За последние шесть лет CLI-инструмент Cloudflare Wrangler выпустил несколько основных версий, каждая из которых содержала как минимум некоторые критические изменения в командах, конфигурации или во взаимодействии разработчиков с платформой. Как и любой активно поддерживаемый проект с открытым исходным кодом, мы храним документацию для старых версий. В документации v1 размещен баннер об устаревании, метатег noindex и канонические теги, указывающие на актуальную документацию. Все сигналы-предупреждения говорят об одном: этот контент устарел, ищите в другом месте. Краулеры для обучения ИИ не всегда корректно учитывают эти сигналы.
Мы используем AI Crawl Control на developers.cloudflare.com, поэтому мы знаем, что боты из категории AI Crawler посещали нас 4,8 миллиона раз за последние 30 дней, и они потребляли устаревший контент с той же частотой, что и актуальный. Сигналы-предупреждения не оказали заметного влияния. Эффект накапливается, потому что агенты ИИ не всегда получают контент в реальном времени; они опираются на обученные модели. Когда краулеры поглощают устаревшую документацию, агенты наследуют устаревшие основы.
Сегодня мы запускаем функцию Redirects for AI Training (Перенаправления для обучения ИИ), которая позволяет обеспечить перенаправление проверенных краулеров для обучения ИИ на актуальный контент. Ваши существующие канонические теги автоматически, одним переключателем, на всех платных тарифах Cloudflare превращаются в редиректы HTTP 301 для проверенных краулеров обучения ИИ.
И поскольку статус-коды — это в конечном счете то, как веб передает политику краулерам, на странице Radar's AI Insights теперь есть анализ кодов состояния ответов, показывающий различные типы (успешные (2xx), перенаправления (3xx), ошибки клиента (4xx) и ошибки сервера (5xx)) статус-кодов, которые краулеры ИИ получают во всем трафике Cloudflare, что дает представление о том, как веб реагирует на краулеры ИИ сегодня.
Краулеры для обучения ИИ сегодня упираются в тупики
Для поисковых систем noindex функционирует как развитая система сигналов, но не существует эквивалентной встроенной директивы, которую страница может нести, означающей «не обучайся на этом». Поддержка устаревшей страницы в живом состоянии с предупреждающим баннером может сработать для людей, которые прочитают уведомление и перейдут дальше, но краулеры для обучения ИИ поглощают весь текст и рискуют воспринять баннер как просто еще один абзац, возвращаясь тысячи раз даже после того, как предупреждение стало видимым.
Блокировка создает свою собственную проблему: она создает пустоту без сигнала о том, что вместо этого должен узнать краулер. robots.txt предлагает ограниченную защиту, но по мере роста автоматического трафика поддержка директив для каждого краулера, каждого пути, каждого обновления контента требует серьезных ручных усилий. Краулерам нужны конкретные указания: «Вот где находится актуальный контент».
Тег <link rel="canonical"> — это HTML-элемент, определенный в RFC 6596, который сообщает поисковым системам и автоматизированным системам, какой URL представляет авторитетную версию страницы. Он уже присутствует на 65–69% веб-страниц и автоматически генерируется такими платформами, как EmDash, WordPress и Contentful. Эта инфраструктура объявляет, какой является текущая версия вашего контента, а функция Redirects for AI Training обеспечивает ее соблюдение.
Как это работает
Redirects for AI Training работает на основе двух входных данных: поля Cloudflare cf.verified_bot_category и тегов <link rel="canonical">, уже присутствующих в вашем HTML. Категория AI Crawler охватывает ботов, которые сканируют веб для обучения моделей ИИ, включая GPTBot, ClaudeBot и Bytespider, и отличается от категорий AI Assistant и AI Search, которые охватывают агентов ИИ.
Когда поступает запрос от проверенного AI Crawler, Cloudflare считывает HTML ответа. Если присутствует не самореферентный канонический тег, Cloudflare выдает 301 Moved Permanently на канонический URL, прежде чем вернуть ответ. Трафик от людей, поисковая индексация и другой автоматический трафик не затрагиваются.
Вот как выглядит обмен для запроса GPTBot к устаревшему пути:
GET /durable-objects/api/legacy-kv-storage-api/
Host: developers.cloudflare.com
User-Agent: Mozilla/5.0 (compatible; GPTBot/1.1; +https://openai.com/gptbot)
HTTP/1.1 301 Moved Permanently
Location: https://developers.cloudflare.com/durable-objects/api/sqlite-storage-api/
Чего это не делает
Это не исправляет ретроспективно уже загруженные данные для обучения и не охватывает непроверенные краулеры за пределами категории ботов AI Crawler. Люди и агенты ИИ, посещающие устаревшие страницы, не будут перенаправлены. Мы также намеренно исключаем межсайтовые (кросс-доменные) канонические теги (теги, указывающие на предпочтительные URL в других доменах), поскольку они часто используются для консолидации доменов, а не для обеспечения свежести контента. Во избежание зацикливаний самореферентные канонические теги (тег на странице, указывающий на её собственный URL) также не вызывают перенаправления.
Почему бы просто не использовать правила редиректа?
Правила единичных перенаправлений (Single Redirect Rules) могут нацеливаться на краулеров ИИ по строке User-Agent, и если на сайте всего несколько известных устаревших путей, это работает. Но это не масштабируется: каждый новый устаревший путь требует изменения правила, User-Agent'ы необходимо отслеживать вручную, и это будет засчитываться в ограничения тарифного плана, которые в противном случае могли бы использоваться для промо-URL или миграций доменов. Правила редиректов также вручную перекодируют то, что уже объявляют канонические теги, и рассинхронизируются при изменении контента.
Что мы обнаружили на нашем собственном сайте с документацией
Наш собственный опыт показывает, что эта проблема реальна. Мы используем AI Crawl Control на developers.cloudflare.com через ту же панель управления, что доступна всем клиентам Cloudflare. В марте 2026 года устаревшая документация по Workers была просканирована около 46 000 раз OpenAI, 3 600 раз Anthropic и 1 700 раз Meta.
Возможно, именно это сканирование устаревших страниц привело к тому, что когда мы в апреле 2026 года спросили у ведущего ИИ-ассистента: «Как записать значения в KV с помощью Wrangler CLI?», он дал устаревший ответ: «Вы записываете в Cloudflare KV через Wrangler CLI с помощью команды kv:key put».
На самом деле, правильный синтаксис (по состоянию на апрель 2026 года) — это wrangler kv key put; синтаксис с двоеточием (kv:key put) был объявлен устаревшим в Wrangler 3.60.0. Наша документация содержит встроенное уведомление об устаревании, но неясно, как конвейеры обучения их интерпретируют.
Поэтому мы включили Redirects for AI Training на developers.cloudflare.com и измерили отклик. В первые семь дней 100% запросов краулеров обучения ИИ к страницам с не самореферентными каноническими тегами были перенаправлены, и устаревший контент им не предоставлялся.
Мы ожидаем, что перенаправление краулеров на актуальный контент со временем улучшит ответы, генерируемые ИИ, об устаревших инструментах. Учитывая закрытый характер конвейеров обучения и изменчивость времени повторного сканирования, это гипотеза, которую мы продолжим проверять. Но то, что краулер получает в точке доступа, показало немедленное улучшение.
Как включить
Если на вашем сайте есть канонические теги, ваша существующая иерархия контента теперь может быть обеспечена для проверенных краулеров обучения ИИ. Классификация проверенных ботов Cloudflare автоматически обрабатывает идентификацию краулеров.
В панели управления: на любом домене перейдите в раздел AI Crawl Control > Quick Actions > Redirects for AI training > переключите в положение "on" (включено).
Для управления с учетом путей через Правила конфигурации и Cloudflare для SaaS см. полную документацию.
Как веб-ресурсы реагируют на ИИ-краулеры
Функция «Перенаправления для обучения ИИ» превращает один код состояния, 301 Moved Permanently, в механизм принудительного применения вашей политики контента. Но 301 — это лишь один сигнал в более широком диалоге между источниками и краулерами. 200 OK означает, что контент был предоставлен. 403 Forbidden означает, что доступ был заблокирован. 402 Payment Required сообщает клиенту, что ему необходимо оплатить доступ. В совокупности распределение кодов состояния в трафике ИИ-краулеров показывает, как веб на самом деле реагирует на краулеры в масштабе.
На странице AI Insights в Radar теперь есть график анализа кодов состояния ответа, иллюстрирующий распределение основных кодов состояния ответа или их групп (выбираемых через выпадающий список) для трафика ИИ-краулеров. Данные можно фильтровать по набору отраслей; фильтр цели сканирования также можно применить в Data Explorer. Отфильтрованный анализ позволяет понять, ведут ли себя определенные типы краулеров по-разному или же шаблоны запросов и распределение различаются в зависимости от отрасли.
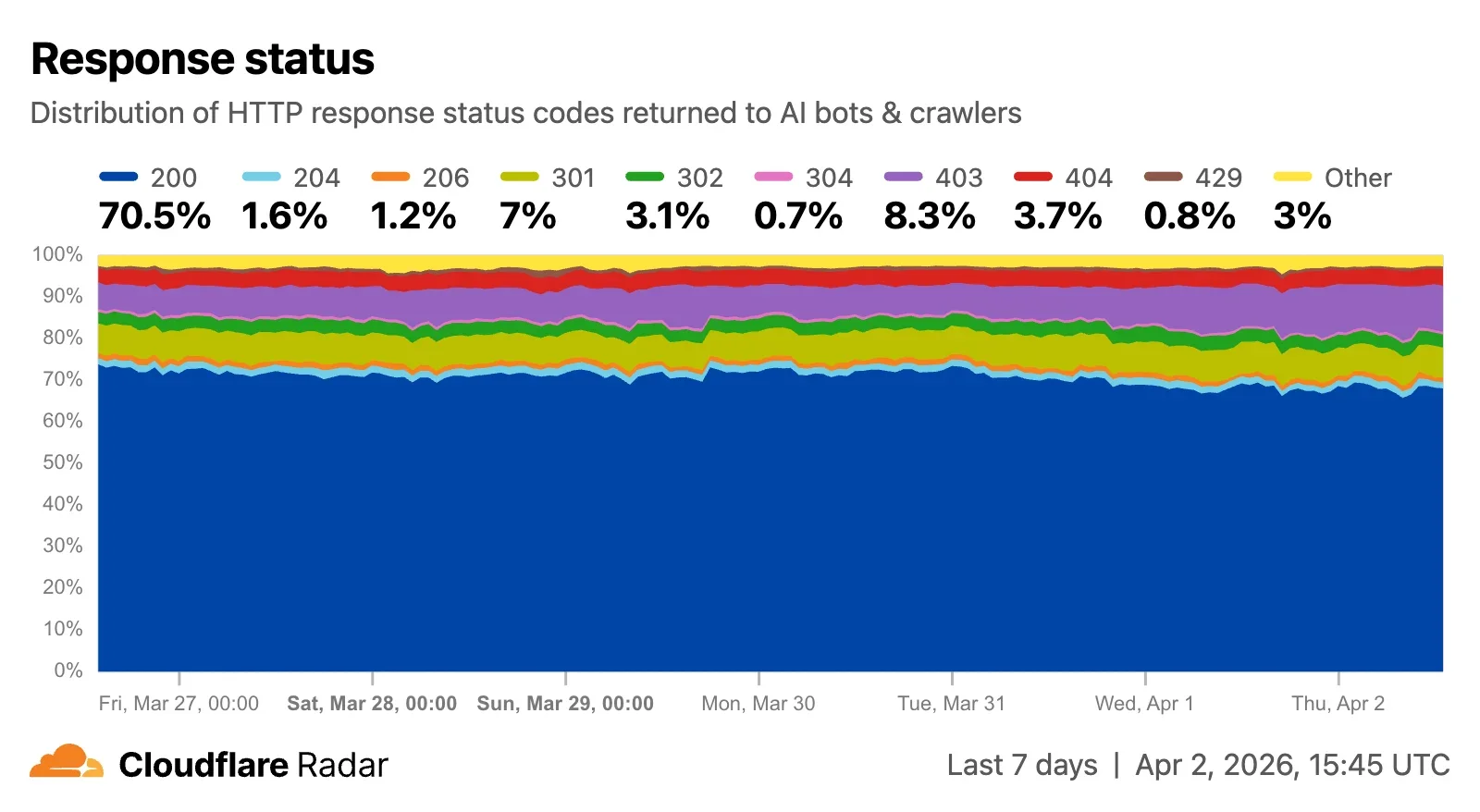
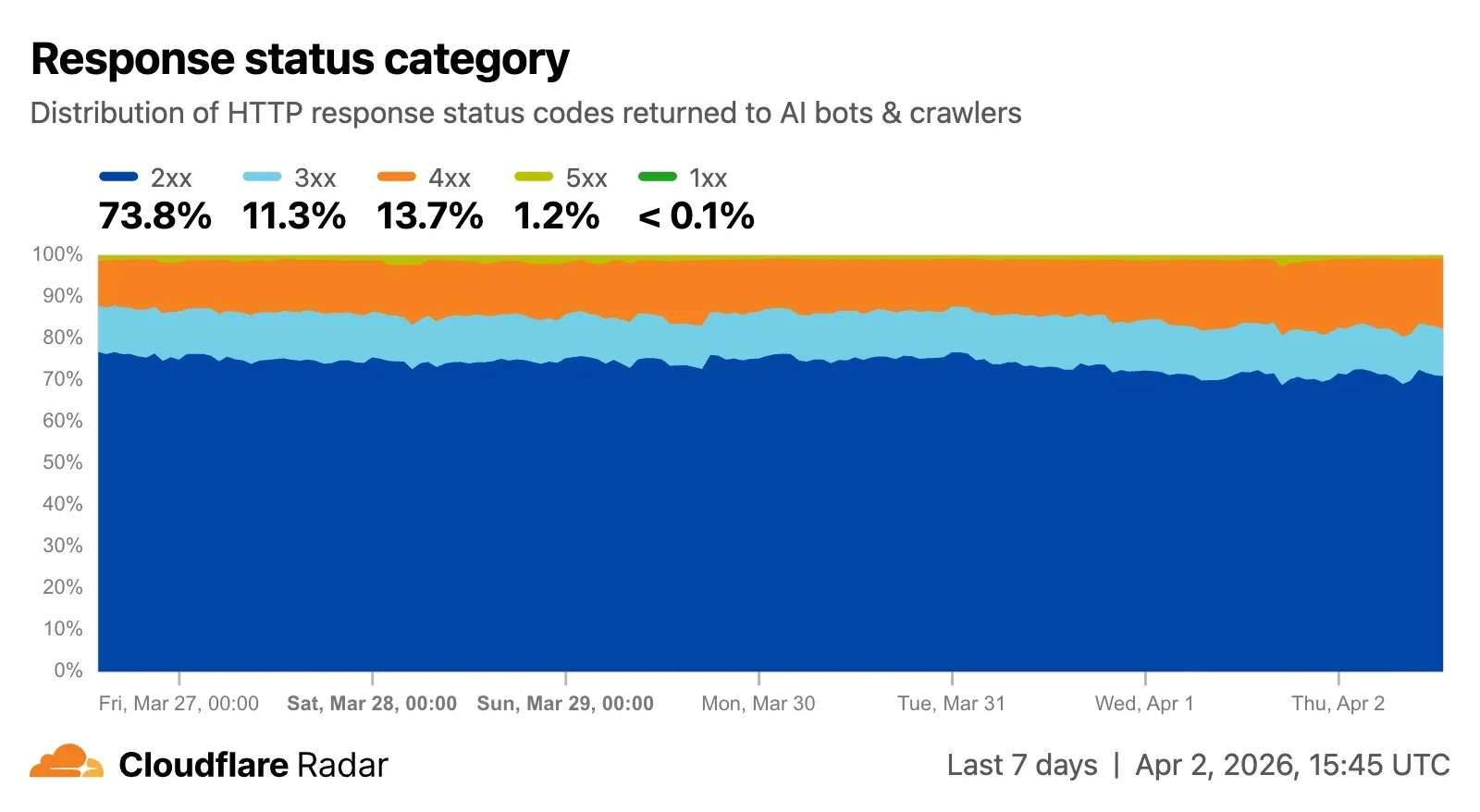
В общем примере, показанном ниже, мы видим, что за период, охватываемый графиком, чуть более 70% запросов были успешно обработаны (200), в то время как 10,1% запросов были перенаправлены (301, 302) на другой URL, и 3,7% приходилось на файлы, которые не были найдены (404). Доступ к контенту был заблокирован для 8,3% запросов, которые получили код состояния ответа 403. Сгруппировав данные, мы видим, что почти 74% запросов получили успешные ответы (2xx), 13,7% получили ответы с ошибкой клиента (4xx), 11,3% получили сообщения о перенаправлении (3xx), и 1,2% получили ответы с ошибкой сервера (5xx).
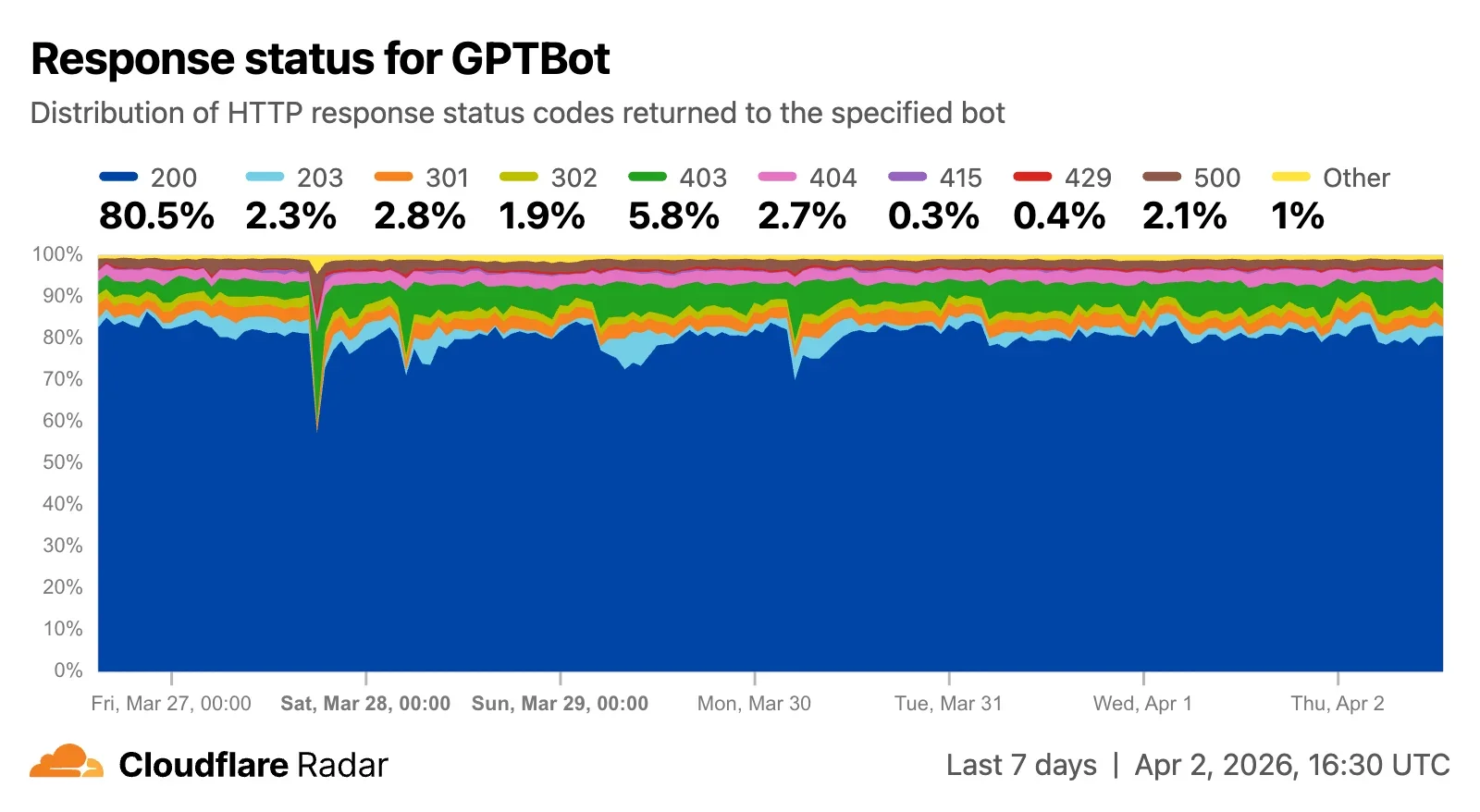
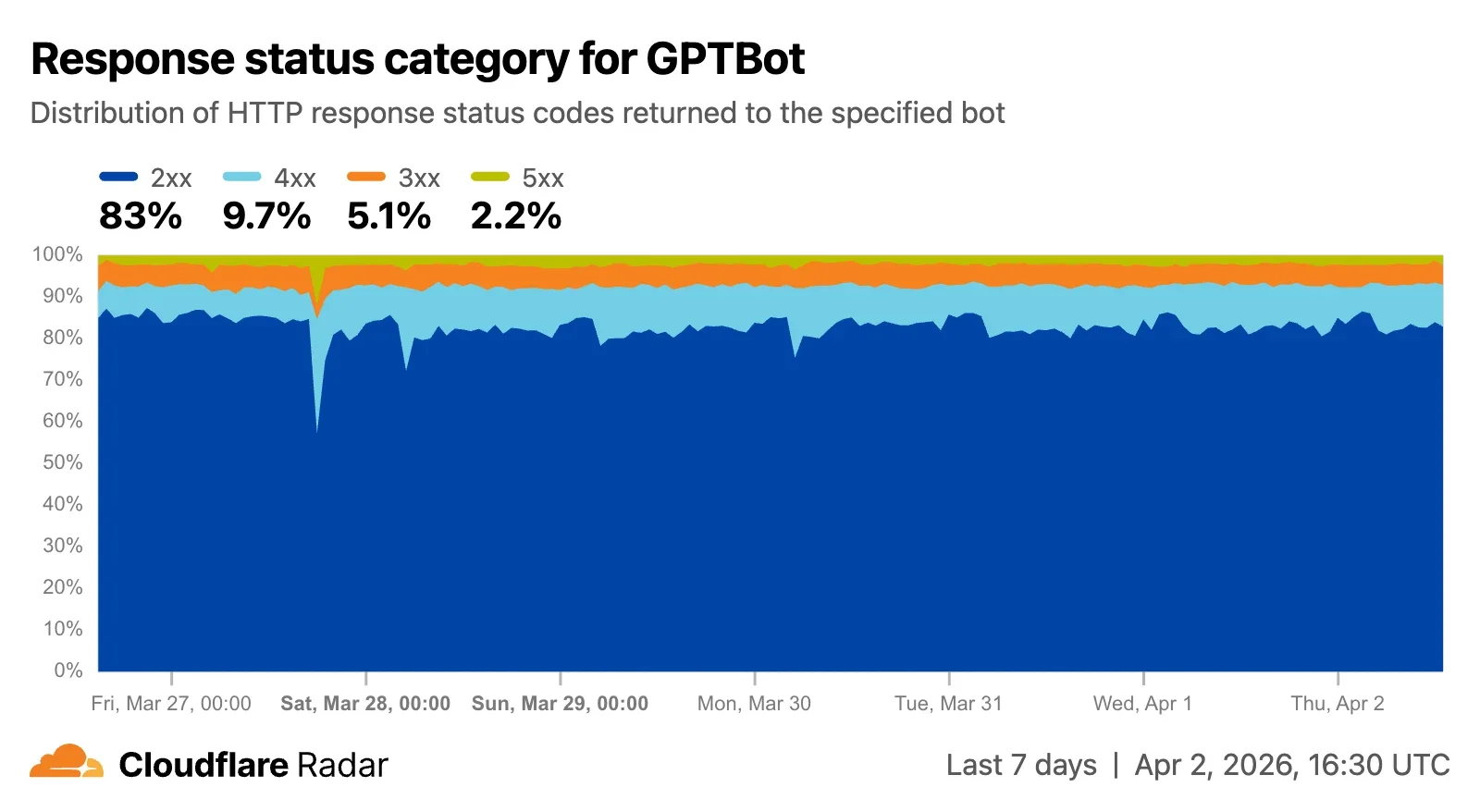
Этот анализ также был добавлен на отдельные страницы ботов, чтобы дать представление и об этом аспекте поведения краулера. В примере с GPTBot, показанном ниже, мы видим, что за период, охватываемый графиком, чуть более 80% запросов были успешно обработаны (200), в то время как 4,7% запросов были перенаправлены (301, 302) на другой URL, и всего 2,7% приходилось на файлы, которые не были найдены (404). Почти 6% были заблокированы, а Cloudflare вернул код состояния ответа 403. Сгруппировав данные, мы видим, что 83% запросов получили успешные ответы (2xx), почти 10% получили ответы с ошибкой клиента (4xx), 5,1% получили сообщения о перенаправлении (3xx), а оставшиеся 2,2% получили ответы с ошибкой сервера (5xx).
Как отмечалось выше, Data Explorer в Radar позволяет пользователям глубже анализировать данные, применяя дополнительные фильтры. Например, мы можем посмотреть, какие краулеры запрашивают больше всего несуществующего контента (что приводит к коду состояния ответа 404), и как этот трафик запросов изменяется со временем, или какие отрасли отправляют больше всего кодов состояния ответа Перенаправление (3xx) краулерам с целью Обучение, и как эта активность меняется со временем.
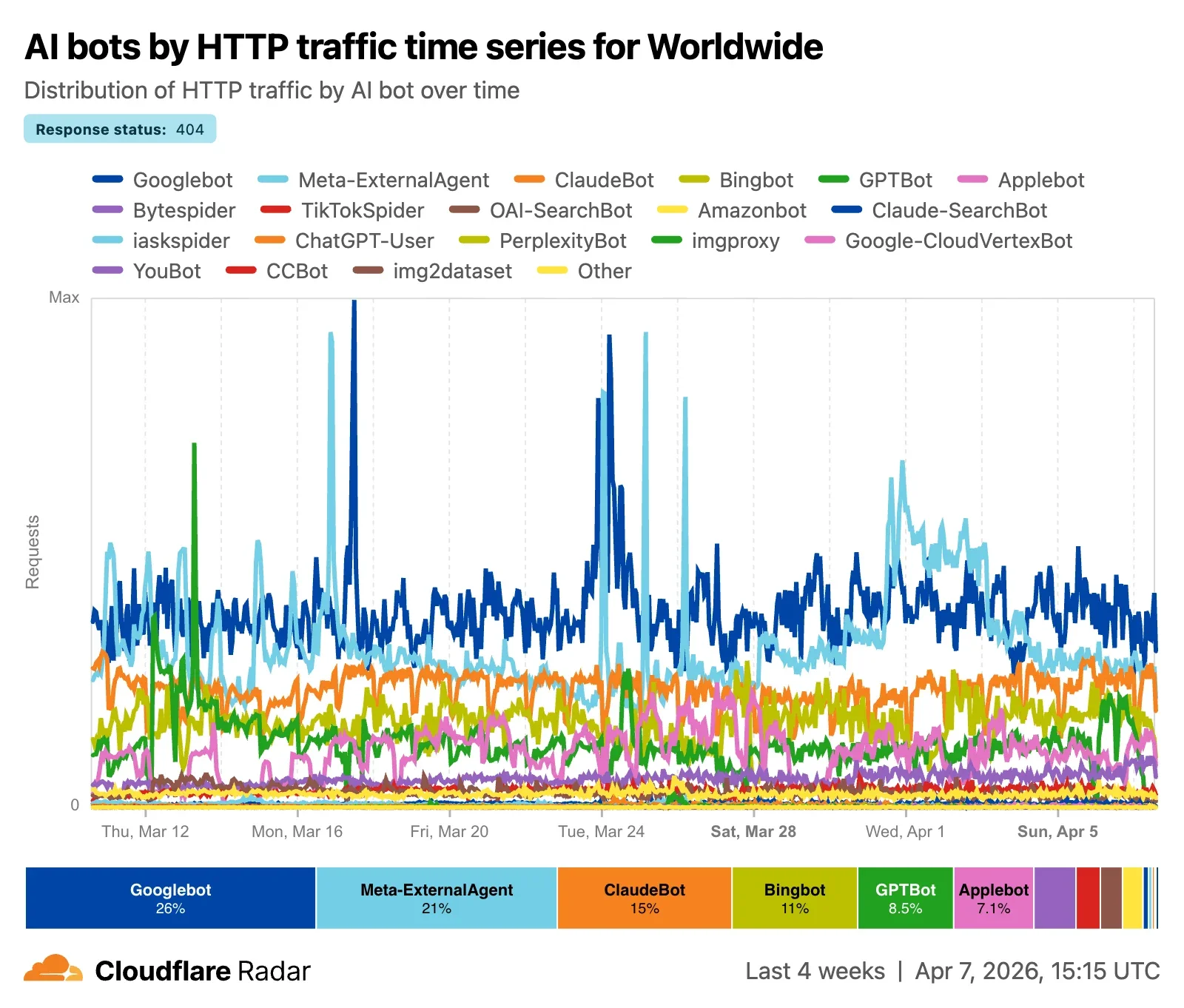
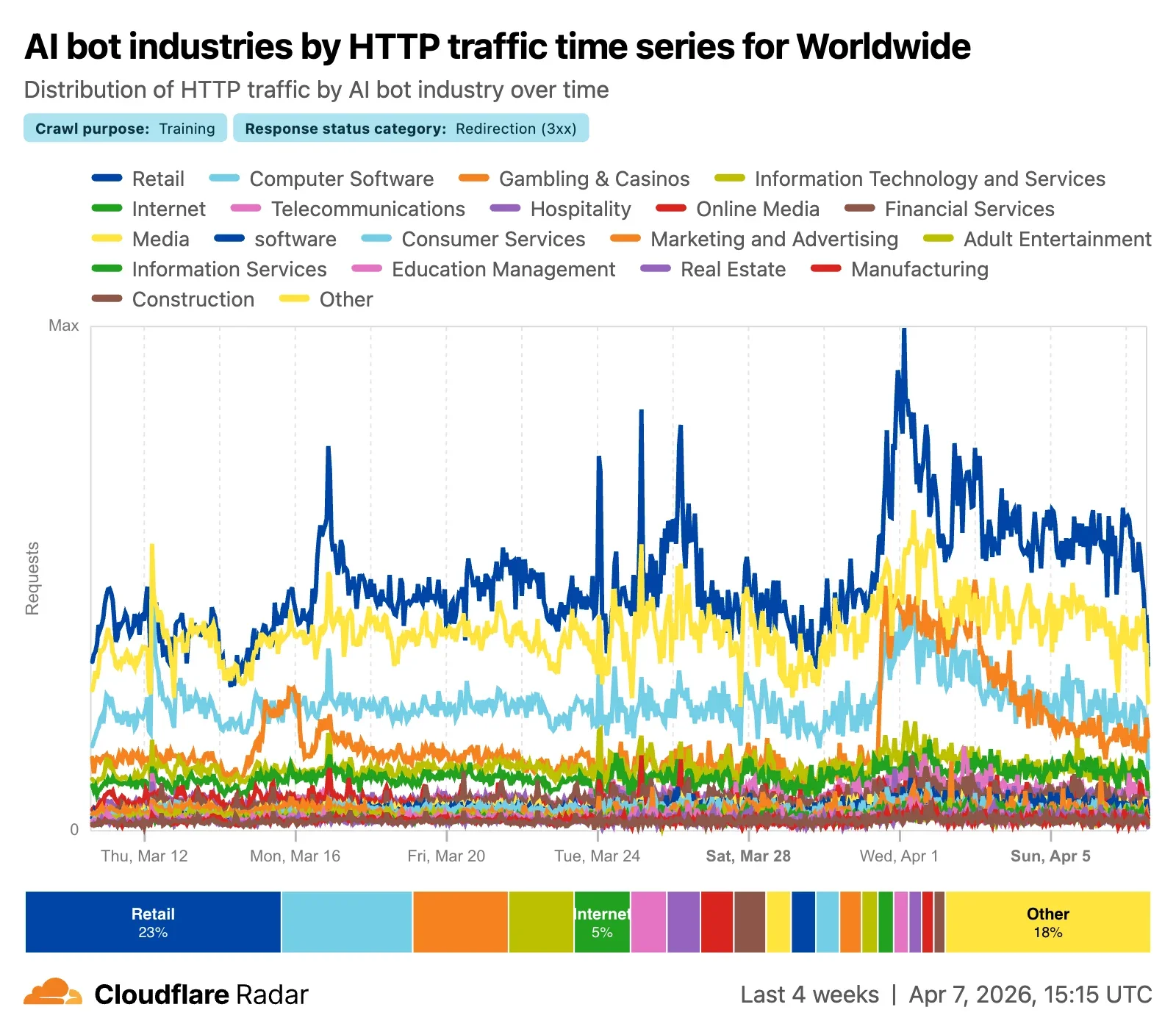
Данные о кодах состояния ответа, как агрегированные, так и для отдельных ботов, также доступны через Cloudflare Radar API.
Перенаправления для обучения ИИ позволяют вам определять, что краулеры получают от вашего источника; анализ кодов состояния в Radar позволяет увидеть, как остальная часть веба делает то же самое. Включите функцию «Перенаправления для обучения ИИ» в разделе AI Crawl Control > Обзор > Быстрые действия, чтобы уже сегодня начать заменять рекомендательные сигналы принудительными результатами на вашем сайте.
Есть вопросы или хотите поделиться своими наблюдениями? Присоединяйтесь к обсуждению в сообществе Cloudflare или найдите нас в Discord.