CUBIC, стандартизированный в RFC 9438, является контроллером перегрузки по умолчанию в Linux и, как следствие, управляет тем, как большинство TCP- и QUIC-соединений в публичном интернете зондируют доступную пропускную способность, сбрасывают скорость при обнаружении потерь и восстанавливаются после этого. В Cloudflare наша реализация QUIC с открытым исходным кодом, quiche, использует CUBIC в качестве контроллера перегрузки по умолчанию, что означает, что этот код находится на критическом пути для значительной доли трафика, который мы обслуживаем.
В этой статье мы расскажем историю ошибки, из-за которой окно перегрузки (cwnd) CUBIC навсегда застревает на минимальном значении и никогда не восстанавливается после события коллапса перегрузки.
История начинается с изменения в ядре Linux, направленного на приведение CUBIC в соответствие с исключением для приложений с ограниченной отправкой, описанным в RFC 9438 §4.2-12 — это исправление реальной проблемы в TCP, которое при переносе в нашу реализацию QUIC выявило неожиданное поведение в quiche. У этой истории счастливый конец: элегантное (почти) однострочное исправление, которое разорвало этот цикл.
Логика CUBIC в двух словах
Прежде чем мы углубимся в основную проблему, краткое напоминание о CCA (алгоритмах управления перегрузкой) может помочь задать контекст.
Центральный параметр, которым управляет CCA — это окно перегрузки (cwnd): ограничение со стороны отправителя на количество байт, которые могут находиться в полёте (отправлены, но ещё не подтверждены) в любой момент времени. Большее cwnd позволяет отправителю передавать больше данных за один круг; меньшее cwnd его ограничивает. Каждый CCA, основанный на потерях, включая CUBIC, в конечном счёте представляет собой политику того, как увеличивать cwnd, когда сеть выглядит здоровой, и как уменьшать его, когда это не так.
По сути, CCA стремятся максимизировать передачу данных, оценивая «доступную пропускную способность» сети; ведь никто не хочет платить за подписку на 1 Гбит/с и использовать лишь её часть. Семейство алгоритмов, основанных на потерях, к которому принадлежит CUBIC, работает на фундаментальной предпосылке: (1) если потерь пакетов нет, увеличивайте скорость отправки (т.е. увеличивайте загрузку канала); (2) если есть потери, алгоритмы на основе потерь предполагают, что ёмкость сети превышена, и отправитель должен снизить скорость (т.е. уменьшить загрузку канала).
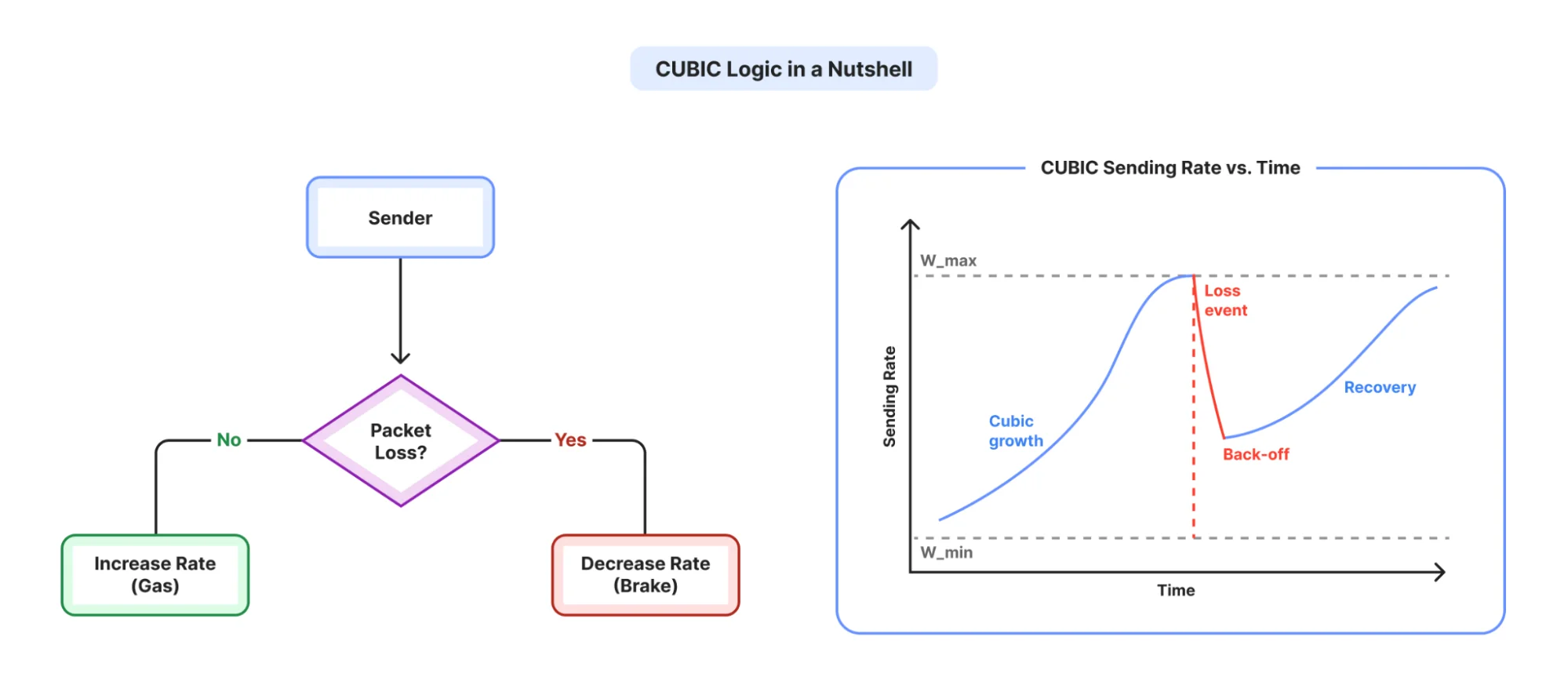
Эта логика основана на нескольких допущениях, которые пересматривались с годами. Однако мы оставим это обсуждение на другой раз.
Симптом: тест, который проваливается в 61% случаев
Наше расследование началось с сообщения о неожиданных сбоях в тестовом конвейере интеграции нашего входящего прокси. Это нерегулярное поведение проявилось в тестах, где CUBIC оценивался в сценарии с большими потерями в начале соединения.
Восстановление после коллапса перегрузки — это необычный режим, но именно для его обработки и существует контроллер перегрузки. Большинство тестов управления перегрузкой проверяют установившееся состояние и фазы роста алгоритма; гораздо меньше тестов исследуют, что происходит при минимальном cwnd, после того как соединение было «побито». Ошибки в этом углу пространства состояний не видны на информационных панелях пропускной способности, не обнаруживаются при статическом анализе кода и проявляются только тогда, когда вы намеренно загоняете CCA в это состояние и наблюдаете, сможет ли оно выбраться обратно — именно это и делал данный тест.
Тестовая установка включает следующие детали:

-
Клиент и сервер Quiche HTTP/3 работают локально (localhost)
-
RTT = 10 мс (установлено в конфигурации)
-
Загрузка файла размером 10 МБ по протоколу HTTP/3
-
Используется управление перегрузкой CUBIC
-
В течение первых двух секунд внедряются случайные потери пакетов с вероятностью 30%
-
Через две секунды потери полностью прекращаются
-
Тест имеет щедрый 10-секундный тайм-аут для завершения загрузки, которая, как ожидается, должна завершиться за четыре или пять секунд
Ожидаемое поведение очевидно: CUBIC должен понести некоторые потери во время фазы потерь, уменьшить своё окно перегрузки, а после прекращения потерь плавно увеличить его и завершить загрузку задолго до тайм-аута. Вместо этого мы наблюдали в нескольких прогонах по 100 раз, что около 60% наших тестов не смогли завершить загрузку в течение щедрого 10-секундного тайм-аута.
Аномалия: 999 переходов состояния при нулевых потерях
Мы добавили в вывод qlog quiche инструментирование событий потери пакетов и создали визуализации, чтобы понять, что происходит внутри контроллера перегрузки:
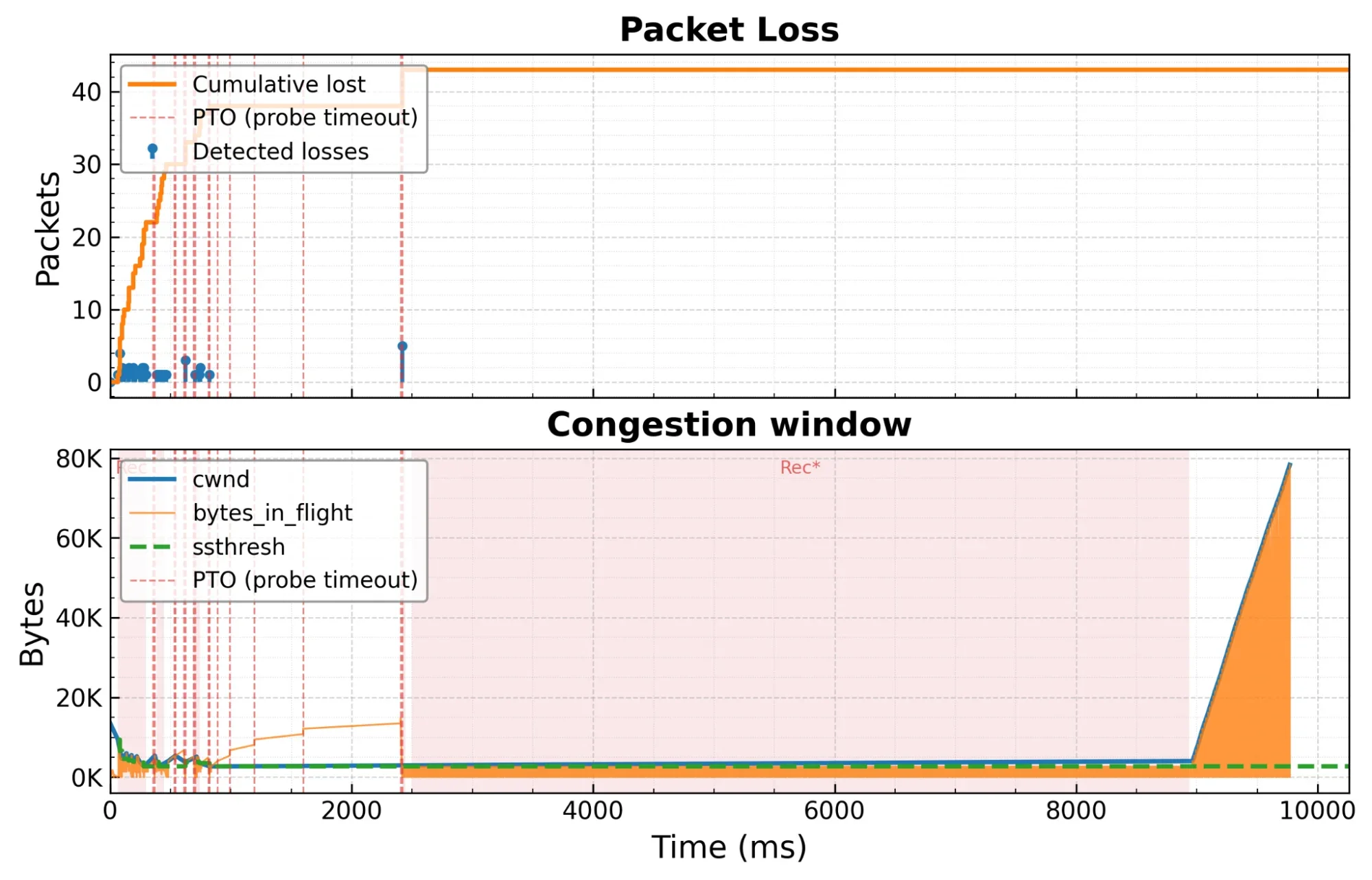
Обзор соединения для провалившегося теста. После T=2 с потери пакетов полностью прекращаются — однако cwnd остаётся заблокированным на минимальном уровне, а состояние перегрузки колеблется между восстановлением и предотвращением перегрузки каждые ~14 мс.
После отметки в две секунды (2000 мс) потери пакетов полностью прекращаются. Однако количество байт в полёте остаётся плоским, что противоречит основной логике алгоритма CUBIC: при отсутствии потерь следует увеличивать «газ» (больше байт в нашем мире). Отсюда возникает вопрос: если сеть больше не теряет пакеты, почему окно перегрузки не растёт?
Когда мы приближаем эту область, наш анализ показывает, что CUBIC входит в быстрые колебания, показанные на нашем графике как расширенная фаза восстановления, между состоянием предотвращения перегрузки (операционный режим) и состоянием восстановления (режим восстановления после потери пакетов) — 999 переходов примерно за 6,7 секунды. Это один переход каждые ~14 мс — что подозрительно близко к RTT соединения (10 мс). В течение всего этого периода cwnd зафиксирован на минимальном уровне: 2700 байт, или два полных пакета.
Очевидно, что что-то в логике CUBIC неправильно интерпретирует состояние соединения. Ключевая подсказка — период колебаний: ~14 мс совпадает с RTT. То, что вызывает переключение между восстановлением и предотвращением, происходит один раз за круговой обход, в такт с ACK-часами соединения; самосинхронизирующийся ритм, в котором ACK-пакеты каждого кругового обхода от клиента запускают следующую отправку сервера. Поскольку это загрузка (от сервера к клиенту), соответствующие ACK-пакеты путешествуют от клиента к серверу, и конечный автомат CUBIC выполняется на стороне сервера: каждый раз, когда приходят эти ACK-пакеты, bytes_in_flight падает до нуля, и сервер отправляет следующую порцию из двух пакетов, что и вызывает ошибку.
Чтобы подтвердить, что это поведение свойственно именно CUBIC, мы запустили тот же тест с Reno, другим представителем семейства основанных на потерях алгоритмов, но с другой скоростью роста. Результаты были однозначными: 100% прохождение, Reno чисто восстановился после фазы потерь, что выявило: это ошибка, связанная с CUBIC.
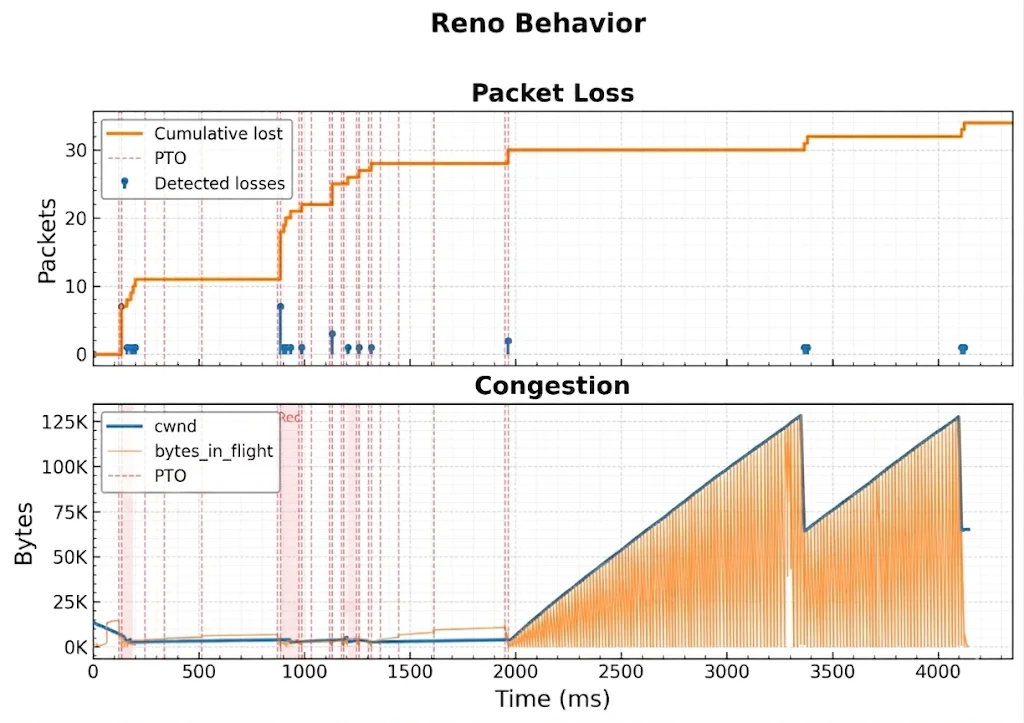
Reno чисто восстанавливается после окончания фазы потерь в T=2 с и завершает загрузку примерно за 5 с
Поиск первопричины
У алгоритмов, основанных на потерях, есть две педали: газ и тормоз, с разницей в том, как они ускоряются. Что ж, у CUBIC есть некоторые дополнительные функции. Здесь мы сосредоточимся на случае, когда bytes_in_flight == 0.
CUBIC TCP после бездействия (Linux, 2017)
Чтобы понять ошибку, сначала нужно понять оптимизацию, из которой она возникла. В 2017 году была обнаружена проблема в реализации CUBIC в ядре Linux. Сообщение коммита объясняет:
Эпоха обновляется/сбрасывается только изначально и при возникновении потерь. Разность «t» =
now - epoch_startможет быть произвольно большой после бездействия приложения, как иbic_target. Следовательно, наклон (обратная величинаca->cnt) будет очень большим, и в конечном итогеca->cntбудет ограничен снизу значением 2 для имитации поведения медленного старта с отложенными ACK.Это особенно заметно, когда
slow_start_after_idleотключено, что приводит к опасному раздуванию cwnd (1,5 x RTT) после нескольких секунд бездействия.
Эпоха — это временная метка, которую CUBIC использует как точку привязки для своей кривой роста: W_cubic(delta_t) параметризуется delta_t = now - epoch_start, и эпоха сбрасывается всякий раз, когда CUBIC перезапускает свою функцию роста — в первую очередь после события потери, уменьшающего cwnd. Между сбросами delta_t монотонно растёт вместе с реальным временем.
Когда приложение бездействует (прекращает отправку) на некоторое время, а затем возобновляет работу, функция роста CUBIC W_cubic(delta_t) вычисляет delta_t как now - epoch_start, как показано на рисунке ниже. Поскольку эпоха не обновлялась во время бездействия, delta_t становится огромным, что даёт чрезвычайно большой целевой размер окна — и CUBIC немедленно попытается раздуть cwnd до необоснованного значения.
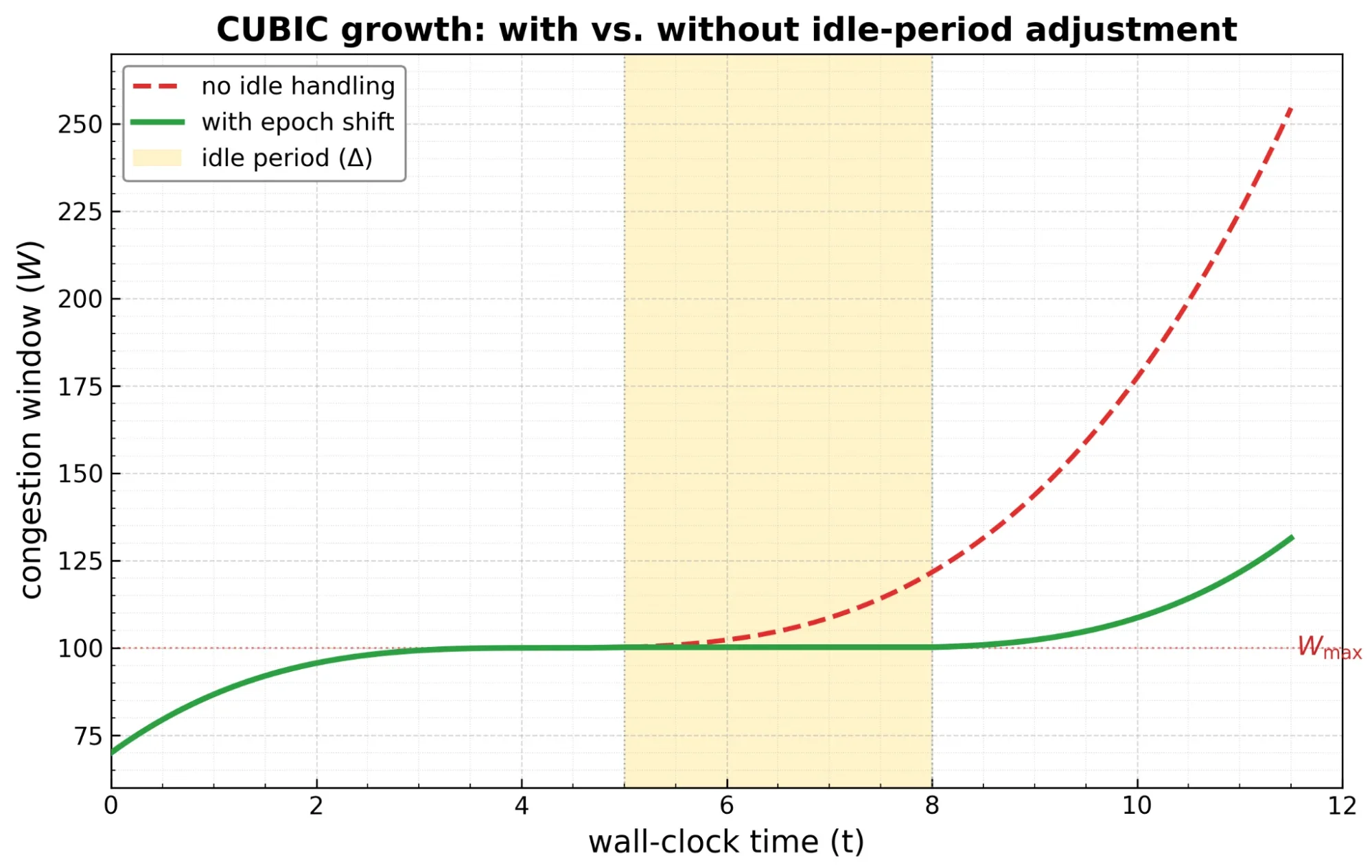
Первоначальное исправление Яны Айенгара заключалось в сбросе `epoch_start` при возобновлении отправки приложением. Но Нил Кардуэлл указал на недостаток такого подхода:
…это заставило бы алгоритм CUBIC пересчитать кривую так, чтобы мы снова начали круто расти вверх от текущего значения cwnd (как CUBIC делает сразу после потери). В идеале мы хотим, чтобы кривая роста cwnd имела ту же форму, просто сдвинутую во времени на величину периода бездействия.
Элегантное решение, созданное Эриком Дюмазе, Ючэн Чэном и Нилом Кардуэллом, заключалось в том, чтобы сдвинуть эпоху вперёд на длительность бездействия, а не сбрасывать её. Это сохраняет форму кривой роста CUBIC — просто сдвигает её во времени, так что алгоритм продолжает с того места, где остановился.
Портирование в quiche (2020)
Когда CUBIC был впервые реализован в quiche, эта корректировка периода бездействия была портирована. Однако QUIC, работающий в пользовательском пространстве, не имеет колбэка CA_EVENT_TX_START на уровне ядра, как в TCP. Вместо этого реализация quiche проверяет условие бездействия внутри on_packet_sent():
// cubic.rs — on_packet_sent() (упрощённо)
/// Обновляет состояние при отправке пакета.
fn on_packet_sent(&mut self, bytes_in_flight: usize, now: Instant, ...) {
// Если отправка возобновляется (т.е. bytes_in_flight был нулевым до этой отправки),
// корректируем время начала восстановления после перегрузки с учётом паузы в отправке.
if bytes_in_flight == 0 {
let delta = now - self.last_sent_time;
self.congestion_recovery_start_time += delta;
}
// Записываем время этого события отправки.
self.last_sent_time = now;
}Где это ломается: отличие QUIC
Исправление, портированное в quiche, содержало ошибку из исходного изменения ядра, которая была исправлена дополнительным изменением модуля ядра cubic примерно через неделю. Сообщение коммита второго исправления объясняет:
tcp_cubic: не устанавливайтеepoch_startв будущем Отслеживание времени бездействия вbictcp_cwnd_event()неточно, так какepoch_startобычно устанавливается во время обработки ACK, а не во время отправки.Правильное исправление потребовало бы добавления дополнительной переменной состояния, и это не стоит хлопот, учитывая, что ошибка CUBIC была там всегда, до того как Яна заметила её.
Давайте просто не будем устанавливать
epoch_startв будущем, иначеbictcp_update()может переполниться, и CUBIC снова будет слишком быстро увеличиватьcwnd.
Как упоминалось в сообщении коммита, время начала восстановления устанавливается во время обработки ACK, и вычисление корректировки на основе времени отправки может сдвинуть время начала восстановления в будущее. Это объясняет колебания между восстановлением и предотвращением перегрузки, наблюдавшиеся в нашем тесте. Ловушка срабатывает стабильно только тогда, когда каждый входящий ACK обнуляет bytes_in_flight — что на практике означает, что cwnd уменьшился до минимума (два пакета), а приложение готово отправить ещё одно полное окно сразу после получения ACK. Вне этого режима условие bytes_in_flight == 0 с меньшей вероятности выполняется при каждой отправке, поэтому ошибка проявляется реже.
Почему это не происходит также при запуске соединения? Ошибка срабатывает только когда соединение выходит из медленного старта и переключается на предотвращение перегрузки. До выхода из медленного старта congestion_recovery_start_time не установлен, поэтому ошибочная ветвь в on_packet_sent не имеет границы восстановления, которую можно было бы сдвинуть. Во время медленного старта cwnd CUBIC растёт по тому же правилу Reno на основе ACK, общему для всех CCA, основанных на потерях — кубическая кривая и её чувствительность к congestion_recovery_start_time вступают в игру только когда соединение переходит в режим предотвращения перегрузки. Таким образом, ловушке нужны три условия одновременно: реальное событие потери для установки границы восстановления, активный режим предотвращения перегрузки и cwnd, сжавшийся до минимального уровня в два пакета.
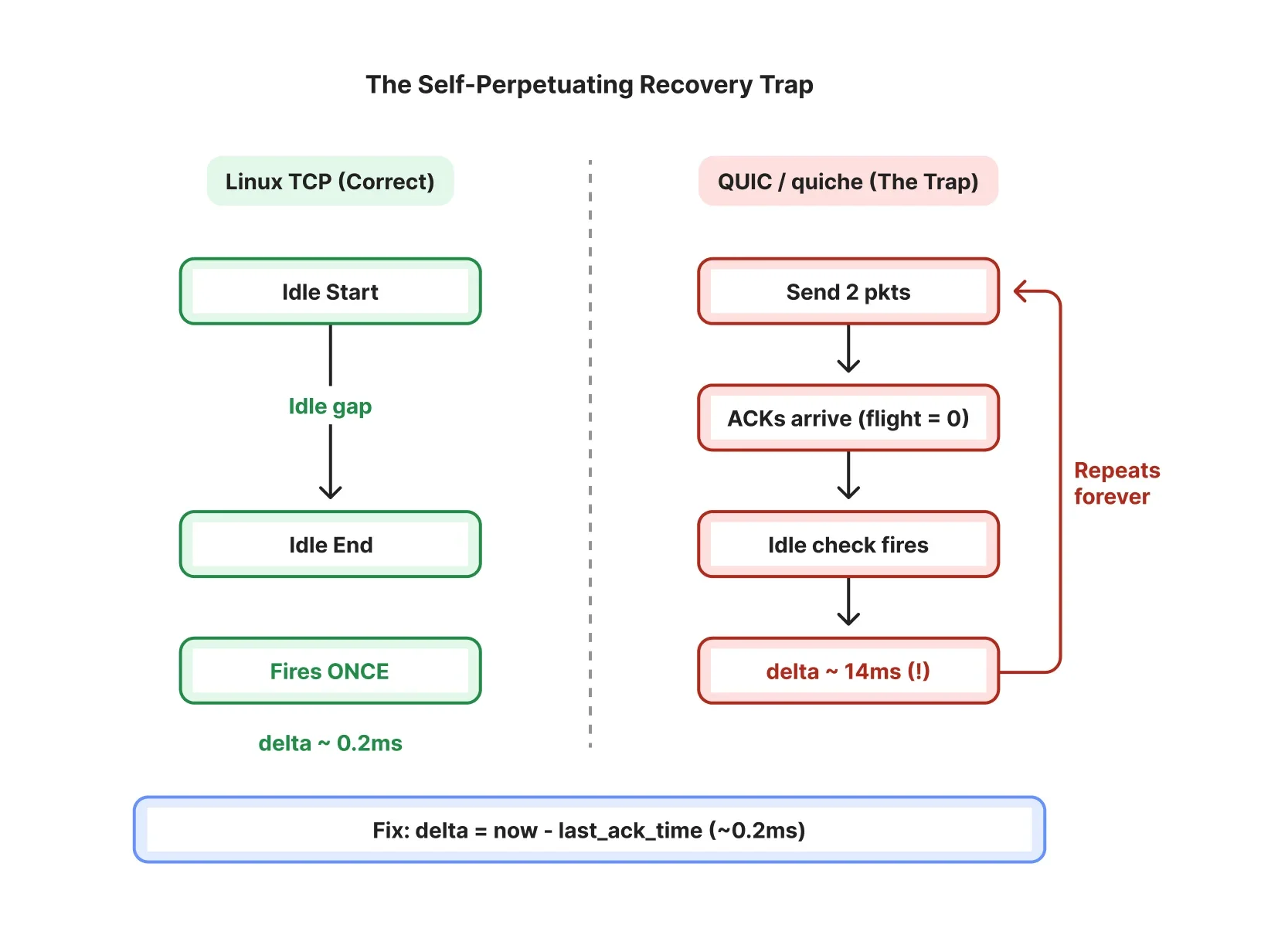
Самоувековечивающаяся ловушка восстановления. При минимальном cwnd каждый цикл ACK запускает корректировку периода бездействия с завышенной дельтой.
При минимальном cwnd (два пакета) динамика соединения переходит в «спираль смерти», где оптимизация периода бездействия становится самосбывающимся пророчеством. Эта ловушка работает в непрерывном цикле:
-
Отправка и подтверждение пакетов: Отправитель передаёт всё окно из двух пакетов. Через один RTT (~14 мс) оба пакета подтверждаются, и bytes_in_flight падает до нуля.
-
Ложное обнаружение бездействия: При следующей отправке on_packet_sent() видит bytes_in_flight == 0 и предполагает, что соединение было бездействующим, хотя на самом деле оно было ограничено перегрузкой.
-
Завышенная дельта: Расчёт использует now - last_sent_time для определения длительности бездействия. Когда окно перегрузки (
cwnd) минимально,last_sent_time— это временная метка начала предыдущего цикла RTT. Таким образом, полученная дельта составляет примерно 14 мс (RTT соединения + дополнительные ошибки округления). Эта дельта размером с RTT ошибочно применяется как время «бездействия». Фактическое время простоя соединения (промежуток между приходом последнего ACK и отправкой следующего пакета) практически равно нулю. Измеряя полный RTT вместо реального промежутка, дельта значительно завышается, агрессивно сдвигая время начала восстановления вперёд, возможно, в будущее. -
Восприятие восстановления: Поскольку время начала восстановления теперь в будущем, проверка
in_congestion_recovery()возвращает true для каждого входящего ACK. Обработка следующего ACK выходит из восстановления и устанавливает время начала восстановления равным времени ACK, которое больше чем last_sent_time, что увеличивает вероятность того, что контроллер перегрузки сдвинет время восстановления в будущее при следующей отправке. -
Застой: Поскольку CUBIC пропускает рост
cwndдля любого пакета, воспринимаемого как находящийся в периоде восстановления, окно остаётся зафиксированным на двух пакетах — это гарантирует, что при следующем ACK канал полностью опустошится, и цикл начнётся заново.
И этот цикл повторяется тысячи раз, пока накопление небольших отклонений — из-за дрожания планировщика и вариаций обработки ACK — не позволит границе <= в in_congestion_recovery() отстать от времени отправки следующего пакета, разрывая цикл.
Исправление: измерение бездействия с правильного момента
Исправление спирали смерти включает измерение длительности бездействия с момента, когда bytes_in_flight фактически перешёл в ноль (момент обработки последнего ACK), а не с момента последней отправки пакета.
Изменение кода
-
Добавить временную метку last_ack_time в состояние CUBIC.
-
Обновлять эту метку при поступлении ACK.
-
Использовать её для вычисления дельты бездействия:
// cubic.rs — on_packet_sent()
fn on_packet_sent(&mut self, bytes_in_flight: usize, now: Instant, ...) {
// Проверяем, было ли соединение бездействующим перед отправкой этого пакета.
if bytes_in_flight == 0 {
if let Some(recovery_start_time) = r.congestion_recovery_start_time {
// Измеряем бездействие от самого последнего действия: либо
// последнего ACK (аппроксимируя момент, когда bif стал 0), либо
// последней отправки данных — выбираем более позднее.
// Использование только last_sent_time привело бы к завышению
// дельты на целый RTT, когда cwnd мал и bif временно
// падает до 0 между ACK и отправкой.
let idle_start = cmp::max(cubic.last_ack_time, cubic.last_sent_time);
if let Some(idle_start) = idle_start {
if idle_start < now {
let delta = now - idle_start;
r.congestion_recovery_start_time =
Some(recovery_start_time + delta);
}
}
}
}Теперь, когда дельта отражает фактический промежуток с момента последнего ACK, граница восстановления перестаёт «догонять» время отправки:
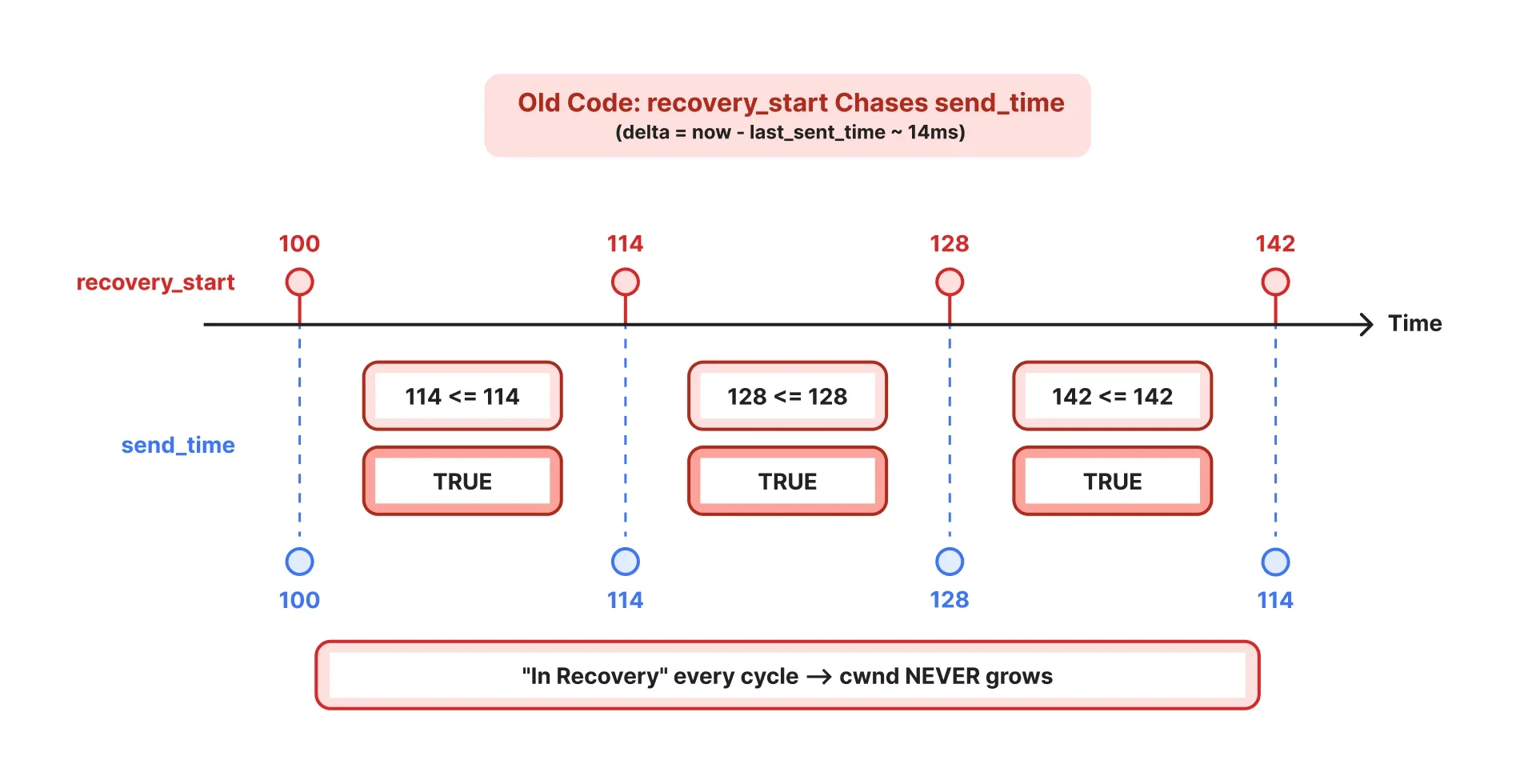
Старый код: граница сдвигается на один RTT за цикл, всегда оказываясь на или перед следующей отправкой.
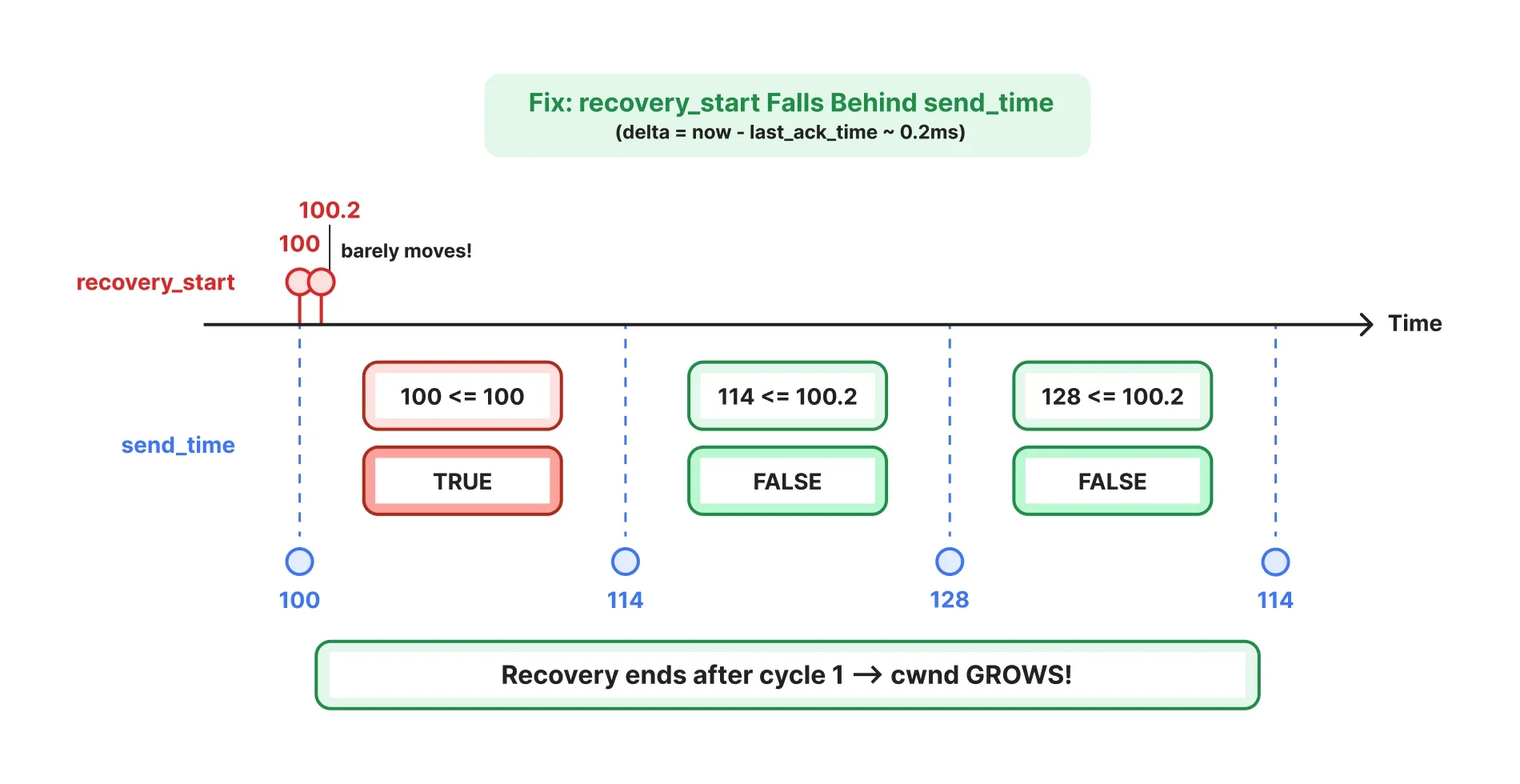
Исправление: граница почти не сдвигается; следующая отправка оказывается позже неё, и cwnd растёт.
Для действительно бездействующих соединений last_ack_time находится далеко в прошлом, и то же выражение захватывает полную длительность бездействия, сохраняя исходное поведение сдвига эпохи.
Проверка
После применения исправления 100% прохождение тестов нашего набора quiche было восстановлено.
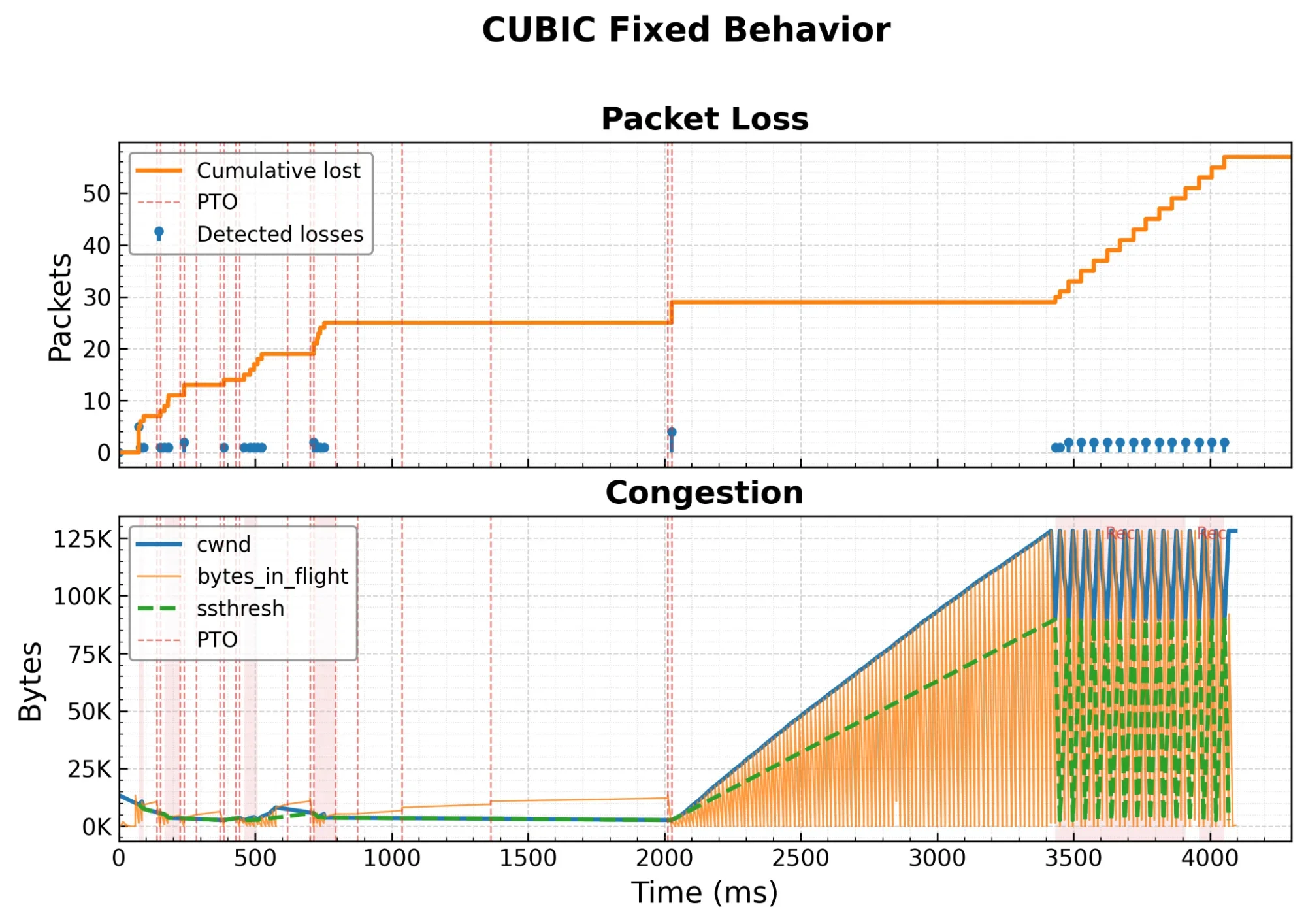
После исправления cwnd растёт вдоль ожидаемой кривой CUBIC, и загрузка завершается примерно за 4–5 секунд.
Мы не беспокоимся о потерях в конце соединения — это ожидаемо, так как мы полностью использовали выделенный буфер маршрутизатора. Другими словами, в этом тестовом случае мы полностью используем доступную пропускную способность.
Выводы
-
«Простой» определить сложнее, чем кажется. Обычные задержки конвейера при маленьких окнах могут выглядеть как простой для простых проверок.
-
Динамика минимального cwnd — уникальный крайний случай. Баг был незаметен на высоких скоростях и срабатывал только после серьезной потери.
-
Исправление оказалось удивительно небольшим по сравнению со сложностью поведения. После недель инструментирования qlogs и анализа визуализаций для поиска первопричины решение потребовало изменения всего трех строк кода. Как мы отметили во время расследования: усилия по поиску бага были огромными, но само исправление — по сути, одна строка логики.
Исправление, описанное в этой статье, было внесено в cloudflare/quiche, открытую реализацию QUIC и HTTP/3 от Cloudflare. Наши усилия по CCA выходят за рамки алгоритмов, основанных на потерях: мы также используем модульную конструкцию управления перегрузкой quiche для экспериментов и настройки нашей модельной реализации BBRv3, которая теперь включена для растущей доли наших развертываний QUIC. Оставайтесь с нами для дальнейших обновлений о реализации и производительности управления перегрузкой QUIC.