Когда мы изначально создавали Workflows, наш механизм устойчивого выполнения для многошаговых приложений, он был предназначен для мира, в котором рабочие процессы запускались действиями людей, например, регистрацией пользователя или оформлением заказа. Для сценариев использования, таких как процессы адаптации, рабочим процессам нужно было поддерживать только один экземпляр на человека — а люди могут кликать лишь с определенной скоростью.
Со временем мы увидели количественный сдвиг в рабочей нагрузке и паттерне доступа: меньше рабочих процессов, запускаемых человеком, и больше рабочих процессов, запускаемых агентами, создаваемых на машинной скорости.
Поскольку агенты становятся постоянной и автономной инфраструктурой, работающей от имени пользователей часами или днями, им нужен устойчивый, асинхронный механизм выполнения для выполняемой работы. Workflows предоставляет именно это: каждый шаг можно повторить независимо, рабочий процесс может приостановиться для одобрения человеком (human-in-the-loop), и каждый экземпляр переживает сбои, не теряя прогресс.
Более того, сами рабочие процессы используются для реализации циклов агентов и служат устойчивой обвязкой, которая управляет агентами и поддерживает их работу. Наша интеграция с Agents SDK ускорила это, упростив для агентов создание экземпляров рабочих процессов и получение обратной связи о прогрессе в реальном времени. Теперь одна сессия агента может запускать десятки рабочих процессов, а множество одновременно работающих агентов означает создание тысяч экземпляров за секунды. С появлением Project Think мы ожидаем, что эта скорость будет только расти.
Чтобы помочь разработчикам масштабировать своих агентов и приложения на Workflows, мы рады объявить, что теперь поддерживаем:
-
50 000 одновременных экземпляров (количество параллельно выполняющихся инстанций рабочих процессов), изначально было 4 500
-
300 создаваемых экземпляров в секунду на аккаунт (ранее 100)
-
2 миллиона экземпляров в очереди (то есть экземпляров, которые были созданы или пробуждены и ожидают свободного слота параллельного выполнения) на один рабочий процесс, ранее было 1 миллион
Мы переработали управляющую плоскость Workflows на основе данных об использовании и первых принципов, чтобы поддержать это увеличение. Для V1 управляющей плоскости один Durable Object (DO) мог служить центральным реестром и координатором всего аккаунта. Для V2 мы создали два новых компонента, чтобы помочь горизонтально масштабировать систему и устранить узкие места, присущие V1, перед тем как перенести всех клиентов — вместе с живым трафиком — на новую версию бесшовно.
V1: исходная архитектура Workflows
Как описано в нашем посте в блоге о публичной бета-версии, мы создали Workflows полностью на нашей собственной платформе для разработчиков. По сути, рабочий процесс — это серия устойчивых шагов, каждый из которых можно повторить независимо, которые могут выполнять задачи, ждать внешних событий или спать до заданного времени.
export class MyWorkflow extends WorkflowEntrypoint {
async run(event, step) {
const data = await step.do("fetch-data", async () => {
return fetchFromAPI();
});
const approval = await step.waitForEvent("approval", {
type: "approval",
timeout: "24 hours",
});
await step.do("process-and-save", async () => {
return store(transform(data));
});
}
}
Для запуска каждого экземпляра, выполнения его логики и хранения его метаданных мы используем Durable Objects на основе SQLite — простой, но мощный примитив для координации и хранения в распределенной системе.
В управляющей плоскости некоторые Durable Objects — например, Engine (Движок), который выполняет фактический экземпляр рабочего процесса, включая его шаги, логику повтора и ожидания — создаются в соотношении 1:1 на экземпляр. С другой стороны, Account (Аккаунт) — это Durable Object уровня аккаунта, который управляет всеми рабочими процессами и их экземплярами для этого аккаунта.
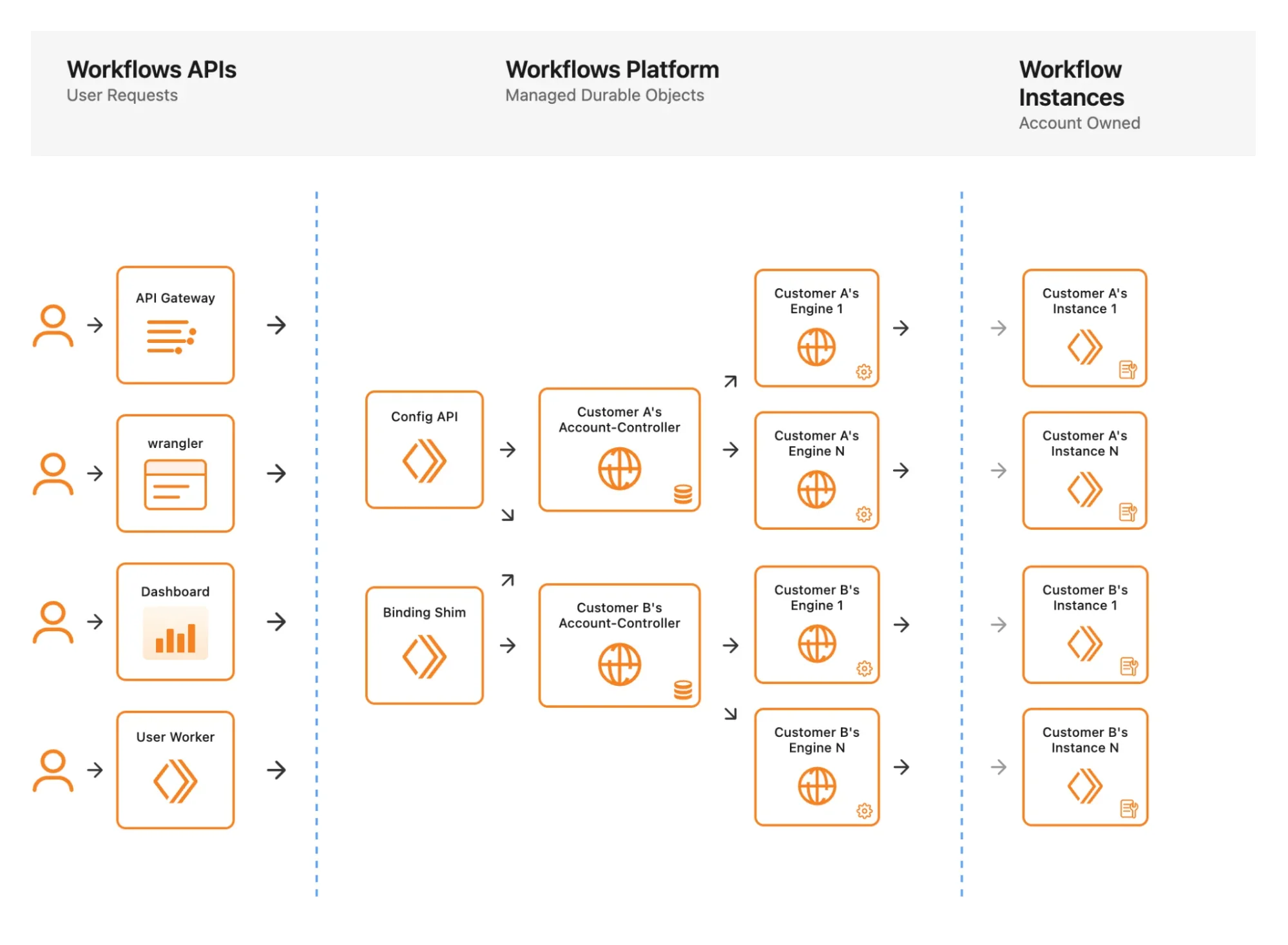
Чтобы узнать больше об управляющей плоскости V1, обратитесь к нашему посту в блоге об анонсе Workflows.
После запуска Workflows в бета-версию мы были в восторге, увидев, как клиенты быстро масштабируют использование продукта, но также поняли, что наличие одного Durable Object для хранения всей информации на уровне аккаунта создает узкое место. Многим клиентам нужно было создавать и выполнять сотни или даже тысячи экземпляров Workflows в минуту, что могло быстро перегрузить Account в нашей исходной архитектуре. Исходные лимиты — 4500 слотов параллельного выполнения и 100 созданий экземпляров за 10 секунд — были следствием этого ограничения.
На управляющей плоскости V1 эти лимиты были жестким ограничением. Любые и все операции, зависящие от Account, включая создание, обновление и вывод списка, должны были проходить через этот единственный DO. У пользователей с высокими нагрузками на параллельное выполнение в любой момент могли запускаться и завершаться тысячи экземпляров, создавая до тысяч запросов в секунду к Account. Чтобы решить эту проблему, мы переработали архитектуру управляющей плоскости рабочих процессов так, чтобы она масштабировалась горизонтально для более высоких лимитов на параллельное выполнение и скорость создания.
V2: горизонтальное масштабирование для большей пропускной способности
Для новой версии мы заново продумали каждую операцию с нуля с целью оптимизации для рабочих процессов с большим объемом. В конечном счете, Workflows должны масштабироваться, чтобы поддерживать все, что нужно разработчикам — будь то тысячи экземпляров, создаваемых в секунду, или миллионы одновременно работающих экземпляров. Мы также хотели убедиться, что V2 позволяет использовать гибкие лимиты, которые мы можем регулировать и продолжать увеличивать, в отличие от жесткого ограничения, которое накладывали лимиты V1. После множества итераций проектирования мы определили следующие основы для нашей новой архитектуры:
-
Источником истины о существовании конкретного экземпляра должен быть его Engine (Движок) и ничего больше.
-
В архитектуре управляющей плоскости V1 у нас не было проверки перед постановкой экземпляра в очередь на предмет того, существует ли его Engine на самом деле. Это позволяло возникновению ошибочного состояния, при котором экземпляр мог быть поставлен в очередь без запуска соответствующего ему Engine.
-
Механизмы жизненного цикла и проверки активности экземпляра должны быть горизонтально масштабируемыми для каждого рабочего процесса и распределены по многим регионам.
-
-
Новый синглтон Account должен хранить только минимально необходимые метаданные и иметь инвариантное максимальное количество одновременных запросов.
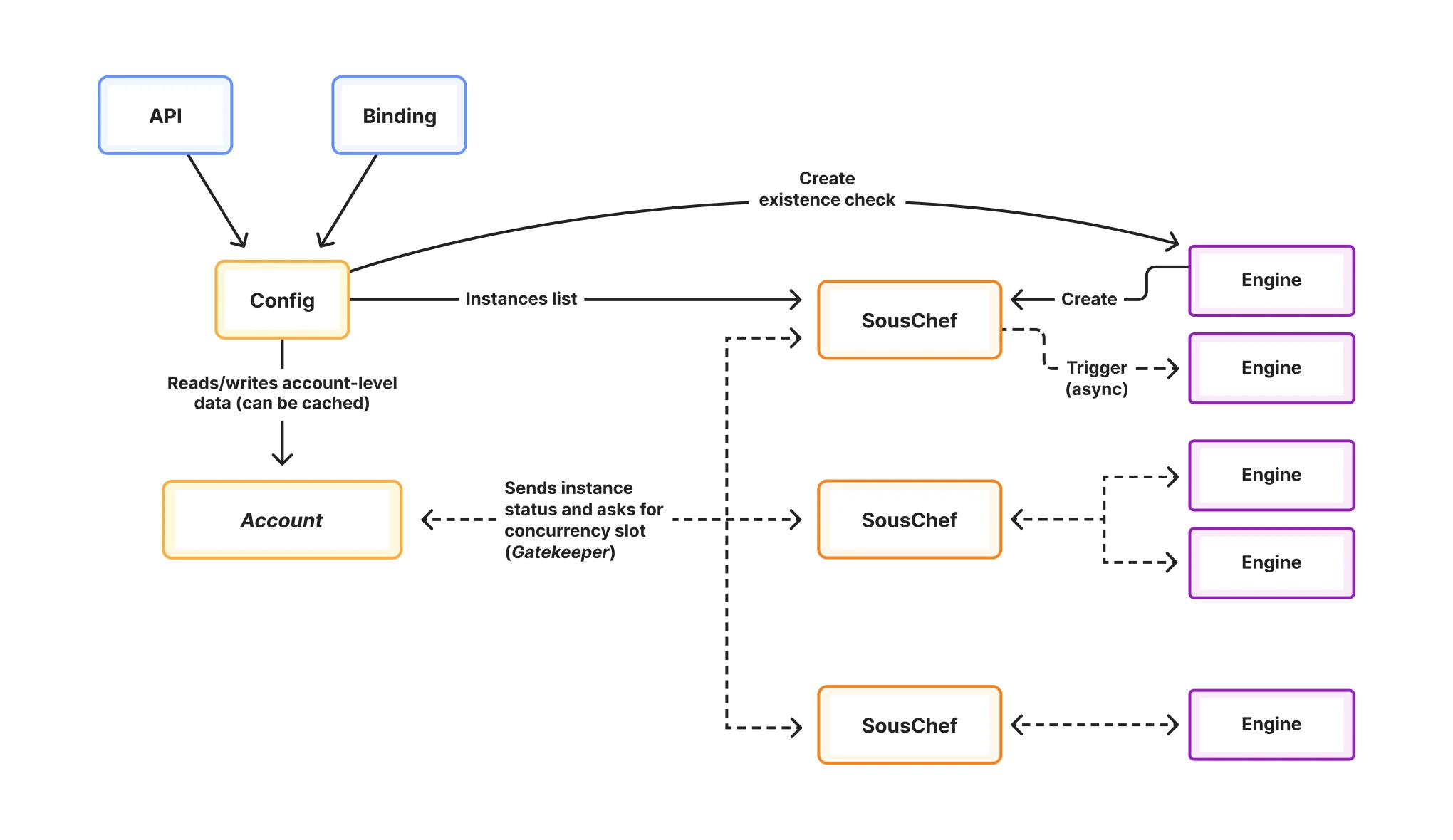
В управляющей плоскости V2 есть два новых, критически важных компонента, которые позволили нам улучшить масштабируемость Workflows: SousChef и Gatekeeper. Первый компонент, SousChef, является «вторым командующим» для Account. Напомним, что ранее Account управлял метаданными и жизненным циклом всех экземпляров во всех рабочих процессах в рамках данного аккаунта. SousChef был введен для отслеживания метаданных и жизненного цикла подмножества экземпляров в заданном рабочем процессе. В рамках аккаунта распределение SousChefs может затем отчитываться перед Account более эффективным и управляемым способом. (Дополнительное преимущество такого дизайна: у нас уже была изоляция на уровне аккаунта, но мы также невольно получили изоляцию «на уровне рабочего процесса» внутри одного аккаунта, поскольку каждый SousChef заботится только об одном конкретном рабочем процессе).
Второй компонент, Gatekeeper (Контролер доступа), — это механизм распределения слотов параллельного выполнения (производных от лимитов параллелизма) между всеми SousChefs в аккаунте. Он действует как система аренды (лизинга). Когда создается экземпляр, он случайным образом назначается одному из SousChefs в этом аккаунте. Затем SousChef отправляет запрос в Account, чтобы запустить этот экземпляр. Либо слот предоставляется, либо экземпляр ставится в очередь. Как только слот предоставлен, SousChef запускает выполнение экземпляра и берет на себя ответственность за то, что экземпляр никогда не зависнет.
Gatekeeper был нужен, чтобы гарантировать, что Engines никогда не перегружают свой Account (острая проблема в V1), поэтому каждое общение между SousChefs и их Account происходит по периодическому циклу, раз в секунду — каждый цикл также будет объединять все запросы на слоты, гарантируя, что выполняется только один JSRPC-вызов. Это гарантирует, что скорость создания экземпляров никогда не может перегрузить или повлиять на самый важный компонент — Account (к слову: если количество SousChefs слишком велико, мы ограничиваем частоту вызовов или распределяем их по разным SousChefs в разные периоды времени). Кроме того, это периодическое свойство позволяет нам сохранять справедливость для более старых экземпляров и обеспечивать max-min справедливость через множество SousChefs, позволяя всем им прогрессировать. Например, если экземпляр просыпается, он должен получить приоритет на слот перед вновь созданным экземпляром, но каждый SousChef следит за тем, чтобы его собственные экземпляры не зависали.
Эта архитектура более распределенная и, следовательно, более масштабируемая. Теперь, когда создается экземпляр, путь запроса выглядит так:
-
Проверить версию управляющей плоскости
-
Проверить, доступна ли кэшированная версия рабочего процесса и деталей его версии в этом месте
-
Если нет, обратиться к Account, чтобы получить название рабочего процесса, уникальный идентификатор и версию, и закэшировать эту информацию
-
Храните только необходимые метаданные (полезную нагрузку экземпляра, дату создания) в собственном Engine
Итак, как же Engine сообщает плоскости управления, что он теперь существует? Это происходит в фоновом режиме после установки метаданных экземпляра. Поскольку фоновые операции на Durable Object могут завершиться неудачей из-за вытеснения или сбоя сервера, мы также устанавливаем «будильник» (alarm) на Engine в горячем пути создания. Таким образом, если фоновая задача не завершится, будильник гарантирует, что экземпляр начнет работу.
Будильник Durable Object позволяет разбудить экземпляр Durable Object в точно указанное время в будущем с моделью выполнения как минимум один раз (at-least-once), имеющей встроенные автоматические повторные попытки. Мы широко используем эту комбинацию фоновых «задач» и будильников, чтобы вынести операции из горячего пути, сохраняя при этом уверенность, что всё произойдет по плану. Вот как мы обеспечиваем высокую скорость критических операций, таких как создание экземпляра, нисколько не жертвуя надежностью.
Помимо достижения масштабируемости, эта версия плоскости управления означает, что:
-
Производительность листинга экземпляров стала выше и действительно согласована с постраничной навигацией (cursor pagination);
-
Любая операция с экземпляром совершает ровно один сетевой переход (так как может идти напрямую к своему Engine, что гарантирует минимально возможную задержку запроса от пользователя);
-
Мы можем обеспечить корректное поведение большего количества экземпляров одновременно (запуская их вовремя) (и исправить ситуацию, если это не так, следя за тем, чтобы Engines никогда не опаздывали с продолжением выполнения).
Миграция с V1 на V2
Теперь, когда у нас была новая версия плоскости управления Workflows, способная обрабатывать большую пользовательскую нагрузку, нам предстояла «скучная» часть: миграция наших клиентов и экземпляров на новую систему. В масштабах Cloudflare это само по себе становится проблемой, поэтому «скучная» часть превращается в самую большую сложность. Еще до своего годового юбилея Workflows уже накопили миллионы экземпляров и тысячи клиентов. Кроме того, некоторые технические долги в плоскости управления V1 означали, что экземпляр в очереди мог еще не иметь своего собственного Durable Object Engine, что еще больше усложняло ситуацию.
Такая миграция сложна, потому что у клиентов в любой момент могут работать экземпляры; нам нужен был способ добавить компоненты SousChef и Gatekeeper в старые учетные записи, не вызывая сбоев или простоев.
В итоге мы решили, что будем переносить существующие Учетные записи (которые мы будем называть AccountOlds), чтобы они вели себя как SousChefs. Сохраняя DO Account, мы сохранили метаданные экземпляров и просто преобразовали DO в «DO» SousChef:
// Вам наверное интересно, что это за класс SousChef? Это класс DO SousChef!
import { SousChef } from "@repo/souschef";
class AccountOld extends DurableObject {
constructor(state: DurableObjectState, env: Env) {
// Мы добавили следующий фрагмент в конец конструктора DO AccountOld.
// Это гарантирует, что при желании мы можем использовать любую примитивную операцию,
// доступную в DO SousChef
if (this.currentVersion === ControlPlaneVersions.SOUS_CHEFS) {
this.sousChef = new SousChef(this.ctx, this.env);
await this.sousChef.setup()
}
}
async updateInstance(params: UpdateInstanceParams) {
if (this.currentVersion === ControlPlaneVersions.SOUS_CHEFS) {
assert(this.sousChef !== undefined, 'SousChef must exist on v2');
return this.sousChef.updateInstance(params);
}
// старая логика остается прежней
}
@RequiresVersion<AccountOld>(ControlPlaneVersions.V1)
async getMetadata() {
// этот метод может быть выполнен, только если
// this.currentVersion === ControlPlaneVersions.V1
}
}Мы можем создать экземпляр класса SousChef внутри AccountOld, потому что SQL-таблицы, отслеживающие метаданные экземпляров, и в DO SousChefs, и в AccountOld одинаковы. Таким образом, мы могли просто решать, какую версию кода использовать. Если бы это было не так, нам пришлось бы переносить метаданные миллионов экземпляров, что сделало бы миграцию более сложной и продолжительной для каждой учетной записи. Итак, как же прошла миграция?
Сначала мы подготовили DO AccountOld к переключению на поведение как у SousChefs (что означало создание релиза с версией приведенного выше фрагмента кода). Затем мы включили плоскость управления V2 для каждой учетной записи, что примерно в одно и то же время запустило следующие три шага:
-
Все новые запросы на создание экземпляра теперь направляются в новые SousChefs (SousChefs создаются при получении первого запроса), новые экземпляры больше никогда не попадают в AccountOld;
-
DO AccountOld начинают самостоятельно мигрировать, чтобы вести себя как SousChefs;
-
Новый DO Account запускается с соответствующими метаданными.
После того как все учетные записи были перенесены на новую версию плоскости управления, мы смогли вывести из эксплуатации DO AccountOld по мере истечения сроков хранения их экземпляров. Как только все экземпляры во всех учетных записях на AccountOlds были перенесены, мы смогли окончательно остановить эти DO. Миграция была завершена без простоев в процессе, который по-настоящему напоминал смену колес автомобиля на ходу.
Попробуйте
Если вы новичок в Workflows, попробуйте наше Руководство по началу работы или создайте своего первого долговечного агента с помощью Workflows.