Данные Cloudflare показывают, что 32% трафика в нашей сети поступает от автоматизированного трафика. Это включает поисковых роботов, проверяющих доступность сайтов, рекламные сети, а в последнее время и ИИ-ассистентов, которые обращаются к сети, чтобы добавить релевантные данные в свои базы знаний при генерации ответов с помощью реактивного расширения генерации (RAG). В отличие от типичного поведения человека, автоматическое поведение ИИ-агентов, краулеров и скрейперов может показаться агрессивным для сервера, отвечающего на запросы.
Например, ИИ-боты часто отправляют большое количество запросов, часто параллельно. Вместо того чтобы фокусироваться на популярных страницах, они могут обращаться к редко посещаемому или слабо связанному контенту по всему сайту, часто осуществляя последовательное, полное сканирование веб-сайтов. Например, ИИ-ассистент, генерирующий ответ, может извлекать изображения, документацию и статьи базы знаний из десятков несвязанных источников.
Хотя Cloudflare уже упрощает контроль и ограничение автоматического доступа к вашему контенту, многие сайты могут хотеть обслуживать ИИ-трафик. Например, разработчик приложений может захотеть гарантировать, что его документация для разработчиков актуальна в базовых ИИ-моделях, интернет-магазин может захотеть, чтобы описания товаров были частью результатов поиска LLM, а издатели могут захотеть получать оплату за свой контент через такие механизмы, как оплата за сканирование.
Поэтому операторы сайтов сталкиваются с дилеммой: настраивать кэш для ИИ-краулеров или для человеческого трафика. Поскольку оба типа демонстрируют сильно различающиеся шаблоны трафика, текущие архитектуры кэша вынуждают операторов выбирать один подход для экономии ресурсов.
В этом посте мы исследуем, как ИИ-трафик влияет на кэш хранения, опишем некоторые проблемы, связанные со смягчением этого воздействия, и предложим направления, которые сообществу стоит рассмотреть для адаптации кэша CDN к эпохе ИИ.
Эта работа является результатом сотрудничества с группой исследователей из ETH Zurich. Полная версия этой работы была опубликована на симпозиуме 2025 года по облачным вычислениям под названием «Переосмысление дизайна веб-кэша для эпохи ИИ» (Zhang и др.).
Кэширование
Давайте начнем с быстрого повторения основ кэширования. Когда пользователь инициирует запрос контента на своем устройстве, он обычно отправляется в ближайший к нему дата-центр Cloudflare. Когда запрос поступает, мы проверяем, есть ли у нас действительная кэшированная копия. Если да, мы можем немедленно предоставить контент, что приводит к быстрому ответу и довольному пользователю. Если контент недоступен для чтения из нашего кэша («промах кэша»), наши дата-центры обращаются к серверу-источнику (origin server), чтобы получить свежую копию, которая затем остается в нашем кэше до истечения срока ее действия или пока другие данные не вытеснят ее.
Сохранение правильных элементов в нашем кэше критически важно для уменьшения количества промахов кэша и обеспечения отличного пользовательского опыта — но то, что «правильно» для человеческого трафика, может сильно отличаться от того, что правильно для ИИ-краулеров!
ИИ-трафик в Cloudflare
Здесь мы сосредоточимся на трафике ИИ-краулеров, который, согласно последним анализам, стал наиболее активным типом ИИ-ботов, составляя 80% трафика самоидентифицируемых ИИ-ботов, который мы наблюдаем. ИИ-краулеры получают контент для поддержки сервисов ИИ в реальном времени, таких как ответы на вопросы или суммирование страниц, а также для сбора данных для создания больших обучающих наборов данных для моделей типа LLM.
Из Cloudflare Radar мы видим, что подавляющее большинство трафика узкоспециализированных ИИ-ботов предназначено для обучения, а поиск занимает отдаленное второе место. (См. этот пост в блоге для глубокого обсуждения трафика ИИ-краулеров, который мы наблюдаем в Cloudflare).
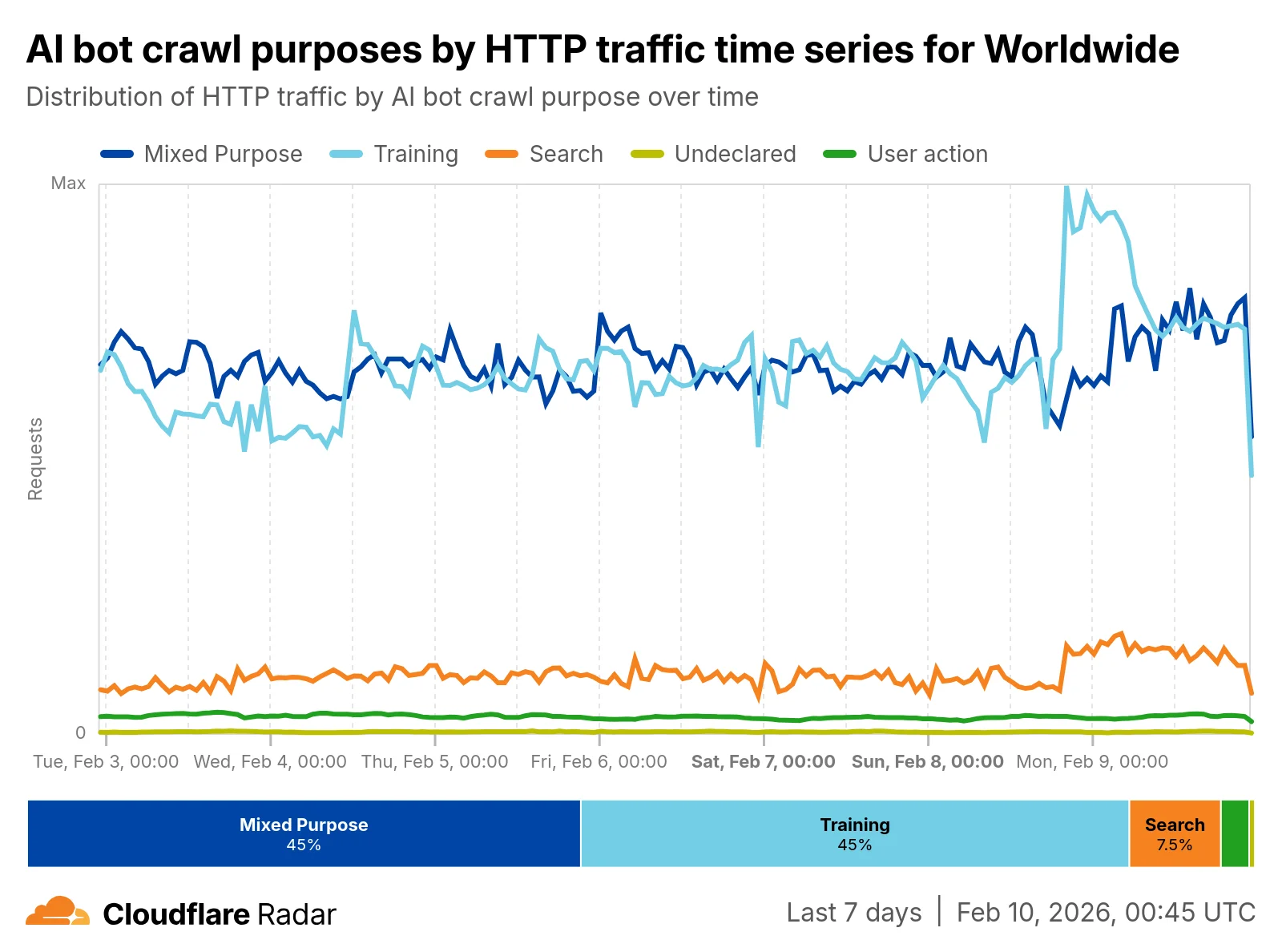
Хотя и поисковые, и обучающие сканирования влияют на кэш через множество последовательных обращений к «длинному хвосту» контента, обучающий трафик обладает такими свойствами, как высокое соотношение уникальных URL, разнообразие контента и неэффективность сканирования, которые делают его еще более влиятельным на кэш.
Чем ИИ-трафик отличается от другого трафика для CDN?
Трафик ИИ-краулеров имеет три основные отличительные характеристики: высокое соотношение уникальных URL, разнообразие контента и неэффективность сканирования.
Публичная статистика сканирований от Common Crawl, которая ежемесячно выполняет крупномасштабное сканирование веба, показывает, что более 90% страниц уникальны по содержанию. Разные ИИ-краулеры также нацелены на различные типы контента: например, некоторые специализируются на технической документации, в то время как другие фокусируются на исходном коде, медиафайлах или блогах. Наконец, ИИ-краулеры не обязательно следуют оптимальным путям сканирования. Значительная часть запросов от популярных ИИ-краулеров приводит к ошибкам 404 или редиректам, часто из-за плохой обработки URL. Частота этих неэффективных запросов варьируется в зависимости от того, насколько хорошо краулер настроен на получение актуального, значимого контента. ИИ-краулеры также обычно не используют кэширование на стороне браузера или управление сессиями так, как это делают пользователи-люди. ИИ-краулеры могут запускать несколько независимых экземпляров, и поскольку они не разделяют сессии, каждый может казаться новым посетителем для CDN, даже если все экземпляры запрашивают один и тот же контент.
Даже один ИИ-краулер, скорее всего, будет углубляться в веб-сайты и исследовать более широкий спектр контента, чем типичный пользователь-человек. Данные использования Википедии показывают, что страницы, когда-то считавшиеся частью «длинного хвоста» или редко запрашиваемые, теперь запрашиваются часто, что смещает распределение популярности контента внутри кэша CDN. Фактически, ИИ-агенты могут итеративно зацикливаться для уточнения результатов поиска, повторно извлекая один и тот же контент. Мы моделируем это, чтобы показать, что такое итеративное зацикливание приводит к низкому повторному использованию контента и широкому охвату.
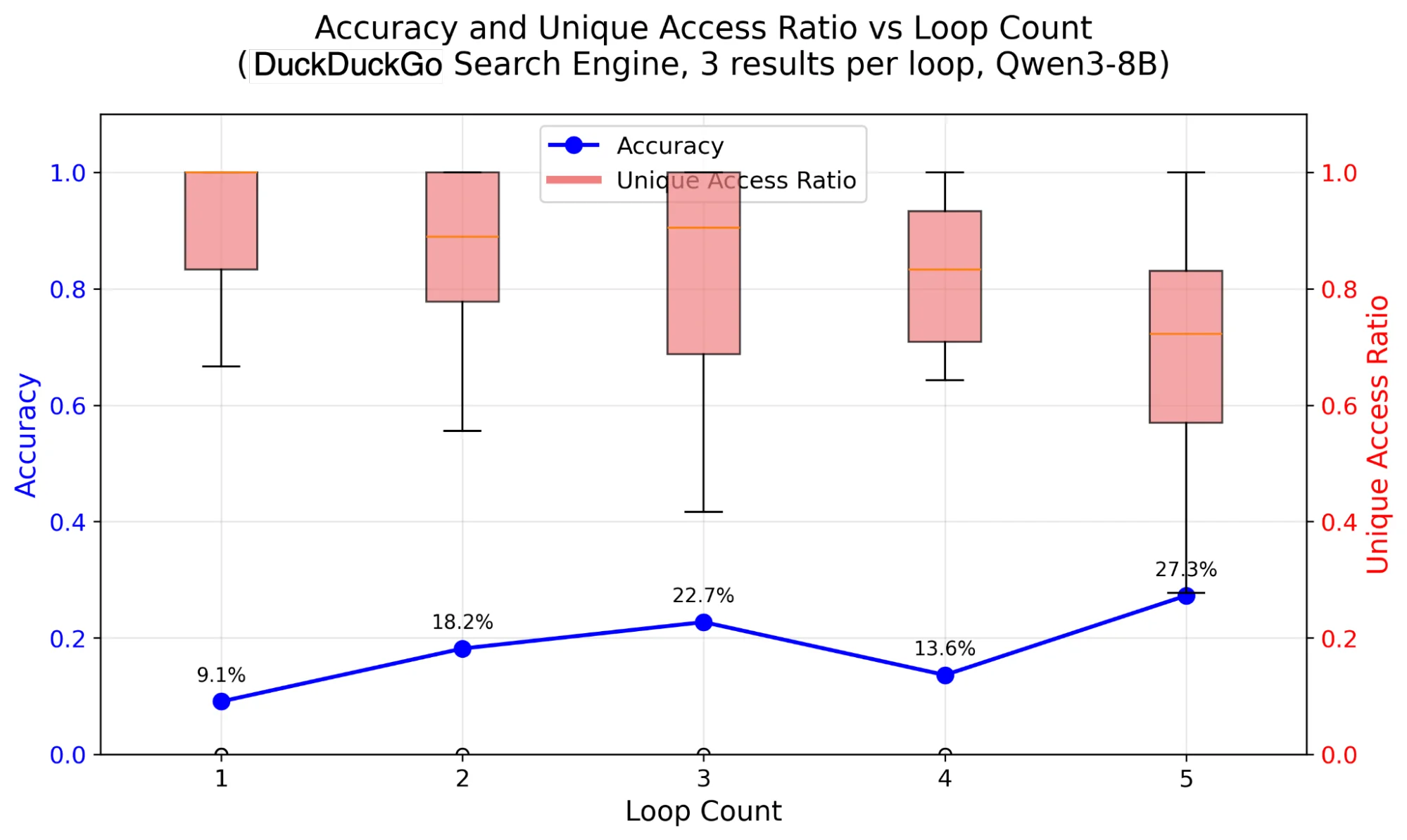
Наше моделирование поведения ИИ-агентов показывает, что по мере итеративного зацикливания для уточнения результатов поиска (распространенный шаблон для реактивного расширения генерации) они сохраняют стабильно высокое соотношение уникальных обращений (красные столбцы выше) — обычно между 70% и 100%. Это означает, что каждый цикл, хотя обычно и повышает точность для агента (представленную здесь синей линией), постоянно извлекает новый, уникальный контент, а не возвращается к ранее просмотренным страницам.
Это повторное обращение к активам из «длинного хвоста» вытесняет из кэша контент, на который полагается человеческий трафик. Это может сделать существующие стратегии предварительной загрузки и традиционной инвалидации кэша менее эффективными по мере роста объема трафика краулеров.
Как ИИ-трафик влияет на кэш?
Для CDN промах кэша означает необходимость обращаться к серверу-источнику для получения запрошенного контента. Представьте промах кэша как ситуацию, когда в вашей местной библиотеке нет книги, и вам приходится ждать, пока ее доставят по межбиблиотечному абонементу. Вы получите свою книгу в конце концов, но это займет больше времени, чем вы хотели. Это также даст вашей библиотеке понять, что наличие этой книги в наличии на месте может быть хорошей идеей.
Из-за своего широкого, непредсказуемого шаблона доступа с повторным обращением к «длинному хвосту» ИИ-краулеры значительно повышают частоту промахов кэша. И многие из наших типичных методов повышения результативности кэша, такие как спекулятивное кэширование (cache speculation) или предварительная загрузка, становятся значительно менее эффективными.
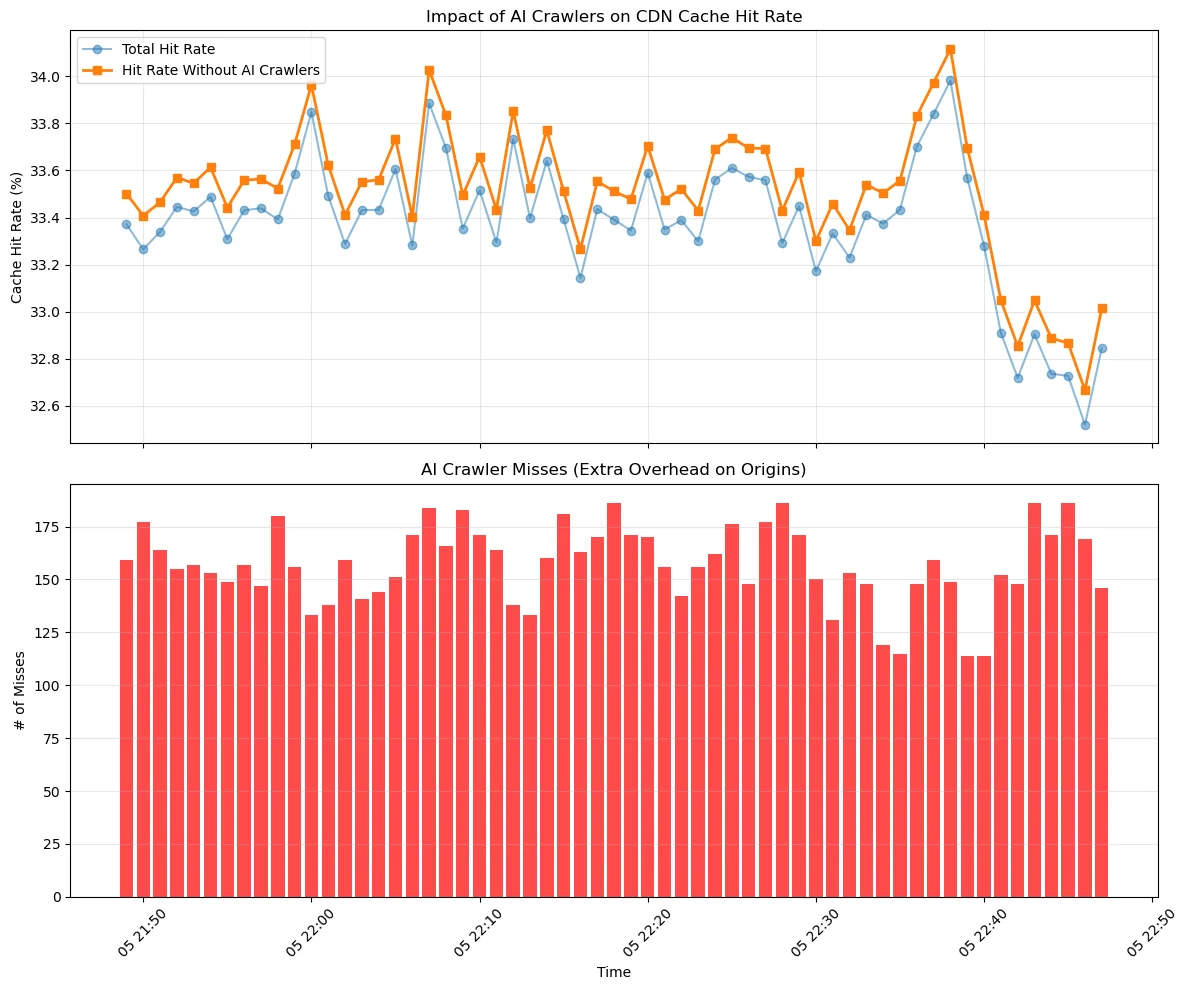
Первая диаграмма ниже показывает разницу в результативности кэша для одного узла в CDN Cloudflare с нашими идентифицированными ИИ-краулерами и без них. Хотя влияние краулеров все еще относительно ограничено, наблюдается явное падение результативности с добавлением трафика ИИ-краулеров. Мы управляем нашим кэшем с помощью алгоритма под названием «вытеснение давно неиспользуемых элементов» (least recently used, LRU). Это означает, что контент, к которому реже всего обращались, может быть удален из кэша первым, чтобы освободить место для более популярного контента, когда место для хранения заполнено. Падение результативности подразумевает, что LRU испытывает трудности при повторяющемся сканирующем поведении ИИ-краулеров.
Нижний рисунок показывает промахи кэша ИИ за это время. Каждый из этих промахов кэша представляет собой запрос к серверу-источнику, замедляя время отклика, а также увеличивая расходы на исходящий трафик и нагрузку на источник.
Этот всплеск трафика ИИ-ботов оказал влияние в реальном мире. Следующая таблица из нашей работы показывает последствия для нескольких крупных веб-сайтов. Каждый пример связан с исходным отчетом.
|
Система |
Сообщаемое поведение ИИ-трафика |
Сообщаемое воздействие |
Сообщаемые меры смягчения |
|
Wikipedia |
Bulk image scraping for model training1 |
50% surge in multimedia bandwidth usage1 |
Blocked crawler traffic1 |
|
SourceHut |
LLM crawlers scraping code repositories2,3 |
Service instability and slowdowns2,3 |
Blocked crawler traffic2,3 |
|
Read the Docs |
AI crawlers download large files hundreds of times daily2,4 |
Significant bandwidth increase2,4 |
Temporarily blocked crawler traffic, performed IP-based rate limiting, reconfigured CDN to improve caching2,4 |
|
Fedora |
AI scrapers recursively crawl package mirrors2,5,6 |
Slow response for human users2,5,6 |
Geo-blocked traffic from known bot sources along with blocking several subnets and even countries2,5,6 |
|
Diaspora |
Aggressive scraping without respecting robots.txt7 |
Slow response and downtime for human users7 |
Blocked crawler traffic and added rate limits7 |
The impact is severe: Wikimedia experienced a 50% surge in multimedia bandwidth usage due to bulk image scraping. Fedora, which hosts large software packages, and the Diaspora social network suffered from heavy load and poor performance for human users. Many others have noted bandwidth increases or slowdowns from AI bots repeatedly downloading large files. While blocking crawler traffic mitigates some of the impact, a smarter cache architecture would let site operators serve AI crawlers while maintaining response times for their human users.
AI-aware caching
AI crawlers power live applications such as retrieval-augmented generation (RAG) or real-time summarization, so latency matters. That’s why these requests should be routed to caches that can balance larger capacity with moderate response times. These caches should still preserve freshness, but can tolerate slightly higher access latency than human-facing caches.
AI crawlers are also used for building training sets and running large-scale content collection jobs. These workloads can tolerate significantly higher latency and are not time-sensitive. As such, their requests can be served from deep cache tiers that take longer to reach (e.g., origin-side SSD caches), or even delayed using queue-based admission or rate-limiters to prevent backend overload. This also opens the opportunity to defer bulk scraping when infrastructure is under load, without affecting interactive human or AI use cases.
Existing projects like Cloudflare’s AI Index and Markdown for Agents allow website operators to present a simplified or reduced version of websites to known AI agents and bots. We're making plans to do much more to mitigate the impact of AI traffic on CDN cache, leading to better cache performance for everyone. With our collaborators at ETH Zurich, we’re experimenting with two complementary approaches: first, traffic filtering with AI-aware caching algorithms; and second, exploring the addition of an entirely new cache layer to siphon AI crawler traffic to a cache that will improve performance for both AI crawlers and human traffic.
There are several different types of cache replacement algorithms, such as LRU (“Least Recently Used”), LFU (“Least Frequently Used”), or FIFO (“First-In, First-Out”), that govern how a storage cache chooses to evict elements from the cache when a new element needs to be added and the cache is full. LRU is often the best balance of simplicity, low-overhead, and effectiveness for generic situations, and is widely used. For mixed human and AI bot traffic, however, our initial experiments indicate that a different choice of cache replacement algorithm, particularly using SEIVE or S3FIFO, could allow human traffic to achieve the same hit rate with or without AI interference. We are also experimenting with developing more directly workload-aware, machine learning-based caching algorithms to customize cache response in real time for a faster and cheaper cache.
Long term, we expect that a separate cache layer for AI traffic will be the best way forward. Imagine a cache architecture that routes human and AI traffic to distinct tiers deployed at different layers of the network. Human traffic would continue to be served from edge caches located at CDN PoPs, which prioritize responsiveness and cache hit rates. For AI traffic, cache handling could vary by task type.
This is just the beginning
The impact of AI bot traffic on cloud infrastructure is only going to grow over the next few years. We need better characterization of the effects on CDNs across the globe, along with bold new cache policies and architectures to address this novel workload and help make a better Internet.
Cloudflare is already solving the problems we’ve laid out here. Cloudflare reduces bandwidth costs for customers who experience high bot traffic with our AI-aware caching, and with our AI Crawl Control and Pay Per Crawl tools, we give customers better control over who programmatically accesses their content.