Выполнение вывода в пределах 50 мс для 95% подключенного к интернету населения мира требует беспощадной эффективности в использовании памяти GPU. В прошлом году мы улучшили утилизацию памяти с помощью Infire, нашего механизма вывода на основе Rust, и устранили холодные старты с помощью Omni, нашей платформы планирования моделей. Теперь мы решаем следующее крупное узкое место в нашей платформе вывода: веса модели.
Генерация одного токена LLM требует чтения каждого веса модели из памяти GPU. На GPU NVIDIA H100, которые мы используем во многих наших дата-центрах, тензорные ядра могут обрабатывать данные почти в 600 раз быстрее, чем память может их доставить, что создает узкое место не в вычислениях, а в пропускной способности памяти. Каждый байт, пересекающий шину памяти, — это байт, которого можно было бы избежать, если бы веса были меньше.
Чтобы решить эту проблему, мы создали Unweight: систему сжатия без потерь, которая может уменьшить веса модели до 15–22%, сохраняя при этом побитово точный вывод, без использования какого-либо специального оборудования. Ключевой прорыв здесь заключается в том, что распаковка весов в быстрой памяти на кристалле и подача их напрямую в тензорные ядра позволяет избежать лишнего обращения к медленной основной памяти. В зависимости от рабочей нагрузки, среда выполнения Unweight выбирает из нескольких стратегий выполнения — некоторые отдают приоритет простоте, другие минимизируют трафик памяти — а автотюнер выбирает лучшую для каждой матрицы весов и размера батча.
В этом посте подробно рассказывается, как работает Unweight, но в духе большей прозрачности и поощрения инноваций в этой быстро развивающейся области мы также публикуем техническую статью и выкладываем в открытый доступ GPU-ядро.
Наши первоначальные результаты для Llama-3.1-8B показывают сжатие только весов многослойного перцептрона (MLP) примерно на ~30%. Поскольку Unweight работает выборочно с параметрами для декодирования, это приводит к уменьшению размера модели на 15-22% и экономии ~3 ГБ видеопамяти. Как показано на графике ниже, это позволяет нам выжать больше из наших GPU и, следовательно, запускать больше моделей в большем количестве мест — делая вывод дешевле и быстрее в сети Cloudflare.
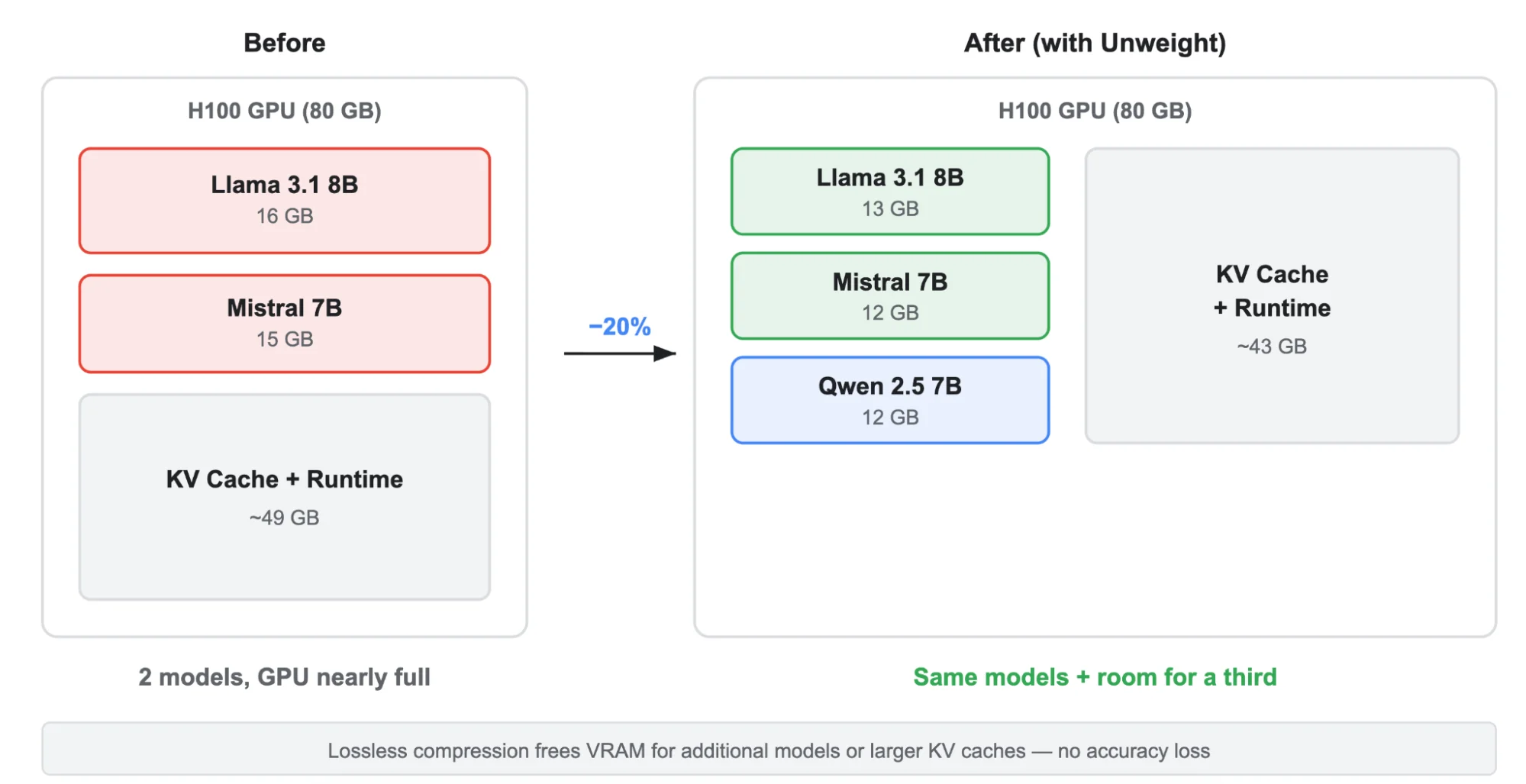
Благодаря Unweight мы можем разместить больше моделей на одном GPU
Почему сжатие сложнее, чем кажется
Растет объем исследований, изучающих, как сжимать веса модели креативными способами, чтобы сделать вывод быстрее и/или запускать его на меньших GPU. Наиболее распространенным является квантование — техника уменьшения размера весов и активаций модели путем преобразования больших 32- или 16-битных чисел с плавающей запятой в меньшие 8- или 4-битные целые числа. Это форма сжатия с потерями: разные 16-битные значения с плавающей запятой могут быть преобразованы в одно и то же 4-битное целое число. Это снижение точности непредсказуемо влияет на качество ответов. Для промышленного вывода, обслуживающего разнообразные случаи использования, мы хотели чего-то без потерь, что сохраняет точное поведение модели.
Несколько недавних систем (Huff-LLM, ZipNN и ZipServ) показали, что веса LLM можно значительно сжать, но эти подходы решают другие проблемы, чем наши. ZipNN сжимает веса для распространения и хранения, а распаковка происходит на CPU. Huff-LLM предлагает пользовательское оборудование на FPGA для декодирования. А ZipServ действительно объединяет распаковку с выводом на GPU, но ориентирован на потребительские GPU, которые не работают с нашими H100. Ни один из этих вариантов не дал нам того, что было нужно: распаковку без потерь во время вывода на GPU Hopper, которая может быть интегрирована с нашим движком вывода на основе Rust.
Основная проблема не в простом сжатии — байты экспоненты в весах BF16 сильно избыточны, поэтому энтропийное кодирование хорошо с ними работает. Проблема в том, чтобы распаковывать достаточно быстро, чтобы это не замедляло вывод. На H100 тензорные ядра большую часть времени простаивают в ожидании памяти — но эту свободную мощность нельзя просто переназначить для распаковки. Каждый блок вычислений GPU может запускать либо ядро распаковки, либо ядро матричного умножения, но не оба одновременно, из-за ограничений общей памяти. Любая задержка декодирования, которая не идеально перекрывается с матричным умножением, напрямую добавляется к задержке токена. Ответ Unweight — распаковывать веса в быстрой общей памяти на кристалле и подавать результаты прямо в тензорные ядра — но заставить это эффективно работать при разных размерах батчей и формах весов — вот где настоящая инженерная работа.
Как можно эффективно сжимать веса модели
Каждое число в модели ИИ хранится как 16-битное «мозговое число с плавающей запятой» (BF16). Каждое значение BF16 состоит из трех частей:
-
Знак (1 бит): положительный или отрицательный
-
Экспонента (8 бит): величина
-
Мантисса (7 бит): точное значение в пределах этой величины
Вот как раскладывается один из таких весов:
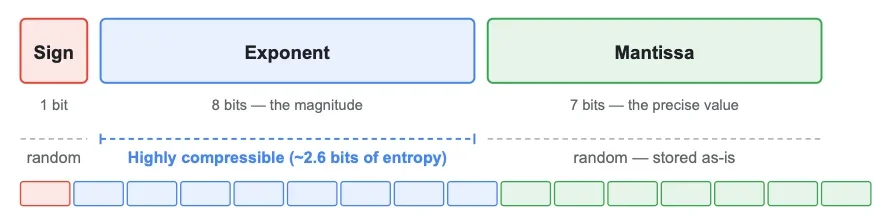
Знак и мантисса непредсказуемо меняются от веса к весу — они выглядят как случайные данные и не могут быть осмысленно сжаты. Но с экспонентой другая история.
Экспонента удивительно предсказуема
Предыдущие исследования установили, что в обученных LLM из 256 возможных значений экспоненты доминирует лишь горстка. 16 наиболее распространенных экспонент покрывают более 99% всех весов в типичном слое. Теория информации говорит, что для представления этого распределения нужно всего ~2,6 бита — гораздо меньше, чем выделенные 8 бит. Если посмотреть на распределение значений экспоненты в типичном слое LLM, можно увидеть, что 16 лучших экспонент составляют 99% всех весов модели.
Распределение значений экспоненты в типичном слое LLM
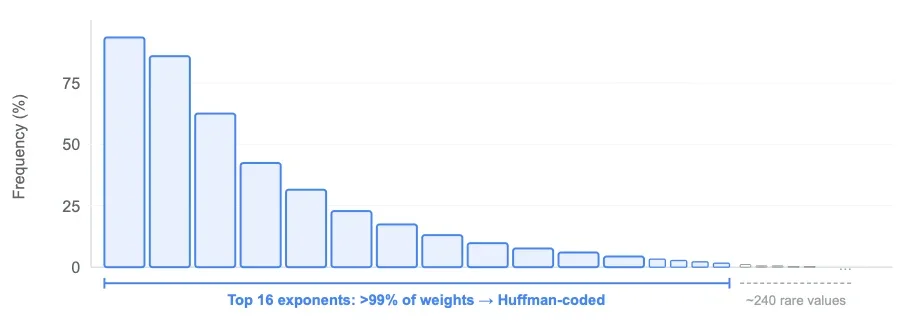
Это избыточность, которую использует Unweight. Мы не трогаем знак и мантиссу и сжимаем только байт экспоненты, используя кодирование Хаффмана — классическую технику, которая присваивает короткие коды распространенным значениям, а длинные — редким. Поскольку распределение экспоненты настолько смещено, это дает примерно 30% сжатие потока экспонент. Мы применяем это выборочно к матрицам весов MLP (проекции gate, up и down), которые составляют примерно две трети параметров модели и доминируют в трафике памяти во время генерации токенов. Веса внимания, эмбеддинги и нормы слоев не сжимаются. В совокупности эти оптимизации приводят к уменьшению общего размера весов многослойного перцептрона (MLP) примерно на 20%, как подробно объясняется в нашем техническом отчете.
Небольшое количество весов с редкими экспонентами обрабатывается отдельно: если какой-либо вес в строке из 64 имеет экспоненту вне палитры 16 лучших, вся строка хранится в исходном виде. Этот подход устраняет ветвление на элемент в критическом пути — вместо проверки каждого веса на крайние случаи мы принимаем одно решение на строку заранее.
Узкое место памяти GPU
GPU NVIDIA H100 имеет два соответствующих вида памяти:
-
Высокоскоростная память (HBM): большая, но относительно медленная для доступа. Здесь находятся веса модели.
-
Общая память (SMEM): крошечная, но чрезвычайно быстрая. Здесь GPU подготавливает данные прямо перед выполнением вычислений.
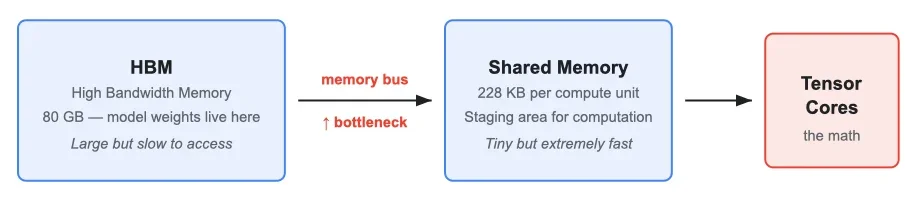
Во время вывода генерация каждого токена требует чтения полной матрицы весов из HBM. Шина памяти между HBM и SMEM является узким местом производительности —не сами вычисления. Меньше байт через шину = быстрее генерация токенов.
Во время вывода генерация каждого токена требует чтения полной матрицы весов из HBM через шину памяти — это и есть узкое место. Тензорные ядра H100 могут перемалывать числа гораздо быстрее, чем HBM может подавать им данные. Сжатие помогает, потому что через шину нужно передать меньше байт. Но есть загвоздка: GPU не может выполнять вычисления над сжатыми данными. Веса сначала необходимо распаковать.
Большинство предыдущих работ распаковывают целые матрицы весов обратно в HBM, а затем запускают стандартное матричное умножение. Это помогает с емкостью хранения, но не помогает с пропускной способностью, потому что вы все равно читаете полную несжатую матрицу из HBM для каждого токена.
Четыре способа использования сжатых весов
Не существует единственного лучшего способа использования сжатых весов во время вывода. Правильный подход зависит от рабочей нагрузки — размера батча, формы матрицы весов и того, сколько времени GPU доступно для распаковки. Unweight предлагает четыре конвейера выполнения со сжатием, каждый со своим балансом между усилиями по распаковке и сложностью вычислений: полное декодирование Хаффмана, декодирование только экспоненты, преобразование палитры или полный пропуск предварительной обработки.
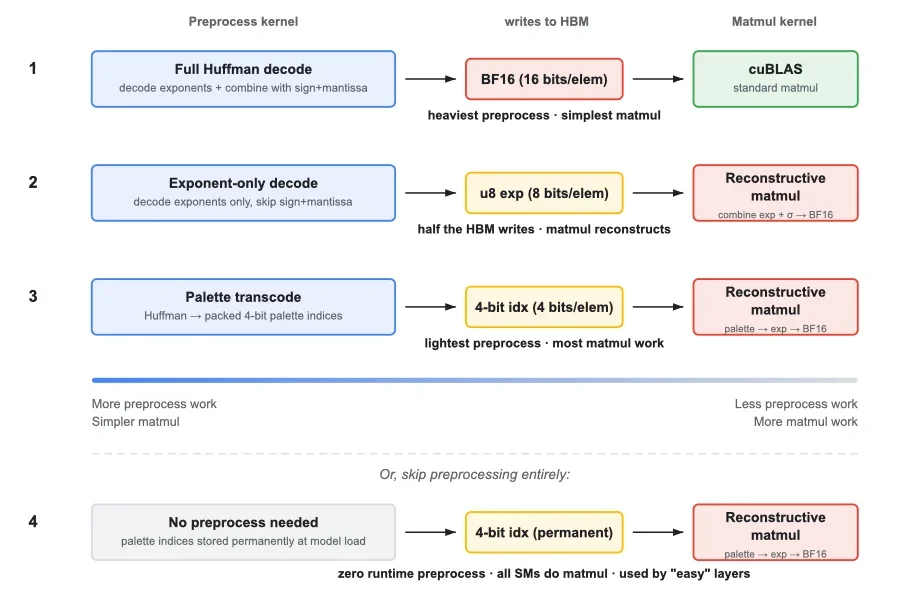
Четыре различных конвейера выполнения
Четыре конвейера образуют спектр. На одном конце полное декодирование полностью восстанавливает исходные BF16-веса и передает их в библиотеку NVIDIA cuBLAS для стандартного матричного умножения. Это самый простой путь, cuBLAS работает на полной скорости с обычными данными, но этап предварительной обработки записывает наибольшее количество байт обратно в основную память. Он хорошо работает при малых размерах пакета, где матричное умножение невелико, а накладные расходы специализированного ядра доминируют. На другом конце прямая палитра полностью пропускает предварительную обработку. Веса преобразуются в компактный 4-битный формат во время загрузки модели, а ядро матричного умножения восстанавливает значения BF16 на лету из этих индексов. Нулевая стоимость предобработки, но ядро выполняет больше работы на элемент.
Между ними расположены два независимых пути: один декодирует только байты экспоненты (уменьшая трафик предобработки вдвое), а другой преобразует данные в 4-битные индексы палитры во время выполнения (уменьшая трафик вчетверо). Оба используют реконструктивное матричное умножение — специализированное ядро, которое загружает сжатые данные, восстанавливает BF16 в быстрой разделяемой памяти и напрямую подает их в тензорные ядра, без обратной записи в основную память.
Почему не существует одного победившего конвейера
Меньше предобработки означает меньше данных, записанных в HBM, что освобождает шину памяти раньше. Но это перекладывает больше работы по восстановлению на ядро матричного умножения. Окупается ли такой компромисс, зависит от ситуации.
При малых размерах пакета (например, 1-64 токена) матричное умножение крошечное, поэтому не так много вычислений, с которыми можно было бы совместить работу, и доминируют фиксированные издержки специализированного ядра. Полное декодирование + cuBLAS часто выигрывает просто потому, что у cuBLAS ниже накладные расходы. При больших размерах пакета (например, 256+ токенов) матричное умножение выполняется достаточно долго, чтобы поглотить дополнительную работу по восстановлению. Более легкая предобработка завершается быстрее, а выигрыш от освободившейся пропускной способности шины и совмещения вычислений окупается. Конвейеры с палитрой или экспонентой вырываются вперед. Разные матрицы весов внутри одного слоя могут быть оптимальны для разных конвейеров. Проекции "gate" и "up" имеют размерности, отличные от проекции "down", что меняет порядок операций в матричном умножении и требует различных компромиссов производительности.
Пропускная способность vs стратегия конвейера
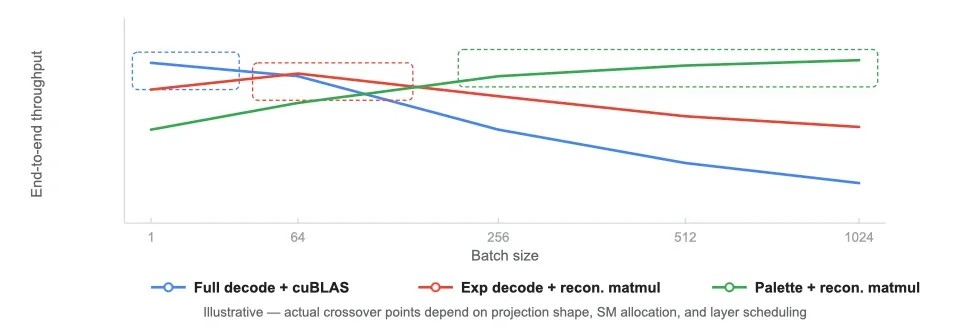
Вот почему Unweight не фиксирует жестко одну стратегию. Среда выполнения выбирает лучший конвейер для каждой матрицы весов при каждом размере пакета, основываясь на процессе автонастройки, который измеряет фактическую сквозную пропускную способность на целевом оборудовании (об этом далее).
Как работает реконструктивное матричное умножение
Три из четырех конвейеров используют специализированное ядро матричного умножения, совмещающее распаковку с вычислениями. Это ядро загружает сжатые данные из HBM, восстанавливает исходные значения BF16 в разделяемой памяти и напрямую подает их в тензорные ядра — все за одну операцию. Восстановленные веса никогда не существуют в основной памяти.
Традиционная распаковка vs Unweight
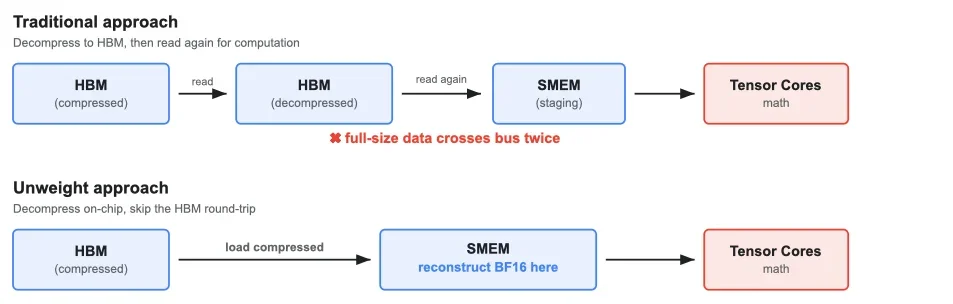
С Unweight через шину памяти для матриц весов MLP передается на ~30% меньше байт
Внутри этого ядра группы потоков GPU разделены на две роли:
-
Группа поставщика загружает сжатые данные из HBM в разделяемую память с помощью специализированного аппаратного обеспечения копирования памяти (TMA). Она подготавливает байты знака+мантиссы, данные экспоненты (или индексы палитры) и — для строк с редкими экспонентами — исходные строки экспоненты. Она работает с опережением потребителя, заполняя циклический буфер, чтобы данные были готовы до того, как они потребуются.
-
Группы потребителей восстанавливают значения BF16, объединяя экспоненты с байтами знака+мантиссы, а затем немедленно передают результат в инструкции тензорных ядер WGMMA архитектуры Hopper. Восстановленные веса идут напрямую из ассемблерного кода в вычисления, не покидая разделяемой памяти.
Реконструктивное матричное умножение имеет несколько вариантов, различающихся тем, сколько выходных блоков обрабатывает каждое вычислительное устройство и насколько глубоким является циклический буфер. Более широкие выходные блоки улучшают повторное использование данных при больших размерах пакета; более глубокие буферы скрывают задержку памяти при малых размерах пакета. Автонастройщик выбирает лучший вариант для каждой рабочей нагрузки.
Разделение GPU между декодированием и вычислениями
В двух совмещенных конвейерах отдельное ядро предобработки (декодер Хаффмана или преобразователь палитры) выполняется параллельно с реконструктивным матричным умножением. Но эти ядра конкурируют за ресурсы GPU.
На архитектуре Hopper каждое вычислительное устройство (SM) имеет 228 КБ разделяемой памяти. Реконструктивному матричному умножению требуется ~227 КБ для его конвейерного буфера и блоков аккумуляторов. Декодирующему ядру нужно ~16 КБ для его таблицы поиска Хаффмана. Поскольку 227 + 16 > 228, эти два ядра не могут совместно использовать одно и то же вычислительное устройство. Каждое SM, выделенное под декодирование, — это на одно SM меньше доступного для матричного умножения.
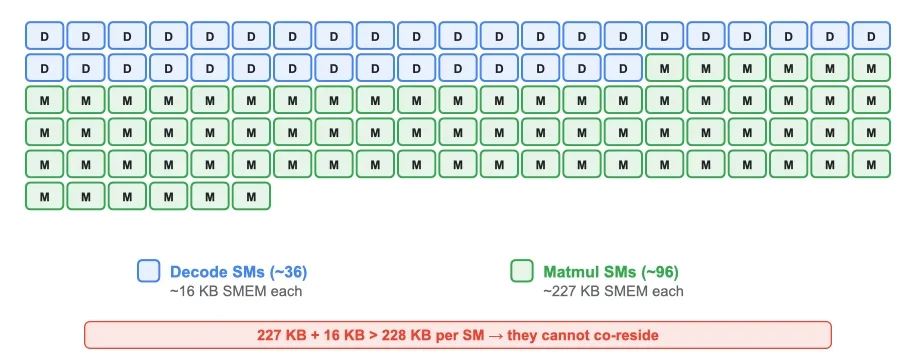
Это создает балансировку: больше SM для декодирования означает более быструю предобработку, но более медленное матричное умножение, и наоборот. Оптимальное разделение — еще один настраиваемый параметр, и еще одна причина, по которой автонастройщик измеряет реальную пропускную способность, а не полагается на эвристики.
Конвейеризация между слоями
Даже с учетом ограничения на разделение SM, Unweight скрывает большую часть стоимости распаковки, используя структуру трансформерных моделей.
Не каждому слою требуется декодирование Хаффмана во время выполнения. Unweight классифицирует слои как "сложные" (требующие предобработки Хаффманом) или "простые" (использующие предварительно преобразованные данные палитры, которые матричное умножение может потреблять напрямую). Среда выполнения чередует их:

Декодирование выполняется в отдельных потоках CUDA во время начальной загрузки, работы внимания и вычислений простых MLP. К тому моменту, когда запускается MLP сложного слоя, его предобработанные веса уже ждут
Пока GPU вычисляет простой слой — которому не нужна предобработка — отдельный набор потоков CUDA фоново декодирует веса следующего сложного слоя. К тому времени, когда простые слои завершатся и наступит очередь сложного слоя, его предобработанные данные уже будут ждать. Двухбуферные слоты предобработки гарантируют, что выходные данные декодирования одного сложного слоя не будут перезаписаны, пока они еще используются.
Проекция "down" получает наибольшую выгоду от этого совмещения: она потребляется последней в последовательности MLP (после gate, активации и up), поэтому у ее декодирования самая длинная "взлетная полоса" для завершения.
Автонастройка
При наличии четырех конвейеров, нескольких вариантов ядра матричного умножения и настраиваемого разделения SM между декодированием и вычислениями пространство конфигураций велико. Вместо жесткого кодирования одной стратегии Unweight использует автонастройщик, который измеряет фактическую сквозную пропускную способность вывода на целевом оборудовании. Он перебирает возможные конфигурации для проекции gate, оставляя проекции up и down фиксированными, затем перебирает up, затем down, повторяя до тех пор, пока улучшения не прекратятся. Результатом является файл конфигурации для конкретной модели, который сообщает среде выполнения, какой именно конвейер, вариант матричного умножения и распределение SM использовать для каждой проекции при каждом размере пакета — все на основе измеренной производительности, а не эвристик.
Один формат сжатия, множество применений
Формат кодирования, исполняемый конвейер и планирование — это независимые выборы. Один и тот же пакет модели, сжатый по Хаффману, может служить как для распространения, так и для вывода:
-
Для распространения кодирование Хаффмана максимизирует сжатие (~22% общего уменьшения размера модели), сокращая время передачи при доставке моделей по сети.
-
Для вывода проекции, закодированные по Хаффману, могут быть преобразованы в промежуточный формат палитры при загрузке модели, обеспечивая наиболее эффективное выполнение в среде выполнения без ограничений со стороны формата распространения.
Единому пакету модели не нужно принимать решение в пользу одной стратегии на этапе упаковки. Среда выполнения динамически выбирает оптимальный путь выполнения для каждой проекции и каждого размера пакета.
Наши результаты
На модели Llama 3.1 8B (нашей основной тестовой платформе) Unweight обеспечивает:
-
~13% сокращение объема модели для пакетов вывода (сжатие только проекций MLP gate/up) или ~22% для пакетов распространения (сжатие всех проекций MLP, включая down). Все сжатие является 100% бит-точным и без потерь. Экстраполяция на Llama 70B может означать экономию примерно 18–28 ГБ в зависимости от конфигурации.
-
Накладные расходы на пропускную способность в 30–40% при текущем уровне оптимизации, измеренные сквозным образом на H100 SXM5. Накладные расходы максимальны при размере пакета 1 (~41%) и снижаются при размере пакета 1024 (~30%). Три известных источника — фиксированные издержки при малых размерах пакета, избыточное восстановление блоков весов и исключенная проекция down — находятся в активной оптимизации.
Это промежуточные результаты для одной модели. Коэффициенты сжатия должны быть применимы к другим архитектурам SwiGLU (статистика экспонент согласована для моделей разных масштабов), но цифры пропускной способности специфичны для текущих реализаций ядер и будут меняться по мере продолжения оптимизации. Мы пока не сжимаем веса внимания, эмбеддинги или нормы слоев, что снижает общее сокращение.
Почему это важно
Графические процессоры дороги в нескольких аспектах: стоимость самих карт, высокоскоростная память, которую они требуют, и их значительное энергопотребление.
Для борьбы с этим несколько исследователей показали системы с перспективными результатами — степенью сжатия около 30% для полных моделей, — но они ориентированы на потребительские графические процессоры и исследовательские фреймворки, которые не работают в производственном масштабе. Ключевое понимание при разработке Unweight заключается в том, что многослойные перцептроны (MLP) составляют большинство весов модели и значительную часть вычислительных затрат при выполнении задач вывода. Он сжимает только веса MLP (избегая накладных расходов на слоях, где выгода от сжатия незначительна), разработан специально для датацентровых графических процессоров H100 с их сбалансированными вычислительными возможностями и памятью и использует четыре конвейера выполнения, которые адаптируются к размеру пакета, а не применяют единый подход.
Однако мы хотим прояснить: Unweight — это не бесплатный обед. Реконструкция на чипе добавляет вычислительную работу, которой не существует при несжатых весах. Для модели Llama 3.1 8B конфигурация для вывода экономит примерно 13% от общей памяти модели ценой снижения пропускной способности примерно на 30% при типичных размерах пакетов обслуживания. Этот разрыв сокращается при больших пакетах (где улучшается перекрытие предобработки) и, как ожидается, сократится еще больше по мере нашей оптимизации — в частности, мы еще не сжали проекцию down в каждом слое MLP (около одной трети сжимаемых весов), и несколько улучшений ядра находятся в активной разработке.
Для сети Cloudflare Unweight дает нам лучшую емкость: он позволяет обслуживать современные модели с меньшим объемом памяти графического процессора на экземпляр, что приводит к экономии затрат и возможности развертывать больше моделей в большем количестве мест. Для распространения моделей экономия больше: пакеты, сжатые по Хаффману, примерно на 22% меньше, что сокращает время передачи при отправке моделей в периферийные локации по всему миру.
Что дальше
В перспективе у нас есть три конкретных направления исследований, которые, как мы полагаем, улучшат наши достижения в эффективности:
Сжатие проекции down. На данный момент Unweight сжимает проекции gate и up в MLP, но проекция down составляет примерно одну треть сжимаемых весов. Это требует другого варианта ядра из-за ее транспонированных размеров, что, как мы ожидаем, уменьшит общий размер модели более чем на 22%.
Оптимизация ядра. Текущие 30–40% накладных расходов на пропускную способность имеют три выявленных источника: фиксированные затраты при малых размерах пакета в реконструктивной матричной операции, избыточная реконструкция весов при больших размерах пакетов и отсутствие сжатия проекции down. Для каждого из них есть известный путь смягчения, который мы описываем в нашем техническом документе.
Больше моделей. Наши результаты получены для Llama 3.1 8B, но базовые статистики экспонент согласованы для архитектур SwiGLU всех масштабов. Мы работаем над тем, чтобы внедрить Unweight в более крупные модели, которые мы обслуживаем через Workers AI.
В долгосрочной перспективе мы исследуем, что архитектура Unweight означает для моделей типа Mixture-of-Experts, где "холодные" эксперты должны извлекаться по требованию, а сокращенный объем хранилища дополнительно снизит затраты.
Это быстро развивающаяся область, поэтому мы рады открыть исходный код нашей работы и внести вклад в растущий массив исследований по сжатию и эффективности GPU. Unweight — это один элемент головоломки, но мы надеемся, что другие исследователи найдут его полезной парадигмой для дальнейшего развития!
