По мере роста площади атак в интернете, Межсетевой экран веб-приложений (WAF) от Cloudflare предоставляет множество решений для смягчения этих атак. Это отлично для наших клиентов, но высокая кардинальность рабочих нагрузок миллионов обрабатываемых нами запросов означает, что генерация ложных срабатываний неизбежна. Это означает, что конфигурация по умолчанию для наших клиентов должна быть точно настроена.
Тонкая настройка — не непрозрачный процесс: клиентам необходимо получить некоторые данные и затем решить, что подходит им. В этом посте объясняются технологии, которые мы предлагаем, чтобы клиенты могли видеть, почему WAF предпринимает определенные действия, а также улучшения, которые были внесены для уменьшения шума и увеличения полезного сигнала.
Действие Log — отлично, но можно ли сделать больше?
WAF от Cloudflare защищает серверы источников от различных атак 7-го уровня, то есть атак, которые нацелены на уровень приложений. Защита обеспечивается с помощью различных инструментов, таких как:
-
Управляемые правила, которые пишут аналитики безопасности Cloudflare для устранения распространенных уязвимостей и эксплойтов (CVE), рисков безопасности OWASP и уязвимостей вроде Log4Shell.
-
Пользовательские правила, где клиенты могут писать правила с помощью выразительного Языка правил.
-
Правила ограничения частоты запросов, обнаружение вредоносных загрузок, обнаружение утечек учетных данных и т.д.
Эти инструменты построены на Движке наборов правил. Когда происходит совпадение с Выражением правила, движок выполняет действие.
Действие Log используется для имитации поведения правил. Это действие доказывает, что выражение правила совпало в движке, и генерирует событие журнала, к которому можно получить доступ через Аналитику безопасности, События безопасности, Logpush или Доставку журналов с границы.
Журналы отлично подходят для проверки того, что правило работает как ожидалось на трафике, с которым оно должно было совпасть, но показать, что правило совпало, недостаточно, особенно когда выражение правила может принимать множество путей выполнения. В псевдокоде выражение может выглядеть так:
Если любой из заголовков HTTP-запроса содержит ключ "authorization" ИЛИ приведенное к нижнему регистру представление заголовка HTTP host начинается с "cloudflare", ТОГДА логировать
Синтаксис языка правил будет:
any(http.request.headers[*] contains "authorization") or starts_with(lower(http.host), "cloudflare")Отладка этого выражения создает пару проблем. Это левая (LHS) или правая (RHS) часть выражения OR совпала? Функции, такие как Декодирование Base64, Декодирование URL и, в данном случае, приведение к нижнему регистру, могут применять преобразования к исходному представлению этих полей, что приводит к дальнейшей неопределенности в отношении того, какие характеристики запроса привели к совпадению.
Чтобы еще больше усложнить это, множество правил в наборе правил могут регистрировать совпадения. Наборы правил, такие как Cloudflare OWASP, используют совокупный балл различных правил для запуска действия, когда балл пересекает установленный порог.
Кроме того, выражения Управляемых правил Cloudflare и правил OWASP являются приватными. Это повышает нашу безопасность, но также означает, что клиенты могут только догадываться о том, что делают эти правила, по их названиям, тегам и описаниям. Например, одно правило может быть помечено как "SonicWall SMA - Удаленное выполнение кода - CVE:CVE-2025-32819".
Что поднимает вопросы: Какая часть моего запроса привела к совпадению в Движке наборов правил? Это ложные срабатывания?
Вот где проявляет себя логирование полезной нагрузки. Оно может помочь нам детально разобраться в конкретных полях и их соответствующих значениях, после преобразований, в правиле, которое привело к совпадению.
Логирование полезной нагрузки
Логирование полезной нагрузки — это функция, которая регистрирует, какие поля в запросе связаны с правилом, которое привело к действию WAF. Это снижает неоднозначность и предоставляет полезную информацию, которая может помочь выборочно проверить ложные срабатывания, гарантировать корректность и помочь в тонкой настройке этих правил для лучшей производительности.
Из примера выше запись журнала полезной нагрузки будет содержать либо LHS, либо RHS выражения, но не обе части одновременно.
Как работает логирование полезной нагрузки?
Движки логирования полезной нагрузки и наборов правил построены на Wirefilter, который был подробно объяснен.
По своей сути, эти движки — это объекты, написанные на Rust, которые реализуют черту компилятора. Эта черта управляет компиляцией абстрактных синтаксических деревьев (AST), полученных из этих выражений.
struct PayloadLoggingCompiler {
regex_cache HashMap<String, Arc<Regex>>
}
impl wirefilter::Compiler for PayloadLoggingCompiler {
type U = PayloadLoggingUserData
fn compile_logical_expr(&mut self, node: LogicalExpr) -> CompiledExpr<Self::U> {
// ...
let regex = self.regex_cache.entry(regex_pattern)
.or_insert_with(|| Arc::new(regex))
// ...
}
}Движок наборов правил выполняет выражение, и если оно вычисляется как истина, выражение и его контекст выполнения отправляются в компилятор логирования полезной нагрузки для повторного вычисления. Контекст выполнения предоставляет все значения времени выполнения, необходимые для вычисления выражения.
После завершения повторного вычисления логируются поля, задействованные в ветвях выражения, которые вычислились как истина.
Структура журнала — это карта полей wirefilter и их значений Map<Field, Value>
{
“http.host”: “cloudflare.com”,
“http.method”: “get”,
“http.user_agent”: “mozilla”
}Примечание: Эти журналы шифруются с помощью открытого ключа, предоставленного клиентом.
Эти журналы проходят через наш конвейер логирования и могут быть прочитаны разными способами. Клиенты могут настроить задание Logpush для записи в пользовательский Worker, который мы построили, и который использует закрытый ключ клиента для автоматической расшифровки этих журналов. Для расшифровки также можно использовать CLI-инструмент логирования полезной нагрузки, Worker или панель управления Cloudflare.
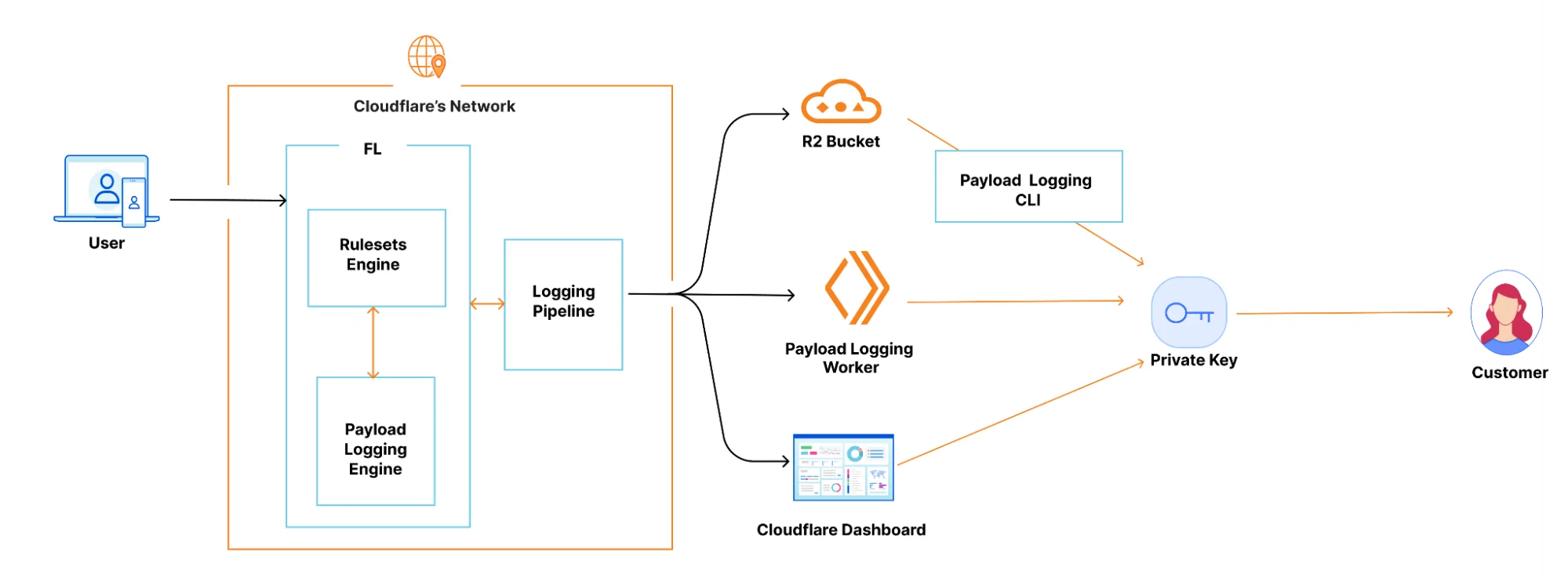
Какие улучшения были внедрены?
В wirefilter некоторые поля имеют тип массив. Поле http.request.headers.names — это массив всех имен заголовков в запросе. Например:
[“content-type”, “content-length”, “authorization”, "host"]Выражение, которое гласит any(http.request.headers.names[*] contains “c”), будет вычисляться как истина, потому что по крайней мере один из заголовков содержит букву "c". С предыдущей версией компилятора логирования полезной нагрузки будут залогированы все заголовки в поле "http.request.headers.names", поскольку это часть выражения, которая вычисляется как истина.
Журнал полезной нагрузки (предыдущий)
http.request.headers.names[*] = ["content-type", "content-length", "authorization", "host"]Теперь мы частично вычисляем поля массива и логируем индексы, соответствующие ограничению выражений. В данном случае это будут только заголовки, содержащие "c"!
Лог полезной нагрузки (новый)
http.request.headers.names[0,1] = ["content-type", "content-length"]Операторы
Это подводит нас к операторам в Wirefilter. Некоторые операторы, такие как "eq", приводят к точным совпадениям, например http.host eq "a.com". Есть другие операторы, которые приводят к "частичным" совпадениям – такие как "in", "contains", "matches" – которые работают вместе с регулярными выражениями.
Выражение в этом примере: `any(http.request.headers[*] contains "c")` использует оператор "contains", который производит частичное совпадение. Оно также использует функцию "any", которую мы можем назвать производящей частичное совпадение, потому что если хотя бы один из заголовков содержит "c", то мы должны логировать этот заголовок – а не все заголовки, как мы делали в предыдущей версии.
С улучшениями в компиляторе логирования полезной нагрузки, когда эти выражения вычисляются, мы логируем только частичные совпадения. В данном случае, новый компилятор логирования полезной нагрузки обрабатывает оператор "contains" аналогично методу "find" для байтов в стандартной библиотеке Rust. Это улучшает наш лог полезной нагрузки до:
http.request.headers.names[0,1] = ["c", "c"]Это делает всё намного понятнее. Это также избавляет наш конвейер логирования от обработки миллионов байтов. Например, поле, которое часто анализируется – это тело запроса — http.request.body.raw — которое может быть размером в десятки килобайт. Иногда выражения проверяют шаблон регулярного выражения, который должен соответствовать трём символам. В этом случае мы будем логировать 3 байта вместо килобайтов!
Контекст
Я знаю, знаю, ["c", "c"] не очень информативно. Даже если мы предоставили точную причину совпадения и значительно экономим на объёме байтов, записываемых в хранилища клиентов, ключевая цель – предоставить полезную отладочную информацию клиенту. В рамках улучшений логирования полезной нагрузки компилятор теперь также логирует "до" и "после" (если применимо) для частичных совпадений. Размер этих буферов в настоящее время составляет 15 байт каждый. Это означает, что наш лог полезной нагрузки теперь выглядит так:
http.request.headers[0,1] = [
{
before: null, // не включается в окончательный лог
content: "c",
after: "ontent-length"
},
{
before: null, // не включается в окончательный лог
content: "c",
after:"ontent-type"
}
]Пример лога полезной нагрузки (предыдущий)

Пример лога полезной нагрузки (новый)
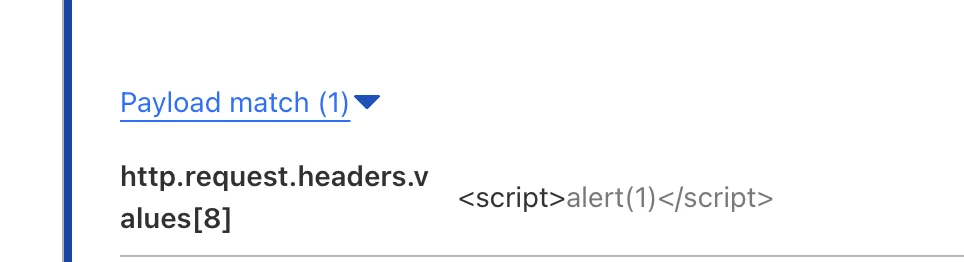
В предыдущем логе у нас есть все значения заголовков. В новом логе у нас есть 8-й индекс, который представляет собой вредоносный скрипт в HTTP-заголовке. Совпадение происходит по тегу "<script>", а остальное – это контекст, который показан серым текстом.
Оптимизации
Управляемые правила сильно зависят от регулярных выражений для идентификации вредоносных запросов. Разбор и компиляция этих выражений – это ресурсоёмкие задачи. Поскольку управляемые правила пишутся один раз и развертываются в миллионах зон, мы получаем выгоду от компиляции этих регулярных выражений и кэширования их в памяти. Это экономит нам циклы процессора, так как нам не нужно перекомпилировать их до перезапуска процесса.
Компилятор логирования полезной нагрузки использует много динамически размещаемых массивов или векторов для хранения промежуточного состояния этих логов. Такие крейты, как smallvec, также используются для сокращения выделений памяти в куче.
Печально известное значение "TRUNCATED"
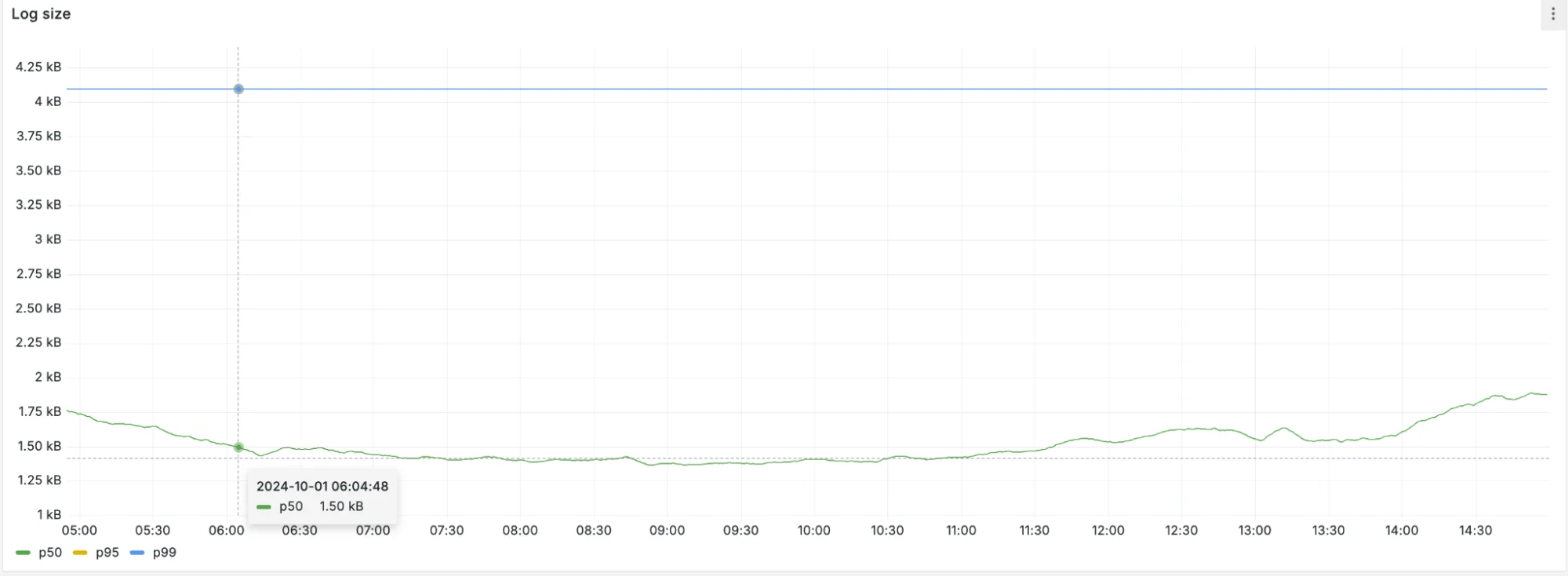
Иногда клиенты видят "truncated" в своих логах полезной нагрузки. Это происходит потому, что каждое событие брандмауэра имеет ограничение размера в байтах. Когда это ограничение превышается, лог полезной нагрузки обрезается.
Лог полезной нагрузки (предыдущий)
Лог полезной нагрузки (новый)
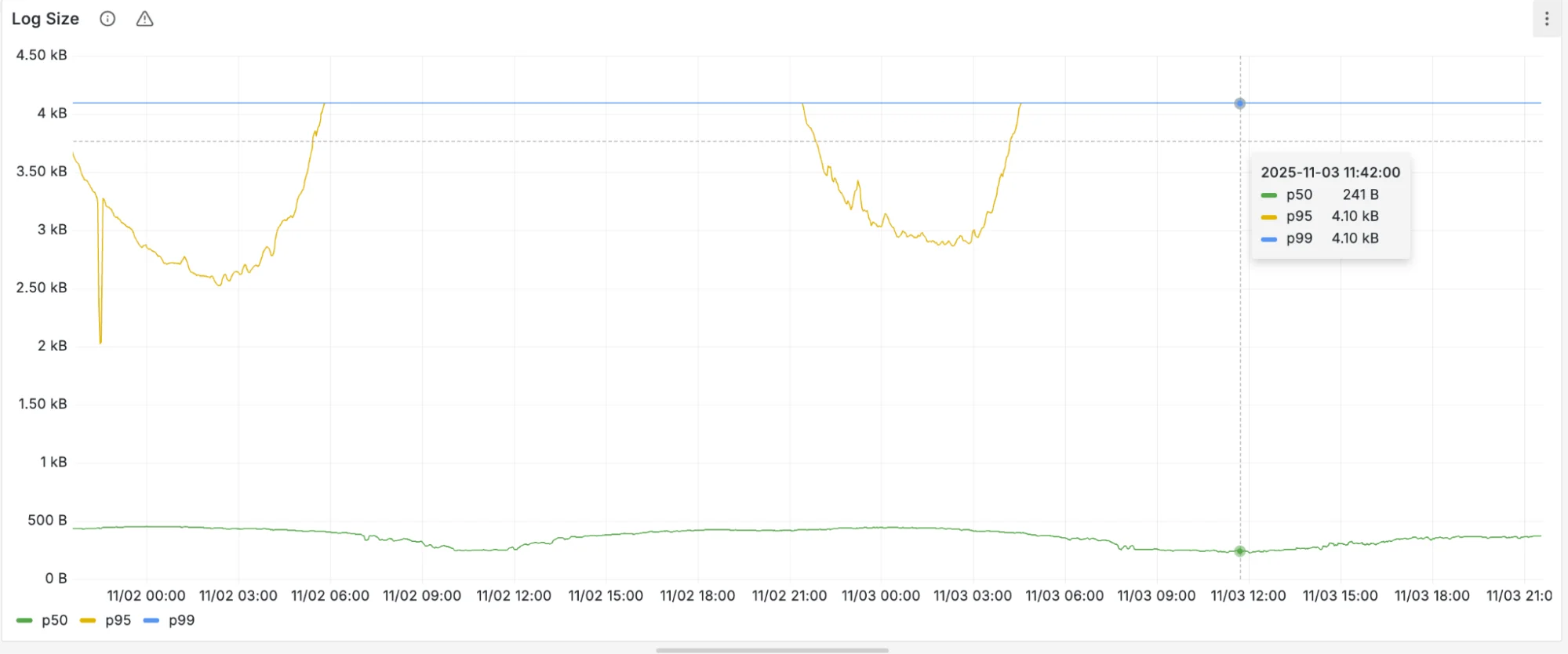
Мы увидели, что средний размер логов полезной нагрузки сократился с 1,5 Килобайт до 500 байт – снижение на 67%! Это означает гораздо меньше обрезанных логов полезной нагрузки.
Что дальше?
В настоящее время мы используем потерянное представление UTF-8 строк для представления значений. Это означает, что невалидные UTF-8 строки, такие как мультимедиа, представляются как U+FFFD символы замены Unicode. Для правил, которые будут работать с бинарными данными, целостность этих значений должна сохраняться с помощью байтовых массивов или другого формата сериализации.
Формат хранения для логирования полезной нагрузки – это JSON. Мы будем сравнивать его производительность с другими бинарными форматами, такими как CBOR, Cap'n Proto, Protobuf и др., чтобы увидеть, сколько времени обработки это сэкономит нашему конвейеру. Это поможет нам доставлять логи нашим клиентам быстрее, с дополнительным преимуществом, что бинарные форматы также помогают поддерживать определённую схему, которая будет обратно совместимой.
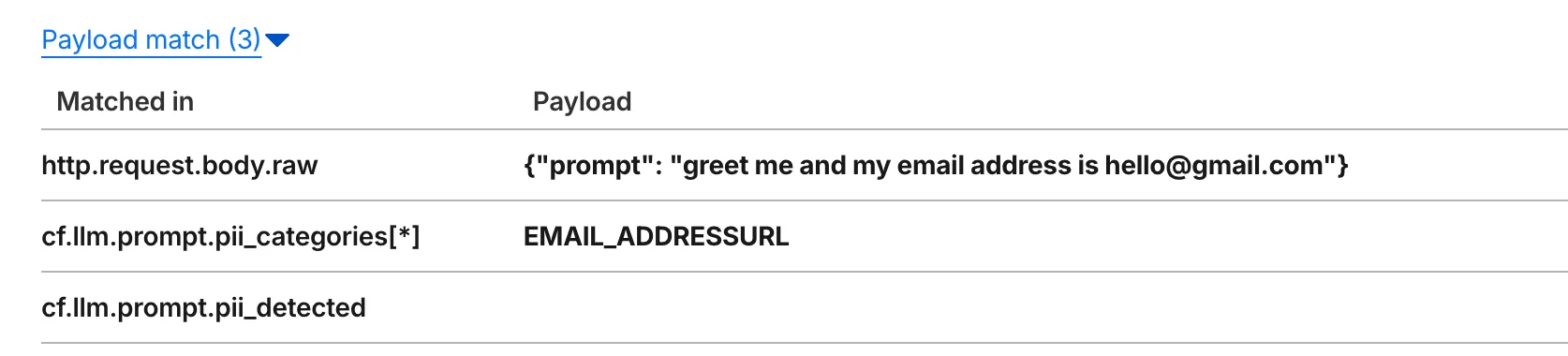
Наконец, логирование полезной нагрузки работает только с Управляемыми правилами. Оно будет развернуто в других продуктах Cloudflare WAF, таких как пользовательские правила, WAF Attack Score, проверка содержимого, Firewall for AI и другие. Пример логирования полезной нагрузки, показывающий промпты, содержащие PII, обнаруженные Firewall for AI:
Почему я должен быть в восторге?
Видимость действий, предпринимаемых WAF, даст клиентам уверенность в том, что их правила или конфигурации делают именно то, что они ожидают. Улучшения специфичности логирования полезной нагрузки – это шаг в этом направлении, а в конвейере – дальнейшие улучшения надежности, задержек и расширение на большее количество продуктов WAF.
Поскольку это было критическим изменением схемы JSON, мы развернули это постепенно для клиентов с соответствующей документацией.