Каждому агенту нужен поиск: агенты для программирования ищут среди миллионов файлов в репозиториях. Агенты поддержки ищут в обращениях клиентов и внутренней документации. Даже память агента, его способность вспоминать прошлые взаимодействия, по своей сути является проблемой поиска. Сценарии использования разные, но базовая проблема одна: предоставить модели нужную информацию в нужное время.
Если вы создаёте поиск самостоятельно, вам понадобится векторный индекс, конвейер индексации для обработки и разбиения ваших документов, а также что-то, что будет поддерживать индекс в актуальном состоянии при изменении данных. Если вам также нужен поиск по ключевым словам, это отдельный индекс и логика слияния поверх. И если каждому вашему агенту нужен собственный контекст для поиска, вам придётся настраивать всё это для каждого агента.
AI Search (ранее AutoRAG) — это готовый к использованию поисковый примитив, который вам нужен. Вы можете динамически создавать экземпляры, загружать в них ваши данные и выполнять поиск — из Worker, Agents SDK или Wrangler CLI. Вот что мы представляем:
-
Гибридный поиск. Включите семантическое соответствие и соответствие по ключевым словам в одном запросе. Векторный поиск и BM25 работают параллельно, а результаты объединяются. (Поиск в нашем блоге теперь работает на AI Search. Попробуйте значок лупы в правом верхнем углу.)
-
Встроенное хранилище и индекс. Новые экземпляры поставляются со своим собственным хранилищем и векторным индексом. Загружайте файлы напрямую в экземпляр через API, и они будут проиндексированы. Не нужно настраивать бакеты R2, не нужно подключать внешние источники данных. Новое привязка
ai_search_namespacesпозволяет создавать и удалять экземпляры во время выполнения из вашего Worker, так что вы можете запускать по одному на агента, на клиента или на язык без повторного развертывания.
Теперь вы также можете прикреплять метаданные к документам и использовать их для повышения рейтинга во время запроса, а также выполнять запросы к нескольким экземплярам за один вызов.
Теперь давайте посмотрим, что это значит на практике.
На практике: Агент поддержки клиентов
Давайте рассмотрим агента поддержки, который ищет два вида знаний: общую документацию по продукту и историю каждого клиента, например, прошлые решения проблем. Документация по продукту слишком велика, чтобы поместиться в контекстное окно, а история каждого клиента растёт с каждым решённым вопросом, поэтому агенту требуется извлечение информации, чтобы найти релевантные данные.
Вот как это выглядит с AI Search и Agents SDK. Начните с создания каркаса проекта:
npm create cloudflare@latest -- --template cloudflare/agents-starter
Сначала привяжите пространство имён AI Search к вашему Worker:
// wrangler.jsonc
{
"ai_search_namespaces": [
{ "binding": "SUPPORT_KB", "namespace": "support" }
],
"ai": { "binding": "AI" },
"durable_objects": {
"bindings": [
{ "name": "SupportAgent", "class_name": "SupportAgent" }
]
}
}
Предположим, ваша общая документация по продукту находится в бакете R2 с именем product-doc. Вы можете создать одноразовый экземпляр AI Search (с именем product-knowledge), связанный с бакетом, в Cloudflare Dashboard внутри пространства имён support:
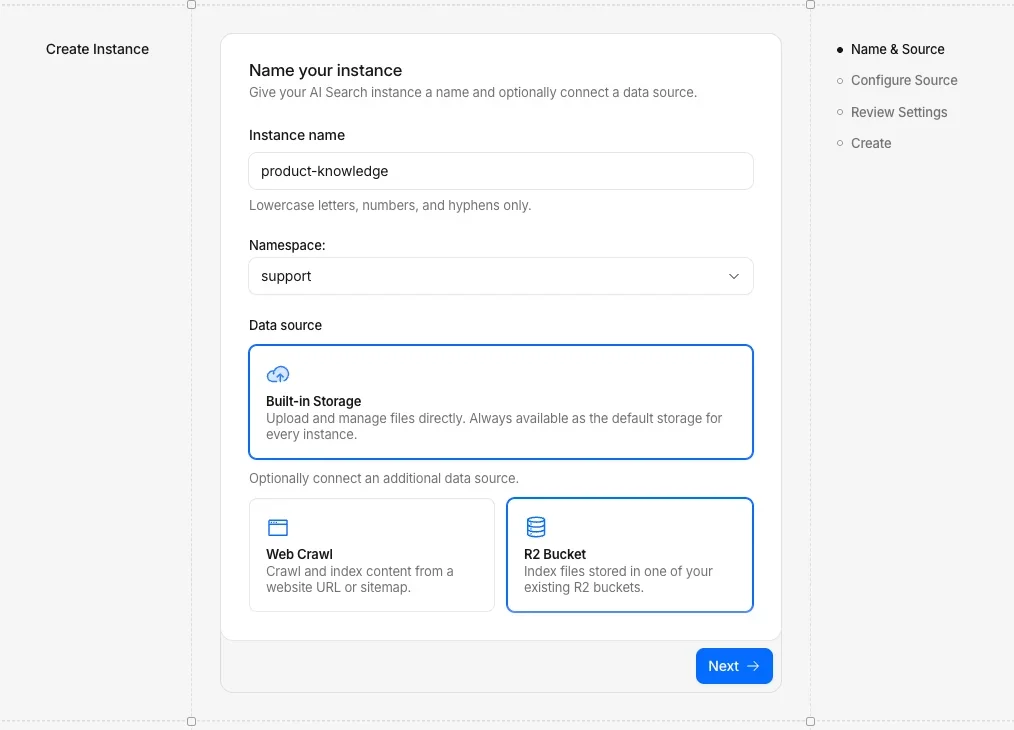
Это ваша общая база знаний, документация, к которой могут обращаться все агенты.
Когда клиент возвращается с новой проблемой, знание о том, что уже было опробовано, экономит время всем. Вы можете отслеживать это, создавая экземпляр AI Search для каждого клиента. После каждого решённого вопроса агент сохраняет краткое описание того, что пошло не так и как это было исправлено. Со временем это создаёт доступный для поиска журнал прошлых решений. Вы можете создавать экземпляры динамически, используя привязку пространства имён:
// создать экземпляр для каждого клиента при его первом появлении
await env.SUPPORT_KB.create({
id: `customer-${customerId}`,
index_method:{ keyword: true, vector: true }
});
Каждый экземпляр получает своё собственное встроенное хранилище и векторный индекс — работающие на R2 и Vectorize. Экземпляр начинается пустым и со временем накапливает контекст. Когда клиент вернётся в следующий раз, вся эта информация будет доступна для поиска.
Вот как выглядит пространство имён после работы с несколькими клиентами:
namespace: "support"
├── product-knowledge (источник — R2, общий для всех агентов)
├── customer-abc123 (управляемое хранилище, для клиента)
├── customer-def456 (управляемое хранилище, для клиента)
└── customer-ghi789 (управляемое хранилище, для клиента)
Теперь сам агент. Он расширяет AIChatAgent из Agents SDK и определяет два инструмента. Мы используем Kimi K2.5 в качестве LLM через Workers AI. Модель решает, когда вызывать инструменты, на основе разговора:
import { AIChatAgent, type OnChatMessageOptions } from "@cloudflare/ai-chat";
import { createWorkersAI } from "workers-ai-provider";
import { streamText, convertToModelMessages, tool, stepCountIs } from "ai";
import { routeAgentRequest } from "agents";
import { z } from "zod";
export class SupportAgent extends AIChatAgent<Env> {
async onChatMessage(_onFinish: unknown, options?: OnChatMessageOptions) {
// клиент передаёт customerId в теле запроса
// через sendMessage({ body: { customerId } }) из Agent SDK
const customerId = options?.body?.customerId;
// создать экземпляр для клиента при его первом появлении.
// каждый экземпляр получает своё хранилище и векторный индекс.
if (customerId) {
try {
await this.env.SUPPORT_KB.create({
id: `customer-${customerId}`,
index_method: { keyword: true, vector: true }
});
} catch {
// экземпляр уже существует
}
}
const workersai = createWorkersAI({ binding: this.env.AI });
const result = streamText({
model: workersai("@cf/moonshotai/kimi-k2.5"),
system: `Вы — агент поддержки. Используйте search_knowledge_base
для поиска релевантных документов перед ответом. Результаты поиска
включают как документацию по продукту, так и прошлые решения
этого клиента — используйте их, чтобы избежать повторения неудачных исправлений
и распознавать повторяющиеся проблемы. Когда проблема
решена, вызовите save_resolution перед ответом.`,
// this.messages — это полная история разговора, автоматически
// сохраняемая AIChatAgent при переподключениях
messages: await convertToModelMessages(this.messages),
tools: {
// инструмент 1: поиск по общей документации по продукту И по
// прошлым решениям этого клиента за один вызов
search_knowledge_base: tool({
description: "Поиск по документации по продукту и истории клиента",
inputSchema: z.object({
query: z.string().describe("Поисковый запрос"),
}),
execute: async ({ query }) => {
// всегда искать в документации по продукту;
// включать историю клиента, если доступна
const instances = ["product-knowledge"];
if (customerId) {
instances.push(`customer-${customerId}`);
}
return await this.env.SUPPORT_KB.search({
query: query,
ai_search_options: {
// показывать новые документы выше старых
boost_by: [
{ field: "timestamp", direction: "desc" }
],
// искать по обоим экземплярам одновременно
instance_ids: instances
}
});
}
}),
// инструмент 2: после решения проблемы агент сохраняет
// краткое описание, чтобы у будущих агентов был полный контекст
save_resolution: tool({
description:
"Сохранить краткое описание решения после решения проблемы клиента",
inputSchema: z.object({
filename: z.string().describe(
"Короткое описательное имя файла, например 'billing-fix.md'"
),
content: z.string().describe(
"В чём была проблема, что её вызвало и как она была решена"
),
}),
execute: async ({ filename, content }) => {
if (!customerId) return { error: "Нет ID клиента" };
const instance = this.env.SUPPORT_KB.get(
`customer-${customerId}`
);
// uploadAndPoll ждёт завершения индексации,
// поэтому решение будет доступно для поиска до следующего запроса
const item = await instance.items.uploadAndPoll(
filename, content
);
return { saved: true, filename, status: item.status };
}
}),
},
// ограничить циклы использования инструментов агента 10 шагами
stopWhen: stepCountIs(10),
abortSignal: options?.abortSignal,
});
return result.toUIMessageStreamResponse();
}
}
// маршрутизировать запросы к устойчивому объекту SupportAgent
export default {
async fetch(request: Request, env: Env) {
return (
(await routeAgentRequest(request, env)) ||
new Response("Не найдено", { status: 404 })
);
}
} satisfies ExportedHandler<Env>;
С этим модель сама решает, когда искать, а когда сохранять. При поиске она запрашивает product-knowledge и прошлые решения этого клиента вместе. Когда проблема решена, она сохраняет краткое описание, которое сразу становится доступным для поиска в будущих разговорах.
Как AI Search находит то, что вам нужно
Под капотом AI Search запускает многоступенчатый конвейер поиска, где каждый шаг можно настраивать.
Гибридный поиск: поиск, который понимает намерение и сопоставляет термины
До сих пор AI Search предлагал только векторный поиск. Векторный поиск отлично понимает намерение, но может упускать детали. В запросе "ERR_CONNECTION_REFUSED timeout" эмбеддинг улавливает общую концепцию сбоев соединения. Но пользователь ищет не общую документацию по сетям. Он ищет конкретный документ, в котором упоминается «ERR_CONNECTION_REFUSED». Векторный поиск может вернуть результаты по устранению неполадок, так и не показав страницу, содержащую именно эту строку с ошибкой.
Ключевой поиск заполняет этот пробел. Теперь AI Search поддерживает BM25 — одну из наиболее широко используемых функций оценки релевантности при поиске. BM25 оценивает документы по частоте появления терминов вашего запроса, редкости этих терминов во всём корпусе документов и длине документа. Он поощряет совпадения по конкретным терминам, штрафует за распространённые слова-заполнители и нормализует оценку с учётом длины документа. Когда вы ищете "ERR_CONNECTION_REFUSED timeout", BM25 находит документы, которые действительно содержат "ERR_CONNECTION_REFUSED" как термин. Однако BM25 может пропустить страницу про «устранение неполадок сетевых подключений», даже если она описывает ту же проблему. Здесь и проявляется сила векторного поиска, и поэтому нужны оба подхода.
Когда вы включаете гибридный поиск, он параллельно выполняет векторный и BM25 поиск, объединяет результаты и, опционально, переранжирует их:
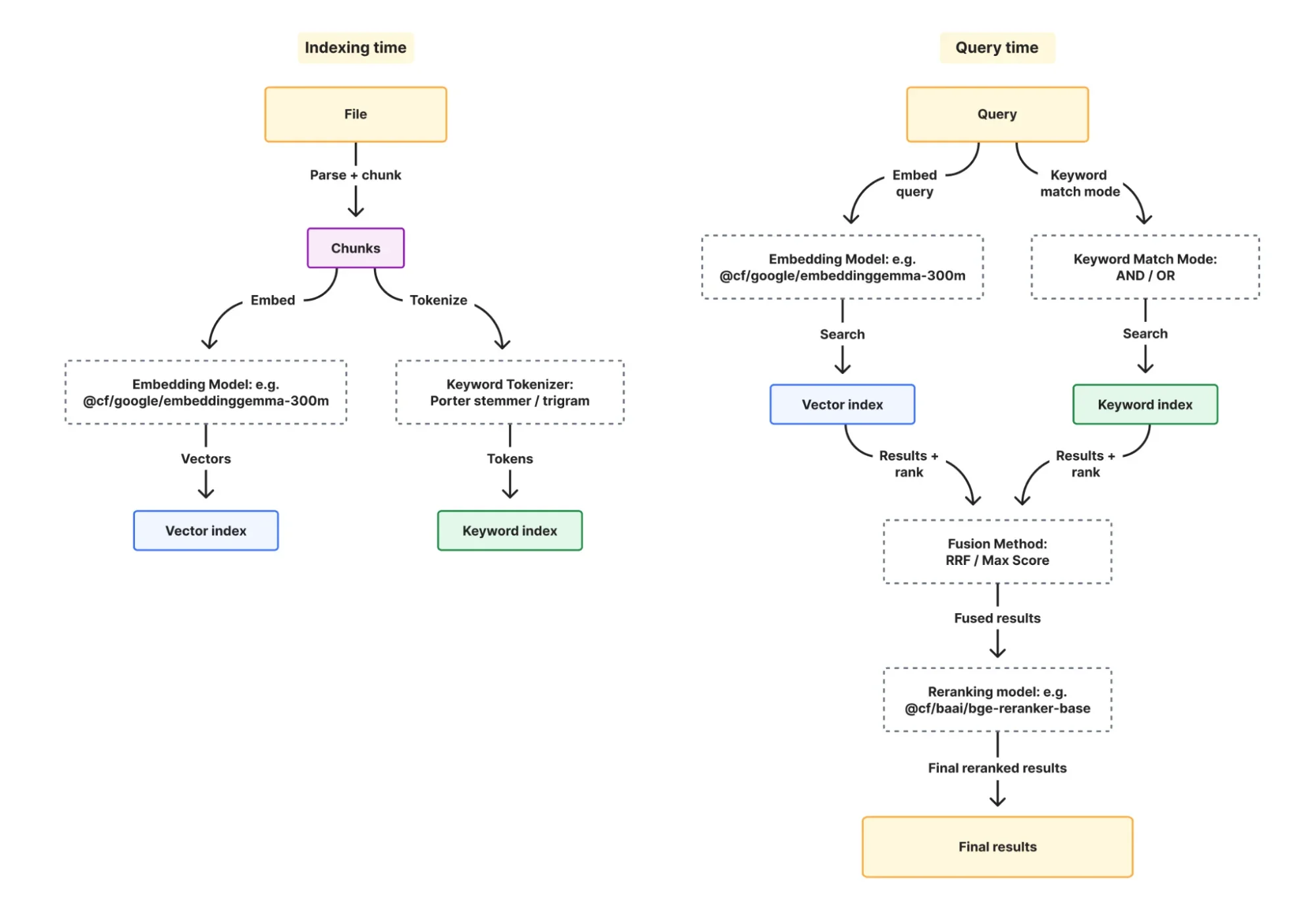
Давайте рассмотрим новые настройки для BM25 и то, как они работают вместе.
-
Токенизатор управляет тем, как ваши документы разбиваются на сопоставимые термины на этапе индексации. Стеммер Портера (опция:
porter) приводит слова к основе, так что "running" совпадает с "run". Триграмма (опция:trigram) сопоставляет подстроки символов, так что "conf" совпадает с "configuration". Вы можете использовать porter для контента на естественном языке, например документации, и trigram для кода, где важны частичные совпадения. -
Режим совпадения ключевых слов управляет тем, какие документы являются кандидатами для оценки BM25 во время запроса.
ANDтребует, чтобы все термины запроса присутствовали в документе, OR включает всё, что имеет хотя бы одно совпадение. -
Слияние управляет тем, как векторные и ключевые результаты объединяются в окончательный список результатов во время запроса. Взаимное слияние рангов (опция:
rrf) объединяет по позиции в ранге, а не по оценке, что позволяет избежать сравнения двух несовместимых шкал оценок, тогда как слияние по максимуму (опция:max) берёт более высокую оценку. -
(Опционально) Переранжирование добавляет этап кросс-энкодера, который переоценивает результаты, оценивая запрос и документ вместе как пару. Это может помочь выявить случаи, когда результат содержит нужные термины, но не отвечает на вопрос.
Каждая опция имеет разумное значение по умолчанию, если она опущена. У вас есть гибкость в настройке того, что важно, при создании нового экземпляра:
const instance = await env.AI_SEARCH.create({
id: "my-instance",
index_method: { keyword: true, vector: true },
indexing_options: {
keyword_tokenizer: "porter"
},
retrieval_options: {
keyword_match_mode: "or"
},
fusion_method: "rrf",
reranking: true,
reranking_model: "@cf/baai/bge-reranker-base"
});
Повышение релевантности: показывайте то, что важно
Поиск даёт релевантные результаты, но одной релевантности не всегда достаточно. Например, при поиске новостей статья за прошлую неделю и статья трёхлетней давности могут быть одинаково семантически релевантны запросу "результаты выборов", но большинству пользователей, вероятно, нужна недавняя. Повышение позволяет наложить бизнес-логику поверх поиска, корректируя ранжирование на основе метаданных документа.
Вы можете повышать на основе временной метки (встроена для каждого элемента) или любого пользовательского поля метаданных, которое вы определите.
// повысить приоритет документов с высоким приоритетом
const results = await instance.search({
query: "руководство по развертыванию",
ai_search_options: {
boost_by: [
{ field: "timestamp", direction: "desc" }
]
}
});
Межэкземплярный поиск: запросы через границы
В примере с агентом поддержки документация по продукту и история решений проблем клиентов по замыслу находятся в отдельных экземплярах. Но когда агент отвечает на вопрос, ему одновременно нужен контекст из обоих источников. Без межэкземплярного поиска пришлось бы делать два отдельных вызова и самостоятельно объединять результаты.
Привязка пространства имён предоставляет метод search(), который делает это за вас. Передайте массив имён экземпляров и получите один ранжированный список:
const results = await env.SUPPORT_KB.search({
query: "ошибка биллинга",
ai_search_options: {
instance_ids: ["product-knowledge", "customer-abc123"]
}
});
Результаты объединяются и ранжируются между экземплярами. Агенту не нужно знать или заботиться о том, что общая документация и история решений проблем клиента хранятся в разных местах.
Как работают экземпляры AI Search
До сих пор мы рассматривали, как AI Search находит нужные результаты. Теперь давайте посмотрим, как вы можете создавать свои поисковые экземпляры и управлять ими.
Если вы использовали AI Search до этого релиза, вы знаете схему настройки: создать корзину R2, привязать её к экземпляру AI Search, AI Search генерирует для вас токен сервисного API, и вы управляете индексом Vectorize, который подготавливается в вашем аккаунте. Загрузка объекта требует записи в R2 и затем ожидания запуска задания синхронизации, чтобы объект был проиндексирован.
Новые экземпляры, создаваемые сейчас, работают иначе. Когда вы вызываете create(), экземпляр поставляется со встроенными собственным хранилищем и векторным индексом. Вы можете загрузить файл, файл сразу отправляется на индексацию, и вы можете отслеживать статус индексации с помощью одного API uploadAndpoll(). После завершения вы можете немедленно выполнять поиск по экземпляру, и нет внешних зависимостей, которые нужно связывать.
const instance = env.AI_SEARCH.get("my-instance");
// загрузить и дождаться завершения индексации
const item = await instance.items.uploadAndPoll("faq.md", content, {
metadata: { category: "onboarding" }
});
console.log(item.status); // "completed"
// немедленно выполнить поиск после завершения индексации
const results = await instance.search({
// альтернативный способ передать запрос пользователя, кроме использования параметра query
messages: [{ role: "user", content: "руководство по началу работы" }],
});
Каждый экземпляр также может подключаться к одному внешнему источнику данных (корзине R2 или веб-сайту) и работать по расписанию синхронизации. Он может существовать наряду со встроенным хранилищем. В примере с агентом поддержки экземпляр product-knowledge использует корзину R2 для общей документации, в то время как экземпляр каждого клиента использует встроенное хранилище для контекста, загружаемого на лету.
Пространства имён: создание поисковых экземпляров во время выполнения
ai_search_namespaces — это новая привязка, которую можно использовать для динамического создания поисковых экземпляров во время выполнения. Она заменяет предыдущий API env.AI.autorag(), который обращался к AI Search через привязку AI. Старые привязки продолжат работать с использованием даты совместимости Workers.
// wrangler.jsonc
{
"ai_search_namespaces": [
{ "binding": "AI_SEARCH", "namespace": "example" },
]
}
Привязка пространства имён предоставляет такие API, как create(), delete(), list() и search() на уровне пространства имён. Если вы создаёте экземпляры динамически (например, для каждого агента, клиента, арендатора), это та привязка, которую нужно использовать.
// создать экземпляр
const instance = await env.AI_SEARCH.create({
id: "my-instance"
});
// удалить экземпляр и все его проиндексированные данные
await env.AI_SEARCH.delete("old-instance");
Цены на новые экземпляры
Новые экземпляры, созданные с сегодняшнего дня, будут автоматически получать встроенное хранилище и векторный индекс.
Эти экземпляры бесплатны для использования, пока AI Search находится в открытой бета-версии, с ограничениями, перечисленными ниже. При использовании веб-сайта в качестве источника данных сканирование веб-сайтов с помощью Browser Run (ранее Browser Rendering) теперь также является встроенной службой, что означает, что за неё не будет отдельной платы. После бета-версии цель — предоставить единую цену для AI Search как единого сервиса, а не отдельно выставлять счёт за каждый базовый компонент. Использование Workers AI и AI Gateway по-прежнему будет тарифицироваться отдельно.
Мы предоставим как минимум 30-дневное уведомление и сообщим детали цен до начала любых выставлений счетов.
|
Ограничение |
Workers Free |
Workers Paid |
|---|---|---|
|
Экземпляры AI Search на аккаунт |
100 |
5 000 |
|
Файлов на экземпляр |
100 000 |
1 млн или 500 тыс. для гибридного поиска (hybrid search) |
|
Максимальный размер файла |
4 МБ |
4 МБ |
|
Запросов в месяц |
20 000 |
Неограниченно |
|
Максимальное количество сканируемых страниц в день |
500 |
Неограниченно |
А что с существующими экземплярами?
Если вы создавали экземпляры до этого релиза, они продолжают работать в точности так же, как и сейчас. Ваши R2 buckets, индексы Vectorize и использование Browser Run остаются на вашем аккаунте и тарифицируются как прежде. Мы скоро поделимся деталями миграции для существующих экземпляров.
Начните сегодня
Поиск — одна из самых фундаментальных возможностей агента. С AI Search вам не нужно создавать инфраструктуру для его реализации. Создайте экземпляр, предоставьте ему свои данные и позвольте вашим агентам выполнять поиск по ним.
Начните сегодня, выполнив эту команду для создания вашего первого экземпляра:
npx wrangler ai-search create my-search
Ознакомьтесь с документацией и расскажите нам, что вы создаёте, в Cloudflare Developer Discord.
