Как найти первопричину сбоя управления конфигурацией, когда у вас пик в сотни изменений за 15 минут на тысячах серверов?
Такую задачу мы решали, создавая инфраструктуру для сокращения задержек выпуска из-за сбоев Salt — инструмента управления конфигурацией. (В итоге мы сократили такие сбои на периферии более чем на 5%, как объясним ниже.) Мы рассмотрим основы Salt и его использование в Cloudflare. Затем опишем типичные режимы сбоев и как они задерживают нашу возможность выпускать ценные изменения для обслуживания клиентов.
Сначала решив архитектурную проблему, мы заложили основу для механизмов самообслуживания по поиску первопричин сбоев Salt на серверах, в дата-центрах и группах дата-центров. Эта система способна коррелировать сбои с коммитами git, отказами внешних сервисов и ad hoc релизами. Результатом стало сокращение длительности задержек выпуска ПО и общее уменьшение рутинного, повторяющегося анализа для SRE.
Для начала мы погрузимся в основы сети Cloudflare и то, как Salt работает в ней. А затем перейдем к тому, как мы решили задачу, подобную поиску иголки в стоге сена.
Как работает Salt
Управление конфигурацией (CM) гарантирует, что система соответствует своей конфигурационной информации, и поддерживает целостность и прослеживаемость этой информации с течением времени. Хорошая система управления конфигурацией обеспечивает, чтобы система не «дрейфовала» — т.е. не отклонялась от желаемого состояния. Современные системы CM включают детальные описания инфраструктуры, контроль версий для этих описаний и другие механизмы для поддержания желаемого состояния в разных средах. Без CM администраторы должны вручную настраивать системы — процесс, подверженный ошибкам и сложный для воспроизведения.
Salt — пример такого инструмента CM. Разработанный для высокоскоростного удаленного выполнения и управления конфигурацией, он использует простую, масштабируемую модель для управления большими парками. Как зрелый инструмент CM, он обеспечивает согласованность, воспроизводимость, контроль изменений, аудируемость и сотрудничество через границы команд и организаций.
Дизайн Salt вращается вокруг архитектуры master/minion, шины сообщений на основе ZeroMQ и декларативной системы состояний. (В Cloudflare мы обычно избегаем терминов "master" и "minion". Но мы будем использовать их здесь, потому что так Salt описывает свою архитектуру.) Salt master — это центральный контроллер, распределяющий задания и данные конфигурации. Он прослушивает запросы на шине сообщений и отправляет команды целевым minion'ам. Также он хранит файлы состояний, данные pillar и кэш-файлы. Salt minion — это легковесный агент, установленный на каждом управляемом хосте/сервере. Каждый minion поддерживает соединение с master'ом через ZeroMQ и подписывается на опубликованные задания. Когда задание соответствует minion'у, он выполняет запрошенную функцию и возвращает результаты.
Диаграмма ниже показывает упрощение архитектуры Salt, описанной в документации, для целей этого блог-поста.
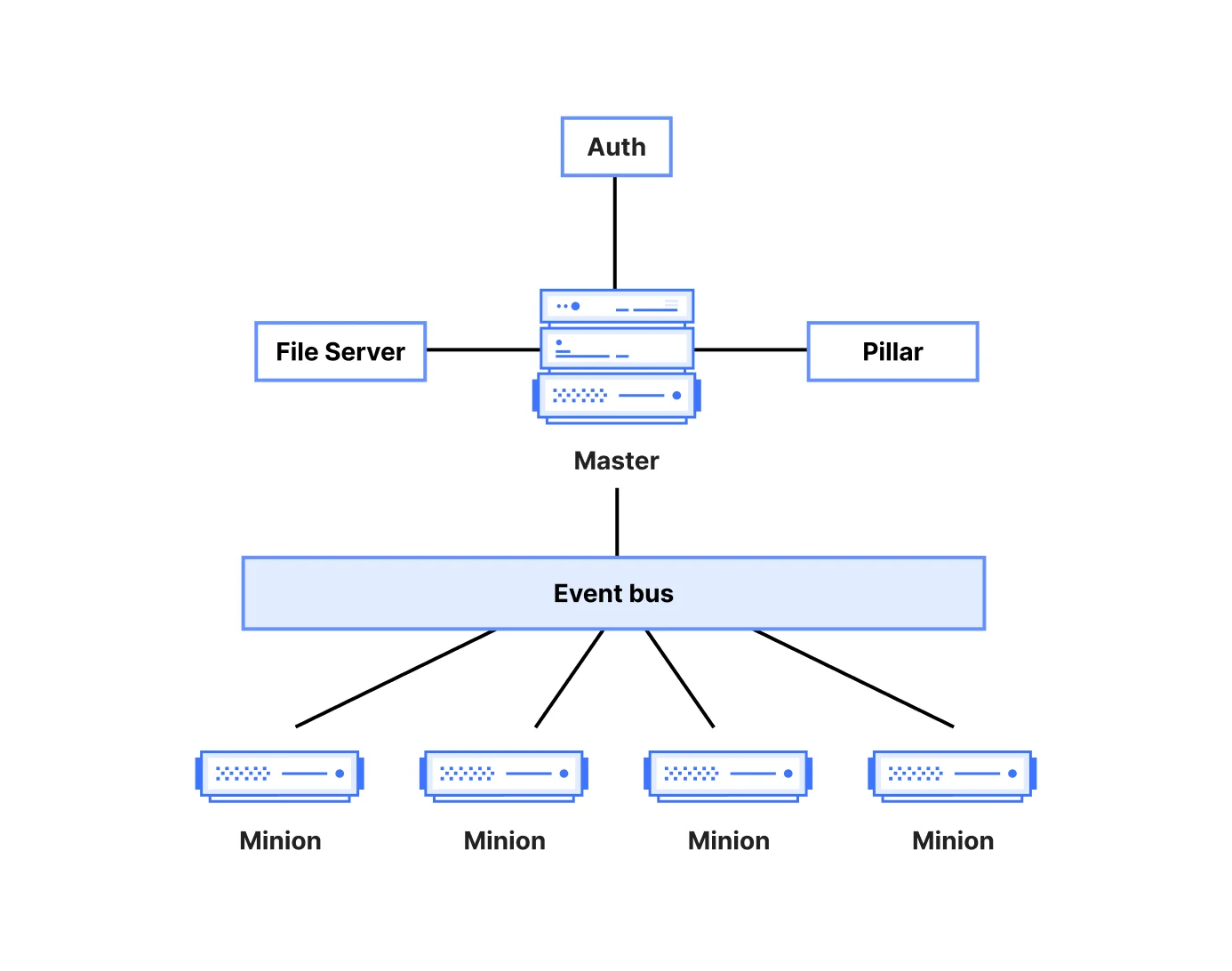
Система состояний предоставляет декларативное управление конфигурацией. Состояния часто пишутся на YAML и описывают ресурс (пакет, файл, службу, пользователя и т.д.) и желаемые атрибуты. Распространенный пример — состояние пакета, которое гарантирует, что пакет установлен в указанной версии.
# /srv/salt/webserver/init.sls
include:
- common
nginx:
pkg.installed: []
/etc/nginx/nginx.conf:
file.managed:
- source: salt://webserver/files/nginx.conf
- require:
- pkg: nginxСостояния могут вызывать модули выполнения — это функции Python, реализующие системные действия. При применении состояний Salt возвращает структурированный результат, содержащий информацию об успешности состояния (result: True/False), комментарий, внесенные изменения и длительность.
Salt в Cloudflare
Мы используем Salt для управления нашим постоянно растущим парком машин и ранее писали о нашем широком использовании. Описанная выше архитектура master-minion позволяет нам передавать конфигурацию в виде состояний на тысячи серверов, что необходимо для поддержания нашей сети. Мы разработали наше распространение изменений с защитой радиуса воздействия. С этими защитами сбой highstate становится сигналом, а не инцидентом, влияющим на клиентов.
Этот дизайн релиза был преднамеренным — мы решили «безопасно отказывать» вместо жесткого отказа. Дополнительно добавив ограничения для безопасного выпуска нового кода до того, как функция достигнет всех пользователей, мы можем распространять изменение с уверенностью, что сбои по умолчанию остановят конвейер развертывания Salt. Однако каждая остановка блокирует другие развертывания конфигурации и требует человеческого вмешательства для определения первопричины. Это может быстро стать рутинным процессом, так как шаги повторяются и не приносят долговременной ценности.
Часть нашего конвейера развертывания для изменений Salt использует Apt. Каждые X минут коммит мержится в мастер-ветку, каждые Y минут эти мержи собираются и развертываются на APT-серверы. Ключевой файл для получения конфигурации Salt Master с этого APT-сервера — файл источников APT:
# /etc/apt/sources.list.d/saltcodebase.sources
# MANAGED BY SALT -- DO NOT MODIFY
Types: deb
URIs: mirror+file:/etc/apt/mirrorlists/saltcodebase.txt
Suites: stable canary
Components: cloudflare
Signed-By: /etc/apt/keyrings/cloudflare.gpgЭтот файл направляет master в правильный набор для его конкретной среды. Используя этот набор, он получает последний пакет, содержащий соответствующий Debian-пакет Salt с последними изменениями. Он устанавливает этот пакет и начинает развертывание включенной конфигурации. По мере развертывания конфигурации на машинах, машины сообщают о своем состоянии здоровья с помощью Prometheus. Если версия здорова, она переходит в следующую среду. Перед переходом версия должна пройти определенный порог выдержки, чтобы позволить версии проявить свои ошибки, делая более сложные проблемы очевидными. Это счастливый сценарий.
Несчастливый сценарий приносит множество осложнений: Поскольку мы делаем прогрессивные развертывания, если версия сломана, любая последующая версия тоже сломана. И поскольку сломанные версии постоянно замещаются новыми, нам нужно полностью останавливать развертывания. В сценарии сломанной версии критически важно выпустить исправление как можно скорее. Это затрагивает ключевой вопрос этого блог-поста: Что, если сломанная версия Salt распространилась по среде, мы прекращаем развертывания, и нам нужно выпустить исправление как можно скорее?
Проблема: как Salt ломается и сообщает об ошибках (и как это влияет на Cloudflare)
Хотя Salt стремится к идемпотентной и предсказуемой конфигурации, сбои могут происходить на этапах рендера, компиляции или выполнения. Эти сбои обычно вызваны ошибочной конфигурацией. Ошибки в шаблонах Jinja или невалидный YAML могут вызвать сбой на этапе рендера. Примеры включают пропущенные двоеточия, некорректные отступы или неопределенные переменные. Синтаксическая ошибка часто возникает с трассировкой стека, указывающей на проблемную строку.
Другая частая причина сбоя — отсутствующие данные pillar или grain. Поскольку данные pillar компилируются на master'е, забывание обновить top-файлы pillar или обновить pillar может привести к исключениям KeyError. Как система, поддерживающая порядок с помощью требований, некорректно настроенные требования могут привести к выполнению состояний в неправильном порядке или их пропуску. Сбои также могут происходить, когда minion'ы не могут аутентифицироваться с master'ом или не могут достичь master'а из-за сетевых проблем или проблем с фаерволом.
Salt сообщает об ошибках несколькими способами. По умолчанию команды salt и salt-call завершаются с кодом возврата 1 , когда любое состояние завершается неудачно. Salt также устанавливает внутренние коды возврата для специфичных случаев: 1 для ошибок компиляции, 2 когда состояние возвращает False, и 5 для ошибок компиляции pillar. Тестовый режим показывает, какие изменения были бы сделаны без фактического выполнения, но полезен для выявления синтаксических проблем или проблем с порядком. Отладочные логи можно включить с помощью опции CLI -l debug (salt <minion> state.highstate -l debug).
Возврат состояния также включает детали отдельных сбоев состояний — длительности, временные метки, функции и результаты. Если мы внесем сбой в состояние file.managed, ссылаясь на файл, которого нет в файловом сервере Salt, мы увидим этот сбой:
web1:
----------
ID: nginx
Function: pkg.installed
Result: True
Comment: Пакет nginx уже установлен
Started: 15:32:41.157235
Duration: 256.138 ms
Changes:
----------
ID: /etc/nginx/nginx.conf
Function: file.managed
Result: False
Comment: Исходный файл salt://webserver/files/nginx.conf не найден в saltenv 'base'
Started: 15:32:41.415128
Duration: 14.581 ms
Changes:
Summary for web1
------------
Succeeded: 1 (changed=0)
Failed: 1
------------
Total states run: 2
Total run time: 270.719 msВозврат также может отображаться в JSON:
{
"web1": {
"pkg_|-nginx_|-nginx_|-installed": {
"comment": "Пакет nginx уже установлен",
"name": "nginx",
"start_time": "15:32:41.157235",
"result": true,
"duration": 256.138,
"changes": {}
},
"file_|-/etc/nginx/nginx.conf_|-/etc/nginx/nginx.conf_|-managed": {
"comment": "Исходный файл salt://webserver/files/nginx.conf не найден в saltenv 'base'",
"name": "/etc/nginx/nginx.conf",
"start_time": "15:32:41.415128",
"result": false,
"duration": 14.581,
"changes": {}
}
}
}Гибкость формата вывода означает, что люди могут анализировать их с помощью пользовательских скриптов. Но что более важно, он также может потребляться более сложными, взаимосвязанными системами автоматизации. Мы знали, что сможем легко анализировать эти выводы, чтобы определить причину сбоя Salt по входным данным — например, изменение в системе контроля версий, сбой внешней службы или выпуск программного обеспечения. Но чего-то не хватало.
Решения
Ошибки конфигурации являются частой причиной сбоев в крупномасштабных системах. Некоторые из них могут даже привести к полным простоям системы, которые мы предотвращаем с помощью нашей архитектуры выпусков. Когда новый выпуск или конфигурация ломается в production, нашей команде SRE необходимо найти и устранить первопричину, чтобы избежать задержек выпуска. Как мы уже отмечали ранее, этот анализ утомителен и становится все сложнее из-за сложности системы.
В то время как некоторые организации используют формальные методы, такие как автоматизированный анализ первопричин, большая часть анализа по-прежнему остается досадно ручной. Оценив масштаб проблемы, мы решили применить автоматизированный подход. В этом разделе описывается пошаговый подход к решению этой широкой, сложной проблемы в production.
Первый этап: извлекаемые входные данные управления конфигурацией
Когда Salt highstate завершается сбоем на минионе, команды SRE сталкивались с утомительным процессом расследования: ручное подключение по SSH к минионам, поиск в журналах сообщений об ошибках, отслеживание идентификаторов заданий (JID) и поиск задания, связанного с JID, на одном из нескольких связанных мастеров. И все это в условиях гонки против 4-часового окна хранения журналов мастера. Фундаментальная проблема была архитектурной: результаты заданий находятся на Salt Masters, а не на минионах, где они выполняются, что заставляет операторов угадывать, какой мастер обработал их задание (подключаясь по SSH к каждому) и ограничивает видимость для пользователей без доступа к мастеру.
Мы создали решение, которое кэширует результаты заданий непосредственно на минионах, аналогично возвращателю local_cache, который существует для мастеров. Это позволяет осуществлять локальное извлечение заданий и расширенные периоды хранения. Это преобразовало многоэтапное, срочное расследование в один запрос — операторы могут получать детали задания, автоматически извлекать контекст ошибки и отслеживать сбои до конкретных изменений файлов и авторов коммитов, все это прямо с самого миниона. Пользовательский возвращатель интеллектуально фильтрует и управляет размером кэша, устраняя проблему «какой мастер?», а также обеспечивая автоматическое определение причины ошибки, сокращая время решения и устраняя ручной труд при рутинном устранении неполадок.
Децентрализуя историю заданий и делая ее доступной для запросов в источнике, мы значительно приблизились к самостоятельному опыту отладки, где сбои автоматически контекстуализируются и атрибутируются, позволяя командам SRE сосредоточиться на исправлениях, а не на расследовании.
Второй этап: Самообслуживание с использованием модуля Salt Blame
Как только информация о заданиях стала доступна на минионе, нам больше не нужно было определять, какой мастер запустил задание, которое завершилось сбоем. Следующим шагом было написание модуля выполнения Salt, который позволил бы внешней службе запрашивать информацию о заданиях, и, более конкретно, информацию о неудачных заданиях, без необходимости знания внутренних механизмов Salt. Это привело нас к написанию модуля под названием Salt Blame. Cloudflare гордится своей культурой безупречности, наше программное обеспечение, с другой стороны…
Модуль blame отвечает за объединение трех вещей:
-
Локальной информации об истории заданий
-
Входных данных управления конфигурацией (последний коммит, присутствовавший во время задания)
-
Истории коммитов репозитория Git
Мы выбрали написание модуля выполнения для простоты, отделив внешнюю автоматизацию от необходимости понимать внутренние механизмы Salt и потенциальное использование операторами для дальнейшего устранения неполадок. Написание модулей выполнения уже хорошо налажено в операционных командах и соответствует четко определенным лучшим практикам, таким как модульные тесты, линтинг и тщательное рецензирование.
Модуль, что понятно, очень прост. Он перебирает в обратном хронологическом порядке задания в локальном кэше и ищет первое хронологически неудачное задание, а затем успешное задание непосредственно перед ним. Это делается для того, чтобы сузить круг истинного первого сбоя и дать нам результаты состояния до и после. На этом этапе у нас есть несколько путей для представления контекста вызывающей стороне: чтобы найти возможных виновников коммитов, мы просматриваем все коммиты между последним успешным Job ID и сбоем, чтобы определить, изменили ли какие-либо из них файлы, относящиеся к сбою. Мы также предоставили список неудачных состояний и их выводы как еще один путь для определения первопричины. Мы поняли, что такая гибкость важна для охвата широкого спектра возможных сбоев.
Мы также проводим различие между обычными неудачными состояниями и ошибками компиляции. Как описано в документации Salt, каждое задание возвращает разные коды возврата в зависимости от результата.
-
Ошибка компиляции: 1 устанавливается, когда встречается любая ошибка в компиляторе состояний.
-
Неудачное состояние: 2 устанавливается, когда любое состояние возвращает результат
False.
Большинство наших сбоев проявляются как неудачные состояния в результате изменения в системе контроля версий. Инженер, создающий новую функцию для наших клиентов, может непреднамеренно внести сбой, который не был обнаружен нашими тестами CI и Salt Master. В первой итерации модуля перечисления всех неудачных состояний было достаточно, чтобы точно определить первопричину сбоя highstate.
Однако мы заметили, что у нас есть слепое пятно. Ошибки компиляции не приводят к неудачному состоянию, поскольку никакое состояние не запускается. Поскольку эти ошибки возвращали код возврата, отличный от того, который мы проверяли, модуль был полностью слеп к ним. Большинство ошибок компиляции происходят, когда зависимость службы Salt fails во время фазы компиляции состояния. Они также могут произойти в результате изменения в системе контроля версий, хотя это редко.
Учет как сбоев состояний, так и ошибок компиляции резко улучшил нашу способность точно определять проблемы. Мы выпустили модуль для SRE, которые сразу же оценили преимущества более быстрого анализа Salt.
# Перечислить все последние неудачные состояния
minion~$ salt-call -l info blame.last_failed_states
local:
|_
----------
__id__:
/etc/nginx/nginx.conf
__run_num__:
5221
__sls__:
foo
changes:
----------
comment:
Исходный файл salt://webserver/files/nginx.conf не найден в saltenv 'base'
duration:
367.233
finish_time_stamp:
2025-10-22T10:00:17.289897+00:00
fun:
file.managed
name:
/etc/nginx/nginx.conf
result:
False
start_time:
10:00:16.922664
start_time_stamp:
2025-10-22T10:00:16.922664+00:00
# Перечислить все коммиты, коррелирующие с неудачным состоянием
minion~$ salt-call -l info blame.last_highstate_failure
local:
----------
commits:
|_
----------
author_email:
johndoe@cloudflare.com
author_name:
John Doe
commit_datetime:
2025-06-30T15:29:26.000+00:00
commit_id:
e4a91b2c9f7d3b6f84d12a9f0e62a58c3c7d9b5a
path:
/srv/salt/webserver/init.sls
message:
просмотрено 5 изменений за 12 коммитов в поисках 1 сбоя состояния
result:
True
# Перечислить все ошибки компиляции
minion~$ salt-call -l info blame.last_compile_errors
local:
|_
----------
error_types:
job_timestamp:
2025-10-24T21:55:54.595412+00:00
message: Произошел сбой службы
state: foo
traceback:
Полная трассировка стека сбоя
urls: http://url-matching-external-service-if-foundТретий этап: автоматизируйте, автоматизируйте, автоматизируйте!
Более быстрый анализ всегда приветствуется, и инженеры были готовы запускать локальные команды на минионах для анализа сбоев Salt. Но в напряженную смену время на вес золота. Когда сбои затрагивали несколько центров обработки данных или машин, запуск команд на всех этих минионах легко становился обременительным. Это решение также требовало переключения контекста между несколькими узлами и центрами обработки данных. Нам нужен был способ агрегировать общие типы сбоев с помощью одной команды – отдельные минионы, предпродажные центры обработки данных и производственные центры обработки данных.
Мы внедрили несколько механизмов для упрощения анализа и устранения ручных триггеров. Мы стремились максимально приблизить эти инструменты к месту анализа, которым часто является чат. С тремя различными командами инженеры теперь могли анализировать сбои Salt прямо из чатов.
С помощью иерархического подхода мы сделали возможной индивидуальную диагностику для миньонов, центров обработки данных и групп центров обработки данных. Иерархия делает эту архитектуру полностью расширяемой, гибкой и самоорганизующейся. Инженер может диагностировать сбой на одном миньоне и одновременно при необходимости во всем центре обработки данных.
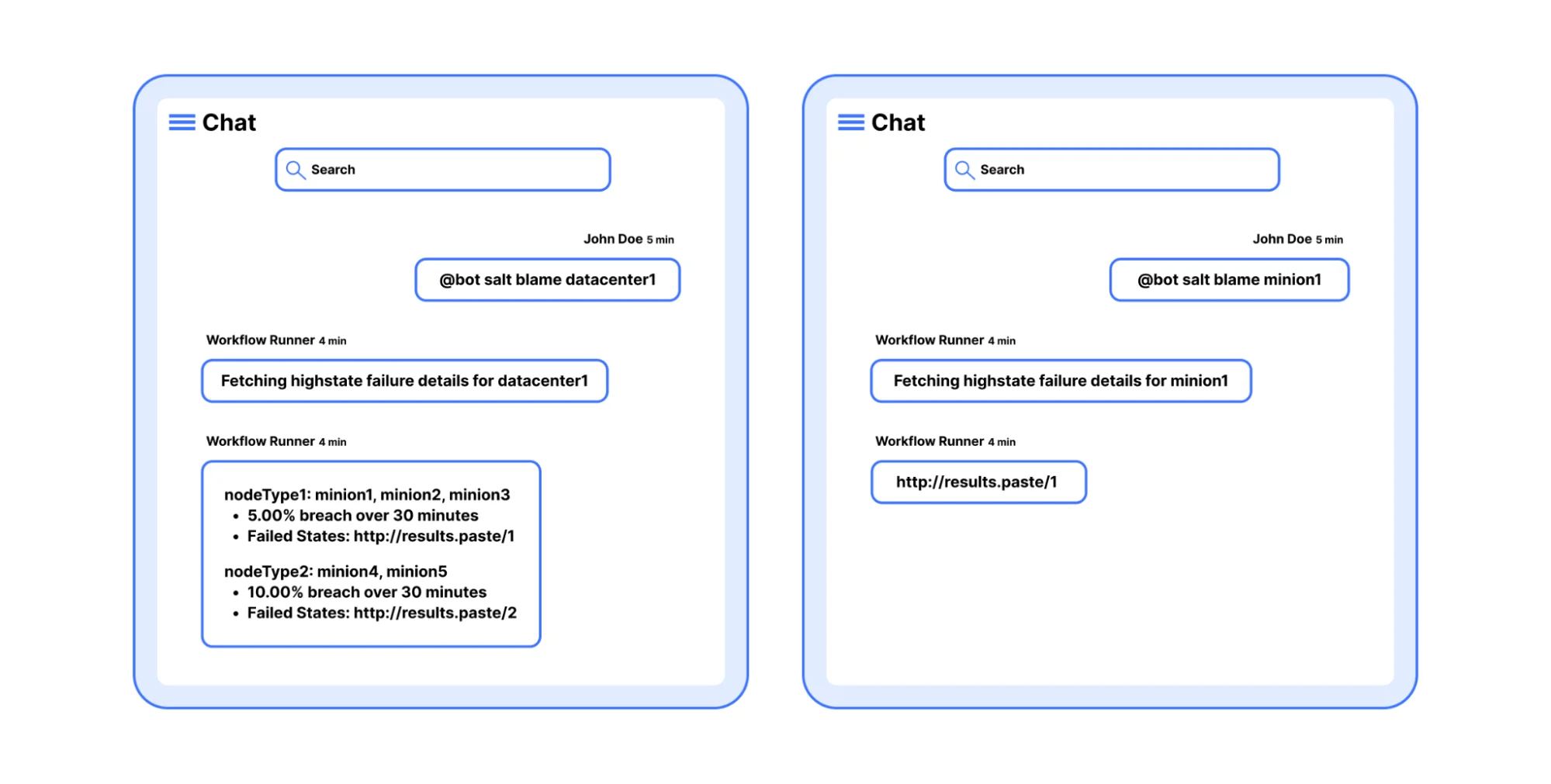
Возможность одновременно диагностировать несколько центров обработки данных сразу же стала полезной для отслеживания первопричин сбоев в пре-продакшн центрах обработки данных. Эти сбои задерживают распространение изменений в другие центры обработки данных и мешают нашей способности выпускать изменения для клиентских функций, исправлений ошибок или устранения инцидентов. Добавление этой опции диагностики сократило время на отладку и устранение сбоев Salt более чем на 5%, что позволяет нам стабильно выпускать важные изменения для наших клиентов.
Хотя 5% сразу не выглядит как кардинальное улучшение, магия заключается в кумулятивном эффекте. Мы не будем раскрывать реальные цифры времени задержек выпусков, но можем провести простой мысленный эксперимент. Если среднее затрачиваемое время составляет даже всего 60 минут в день, сокращение на 5% экономит нам 90 минут (один час 30 минут) в месяц.
Еще одно косвенное преимущество заключается в более эффективных циклах обратной связи. Поскольку инженеры тратят меньше времени на возню со сложными конфигурациями, эта энергия перенаправляется на предотвращение повторного возникновения, что дополнительно сокращает общее время на неизмеримую величину. Наши будущие планы включают измерения и аналитику данных для понимания результатов этих прямых и косвенных циклов обратной связи.
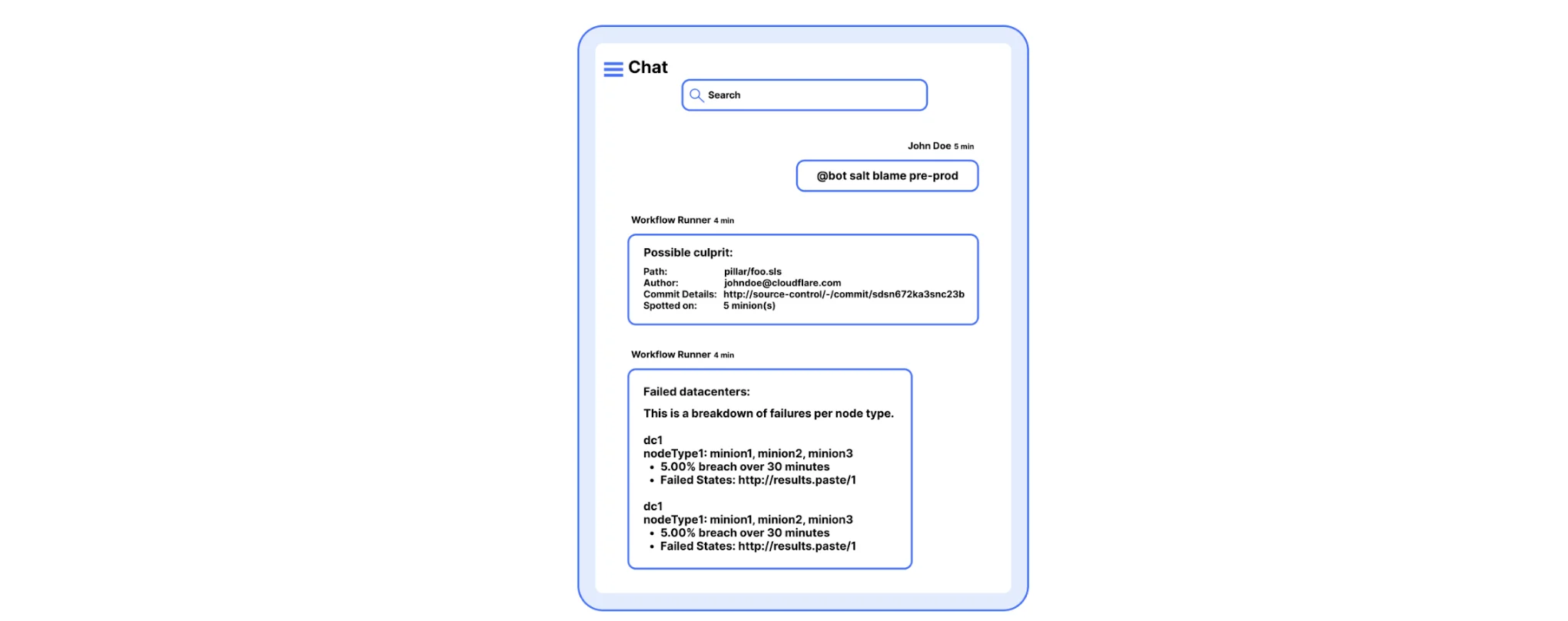
На изображении ниже показан пример вывода диагностики пре-продакшн среды. Мы можем соотносить сбои с git-коммитами, релизами и сбоями внешних сервисов. Во время напряженной смены эта информация бесценна для быстрого исправления поломок. В среднем каждое "определение виновника" для миньона занимает менее 30 секунд, тогда как несколько центров обработки данных способны вернуть результат за минуту или меньше.
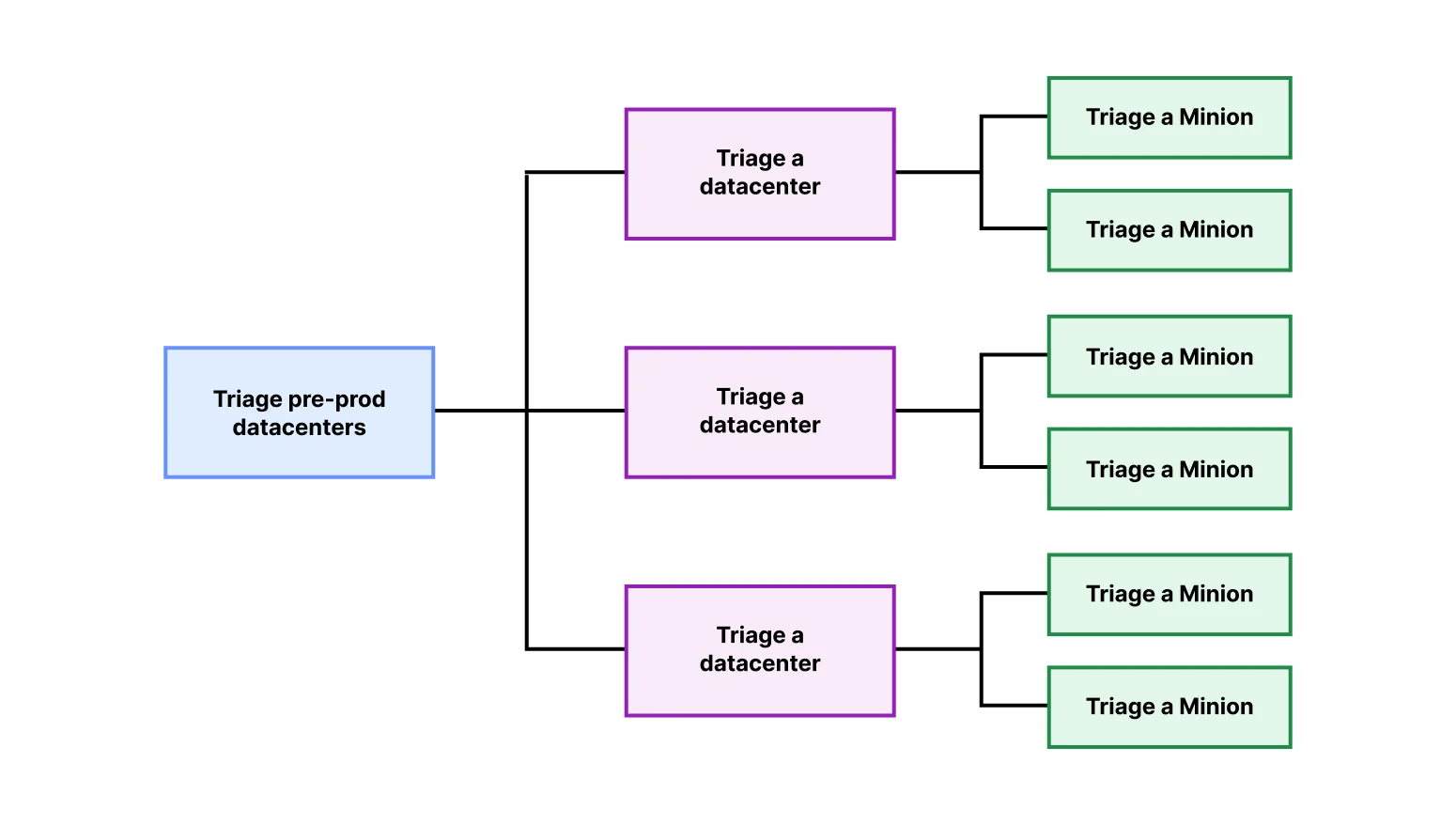
На изображении ниже описана иерархическая модель. Каждый шаг в иерархии выполняется параллельно, что позволяет нам достигать молниеносных результатов.
Имея эти механизмы в распоряжении, мы дополнительно сократили время диагностики, запуская автоматизацию диагностики по известным условиям, особенно тем, которые влияют на конвейер выпуска. Это напрямую улучшило скорость внесения изменений на edge, поскольку требовалось меньше времени для нахождения первопричины и исправления вперед или отката.
Четвертый этап: измерять, измерять, измерять
После того как мы получили молниеносную диагностику Salt, нам потребовался способ измерения первопричин. Хотя отдельные первопричины не имеют немедленной ценности, исторический анализ был признан важным. Мы хотели понять общие причины сбоев, особенно поскольку они мешают нашей способности доставлять ценность клиентам. Эти знания создают цикл обратной связи, который можно использовать для поддержания низкого количества сбоев.
Используя Prometheus и Grafana, мы отслеживаем основные причины сбоев: git-коммиты, релизы, сбои внешних сервисов и неатрибутированные failed states. Список failed states особенно полезен, потому что мы хотим знать повторяющихся нарушителей и стимулировать лучшее внедрение стабильных практик выпуска. Мы также особенно заинтересованы в первопричинах — всплеск количества сбоев из-за git-коммитов указывает на необходимость внедрения лучших практик кодирования и линтинга, всплеск сбоев внешних сервисов указывает на регрессию во внутренней системе, которую нужно исследовать, а всплеск сбоев на основе релизов указывает на необходимость лучшего контроля и сопровождения выпусков.
Мы анализируем эти метрики ежемесячно, обеспечивая механизмы обратной связи через внутренние тикеты и эскалации. Хотя непосредственное влияние этих усилий еще не видно, поскольку они находятся в зачаточном состоянии, мы ожидаем улучшения общего состояния нашей инфраструктуры Saltstack и процесса выпуска за счет сокращения количества наблюдаемых поломок.
Более широкая картина
Большая часть операционной работы часто рассматривается как "неизбежное зло". Люди в ops приучены вмешиваться, когда происходят сбои, и устранять их. Этот цикл "оповещение-реакция" необходим для поддержания работы инфраструктуры, но часто приводит к рутинной работе. Мы обсуждали эффект рутинной работы в предыдущем посте блога.
Эта работа представляет собой еще один шаг в правильном направлении — устранение дополнительной рутины для наших дежурных SRE и высвобождение ценного времени для работы над новыми проблемами. Мы надеемся, что это побудит других инженеров эксплуатации делиться прогрессом, которого они достигают в сокращении общей рутины в своих организациях. Мы также надеемся, что такая работа может быть внедрена в самом Saltstack, хотя отсутствие однородности в производственных системах across нескольких компаний делает это маловероятным.
В будущем мы планируем повысить точность обнаружения и меньше полагаться на внешнюю корреляцию входных данных для определения первопричины неудачных результатов. Мы исследуем, как перенести больше этой логики в наши нативные модули Saltstack, дополнительно упрощая процесс и избегая регрессий по мере расхождения внешних систем.