Годами ответом индустрии на угрозы было «больше видимости». Но большая видимость без контекста — это просто больше шума. Для современной команды безопасности самой большой проблемой стала уже не нехватка данных, а их подавляющий избыток. Большинство специалистов по безопасности начинают свой день, прокладывая путь через море дашбордов, охотясь по разрозненным логам, чтобы ответить на один, обманчиво простой вопрос: «Что делать дальше?»
Когда вы вынуждены переключаться между разными инструментами только для того, чтобы выявить одну-единственную неверную конфигурацию, вы упускаете окно возможности предотвратить инцидент. Именно поэтому мы создали обновленный дашборд «Обзор безопасности»: единый интерфейс, призванный усилить защитников, обеспечив переход от реактивного мониторинга к проактивному контролю.
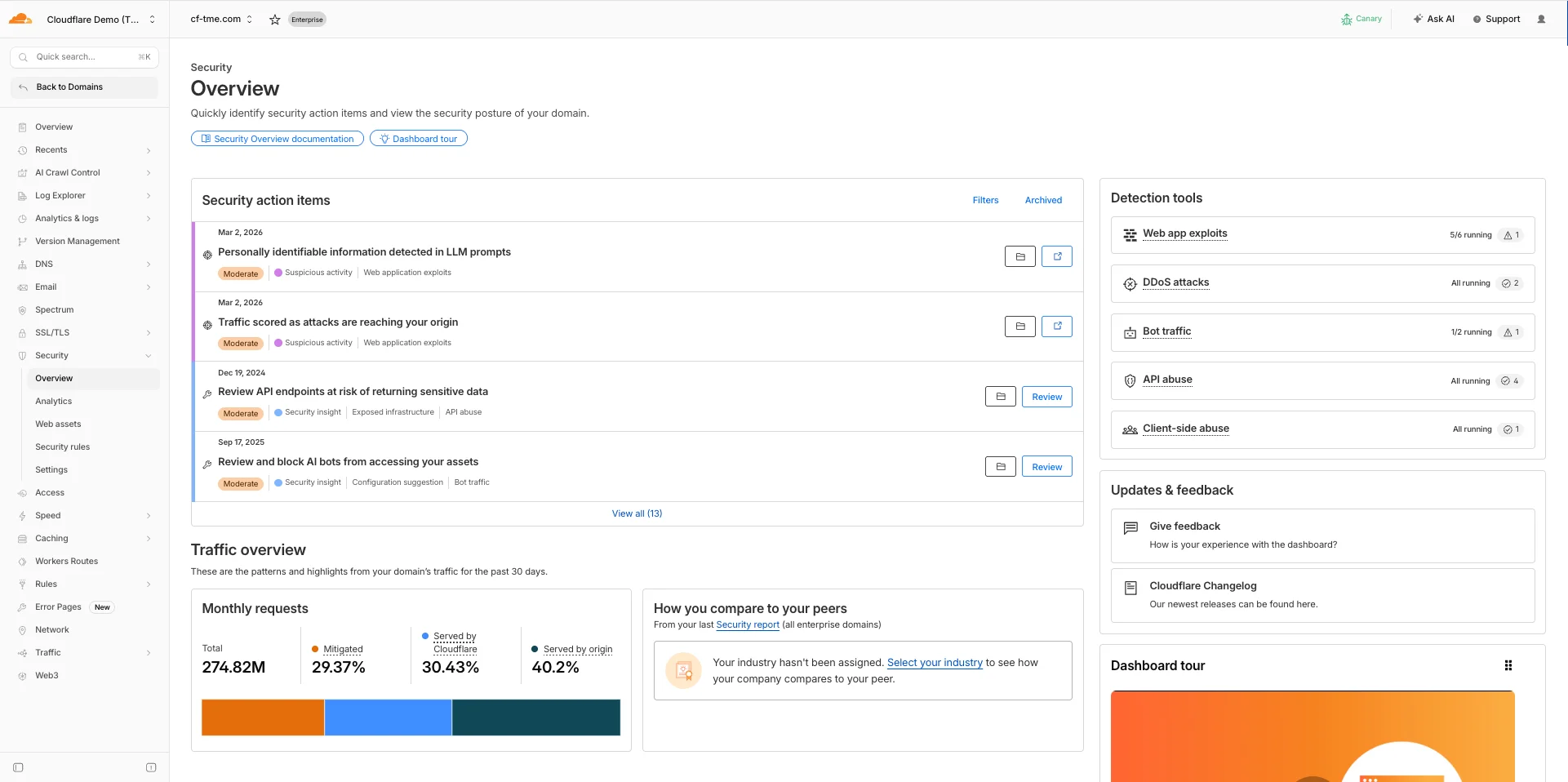
Новый дашборд «Обзор безопасности».
От шума к действию: переосмысление обзора безопасности
Исторически дашборды были сосредоточены на том, чтобы показать вам всё, что происходит. Но для занятого аналитика безопасности более важным вопросом является: «Что мне нужно исправить прямо сейчас?»
Чтобы решить эту задачу, мы представляем «Пункты действий по безопасности». Эта функция выступает в качестве функционального моста между обнаружением и расследованием, выявляя уязвимости, так что вам больше не придется их искать. Чтобы помочь эффективно проводить приоритизацию, пункты ранжируются по критичности:
-
Критический: Неотложные риски, требующие немедленного внимания для предотвращения эксплуатации.
-
Средний: Проблемы, которые следует устранить для поддержания надежной безопасности.
-
Низкий: Оптимизации и предложения по усилению защиты в рамках лучших практик.
Фильтруя по типу инсайта (например, «Подозрительная активность» или «Небезопасная конфигурация»), вы можете адаптировать свой рабочий процесс к конкретным угрозам, с которыми ваша организация сталкивается чаще всего.
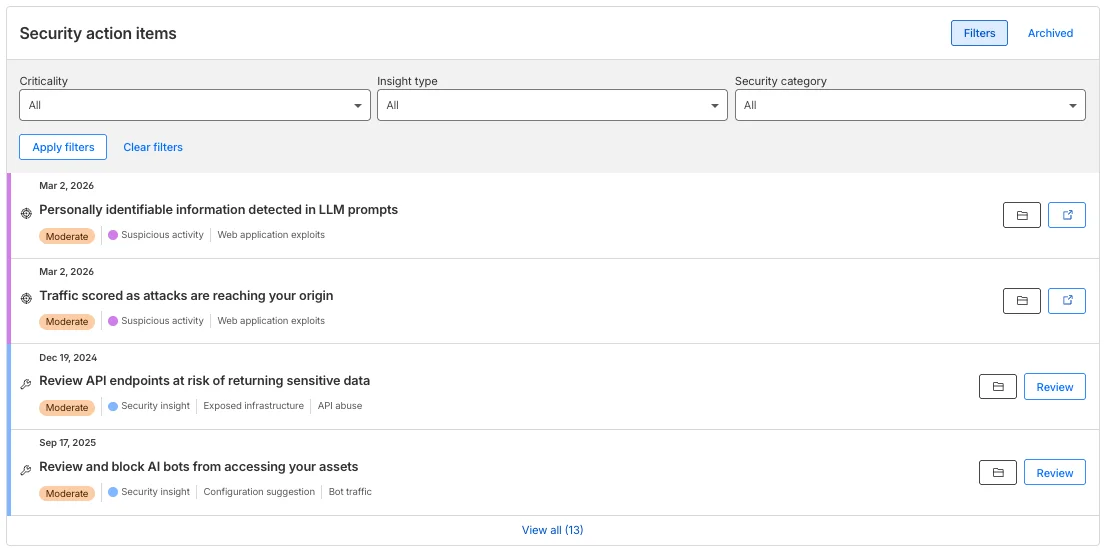
Одной из самых распространенных причин утечки данных является не отсутствие инструмента безопасности, а тот факт, что инструмент никогда не был включен или был настроен неправильно. Мы называем это пробелом в конфигурации.
Новый модуль «Инструменты обнаружения» устраняет эту слепую зону. Вместо того чтобы копаться во вложенных страницах настроек, чтобы увидеть, анализируется ли ваш трафик на самом деле, мы предоставляем общий статус всего вашего стека безопасности Cloudflare в одном представлении:
-
Активны ли ваши основные щиты, или вы находитесь в режиме «Только логирование» в период повышенной волатильности?
-
Обнаруживаете ли вы теневые API или действуете вслепую?
Показывая эти инструменты напрямую вместе с вашими «Пунктами действий по безопасности», мы переводим разговор из плоскости «Есть ли у нас этот инструмент?» в плоскость «Защищает ли этот инструмент нас прямо сейчас?»
Общая сводка хороша настолько, насколько хороши данные, лежащие в ее основе. Чтобы сделать переход от красного флажка к решению беспрепятственным, мы объединили видимость наших карточек «Подозрительная активность». Теперь эти карточки находятся в двух стратегически важных местах: «Обзор безопасности» и страница «Аналитика безопасности».
Если вы заметили на странице обзора карточку «Подозрительная активность», которая вызвала у вас интерес, нет необходимости вручную переходить в «Аналитику» и заново настраивать фильтры. Нажав на карточку, вы получаете прямую глубокую ссылку в дашборд «Аналитика безопасности» со всеми соответствующими фильтрами, уже примененными автоматически. Это устраняет «налог на переключение вкладок», который замедляет реагирование на инциденты, сохраняя ваш рабочий процесс плавным, а время реакции — быстрым.
Как мы создали наш новый дашборд обзора безопасности
Для поддержания проактивной защиты наш механизм ежедневно создает и обновляет более 10 миллионов действенных инсайтов, чтобы обеспечить постоянную актуальность защиты.
Работа на этом уровне представляет две различные инженерные проблемы. Первая — масштаб: бесшовная обработка огромных объемов данных. Вторая и, возможно, более сложная проблема — широта охвата. Истинная безопасность горизонтальна и охватывает весь ваш стек. Чтобы генерировать действенные инсайты, дающие вам всесторонний обзор рисков и уязвимостей, наш механизм должен проверять всё — от простых SSL-сертификатов до сложных конфигураций AI-ботов.
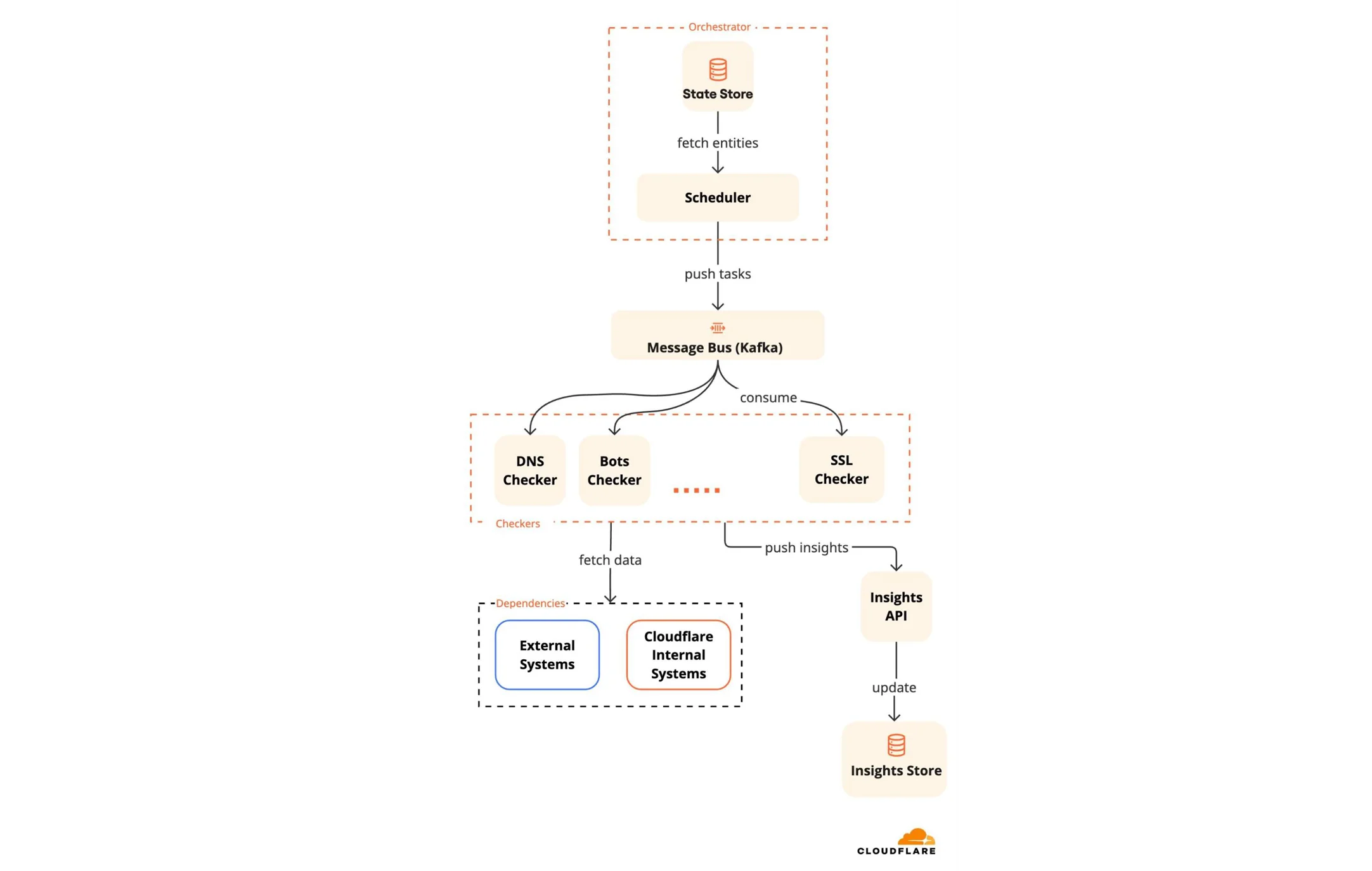
Для решения этой задачи мы создали систему, состоящую из более мелких специализированных микросервисов, которые мы называем «чекеры» (checkers). Каждый чекер является экспертом в предметной области для конкретной части вашего стека, например, DNS-записей. Распределенная архитектура наших чекеров позволяет им масштабироваться независимо, интегрируясь в систему двумя способами: посредством плановых проверок конфигурации или обработчиков событий реального времени, которые помечают риск в момент возникновения события.
1. Плановые проверки: Мы используем этот режим для рисков, требующих глубокой проверки. Они инициируются оркестратором (планировщиком), который периодически отправляет задачи на выполнение чекерам. Мы распределяем рабочую нагрузку чекеров в массово-параллельной системе. Например, задача, отправленная DNS-чекеру, может звучать так: «Просканируй все конфигурации, связанные с DNS, для зоны xyz.com, и найди аномалии».
Чекеры независимо забирают эти задачи. Они используют свою специализированную логику для сканирования активов и конфигураций. В случае DNS-чекера он использует специализированные интеллектуальные правила для сканирования всех DNS-активов и конфигураций зоны, будь то записи A/AAAA/CNAME или записи DMARC/SPF.
Вот как выглядит жизненный цикл инсайта:
-
Чекер активируется при получении сообщения.
-
Чекер собирает соответствующие активы (например, DNS-записи) о зоне или аккаунте.
-
Чекер запускает несколько проверок, чтобы убедиться в статусе актива, например, указывает ли запись CNAME на сервер.
-
Если состояние или конфигурация не соответствуют требуемому порогу, инсайт помечается.
-
Во время следующей проверки, если инсайт сохраняется, временная метка обновляется.
-
Если инсайт был устранен к следующей проверке, он будет удален из базы данных.
2. Обработчики событий: Чекеры работают по расписанию круглосуточно, тогда как обработчики событий функционируют в реальном времени. Они отслеживают сигналы и события от нашей панели управления.
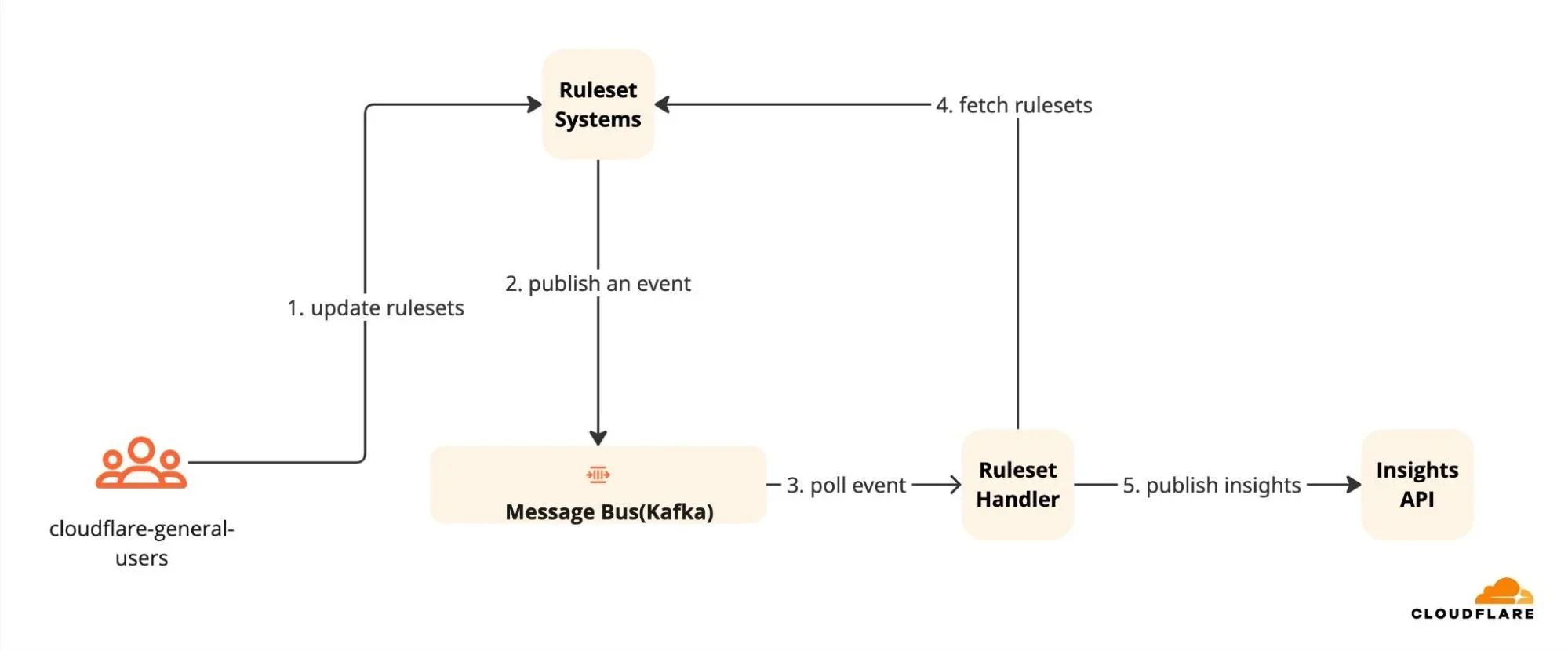
Вот как выглядит жизненный цикл инсайта для набора правил в реальном времени:
-
Конфигурация правила WAF изменяется.
-
Мгновенно генерируется событие с деталями изменения.
-
Обработчик набора правил, который активно отслеживает события, приступает к работе.
-
Обработчик обнаруживает аномалию, например, вы включили управляемый Cloudflare набор правил, но оставили его в режиме «Только логирование».
-
Обработчик делает вывод, что атаки записываются, но не блокируются.
-
Обработчик регистрирует инсайт и делает его доступным на дашборде.
-
Если конфигурация была обновлена до безопасной настройки, обработчик очищает инсайт.
Работа обработчиков наборов правил в реальном времени позволяет нам мгновенно помечать неверную конфигурацию или подтверждать исправление.
Объединение видимости безопасности с контекстными инсайтами
Наши клиенты постоянно просили не просто видимости: они просили контекст. Хотя уведомление о неверной конфигурации записи полезно, это только половина дела. Чтобы предпринять немедленные и уверенные действия, защитникам необходимо знать «и что с того?», включая влияние на бизнес и техническую первопричину. Чтобы решить эту задачу, мы разработали «Контекстные инсайты» для нашего механизма обнаружения. Показывая такие данные, как объем трафика к сломанной A-записи, мы гарантируем, что каждый инсайт является приглашением к действию.
Мы начинаем этот путь «Контекстных инсайтов» с расширения глубины наших DNS-инсайтов. Вместо того чтобы просто помечать сломанную запись, мы сопоставляем сигнал «висячей» записи с дополнительным контекстом и данными о трафике в реальном времени, чтобы предоставить «почему» и «как»:
-
Контекст цели: Мы точно определяем, на какой удаленный ресурс (например, старый бакет S3 или облачный экземпляр) указывает запись.
-
Контекст влияния: Мы показываем вам, сколько именно пользователей всё еще пытаются получить доступ к этой сломанной записи.
Давайте рассмотрим в качестве примера инсайты о «Висячих A/AAAA/CNAME записях».
Чтобы предоставить эти инсайты, мы должны анализировать огромный объем данных, проходящих через нашу сеть каждую секунду. Чтобы вы представляли масштаб работы, происходящей за кулисами:
Наш механизм еженедельно сканирует 100+ миллионов DNS-записей. На прошлой неделе наш механизм выявил более 1 миллиона висячих DNS-записей. Большинство (97%) — это висячие A/AAAA записи, а оставшиеся 3% — висячие CNAME записи.
Из 31 000 висячих CNAME записей:
-
95% указывают на сервисы Microsoft Azure.
-
3% указывают на AWS Elastic Beanstalk.
Это говорит о том, что это цели высокого приоритета для захвата поддомена. Злоумышленник может заявить права на эти заброшенные облачные ресурсы и немедленно получить контроль над вашим поддоменом, что позволит ему проводить фишинговые атаки или распространять дезинформацию под вашим доверенным брендом. При наличии тысяч обращений висячая запись представляет собой риск захвата поддомена высокого приоритета, требующий немедленного устранения для мгновенной оценки и снижения угрозы.
Наш DNS-чекер использует двухэтапный процесс для генерации этих инсайтов
-
Шаг 1: Активное обнаружение инсайтов
-
Проверка начинается, как только механизм получает сообщение о запуске сканирования. Этот процесс был описан в предыдущем разделе.
-
-
Шаг 2: Контекстное обогащение
-
Как только инсайт сгенерирован, механизмы проверки собирают соответствующие контекстные данные для этого инсайта, которые помогают клиенту понять влияние проблемы безопасности.
-
Давайте подробно рассмотрим, как генерируются инсайты о висячих DNS-записях, сосредоточившись на двухэтапном процессе.
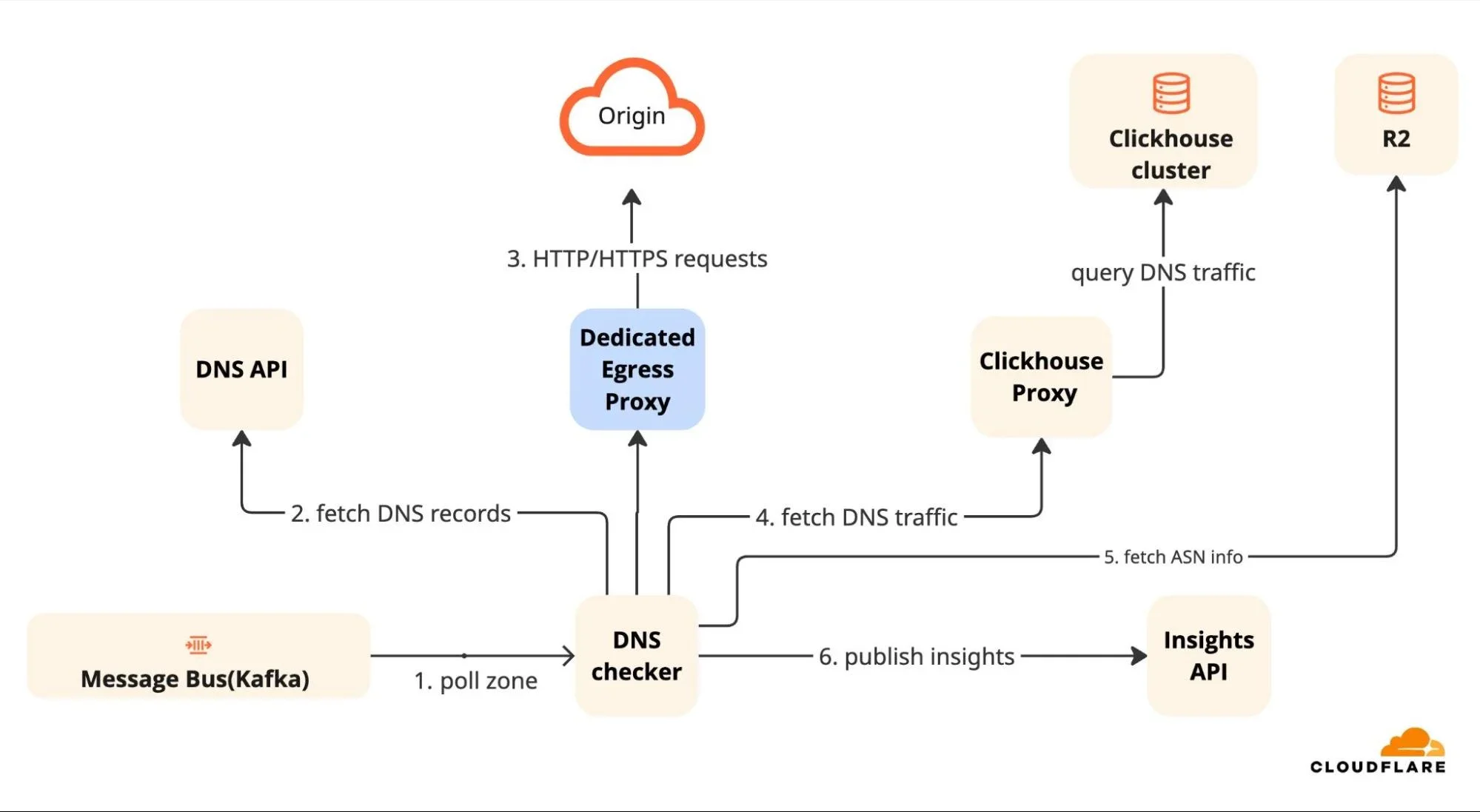
Фаза 1: Активная проверка
DNS-запись, указывающая на IP-адрес, часто выглядит абсолютно корректной на бумаге, даже если сервер за ней был выведен из эксплуатации месяцы назад. Чтобы подтвердить, является ли риск реальным, наш механизм должен выйти за пределы сети и проверить место назначения в реальном времени. Выполняемые проверки можно классифицировать следующим образом:
Проверка неработающего сервера (записи A/AAAA): Для записей, указывающих напрямую на IP-адреса, мы проверяем, активно ли место назначения. Наш механизм запускает специальный исходящий прокси, чтобы попытаться установить соединение с источником по HTTP и HTTPS. Используя этот специальный шлюз, мы имитируем, как реальный пользователь подключился бы извне сети Cloudflare. Если соединение превысит время ожидания или сервер вернет ошибку "404 Not Found", мы подтверждаем, что ресурс не работает. Это доказывает, что DNS-запись является "висячей" — живым указателем, ведущим на пустое место.
Проверка на возможность захвата (записи CNAME): Псевдонимы доменов (CNAME) часто делегируют трафик сторонним сервисам, таким как служба поддержки или хранилище. Если вы отмените этот сервис, но забудете удалить DNS-запись, вы создаете "висячую" ссылку, которую злоумышленники могут заявить своей.
Чтобы найти такие случаи, наш механизм выполняет 3-этапный процесс:
-
Сначала мы отслеживаем цепочку, рекурсивно разрешая CNAME-запись, чтобы найти ее конечный пункт назначения (например,
my-bucket.s3.amazonaws.com). -
Затем мы идентифицируем провайдера, проверяя, принадлежит ли этот пункт назначения известному облачному сервису, такому как AWS, Azure или Shopify.
-
Наконец, мы подтверждаем, что место свободно. Каждый облачный провайдер возвращает определенные шаблоны ошибок, когда ресурс не существует (например, "NoSuchBucket" в S3). Мы проверяем целевой URL и сопоставляем его с этими шаблонами, чтобы подтвердить, доступен ли ресурс для захвата.
Если наш механизм обнаруживает, что ресурс был освобожден, но DNS-запись осталась, мы создаем инсайт, побуждая вас удалить запись до того, как злоумышленник сможет захватить ваш поддомен.
Фаза 2: Контекстное обогащение
Как только запись подтверждена как нерабочая, мы добавляем к инсайту необходимый контекст, который поможет вам принять более обоснованное решение. Механизм проверки подключается к разным системам, чтобы собрать требуемый контекст. Для инсайтов о висячих записях мы фокусируемся на трех критически важных аспектах:
-
Объем трафика (Влияние) Наши глобальные кластеры ClickHouse — это кладезь информации. Чтобы понять, используется ли запись на самом деле, механизм проверки запрашивает наши глобальные кластеры ClickHouse, чтобы суммировать общее количество DNS-запросов к этой записи за последние 7 дней. Этот ценный контекст позволяет вам расставить приоритеты в устранении проблемы. Запись с 0 запросов можно исправить, когда у вас будет время; запись с 10 000 запросов — это активная уязвимость, которую необходимо устранить немедленно.
Запрос к ClickHouse выглядит так:
SELECT query_name,
sum(_sample_interval) as total
FROM <dnslogs_table_name>
WHERE account_id = {{account_id}}
AND zone_id = {{zone_id}}
AND timestamp >= subtractDays(today(), 7)
AND timestamp < today()
AND query_name in ('{{record1}}', '{{record2}}', ...)
GROUP BY query_nameЗапрос спрашивает: "Сколько раз за последние семь дней на эту конкретную неработающую запись запрашивали реальные пользователи?"
-
Владелец инфраструктуры (Цель) Знание того, кто владеет целевой инфраструктурой, жизненно важно как для устранения проблемы, так и для оценки ее серьезности.
Для IP-записей (A/AAAA): Мы определяем владельца сети (ASN) с помощью актуальных геолокационных данных из бакета R2 Cloudflare и выполняем высокоскоростные поиски в памяти. Это точно указывает вам, где находился неработающий ресурс (например, "Google Cloud" или "DigitalOcean"), ускоряя ваше расследование.
Для CNAME-записей: Мы определяем конкретного Хостинг-провайдера (например, AWS S3, Shopify). Это определяет уровень риска. Если запись указывает на провайдера, известного простыми случаями захвата (как S3), мы помечаем ее как Критическую; в противном случае — как Умеренную.
-
DNS TTL Мы также извлекаем значение TTL (Время жизни) непосредственно из конфигурации записи.
Это говорит вам о "времени запаздывания" вашего исправления. Если вы удалите висячую запись с высоким TTL (например, 24 часа), она будет оставаться в кеше резолверов по всему миру целый день, что означает, что уязвимость остается открытой даже после того, как вы ее исправили. Знание этого помогает управлять ожиданиями во время реагирования на инцидент.
Взгляд в будущее
Хотя сегодня этот функционал запускается на уровне домена, мы знаем, что для корпоративных клиентов безопасность не управляется по одному домену за раз. Наша дорожная карта сфокусирована на том, чтобы в следующую очередь перенести эти возможности на уровень аккаунта. Вскоре команды безопасности смогут использовать централизованное представление, которое агрегирует задачи по безопасности и расставляет приоритеты для устранения наиболее критических рисков во всех доменах Cloudflare.
Безопасность не должна ощущаться как игра в догонялки. Слишком долго сложность управления безопасностью приложений давала преимущество злоумышленнику. Благодаря нашей архитектуре специализированных механизмов проверки и обработчиков событий в реальном времени мы обнаруживаем потенциальные риски и обогащаем их критически важным контекстом, обеспечивая защитникам возможность реагировать быстро и точно.