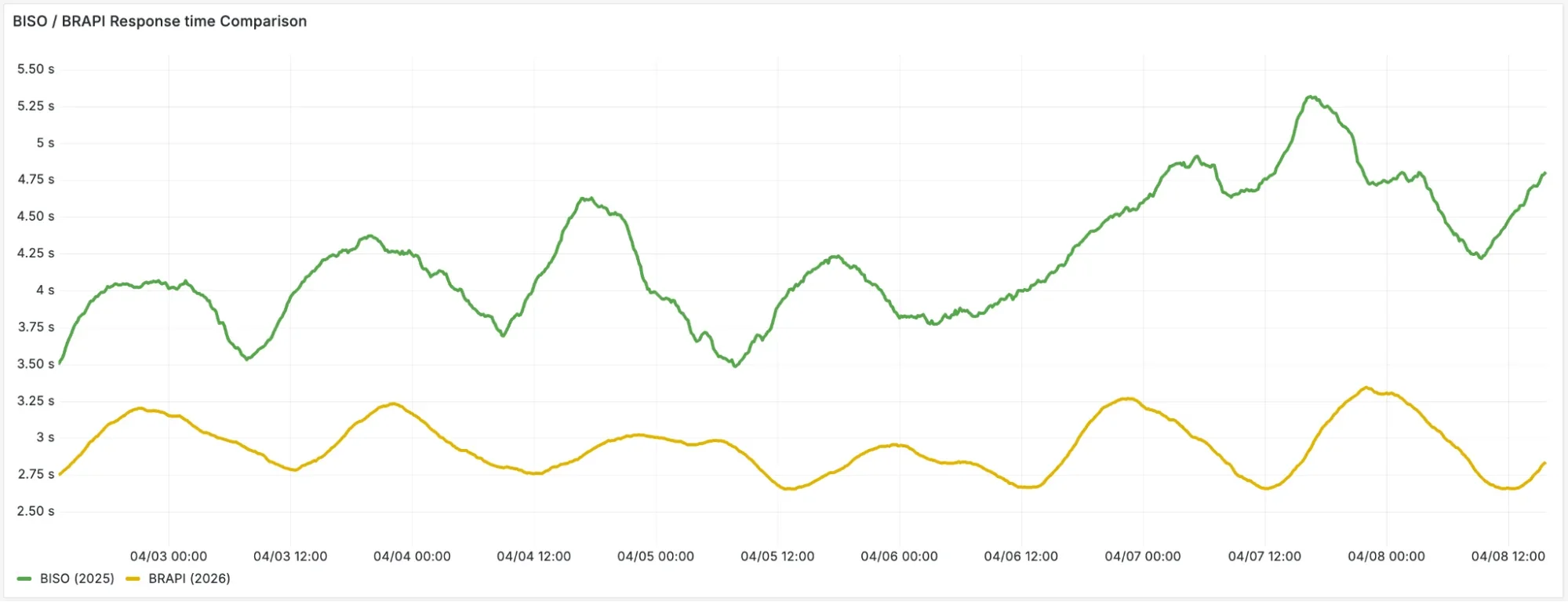
Преодоление нашего управления состоянием в реальном времени в новом масштабе означало, что мы могли проводить больше времени в "песочнице", открывая и создавая новые функции, такие как недавно запущенный /crawl endpoint.
Лучшая гибкость браузера
Мы также получили еще одно важное преимущество, отказавшись от общих контейнеров Browser Isolation: более быстрое обновление.
Когда наши браузеры работали на общей инфраструктуре продуктов, обновление Chrome требовало координации между несколькими командами и продуктами, каждый со своей дорожной картой и приоритетами. Однако теперь, когда мы запускаем собственный образ контейнера, мы можем обновляться быстрее. Например, WebGL, часто запрашиваемая функция, теперь доступна для рендеринга на основе браузера вместе с WebMCP (Model Context Protocol для веба), который открывает новые паттерны агентного взаимодействия. Оба стали возможны благодаря тому, что мы можем контролировать версию браузера и флаги без нежелательных побочных эффектов в других продуктах Cloudflare.
Вкратце, мы только начинаем раскрывать мощь браузеров в масштабе, особенно для агентного разработки. Надеемся, вы тоже погружаетесь — ознакомьтесь с нашей документацией.
Начало работы
Browser Run доступен на всех тарифных планах Workers. Начните с краткого руководства, изучите Quick Actions или попробуйте /crawl endpoint для глубокого извлечения данных с любой веб-страницы, переходя по ссылкам на сайте.