Агенты изменили наше представление о системах контроля версий, файловых системах и сохранении состояния. Разработчики и агенты генерируют больше кода, чем когда-либо — за следующие 5 лет будет написано больше кода, чем за всю историю программирования — и это привело к изменению на порядок величины в масштабах систем, необходимых для удовлетворения этого спроса. Платформы контроля версий особенно страдают от этого: они были созданы для нужд людей, а не для десятикратного роста объёма, вызванного агентами, которые никогда не спят, могут работать над несколькими задачами одновременно и не устают.
Мы считаем, что нужен новый примитив: распределенная, версионированная файловая система, созданная в первую очередь для агентов и способная обслуживать типы приложений, которые создаются сегодня.
Мы называем это Artifacts: версионированная файловая система, которая говорит на Git. Вы можете программно создавать репозитории вместе с вашими агентами, песочницами, Workers или любой другой вычислительной парадигмой и подключаться к ней из любого обычного Git-клиента.
Хотите дать каждой сессии агента свой репозиторий? Artifacts может это сделать. Каждому экземпляру песочницы? Тоже Artifacts. Хотите создать 10 000 форков из известной хорошей отправной точки? Вы угадали: снова Artifacts. Artifacts предоставляет REST API и нативный Workers API для создания репозиториев, генерации учетных данных и коммитов для сред, где Git-клиент не подходит (например, в любой serverless-функции).
Artifacts доступен в закрытой бета-версии для всех разработчиков на платном тарифе Workers, и мы планируем открыть его как публичную бета-версию к началу мая.
// Создать репозиторий
const repo = await env.AGENT_REPOS.create(name)
// Передать токен и удаленный адрес вашему агенту
return { repo.remote, repo.token }# Клонировать его и использовать как любой обычный git remote
$ git clone https://x:${TOKEN}@123def456abc.artifacts.cloudflare.net/git/repo-13194.git
Вот и всё. Голый репозиторий, готовый к работе, созданный на лету, с которым может работать любой git-клиент.
А если вы хотите инициализировать репозиторий Artifacts из существующего git-репозитория, чтобы ваш агент мог работать с ним независимо и отправлять независимые изменения, вы тоже можете это сделать с помощью .import():
interface Env {
ARTIFACTS: Artifacts
}
export default {
async fetch(request: Request, env: Env) {
// Импортировать из GitHub
const { remote, token } = await env.ARTIFACTS.import({
source: {
url: "https://github.com/cloudflare/workers-sdk",
branch: "main",
},
target: {
name: "workers-sdk",
},
})
// Получить дескриптор импортированного репозитория
const repo = await env.ARTIFACTS.get("workers-sdk")
// Форкнуть в изолированную, доступную только для чтения копию
const fork = await repo.fork("workers-sdk-review", {
readOnly: true,
})
return Response.json({ remote: fork.remote, token: fork.token })
},
}Ознакомьтесь с документацией, чтобы начать работу, или, если вы хотите понять, как используется Artifacts, как он был построен и как работает под капотом: читайте дальше.
Почему Git? Что такое версионированная файловая система?
Агенты знают Git. Он глубоко заложен в тренировочных данных большинства моделей. Агентам хорошо известен как стандартный путь работы, так и крайние случаи, а модели, оптимизированные для кода (и/или обвязки), особенно хорошо умеют использовать git.
Кроме того, модель данных Git хороша не только для контроля версий, но и для всего, где нужно отслеживать состояние, путешествовать во времени и хранить большие объемы мелких данных. Код, конфигурация, промпты сессий и история агента: все это вещи («объекты»), которые часто хочется хранить небольшими порциями («коммитами») и иметь возможность откатить или иным образом вернуться к предыдущему состоянию («история»).
Мы могли бы изобрести совершенно новый, специальный протокол… но тогда возникает проблема начальной загрузки. ИИ-модели его не знают, поэтому приходится распространять навыки, или CLI, или надеяться, что пользователи подключены к вашей документации через MCP… все это создает трение. А если мы просто дадим агентам аутентифицированный, безопасный HTTPS Git remote URL, и они будут работать с ним, как с Git-репозиторием? Оказывается, это работает довольно хорошо. А для клиентов, не говорящих на Git — таких как Cloudflare Worker, функция Lambda или приложение Node.js — мы предоставили REST API и (скоро) специфичные для языка SDK. Эти клиенты также могут использовать isomorphic-git, но во многих случаях более простой TypeScript API может сократить необходимую поверхность API.
Не только для контроля версий
Git API Artifacts может заставить вас думать, что он только для контроля версий, но оказывается, что Git API и модель данных — это мощный способ сохранять состояние, позволяющий форкать, путешествовать во времени и сравнивать diff состояния для любых данных.
Внутри Cloudflare мы используем Artifacts для наших внутренних агентов: автоматически сохраняем текущее состояние файловой системы и историю сессии в репозитории Artifacts для каждой сессии. Это позволяет нам:
-
Сохранять состояние песочницы без необходимости выделять (и удерживать) блочное хранилище.
-
Делиться сессиями с другими и позволять им перемещаться назад как по состоянию сессии (промптов), так и по состоянию файлов, независимо от того, были ли коммиты в «фактический» репозиторий (контроль версий).
-
И самое лучшее: форкать сессию с любой точки, позволяя нашей команде делиться сессиями с коллегой, чтобы он мог продолжить с того же места. Отлаживаете что-то и нужен свежий взгляд? Отправьте URL и форкните. Хотите поэкспериментировать с API? Пусть коллега форкнет сессию и продолжит с того места, где вы остановились.
Мы также говорили с командами, которые хотели бы использовать Artifacts в случаях, где протокол Git вообще не требуется, но семантика (откат, клонирование, сравнение diff) требуется. Храните конфигурацию для каждого клиента как часть вашего продукта и хотите иметь возможность отката? Artifacts может быть хорошим представлением для этого.
Мы с нетерпением ждем, когда команды начнут исследовать варианты использования Artifacts, не связанные с Git, так же активно, как и ориентированные на Git.
Под капотом
Artifacts построен поверх Durable Objects. Возможность создавать миллионы (или десятки миллионов+) экземпляров stateful, изолированных вычислений присуща тому, как работают Durable Objects сегодня, и это именно то, что нам нужно для поддержки миллионов Git-репозиториев на пространство имен.
Major League Baseball (для распространения live-игр), Confluence Whiteboards и наш собственный Agents SDK используют Durable Objects под капотом в значительных масштабах, поэтому мы строим это на примитиве, который уже давно работает в production.
Однако нам понадобилась реализация Git, которая могла бы работать на Cloudflare Workers. Она должна была быть небольшой, максимально полной, расширяемой (notes, LFS) и эффективной. Поэтому мы написали её на Zig и скомпилировали в Wasm.
Почему мы использовали Zig? По трем причинам:
-
Весь движок протокола git написан на чистом Zig (без libc), скомпилирован в ~100 КБ бинарный файл WASM (с возможностью оптимизации!). Он реализует SHA-1, zlib inflate/deflate, дельта-кодирование/декодирование, парсинг pack-файлов и полный умный HTTP-протокол git — всё с нуля, без внешних зависимостей, кроме стандартной библиотеки.
-
Zig дает нам ручное управление выделением памяти, что важно в ограниченных средах, таких как Durable Objects. Zig Build System позволяет нам легко делиться кодом между средой выполнения WASM (production) и нативными сборками (тестирование на соответствие libgit2 для проверки корректности).
-
Модуль WASM общается с JS-хостом через тонкий интерфейс обратных вызовов: 11 функций, импортированных хостом, для операций с хранилищем (host_get_object, host_put_object и т.д.) и одна для потоковой передачи вывода (host_emit_bytes). Сторона WASM полностью тестируема изолированно.
Под капотом Artifacts также использует R2 (для снимков состояния) и KV (для отслеживания токенов аутентификации):
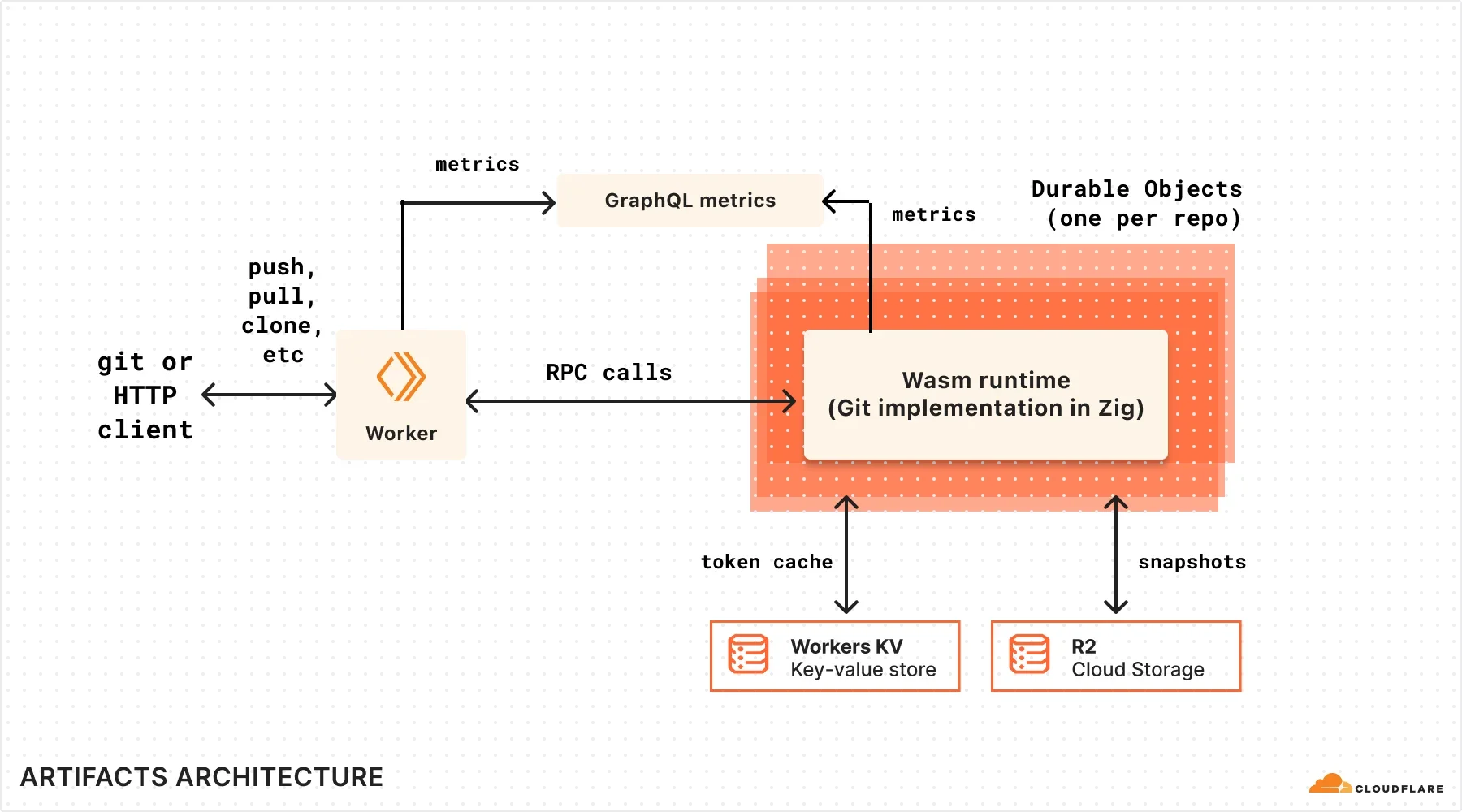
Как работает Artifacts (Workers, Durable Objects и WebAssembly)
Worker выступает в качестве фронтенда, обрабатывая аутентификацию и авторизацию, ключевые метрики (ошибки, задержки) и находя каждый репозиторий Artifacts (Durable Object) на лету.
А именно:
-
Файлы хранятся в базе данных SQLite базового Durable Object.
-
Хранилище Durable Object имеет максимальный размер строки 2 МБ, поэтому крупные Git-объекты разбиваются на части и хранятся в нескольких строках.
-
Мы используем sync KV API (state.storage.kv), который под капотом работает на SQLite.
-
-
Durable Objects имеют ограничение памяти ~128 МБ: это означает, что мы можем запускать десятки миллионов их (они быстрые и легкие), но должны работать в этих пределах.
-
Мы активно используем потоковую передачу как при fetch, так и при push, напрямую возвращая `ReadableStream<Uint8Array>`, построенный из сырых фрагментов вывода WASM.
-
Мы избегаем вычисления собственных git-делта, вместо этого сырые дельты и хэши базового объекта сохраняются вместе с разрешенным объектом. При fetch, если запрашивающий клиент уже имеет базовый объект, Zig выдает дельту вместо полного объекта, что экономит пропускную способность и память.
-
-
Поддержка как v1, так и v2 протокола git.
-
Мы поддерживаем возможности, включая ls-refs, неглубокие клоны (deepen, deepen-since, deepen-relative) и инкрементальное извлечение с переговорами have/want.
-
У нас есть обширный набор тестов с тестами на соответствие для клиентов git и проверочными тестами против сервера libgit2, предназначенными для валидации поддержки протокола.
-
В дополнение к этому у нас есть нативная поддержка git-notes. Artifacts разработан с приоритетом на агентов, а заметки позволяют агентам добавлять заметки (метаданные) к объектам Git. Это включает подсказки, указание авторства агента и другие метаданные, которые можно читать/записывать из репозитория, не изменяя сами объекты.
Большие репозитории, большие проблемы? Знакомьтесь с ArtifactFS.
Большинство репозиториев не такие уж большие, и Git спроектирован быть крайне эффективным с точки зрения хранения: большинство репозиториев клонируются максимум за несколько секунд, и это время в основном определяется настройкой сети, аутентификацией и вычислением контрольных сумм. В большинстве сценариев с агентами или песочницами это приемлемо: просто клонируйте репозиторий при запуске песочницы и приступайте к работе.
Но что насчёт репозитория размером в несколько гигабайт и/или с миллионами объектов? Как мы можем быстро клонировать такой репозиторий, не блокируя способность агента приступить к работе на минуты и не расходуя вычислительные ресурсы?
Популярный веб-фреймворк (размером 2,4 ГБ и с долгой историей!) клонируется почти за 2 минуты. Неглубокий клон быстрее, но недостаточно, чтобы уложиться в единицы секунд, и мы не всегда хотим опускать историю (агентам она полезна).
Можем ли мы сократить время клонирования больших репозиториев до ~10-15 секунд, чтобы наш агент мог приступить к работе? Да, с помощью нескольких трюков.
В рамках запуска Artifacts мы открываем исходный код ArtifactFS — драйвера файловой системы, предназначенного для максимально быстрого монтирования больших Git-репозиториев, подгружая содержимое файлов на лету вместо блокировки на начальном клоне. Он идеально подходит для агентов, песочниц, контейнеров и других случаев, когда критически важен время запуска. Если вы можете сэкономить ~90-100 секунд при запуске песочницы для каждого большого репозитория и запускаете 10 000 таких заданий песочницы в месяц: это экономия 2 778 часов работы песочниц.
Вы можете думать об ArtifactFS как о «Git clone, но асинхронном»:
-
ArtifactFS выполняет клон репозитория git без больших двоичных объектов (blobless clone): он получает дерево файлов и ссылки (refs), но не содержимое файлов. Это можно делать во время запуска песочницы, что позволяет вашей оболочке агента приступить к работе.
-
На фоне он начинает параллельно подгружать (загружать) содержимое файлов через легковесный демон.
-
Он расставляет приоритеты для файлов, с которыми агенты обычно хотят работать в первую очередь: манифесты пакетов (
package.json, go.mod), файлы конфигурации и код, понижая приоритет для двоичных больших объектов (изображения, исполняемые файлы и другие нетекстовые файлы), где это возможно, чтобы агенты могли сканировать дерево файлов по мере их подгрузки. -
Если файл ещё не полностью подгружен, когда агент пытается его прочитать, чтение будет заблокировано до завершения загрузки.
Файловая система не пытается «синхронизировать» файлы обратно с удалённым репозиторием: при тысячах или миллионах объектов это обычно очень медленно, и поскольку мы говорим на языке git, нам это и не нужно. Вашему агенту просто нужно делать коммит и пуш, как и с любым репозиторием. Никаких новых API изучать не придётся.
Важно, что ArtifactFS работает с любым удалённым Git-репозиторием, а не только с нашим Artifacts. Если вы клонируете большие репозитории с GitHub, GitLab или собственной Git-инфраструктуры: вы всё равно можете использовать ArtifactFS.
Что будет дальше?
Наш сегодняшний релиз — это всего лишь бета-версия, и мы уже работаем над рядом функций, которые появятся в ближайшие недели:
-
Расширение доступных метрик, которые мы предоставляем. Сегодня мы выпускаем метрики для количества ключевых операций на пространство имён, репозиторий и хранимых байт на репозиторий, чтобы управление миллионами Artifacts не было обременительным.
-
Поддержка Подписок на События для событий на уровне репозитория, чтобы мы могли отправлять события о пушах, пуллах, клонах и форках любого репозитория в пределах пространства имён. Это также позволит вам потреблять события, писать вебхуки и использовать эти события для уведомления конечных пользователей, управления событиями жизненного цикла в ваших продуктах и/или запуска задач после пуша (например, CI/CD).
-
Нативные клиентские SDK на TypeScript, Go и Python для взаимодействия с API Artifacts.
-
API поиска на уровне репозитория и поиска в пределах всего пространства имён, например, «найти все репозитории с файлом
package.json».
Мы также планируем API для Workers Builds, позволяющий запускать задачи CI/CD в любом рабочем процессе, управляемом агентом.
Сколько это будет стоить?
Мы ещё в начале пути с Artifacts, но хотим, чтобы наше ценообразование работало в масштабе агентов: оно должно быть рентабельным при наличии миллионов репозиториев, неиспользуемые (или редко используемые) репозитории не должны быть обузой, и наше ценообразование должно соответствовать массово-однопользовательской природе агентов.
Вам также не должно приходиться задумываться о том, будет ли репозиторий использоваться или нет, активен он или холоден, и/или разбудит ли его агент. Мы будем взимать плату за потребляемое хранилище и операции (например, клоны, форки, пуши и пулы) с каждого репозитория.
|
$ / единица |
Включено | |
|---|---|---|
|
Операции |
$0,15 за 1 000 операций |
Первые 10 тыс. включены (в месяц) |
|
Хранилище |
$0,50 / ГБ-мес |
Первый 1 ГБ включён. |
Большие, активные репозитории будут стоить дороже, чем маленькие и реже используемые, независимо от того, есть у вас 1 000, 100 000 или 10 миллионов из них.
Мы также планируем добавить Artifacts в бесплатный тариф Workers (с некоторыми разумными ограничениями) по мере развития бета-версии и будем предоставлять обновления на протяжении всей бета-фазы, если это ценообразование изменится, и до начала взимания платы за любое использование.
С чего начать?
Artifacts запускается в закрытой бета-версии, и мы ожидаем, что публичная бета-версия будет готова в начале мая (2026 года, чтобы было понятно!). Мы будем постепенно подключать клиентов в течение следующих недель, и вы можете зарегистрировать свой интерес к закрытой бета-версии напрямую.
А пока вы можете узнать больше об Artifacts:
-
Прочитав руководство по началу работы в документации.
-
Посетив Cloudflare Dashboard (Build > Storage & Databases > Artifacts)
-
Изучив примеры REST API
-
Узнав больше о том, как Artifacts работает изнутри
Следите за логом изменений, чтобы отслеживать прогресс бета-версии.