За последние два с небольшим квартала мы провели интенсивную инженерную работу, имеющую внутреннее кодовое название «Code Orange: Fail Small», направленную на повышение устойчивости, безопасности и надежности инфраструктуры Cloudflare для каждого клиента.
Ранее в этом месяце команда Cloudflare завершила эту работу.
Хотя повышение отказоустойчивости никогда не будет «завершенной задачей» и всегда будет главным приоритетом на всех этапах разработки, мы завершили работы, которые позволили бы избежать глобальных сбоев 18 ноября 2025 года и 5 декабря 2025 года.
Эта работа была сосредоточена на нескольких ключевых областях: более безопасное изменение конфигураций, снижение влияния сбоев, а также пересмотр процедур экстренного доступа («break glass») и управления инцидентами. Мы также внедрили меры для предотвращения отклонений и регрессов с течением времени, а также усилили способы информирования наших клиентов во время сбоя.
Здесь мы подробно объясняем, что мы запустили, и что это значит для вас.
Более безопасное изменение конфигураций
Что это значит для вас: В большинстве случаев внутренние изменения конфигурации Cloudflare больше не достигают нашей сети мгновенно, а развертываются постепенно с мониторингом состояния в реальном времени. Это позволяет нашим инструментам наблюдения выявлять проблемы и откатывать изменения до того, как они повлияют на ваш трафик.
Чтобы выявлять потенциально опасные развертывания до того, как они достигнут продакшена, мы определили конвейеры конфигураций высокого риска и создали новые инструменты для более качественного управления изменениями конфигураций.
Для продуктов, которые работают в нашей сети, обрабатывают клиентский трафик и получают изменения конфигурации, мы больше не развертываем эти изменения мгновенно по всей сети. Вместо этого соответствующие команды приняли методологию «развертывания с контролем состояния» (которую мы используем при выпуске программного обеспечения) для всех развертываний конфигураций. Это распространяется, помимо прочего, на продуктовые команды, на которые напрямую повлияли инциденты.
Ключевую роль в этом играет новый внутренний компонент, который мы называем Snapstone. Мы создали его для внедрения развертывания с контролем состояния для изменений конфигурации. Snapstone — это система, которая объединяет изменение конфигурации в пакет, а затем обеспечивает постепенный выпуск изменения конфигурации с использованием принципов контроля состояния. До появления Snapstone применение этой методологии к конфигурациям было возможным, но сложным. Оно требовало значительных усилий от каждой команды и не применялось последовательно по всей сети. Snapstone устраняет этот пробел, предоставляя унифицированный способ обеспечения постепенного развертывания, мониторинга состояния в реальном времени и автоматического отката для развертываний конфигураций по умолчанию.
Особую мощь Snapstone придает его гибкость. Вместо того чтобы быть исправлением для конкретных прошлых сбоев, Snapstone позволяет командам динамически определять любую единицу конфигурации, требующую контроля состояния, будь то файл данных, подобный тому, что вызвал сбой 18 ноября, или управляющий флаг в нашей глобальной системе конфигурации, подобный тому, что был задействован в сбое 5 декабря. Команды создают эти единицы конфигурации по требованию, и Snapstone гарантирует их безопасное развертывание везде, где они используются.
Это дает нам то, чего у нас не было раньше: когда анализ рисков или операционный опыт выявляет опасный шаблон конфигурации, исправление становится очевидным — перенести его в Snapstone, и этот шаблон конфигурации немедленно получает безопасное развертывание.
Снижение влияния сбоев
Что это значит для вас: В случае возникновения проблемы в нашей сети наши системы теперь отказывают более корректно. Это значительно снижает потенциальный радиус воздействия, гарантируя доставку вашего трафика даже в наихудших сценариях.
Продуктовые команды тщательно проанализировали, как в ручном, так и в программном режиме, потенциальные режимы отказов для продуктов, критически важных для обслуживания клиентского трафика. Команды удалили необязательные зависимости времени выполнения и внедрили более совершенные режимы отказов. Теперь мы будем использовать последнюю известную рабочую конфигурацию, где это возможно («отказ с устаревшими данными»), а если это невозможно, мы рассмотрели каждый случай отказа и внедрили «отказ с продолжением работы» или «отказ с остановкой» в зависимости от того, что предпочтительнее: обслуживать трафик с ограниченной функциональностью или не обслуживать трафик вовсе.
Рассмотрим пример того, как это работает. Наш сбой в ноябре 2025 года был вызван неудачным развертыванием классификатора машинного обучения для обнаружения Bot Management. Согласно нашим новым процедурам, если бы снова были сгенерированы данные, которые наша система не смогла бы прочитать, система отказалась бы использовать обновленную конфигурацию и вместо этого использовала бы старую. Если бы старая конфигурация по какой-то причине была недоступна, система продолжила бы работу в режиме «отказа с продолжением», чтобы обеспечить обслуживание производственного трафика клиентов, что гораздо лучше, чем простой.
В результате, если бы то же самое изменение Bot Management, которое вызвало сбой в ноябре, было развернуто сейчас, система обнаружила бы сбой на ранней стадии развертывания, до того, как он затронул бы более чем небольшой процент трафика.
Мы также начали дальнейшую сегментацию нашей системы, так что независимые копии сервисов работают для разных когорт трафика. Cloudflare уже использует эти клиентские когорты для уменьшения радиуса взрыва с помощью методов управления трафиком, и эта дополнительная работа по сегментации процессов обеспечивает нам мощную возможность повышения надежности в будущем.
Например, система выполнения Workers сегментирована на несколько независимых сервисов, обрабатывающих разные когорты трафика, причем один из них обрабатывает только трафик наших бесплатных клиентов. Изменения развертываются в этих сегментах на основе клиентских когорт, начиная с бесплатных клиентов. Мы также отправляем обновления быстрее и чаще в наименее критичные сегменты и медленнее — в наиболее критичные.
В результате, если бы изменение было развернуто в системе выполнения Workers и нарушило трафик, оно теперь затронуло бы лишь небольшой процент наших бесплатных клиентов, после чего было бы автоматически обнаружено и откачено.
Продолжая использовать систему выполнения Workers в качестве примера: за семидневный период ранее в этом месяце процесс развертывания запускался более 50 раз. Вы можете увидеть, как каждый запуск происходит «волнами» по мере распространения изменения на периферию, часто параллельно с предыдущим и последующим релизами:
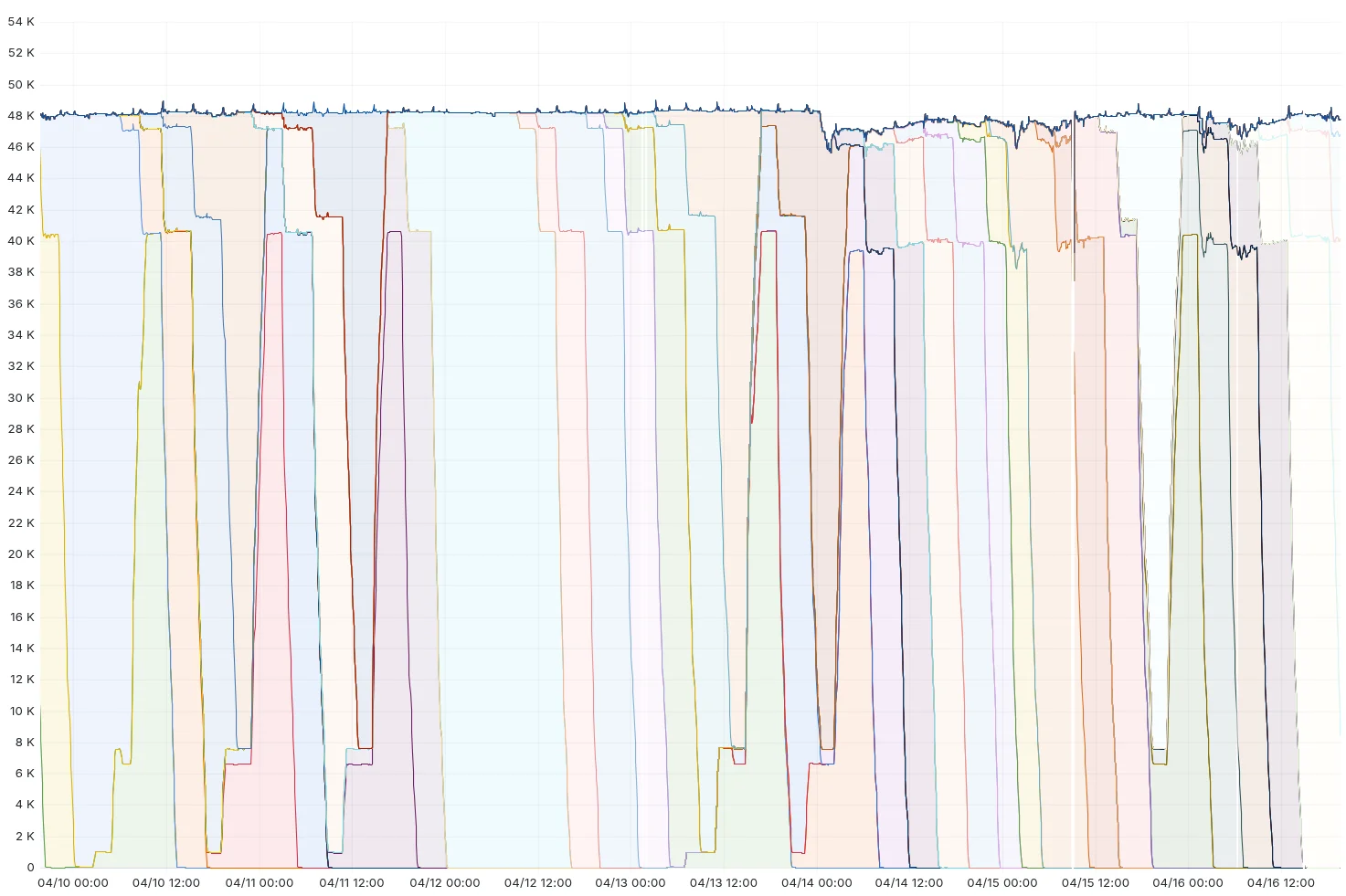
Мы работаем над расширением этой модели развертывания на многие другие наши системы в будущем.
Пересмотренные процедуры экстренного доступа («break glass») и управления инцидентами
Что это значит для вас: Если инцидент все же произойдет, у нас есть инструменты и команды, чтобы общаться более четко и устранять его быстрее, минимизируя время простоя.
Cloudflare работает на Cloudflare. Мы используем собственные продукты Zero Trust для защиты нашей инфраструктуры, но это создает зависимость: если общесетевой сбой повлияет на эти инструменты, мы потеряем те самые пути, которые необходимы для их исправления. До начала этой инициативы Code Orange наши пути экстренного доступа были ограничены горсткой людей и предоставляли ограниченный доступ к инструментам. Нам нужно было, чтобы эти инструменты и пути были более широко доступны во время сбоя.
Чтобы решить эту проблему, мы провели всесторонний аудит инструментов, необходимых для видимости системы, отладки и внесения производственных изменений. В конечном итоге мы разработали резервные пути авторизации для 18 ключевых сервисов, подкрепленные новыми аварийными скриптами и прокси.
На протяжении программы Code Orange мы перешли от теории к практике. После упражнений с малыми группами мы провели общеинженерные учения 7 апреля 2026 года, в которых приняли участие более 200 членов команды. Хотя автоматизация поддерживает эти пути в рабочем состоянии, такие учения гарантируют, что наши инженеры обладают мышечной памятью для их использования под давлением.
Эта работа также была сосредоточена на потоке информации. Когда нарушается внутренняя видимость, наше реагирование на инциденты замедляется, а способность общаться с внешним миром страдает. Исторически сложилось так, что технические наблюдения, сделанные в пылу событий, не всегда превращались в четкие обновления для наших клиентов.
Чтобы преодолеть этот разрыв, мы создали специальную команду по коммуникациям, которая будет работать в тесной связке с реагирующими на инциденты во время крупных событий. Так же, как наши инженеры отрабатывали свои процедуры экстренного доступа, эта команда использовала программу Code Orange для отработки оптимизации частоты и ясности обновлений для клиентов. Обеспечив как инструменты для наблюдения, так и структуру для общения, мы можем быстрее устранять инциденты и лучше информировать наших клиентов.
Мы закрепили наши улучшения
Что это значит для вас: Мы запомним уроки, извлеченные из наших инцидентов, и закрепим их решения. Наша сеть будет становиться только более отказоустойчивой.
Чтобы со временем избежать отклонений и повторного внесения регрессий в работу, проделанную в рамках Code Orange, команда создала внутренний Кодекс, который закрепляет все наши руководства в четких и лаконичных правилах.
Кодекс теперь обязателен для всех инженерных и продуктовых команд и стал центральной частью внутренних процедур Cloudflare. Его правила применяются с помощью проверок кода на основе ИИ, которые автоматически выделяют любые случаи, которые могут отклоняться от руководств, требуя проведения дополнительных ручных проверок. Это применяется без исключения ко всей нашей кодовой базе. Цель проста: создать институциональную память, которая сама себя поддерживает.
Сбои в ноябре и декабре имели общий сценарий отказа: код, который предполагал, что входные данные всегда будут корректными, без корректной деградации, когда это предположение нарушалось. Сервис на Rust вызывал .unwrap() вместо обработки ошибки; код на Lua обращался к несуществующему объекту. Оба паттерна можно предотвратить, если извлечь уроки и соблюдать их.
Codex — часть нашего ответа. Это живой репозиторий инженерных стандартов, написанных экспертами в своих областях через процесс Request For Comments (RFC), а затем превращённых в практические правила. Лучшие практики, которые ранее хранились в головах старших инженеров или обнаруживались только после инцидента, теперь становятся общим знанием, доступным каждому. Каждое правило следует простому формату: «Если вам нужно X, используйте Y» со ссылкой на RFC, где объясняется почему.
Например, один RFC теперь гласит: «Не используйте .unwrap() за пределами тестов и `build.rs`». Другой описывает более общий принцип: «Сервисы ОБЯЗАНЫ проверять, что вышестоящие зависимости находятся в ожидаемом состоянии, перед обработкой».
Если бы эти правила соблюдались раньше, сбои в ноябре и декабре были бы отклонёнными запросами на слияние, а не глобальными инцидентами.
Правила без принуждения — это просто рекомендации. Codex интегрируется с агентами на базе ИИ на каждом этапе жизненного цикла разработки ПО: от проверки дизайна до развёртывания и анализа инцидентов. Это сдвигает контроль влево: от «глобального сбоя» к «отклонённому запросу на слияние». Радиус поражения нарушения сокращается с миллионов затронутых запросов до одного разработчика, получающего практическую обратную связь до того, как его код попадёт в продакшн.
Codex — это живой документ, который будет постоянно улучшаться. Эксперты в предметных областях пишут RFC для формализации лучших практик. Инциденты выявляют пробелы, которые становятся новыми RFC. Каждый одобренный RFC порождает правила Codex. Эти правила питают агентов, которые проверяют следующий запрос на слияние. Это маховик: экспертиза превращается в стандарты, стандарты — в контроль, контроль поднимает планку для всех.
Дело не только в коде: ключевая роль коммуникации
Что это значит для вас: Прозрачность важна для нас. Если что-то пойдёт не так, мы обязуемся информировать вас на каждом этапе, чтобы вы могли сосредоточиться на том, что для вас важно.
Глобальные сбои заставили нас пересмотреть основные процессы и культурные подходы не только в инженерии и разработке продуктов. В рамках более широких инициатив Code Orange мы ввели дополнительные цели уровня обслуживания (SLO) для всех наших сервисов, внедрили глобальный журнал изменений, подключили все команды к нашей системе координации обслуживания и повысили прозрачность по всей компании в отношении отложенных задач по предотвращению инцидентов.
Мы также усилили способы связи с нашими клиентами во время сбоя. Наша цель — предупредить вас о проблеме в момент её подтверждения, прежде чем вы заметите неполадку. К тому времени, когда вы заметите задержку или ошибку, мы стремимся, чтобы обновление уже ждало вас в уведомлениях.
Во время активного инцидента мы теперь предоставляем обновления через предсказуемые интервалы (например, каждые 30 или 60 минут), даже если обновление просто гласит: «Мы всё ещё тестируем исправление; новых изменений пока нет». Это позволяет вам планировать свой день, а не постоянно обновлять страницу статуса.
Наша работа не заканчивается, когда статус возвращается к норме. Мы предоставляем подробные посмертные отчёты (post-mortems), объясняющие, что произошло, почему это произошло и какие конкретные структурные изменения мы вносим, чтобы это не повторилось.
Эта инициатива завершена. Но наша работа по повышению отказоустойчивости никогда не заканчивается.
Мы относимся к инцидентам очень серьёзно и приняли коллективную ответственность по всей организации Cloudflare, спросив каждую команду: что можно было сделать лучше? Это направляло работу, которую мы провели за последние два квартала.