По мере того как разработчики создают всё более сложных агентов на Cloudflare, одной из самых больших проблем, с которой они сталкиваются, является предоставление нужной информации в контексте в нужное время. Качество результатов, выдаваемых моделями, напрямую связано с качеством контекста, с которым они работают, но даже при том, что размеры контекстных окон уже превышают миллион (1M) токенов, контекстное гниение остаётся нерешённой проблемой. Возникает естественное противоречие между двумя плохими вариантами: держать всё в контексте и наблюдать за деградацией качества или агрессивно обрезать и рисковать потерять информацию, которая понадобится агенту позже.
Сегодня мы анонсируем закрытую бета-версию Agent Memory — управляемого сервиса, который извлекает информацию из разговоров агентов и делает её доступной, когда это необходимо, не заполняя при этом контекстное окно.
Он даёт ИИ-агентам постоянную память, позволяя им вспоминать важное, забывать несущественное и становиться умнее со временем. В этом посте мы объясним, как это работает — и что это поможет вам построить.
Состояние дел с памятью агентов
Память агентов — одна из самых быстроразвивающихся областей в инфраструктуре ИИ, где новые open-source библиотеки, управляемые сервисы и исследовательские прототипы появляются почти еженедельно. Эти предложения сильно различаются по тому, что они хранят, как извлекают информацию и для каких типов агентов предназначены. Бенчмарки, такие как LongMemEval, LoCoMo и BEAM, дают полезное сравнение "яблок с яблоками", но они также позволяют легко создавать системы, которые переобучаются под конкретную оценку и ломаются в продакшене.
Существующие предложения также различаются по архитектуре. Некоторые — это управляемые сервисы, которые обрабатывают извлечение и поиск в фоне; другие — это саморазмещаемые фреймворки, где вы сами запускаете конвейер памяти. Некоторые предоставляют ограниченные, специализированные API, которые держат логику памяти вне основного контекста агента; другие дают модели прямой доступ к базе данных или файловой системе, позволяя ей самой проектировать свои запросы, сжигая токены на стратегию хранения и извлечения, а не на саму задачу. Некоторые пытаются уместить всё в контекстное окно, разделяя его между несколькими агентами при необходимости, в то время как другие используют поиск, чтобы поднять наверх только релевантное.
Agent Memory — это управляемый сервис с продуманным API и архитектурой на основе поиска. Мы тщательно рассмотрели альтернативы и считаем, что эта комбинация является правильным выбором по умолчанию для большинства рабочих нагрузок в продакшене. Более тесные конвейеры приёма и поиска лучше, чем предоставление агентам прямого доступа к файловой системе. Помимо улучшенных стоимости и производительности, они предоставляют лучшую основу для сложных задач логического вывода, требуемых в продакшене, таких как темпоральная логика, замещение и следование инструкциям. В будущем мы, вероятно, предоставим данные для программного запроса, но ожидаем, что это будет полезно для частных случаев, а не для типичных.
Мы создали Agent Memory, потому что рабочие нагрузки, которые мы видим на нашей платформе, выявили пробелы, которые существующие подходы не полностью устраняют. Агентам, работающим неделями или месяцами с реальными кодобазами и продакшен-системами, нужна память, которая остаётся полезной по мере роста — а не просто память, которая хорошо показывает себя на чистом наборе данных для бенчмарков, который может полностью поместиться в контекстное окно новой модели.
Им нужен быстрый приём данных. Им нужен поиск, который не блокирует разговор. И им нужно работать на моделях, которые сохраняют стоимость одного запроса приемлемой.
Как этим пользоваться
Agent Memory хранит воспоминания в профиле, который адресуется по имени. Профиль предоставляет несколько операций: принять (ingest) разговор, запомнить (remember) что-то конкретное, вспомнить (recall) то, что нужно, вывести список воспоминаний или забыть (forget) конкретное воспоминание. Ingest — это основной путь, который обычно вызывается, когда оболочка (harness) сжимает контекст. Remember — это для того, чтобы модель сохранила что-то важное на месте. Recall запускает весь конвейер поиска и возвращает синтезированный ответ.
export default {
async fetch(request: Request, env: Env): Promise<Response> {
// Получить профиль — изолированное хранилище памяти, общее для сессий, агентов и пользователей
const profile = await env.MEMORY.getProfile("my-project");
// Ingest — извлечь воспоминания из разговора (обычно вызывается при сжатии)
await profile.ingest([
{ role: "user", content: "Настрой проект с React и TypeScript." },
{ role: "assistant", content: "Готово. Создал каркас проекта React + TS для Workers." },
{ role: "user", content: "Используй pnpm, а не npm. И тёмный режим по умолчанию." },
{ role: "assistant", content: "Понял — pnpm и тёмный режим по умолчанию." },
], { sessionId: "session-001" });
// Remember — явно сохранить одно воспоминание (прямое использование инструмента моделью)
const memory = await profile.remember({
content: "Лимит запросов API был увеличен до 10 000 запр./с на зону после инцидента 10 апреля.",
sessionId: "session-001",
});
// Recall — получить воспоминания и получить синтезированный ответ
const results = await profile.recall("Какой пакетный менеджер предпочитает пользователь?");
console.log(results.result); // "Пользователь предпочитает pnpm вместо npm."
return Response.json({ ok: true });
},
};К Agent Memory можно получить доступ через привязку (binding) из любого Cloudflare Worker. Также к нему можно получить доступ через REST API для агентов, работающих вне Workers, по той же схеме, что и другие API платформы для разработчиков Cloudflare. Если вы создаёте что-то с помощью Cloudflare Agents SDK, служба Agent Memory аккуратно интегрируется в качестве референсной реализации для обработки сжатия, запоминания и поиска по воспоминаниям в части памяти Sessions API.
Что с этим можно построить
Agent Memory разработан для работы с рядом архитектур агентов:
Память для отдельных агентов. Независимо от того, создаёте ли вы агенты для кодирования, такие как Claude Code или OpenCode, с участием человека в цикле, используете саморазмещаемые фреймворки агентов, такие как OpenClaw или Hermes, чтобы действовать от вашего имени, или подключаете управляемые сервисы, такие как Managed Agents от Anthropic, Agent Memory может служить уровнем постоянной памяти без каких-либо изменений в основном цикле агента.
Память для пользовательских оболочек (harnesses) агентов. Многие команды создают свою собственную инфраструктуру агентов, включая фоновых агентов, которые работают автономно без участия человека. Ramp Inspect — один из публичных примеров; Stripe и Spotify описали похожие системы. Эти оболочки также могут получить выгоду от предоставления своим агентам памяти, которая сохраняется между сессиями и переживает перезапуски.
Общая память между агентами, людьми и инструментами. Профиль памяти не обязательно должен принадлежать одному агенту. Команда инженеров может совместно использовать профиль памяти, чтобы знания, полученные агентом для кодирования одного человека, были доступны всем: соглашения по кодированию, архитектурные решения, племенные знания, которые сейчас живут в головах людей или теряются при обрезке контекста. Бот для проверки кода и агент для кодирования могут совместно использовать память, чтобы отзывы по код-ревью влияли на будущую генерацию кода. Знания, которые накапливают ваши агенты, перестают быть эфемерными и становятся прочным активом команды.
Хотя поиск является компонентом памяти, поиск для агентов и память агентов решают разные задачи. AI Search — это наш базовый элемент для поиска результатов по неструктурированным и структурированным файлам; Agent Memory предназначен для извлечения контекста. Данные в Agent Memory не существуют в виде файлов; они получены из сессий. Агент может использовать и то, и другое, и они разработаны для совместной работы.
Ваши воспоминания принадлежат вам
По мере того как агенты становятся более способными и глубже внедряются в бизнес-процессы, память, которую они накапливают, становится по-настоящему ценной — не только как операционное состояние, но и как институциональные знания, для построения которых потребовалась реальная работа. Мы слышим растущую озабоченность клиентов по поводу того, что значит привязать этот актив к одному вендору, и это разумно. Чем больше учится агент, тем выше стоимость переключения, если эта память не может переместиться вместе с ним.
Agent Memory — это управляемый сервис, но ваши данные принадлежат вам. Каждое воспоминание можно экспортировать, и мы стремимся к тому, чтобы знания, которые накапливают ваши агенты на Cloudflare, могли уйти с вами, если ваши потребности изменятся. Мы считаем, что правильный способ заслужить долгосрочное доверие — это сделать уход лёгким и продолжать создавать что-то достаточно хорошее, чтобы вы не захотели уходить.
Как работает Agent Memory
Чтобы понять, что происходит за API, показанным выше, полезно разобрать, как агенты управляют контекстом. Агент состоит из трёх компонентов:
-
Оболочка (harness), которая управляет повторными вызовами модели, обеспечивает вызовы инструментов и управляет состоянием.
-
Модель, которая принимает контекст и возвращает завершения.
-
Состояние, которое включает как текущее окно контекста, так и дополнительную информацию вне контекста: историю разговоров, файлы, базы данных, память.
Критическим моментом в жизненном цикле контекста агента является сжатие, когда управляющий механизм решает сократить контекст, чтобы остаться в пределах лимитов модели или избежать деградации контекста. Сегодня большинство агентов безвозвратно отбрасывают информацию. Память агента сохраняет знания при сжатии, вместо того чтобы терять их.
Память агента интегрируется в этот жизненный цикл двумя способами:
-
Массовое поглощение при сжатии. Когда управляющий механизм сжимает контекст, он отправляет разговор в Память агента для поглощения. Поглощение извлекает факты, события, инструкции и задачи из истории сообщений, дедуплицирует их по отношению к существующим воспоминаниям и сохраняет их как воспоминания для будущего извлечения.
-
Прямое использование инструментов моделью. Модель получает инструменты для непосредственного взаимодействия с воспоминаниями, включая возможность вспоминать (искать в воспоминаниях конкретную информацию). Модель также может запоминать (явно сохранять воспоминания на основе чего-то важного), забывать (помечать воспоминание как более не важное или неверное) и перечислять (видеть, какие воспоминания сохранены). Это легковесные операции, которые не требуют от модели проектировать запросы или управлять хранилищем. Основному агенту никогда не следует тратить контекст на стратегию хранения. Поверхность инструментов, которую он видит, намеренно ограничена, чтобы память не мешала выполнению фактической задачи.
Конвейер поглощения
Когда разговор поступает для поглощения, он проходит через многоэтапный конвейер, который извлекает, проверяет, классифицирует и сохраняет воспоминания.
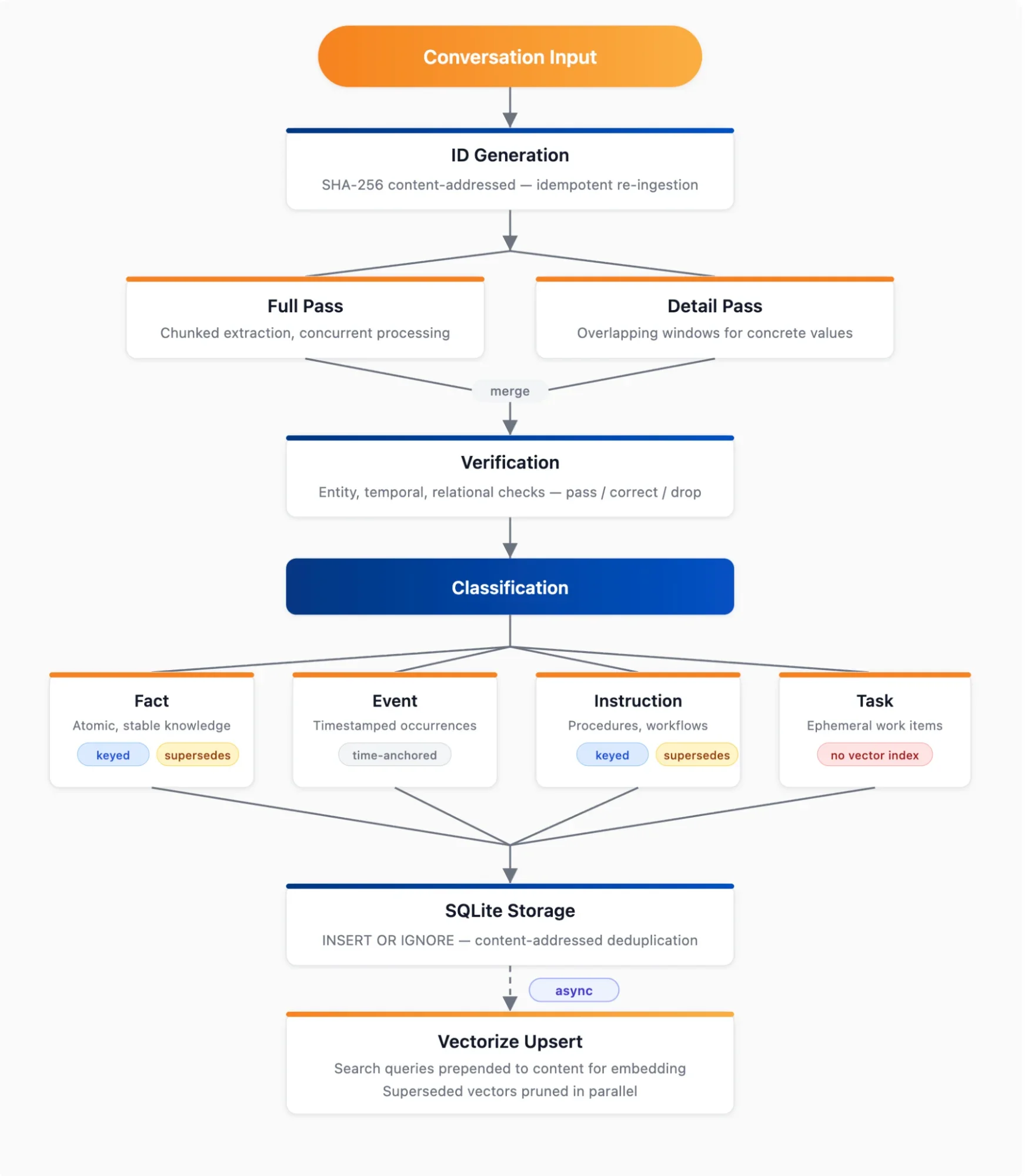
Первый шаг — детерминированная генерация ID. Каждое сообщение получает ID на основе содержимого — хэш SHA-256 от ID сессии, роли и содержимого, обрезанный до 128 бит. Если один и тот же разговор поглощается дважды, каждое сообщение разрешается в тот же ID, что делает повторное поглощение идемпотентным.
Далее экстрактор выполняет два прохода параллельно. Полный проход разбивает сообщения на фрагменты примерно по 10 тыс. символов с перекрытием в два сообщения и обрабатывает до четырёх фрагментов одновременно. Каждый фрагмент получает структурированную транскрипцию с метками ролей, относительными датами, преобразованными в абсолютные («вчера» становится «2026-04-14»), и индексами строк для указания источника. Для более длинных разговоров (9+ сообщений) параллельно с полным проходом запускается детальный проход, использующий перекрывающиеся окна, которые фокусируются specifically на извлечении конкретных значений, таких как имена, цены, номера версий и атрибуты сущностей, которые широкое извлечение склонно упускать. Затем два набора результатов объединяются.
Следующий шаг — проверка каждого извлечённого воспоминания на соответствие исходной транскрипции. Верификатор выполняет восемь проверок, охватывающих идентичность сущности, идентичность объекта, контекст местоположения, временную точность, организационный контекст, полноту, реляционный контекст и то, подтверждаются ли выведенные факты разговором. Каждый элемент соответственно принимается, корректируется или отбрасывается.
Затем конвейер классифицирует каждое проверенное воспоминание на один из четырёх типов.
-
Факты представляют то, что истинно прямо сейчас, атомарное, стабильное знание, такое как «в проекте используется GraphQL» или «пользователь предпочитает тёмную тему».
-
События фиксируют то, что произошло в конкретное время, например, развёртывание или принятие решения.
-
Инструкции описывают, как что-то сделать, например, процедуры, рабочие процессы, руководства.
-
Задачи отслеживают то, над чем работают прямо сейчас, и по замыслу являются эфемерными.
Факты и инструкции имеют ключи. Каждый получает нормализованный тематический ключ, и когда новое воспоминание имеет тот же ключ, что и существующее, старое воспоминание замещается, а не удаляется. Это создаёт цепочку версий с прямым указателем от старого воспоминания к новому. Задачи полностью исключены из векторного индекса, чтобы сохранить его лёгким, но остаются обнаруживаемыми через полнотекстовый поиск.
Наконец, всё записывается в хранилище с помощью INSERT OR IGNORE, чтобы дубликаты на основе содержимого тихо пропускались. После возврата ответа управляющему механизму фоновая векторзация выполняется асинхронно. Текст для эмбеддинга добавляет 3-5 поисковых запросов, сгенерированных во время классификации, к самому содержимому воспоминания, устраняя разрыв между тем, как воспоминания записываются (декларативно: «пользователь предпочитает тёмную тему»), и тем, как они ищутся (вопросительно: «какую тему хочет пользователь?»). Векторы для замещённых воспоминаний удаляются параллельно с добавлением новых.
Конвейер извлечения
Когда агент ищет воспоминание, запрос проходит через отдельный конвейер извлечения. В ходе разработки мы обнаружили, что ни один метод извлечения не работает лучше всего для всех запросов, поэтому мы запускаем несколько методов параллельно и объединяем результаты.
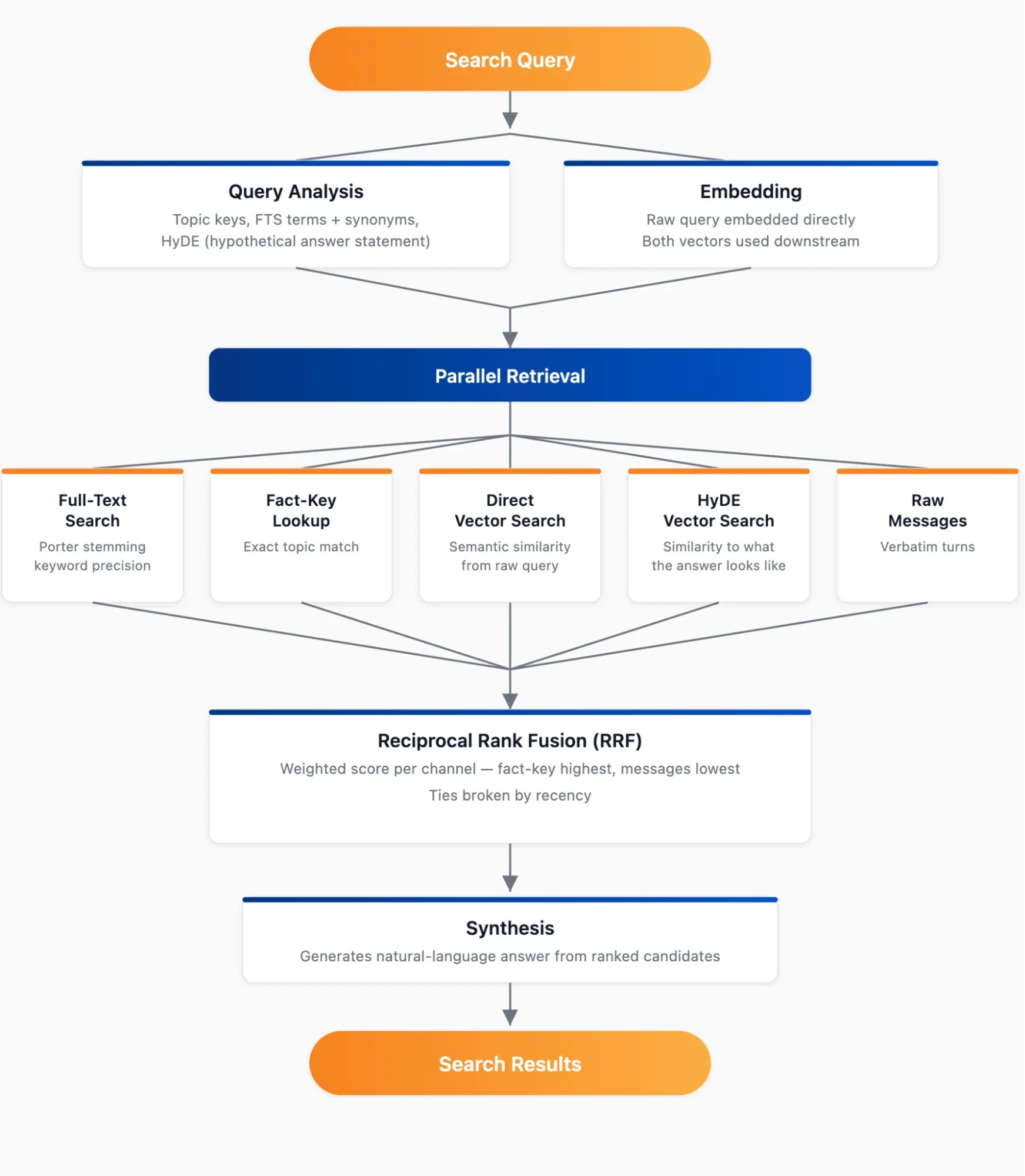
На первом этапе параллельно выполняются анализ запроса и создание эмбеддинга. Анализатор запросов создаёт ранжированные тематические ключи, полнотекстовые поисковые термины с синонимами и HyDE (Гипотетическое Эмбеддинг Документа) — декларативное утверждение, сформулированное так, как если бы оно было ответом на вопрос. Этот этап также напрямую создаёт эмбеддинг исходного запроса, и оба эмбеддинга используются на следующих этапах.
На следующем этапе пять каналов извлечения работают параллельно. Полнотекстовый поиск с стеммингом Портера обеспечивает точность по ключевым словам для запросов, где известно точное слово, но не окружающий контекст. Точный поиск по ключу факта возвращает результаты, где запрос напрямую соответствует известному тематическому ключу. Поиск по исходным сообщениям запрашивает напрямую сохранённые сообщения разговора через полнотекстовый поиск для неклассифицированных фрагментов разговора, действуя как страховочная сеть и улавливая дословные детали, которые конвейер извлечения мог обобщить. Прямой векторный поиск находит семантически похожие воспоминания с использованием эмбеддинга запроса. А векторный поиск по HyDE находит воспоминания, похожие на то, как выглядел бы ответ, что часто выявляет результаты, которые пропускает прямое эмбеддирование — особенно для абстрактных или многошаговых запросов, где вопрос и ответ используют разную лексику.
На третьем, заключительном этапе, результаты со всех пяти каналов извлечения объединяются с использованием Reciprocal Rank Fusion (RRF), где каждый результат получает взвешенный балл на основе его позиции в данном канале. Совпадения по ключу факта получают наибольший вес, потому что точное тематическое совпадение — самый сильный сигнал. Полнотекстовый поиск, векторы HyDE и прямые векторы взвешиваются в зависимости от силы сигнала. Наконец, совпадения по исходным сообщениям также включаются с низким весом в качестве страховочной сети для выявления кандидатов, которые конвейер извлечения мог пропустить. Ничьи разрываются по новизне, при этом более новые результаты ранжируются выше.
Затем конвейер передаёт топ-кандидатов модели синтеза, которая генерирует ответ на естественном языке на исходный поисковый запрос. Некоторые специфические типы запросов получают особую обработку. Например, временные вычисления обрабатываются детерминированно через регулярные выражения и арифметику, а не с помощью LLM. Результаты внедряются в промпт синтеза как предварительно вычисленные факты. Модели ненадёжны в таких вещах, как вычисление дат, поэтому мы не просим их делать это.
Как мы это построили
Наш первоначальный прототип Памяти агента был легковесным, с базовым конвейером извлечения, векторным хранилищем и простым извлечением. Он работал достаточно хорошо, чтобы продемонстрировать концепцию, но недостаточно хорошо для выпуска.
Поэтому мы поместили его в цикл, управляемый агентом, и начали итерации. Цикл выглядел так: запуск бенчмарков, анализ пробелов, предложение решений, человеческий обзор предложений для выбора стратегий, которые обобщают, а не переобучаются, позволить агенту внести изменения, повторить.
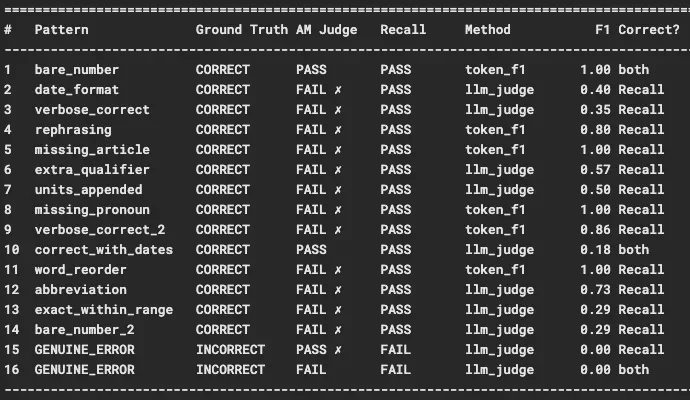
Это работало хорошо, но сопровождалось одной конкретной проблемой. LLM стохастичны, даже при температуре, установленной на ноль. Это вызывало варьирование результатов между запусками, что означало необходимость усреднения нескольких запусков (трудоёмко для больших бенчмарков) и reliance на анализ трендов вместе с сырыми баллами, чтобы понять, что на самом деле работает. По пути нам пришлось тщательно остерегаться переобучения на бенчмарках способами, которые не делали продукт genuinely лучше для общего случая.
Со временем это привело нас к состоянию, когда баллы бенчмарков последовательно улучшались с каждой итерацией, и у нас была обобщённая архитектура, которая будет работать в реальном мире. Мы намеренно тестировали на нескольких бенчмарках (включая LoCoMo, LongMemEval и BEAM), чтобы проверить систему по-разному.
Почему Cloudflare
Мы строим Cloudflare на Cloudflare, и Память агента не исключение. Существующие примитивы, которые мощны и легко комбинируются, позволили нам выпустить первый прототип за выходные и полностью функционирующую, подготовленную к production внутреннюю версию Памяти агента менее чем за месяц. Помимо скорости разработки, Cloudflare оказался идеальным местом для создания такого рода сервиса ещё по нескольким причинам.
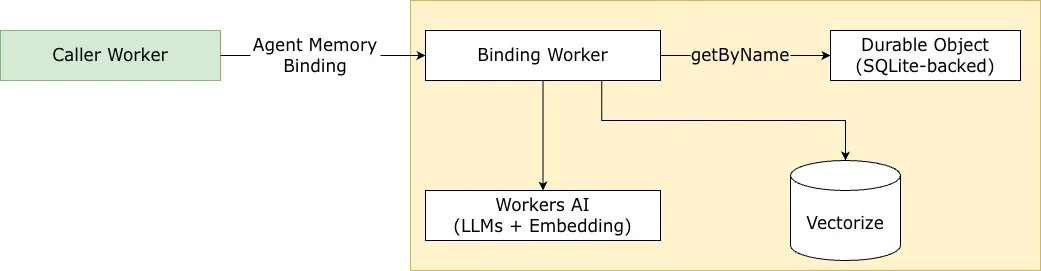
Под капотом Память агента — это Cloudflare Worker, который координирует несколько систем:
-
Durable Object: хранит исходные сообщения и классифицированные воспоминания
-
Vectorize: обеспечивает векторный поиск по эмбеддингам воспоминаний
-
Workers AI: запускает LLM и модели эмбеддинга
Каждый контекст памяти соответствует своему экземпляру Durable Object и индексу Vectorize, что обеспечивает полную изоляцию данных между контекстами. Это также позволяет нам легко масштабироваться при росте нагрузки.
Изоляция вычислений через Durable Objects. Каждый профиль памяти получает свой собственный Durable Object (DO) с хранилищем на базе SQLite, обеспечивая строгую изоляцию между клиентами без каких-либо накладных расходов на инфраструктуру. DO отвечает за полнотекстовое индексирование (FTS), цепочки замещения версий и транзакционные записи. Адресация DO через getByName() означает, что любой запрос из любого места может получить доступ к нужному профилю памяти по имени и гарантирует, что конфиденциальные данные памяти строго изолированы от других клиентов.
Хранилище по всему стеку. Содержимое памяти хранится в DO на базе SQLite. Векторные представления находятся в Vectorize. В будущем снимки состояния (снапшоты) и экспорт будут отправляться в R2 для экономичного долгосрочного хранения. Каждый примитив создан под конкретную задачу, нам не нужно заталкивать всё в единую форму или базу данных.
Локальный вывод моделей с Workers AI. Весь конвейер извлечения, классификации и синтеза работает на моделях Workers AI, развернутых в сети Cloudflare. Все вызовы к ИИ передают заголовок аффининости сессии (session affinity), привязанный к имени профиля памяти, так что повторные запросы попадают на один и тот же бэкенд, что дает преимущества кэширования промптов.
Одно интересное наблюдение из нашего выбора моделей: более крупная и мощная модель не всегда лучше. В настоящее время по умолчанию мы используем Llama 4 Scout (17B, 16-экспертная MoE) для извлечения, проверки, классификации и анализа запросов, а Nemotron 3 (120B MoE, 12B активных параметров) — для синтеза. Scout эффективно справляется со структурированными задачами классификации, в то время как более широкие возможности рассуждений Nemotron улучшают качество ответов на естественном языке. Синтезатор — это единственный этап, где увеличение количества параметров для решения задачи последовательно давало результат. Для всего остального меньшая модель нашла лучший баланс стоимости, качества и задержки.
Как мы это используем
Мы используем Agent Memory внутри компании для наших рабочих процессов в Cloudflare, как полигон для испытаний и источник идей для дальнейшей разработки.
Память для агентов, пишущих код. Мы используем внутренний плагин OpenCode, который интегрирует Agent Memory в цикл разработки. Agent Memory обеспечивает запоминание предыдущих решений как в рамках одной сессии, так и между сессиями. Менее очевидным преимуществом стала общая память для команды: с общим профилем агент знает, что уже изучили другие члены вашей команды, что означает, что он может перестать задавать вопросы, на которые уже есть ответы, и перестать совершать ошибки, которые уже были исправлены.
Агентный ревью кода. Мы подключили Agent Memory к нашему внутреннему агентному ревьюеру кода. Пожалуй, самой полезной вещью, которую он научился делать, было молчать. Теперь ревьюер помнит, что конкретный комментарий был нерелевантен в прошлом ревью, что определенный шаблон был отмечен, и автор решил оставить его по уважительной причине. Ревью со временем становятся не только умнее, но и менее зашумленными.
Чат-боты. Мы также встроили память во внутреннего чат-бота, который принимает историю сообщений, а затем отслеживает и запоминает новые отправленные сообщения. Затем, когда кто-то задает вопрос, бот может ответить на основе предыдущих обсуждений.
У нас также есть ряд дополнительных сценариев использования, которые мы планируем внедрить внутри компании в ближайшем будущем по мере доработки и улучшения сервиса.
Что дальше
Мы продолжаем тестировать и дорабатывать Agent Memory внутри компании, улучшая конвейер извлечения, настраивая качество поиска и расширяя возможности фоновой обработки. Подобно тому, как человеческий мозг консолидирует воспоминания, воспроизводя и укрепляя связи во время сна, мы видим возможности для асинхронного улучшения хранения памяти и в настоящее время реализуем и тестируем различные стратегии для этого.
Мы планируем вскоре сделать Agent Memory общедоступным. Если вы создаете агентов на Cloudflare и хотите получить ранний доступ, свяжитесь с нами, чтобы присоединиться к листу ожидания.