Безопасность электронной почты всегда определялась непостоянством. Это бесконечная гонка вооружений по принципу «вызов-ответ», где защита сильна лишь до последнего обнаруженного обхода, а злоумышленники неумолимо совершенствуются ради даже малейшего преимущества. Каждая внедренная мера защиты в итоге становится вчерашним решением.
Особую сложность этой задаче придает то, что наши самые большие слабости, по определению, невидимы.
Эта проблема прекрасно иллюстрируется классическим примером времен Второй мировой войны. Математик Абрахам Вальд получил задачу помочь инженерам союзников решить, какие части бомбардировщиков следует усилить. Изначально инженеры фокусировались на пробоинах, видимых на самолетах, вернувшихся с заданий. Вальд указал на ошибку: они укрепляли те области, которые уже могли получить повреждения, но самолет при этом выживал. Истинные уязвимости были на тех самолетах, что не вернулись назад.
Безопасность электронной почты сталкивается с точно таким же препятствием: наши пробелы в обнаружении невидимы. Интегрируя LLM (большие языковые модели), мы продвигаем защиту от фишинга по email и переходим от реактивного к проактивному улучшению обнаружения.
Пределы реактивной защиты
Традиционные системы безопасности электронной почты совершенствуются в основном за счет пропущенных угроз, о которых сообщают пользователи. Например, если мы пометили спам-сообщение как чистое, клиенты могут отправить нам исходный файл EML в наши аналитические конвейеры, чтобы наши аналитики изучили его и обновили модели. Эта обратная связь необходима и ценна, но она по своей природе реактивна. Она зависит от того, что кто-то заметил сбой постфактум и нашел время о нем сообщить.
Это означает, что улучшения в обнаружении часто определяются тем, в чем злоумышленники уже преуспели, а не тем, что они собираются использовать в следующий раз.
Чтобы закрыть этот пробел, нам нужен способ систематически наблюдать за «самолетами, которые не вернулись».
Картирование ландшафта угроз с помощью LLM
Большие языковые модели (LLM) вышли на массовый рынок в конце 2022 — начале 2023 года, коренным образом изменив способ обработки неструктурированных данных. В своей основе LLM используют глубокое обучение и огромные наборы данных для предсказания следующего токена в последовательности, что позволяет им понимать контекст и нюансы. Они особенно хорошо подходят для безопасности электронной почты, потому что могут читать естественный язык и характеризовать сложные концепции (такие как намерение, срочность и обман) в миллионах сообщений.
Каждый день Cloudflare обрабатывает миллионы нежелательных писем. Исторически не было возможности глубоко охарактеризовать каждое сообщение за пределами грубой классификации. Ручное сопоставление писем с тонкими векторами угроз просто не масштабировалось.
Теперь Cloudflare интегрировал LLM в наши инструменты безопасности электронной почты для выявления угроз до того, как они нанесут удар. Используя возможности LLM, как мы опишем ниже, мы наконец можем видеть четкую и всеобъемлющую картину развивающегося ландшафта угроз.
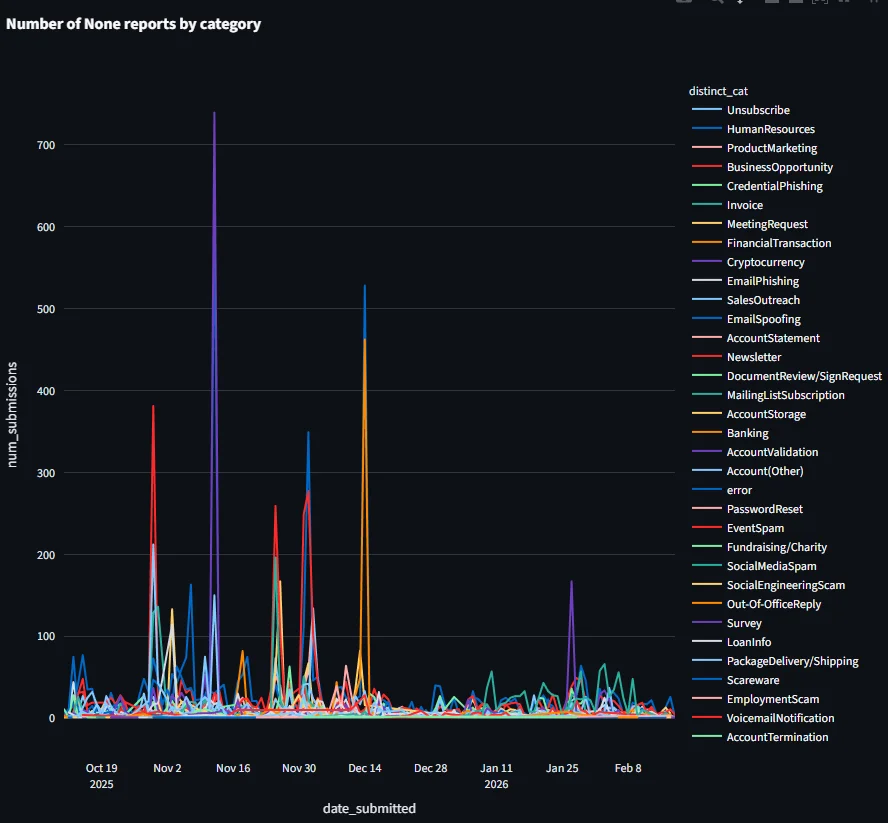
Наша категоризация на основе LLM показывает четкие всплески и устойчивые тенденции по нескольким различным категориям, включая "PrizeNotification" и "SalesOutreach".
Эти сгенерированные LLM теги предоставляют аналитикам Cloudflare высокоточные сигналы почти в реальном времени. Задачи, которые ранее требовали часов ручного расследования и сложных запросов, теперь могут выявляться автоматически, с прикрепленным соответствующим контекстом. Это напрямую увеличивает скорость, с которой мы можем создавать новые целевые модели машинного обучения или дообучать существующие для противодействия новым типам поведения.
Поскольку Cloudflare работает в масштабах глобального интернета, мы можем собирать эти данные раньше, чем когда-либо прежде, часто до того, как новая техника станет широко заметна через пропуски, о которых сообщили клиенты.
Угроза "Sales Outreach" (Коммерческое предложение)
Одной из самых четких выявленных с помощью этой новой разведданных тенденций является сохраняющаяся активность вредоносных сообщений, стилизованных под фишинг в формате "Sales Outreach" (коммерческое предложение). Эти письма созданы для имитации легитимной B2B-коммуникации, часто предлагая возможности купить или получить «специальные предложения» на уникальные товары или услуги, чтобы заманить жертву на переход по вредоносным ссылкам или предоставление учетных данных.
Как только категоризация с помощью LLM выделила "Sales Outreach" как доминирующий вектор, мы перешли от общего обзора к целенаправленному сбору данных.
Используя теги, сгенерированные LLM, мы начали систематически изолировать сообщения, демонстрирующие характеристики "Sales Outreach", в нашем глобальном наборе данных. Это создало непрерывно растущий, высокоточный корпус реальных примеров, включая подтвержденно вредоносные сообщения, а также пограничные случаи, с которыми традиционные системы с трудом справлялись. На основе этого корпуса мы построили специальный конвейер обучения.
Во-первых, мы подготовили данные для обучения, сгруппировав сообщения на основе общих лингвистических и структурных черт, идентифицированных LLM. Эти черты включали убедительную подачу, искусственно созданное ощущение срочности, транзакционный язык и тонкие формы социального доказательства.
Затем мы сосредоточили извлечение признаков на настроении и намерении, а не на статических индикаторах. Модель учится тому, как формулируются запросы, как устанавливается доверие и как призывы к действию встраиваются в в остальном обычные деловые беседы.
Наконец, мы обучили специализированную модель анализа тональности, оптимизированную именно для поведения типа "Sales Outreach". Это позволило избежать перегрузки общего классификатора фишинга и дало возможность точно настраивать точность и полноту для этого класса угроз.
Превращение языка в механизм защиты
Результатом работы этой модели является показатель риска, отражающий, насколько близко сообщение соответствует известным шаблонам атак "Sales Outreach". Этот показатель оценивается вместе с существующими сигналами, такими как репутация отправителя, поведение ссылок и исторический контекст, чтобы определить, следует ли заблокировать сообщение, поместить его в карантин или разрешить.
Этот процесс непрерывен. По мере того как злоумышленники адаптируют свой язык, вновь наблюдаемые сообщения возвращаются в конвейер и используются для уточнения модели, не дожидаясь большого объема пропусков, о которых сообщили пользователи. LLM выступают в качестве слоя обнаружения, выявляя новые языковые варианты, в то время как специализированная модель выполняет быстрое и масштабируемое применение правил.
Вот как выглядит полномасштабное наступление на практике. Это цикл обратной связи, в котором масштабное понимание языка движет целенаправленным, высокоточным обнаружением. Результат — более раннее вмешательство против класса угроз, который процветает за счет тонкости, и меньше вредоносных коммерческих писем, попадающих во входящие.
Результаты проделанной работы
Видимость, открытая картированием на основе LLM, фундаментально изменила то, как мы улучшаем обнаружение. Вместо того чтобы ждать, пока злоумышленники добьются успеха, и полагаться на последующие отчеты пользователей, мы получили возможность выявлять системные пробелы раньше и устранять их в источнике. Этот переход от реактивного исправления к проактивному усилению напрямую воплотился в измеримое влияние на клиентов.
Самым непосредственным сигналом успеха стало заметное снижение количества жалоб от клиентов. Фишинг, связанный с "Sales Outreach", исторически генерировал большой объем пропусков, о которых сообщали пользователи, во многом потому, что эти сообщения очень похожи на легитимную деловую переписку и часто обходят традиционные системы, основанные на правилах или репутации. По мере того как наши целевые модели запускались и непрерывно совершенствовались с помощью данных от LLM, все меньше таких сообщений вообще достигало конечных пользователей.
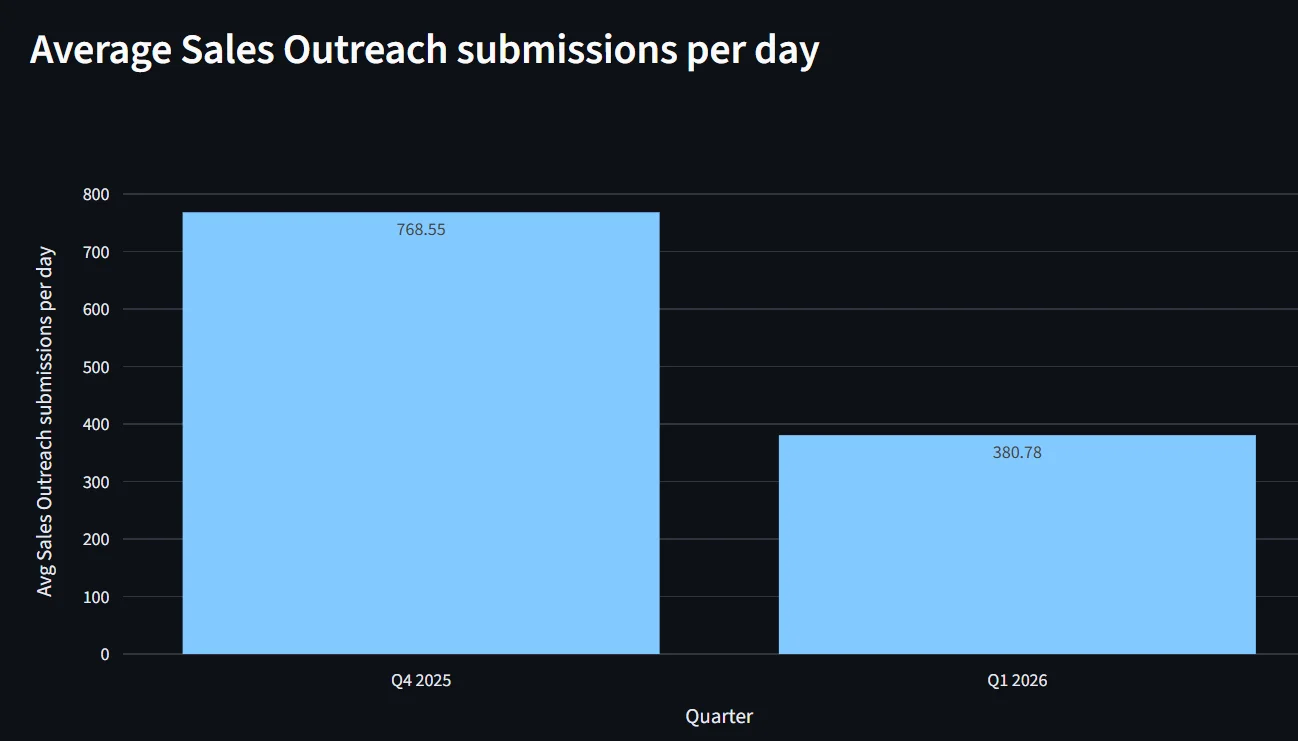
Данные ясно отражают это изменение. Среднедневное количество отправленных на проверку писем категории "Sales Outreach" — сообщений, которые мы пометили как чистые, но которые на самом деле оказались фишинговыми письмами "Sales Outreach", отмеченными конечными пользователями — снизилось с 965 в третьем квартале 2025 года до 769 в четвертом квартале 2025 года, что представляет собой сокращение на 20,4% в отчетных пропусках за один квартал.
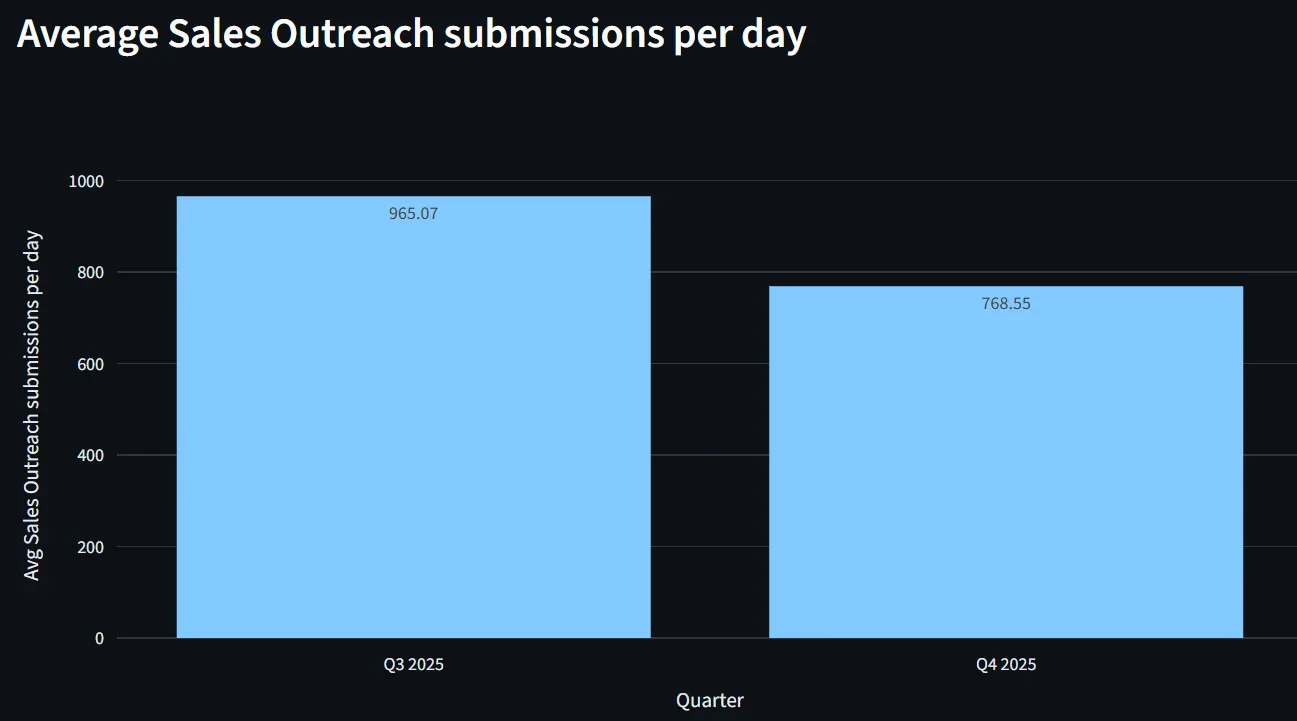
Это снижение — не просто улучшение метрики; оно означает на тысячи меньше disruptive моментов в день для команд безопасности и конечных пользователей. Каждый предотвращенный инцидент — это фишинговая попытка, которая была остановлена до того, как могла подорвать доверие, потратить время аналитика или заставить пользователя принимать решение о безопасности в середине рабочего процесса. Мы наблюдаем продолжение этой тенденции в первом квартале 2026 года: среднедневное количество инцидентов уменьшилось на две трети.
По сути, LLM позволили нам «увидеть» самолеты, которые не вернулись. Освещая ранее невидимые режимы сбоев, мы смогли укрепить защиту именно там, где злоумышленники концентрировали свои усилия. В результате получается система, которая улучшает не только показатели обнаружения, но и повседневный опыт людей, которые на нее полагаются.
Следующий фронт в гонке вооружений
Наша работа с LLM только начинается.
Чтобы оставаться впереди следующей эволюции атак, мы движемся к модели полной осведомленности об окружении, повышая специфичность LLM для извлечения деталей криминалистического уровня из каждого взаимодействия. Это детальное картирование позволяет нам идентифицировать конкретные тактические сигнатуры, а не полагаться на общие метки.
В то же время мы развертываем специализированные модели машинного обучения, целенаправленно созданные для поиска новых, высокообфусцированных векторов на «окраинах», которые упускают традиционные средства защиты. Используя эти данные LLM в реальном времени в качестве стратегического компаса, мы можем перенаправить нашу экспертную работу с людей с известного «шума» на критические пробелы, где, вероятно, произойдет следующая атака.
Освещая «самолеты, которые не вернулись», мы делаем больше, чем просто реагируем на пропущенные письма; мы систематически сужаем поле боя. В гонке вооружений для электронной почты преимущество принадлежит той стороне, которая первой может увидеть невидимое.
Готовы усилить защиту вашей электронной почты?
Мы предоставляем всем организациям (независимо от того, являются ли они клиентами Cloudflare или нет) бесплатный доступ к нашему инструменту Retro Scan, позволяя им использовать наши прогнозные модели ИИ для сканирования существующих входящих сообщений в Microsoft 365.
Retro Scan обнаружит и выделит любые найденные угрозы, позволяя организациям устранить их прямо в своих почтовых ящиках. Обладая этими данными, организации могут внедрить дополнительные средства контроля, используя либо Cloudflare Email Security, либо предпочтительное для них решение, чтобы предотвратить попадание подобных угроз в свои почтовые ящики в будущем.