Каждое взаимодействие в Интернете — включая загрузку веб-страницы, потоковое видео или вызов API — начинается с соединения. Эти фундаментальные логические соединения состоят из потока пакетов, передаваемых туда и обратно между устройствами.
Различные аспекты этих сетевых соединений привлекают внимание исследователей и практиков с самого существования Интернета. Интерес к соединениям даже предшествовал самому термину, как видно из основополагающей статьи 1991 года «Characteristics of wide-area TCP/IP conversations». Под любым названием, сообщество измерения Интернета было погружено в характеристики интернет-коммуникаций на протяжении десятилетий, задавая вопросы от «как долго?» и «какого размера?» до «как часто?» — и это только начало.
Удивительно, но характеристики соединений в глобальном Интернете в значительной степени недоступны. Хотя любой может использовать инструменты (например, Wireshark) для локального захвата данных, из-за проблем доступа и масштаба практически невозможно измерить соединения глобально. Более того, сетевые операторы обычно не делятся наблюдаемыми характеристиками — при условии, что на их наблюдение затрачено немало времени и усилий.
В этой записи блога мы движемся в другом направлении, делясь агрегированными данными о соединениях, установленных через нашу глобальную CDN. Мы представляем характеристики TCP-соединений — на которые приходится около 70% HTTP-запросов к Cloudflare — предоставляя эмпирические данные, которые трудно получить только с помощью клиентских измерений.
Почему важны характеристики соединений
Характеристика поведения системы помогает нам прогнозировать влияние изменений. В контексте сетей рассмотрим новый алгоритм маршрутизации или транспортный протокол: как можно измерить его эффекты? Один из вариантов — развернуть изменение непосредственно в рабочих сетях, но это рискованно. Непредвиденные последствия могут нарушить работу пользователей или других частей сети, делая подход «сначала развернуть» потенциально небезопасным или этически сомнительным.
Более безопасной альтернативой живому развертыванию в качестве первого шага является симуляция. Используя симуляцию, разработчик может получить важные сведения о своей схеме, не создавая полную версию. Но моделирование всего Интернета является сложной задачей, как описано в другой основополагающей работе «Why we don't know how to simulate the Internet».
Для проведения полезной симуляции нам нужно, чтобы она вела себя как реальная система, которую мы изучаем. Это означает генерацию синтетических данных, имитирующих поведение в реальном мире. Часто мы делаем это, используя статистические распределения — математические описания того, как ведут себя реальные данные. Но прежде чем мы сможем создать эти распределения, нам сначала нужно охарактеризовать данные — измерить и понять их ключевые свойства. Только тогда наша симуляция сможет давать реалистичные результаты.
Разбор набора данных
Ценность любых данных зависит от механизма их сбора. Каждый набор данных имеет слепые зоны, смещения и ограничения, и игнорирование этого может привести к вводящим в заблуждение выводам. Изучая детали — как данные были собраны, что они представляют и что исключают — мы можем лучше понять их надежность и принимать обоснованные решения об их использовании. Давайте внимательнее рассмотрим собранную нами телеметрию.

Обзор набора данных. Данные описывают TCP-соединения, обозначенные на диаграмме выше как Посетитель к Cloudflare, которые обслуживают запросы через HTTP 1.0, 1.1 и 2.0 и составляют около 70% всех 84 миллионов HTTP-запросов в секунду в среднем, получаемых нашими глобальными серверами CDN.
Выборка. Пассивно собранный снимок данных берется из равномерно выбранных 1% всех TCP-соединений с Cloudflare в период с 7 по 15 октября 2025 года. Выборка происходит на каждом отдельном сервере, обращенном к клиенту, чтобы смягчить смещения, которые могут возникнуть при выборке на уровне центра обработки данных.
Разнообразие. В отличие от многих крупных операторов, чей трафик в основном их собственный и доминирует несколькими сервисами, такими как поиск, социальные сети или потоковое видео, подавляющая часть рабочей нагрузки Cloudflare поступает от наших клиентов, которые выбирают размещение Cloudflare перед своими веб-сайтами для помощи в защите, улучшении производительности и снижении затрат. Это разнообразие клиентов приносит широкий спектр веб-приложений, сервисов и пользователей со всего мира. В результате, соединения, которые мы наблюдаем, формируются широким диапазоном клиентских устройств и специфичного для приложений поведения, которые постоянно развиваются.
Что мы логируем. Каждая запись в журнале состоит из метаданных на уровне сокета, захваченных через структуру TCP_INFO ядра Linux, вместе с SNI и количеством запросов, сделанных во время соединения. Журналы исключают отдельные HTTP-запросы, транзакции и детали. Мы ограничиваем использование журналов статистикой метаданных соединений, такой как продолжительность и количество переданных пакетов, а также количество обработанных HTTP-запросов.
Захват данных. Мы решили представить в нашем наборе данных «полезные» соединения, которые были полностью обработаны, характеризуя только те соединения, которые закрываются корректно с пакетом FIN. Это исключает соединения, перехваченные механизмами защиты от атак, или те, которые превышают время ожидания, или прерываются из-за пакета RST.
Поскольку корректное закрытие само по себе не указывает на «полезное» соединение, мы дополнительно требуем как минимум один успешный HTTP-запрос во время соединения, чтобы отфильтровать из этого анализа idle-соединения или не-HTTP соединения — что интересно, они составляют 11% всех TCP-соединений с Cloudflare, закрывающихся пакетом FIN.
Если вам интересно, мы ранее также писали в блоге о деталях общего механизма логирования Cloudflare и конвейера постобработки.
Визуализация характеристик соединений
Хотя сети по своей природе динамичны и тенденции могут меняться со временем, крупномасштабные паттерны, которые мы наблюдаем в нашей глобальной инфраструктуре, остаются remarkably consistent с течением времени. Хотя наши данные предлагают глобальный взгляд на характеристики соединений, распределения все же могут варьироваться в зависимости от региональных паттернов трафика.
В наших визуализациях мы представляем характеристики с помощью графиков функции кумулятивного распределения (CDF), specifically их эмпирических эквивалентов. CDF особенно полезны для получения макроскопического взгляда на распределение. Они дают четкую картину как обычных, так и экстремальных случаев в одном представлении. Мы используем их на иллюстрациях ниже, чтобы осмыслить крупномасштабные паттерны. Для лучшей интерпретации распределений мы также используем логарифмические оси, чтобы учесть наличие экстремальных значений, обычных для сетевых данных.
Давний вопрос о интернет-соединениях относится к «Слонам и Мышам»; практики и исследователи полностью осознают, что большинство потоков малы, а некоторые огромны, но существует мало данных, чтобы проинформировать о границах, разделяющих их. С этого начинается наша презентация.
Количество пакетов
Давайте начнем с взгляда на распределение количества ответных пакетов, отправленных в соединениях серверами Cloudflare обратно клиентам.
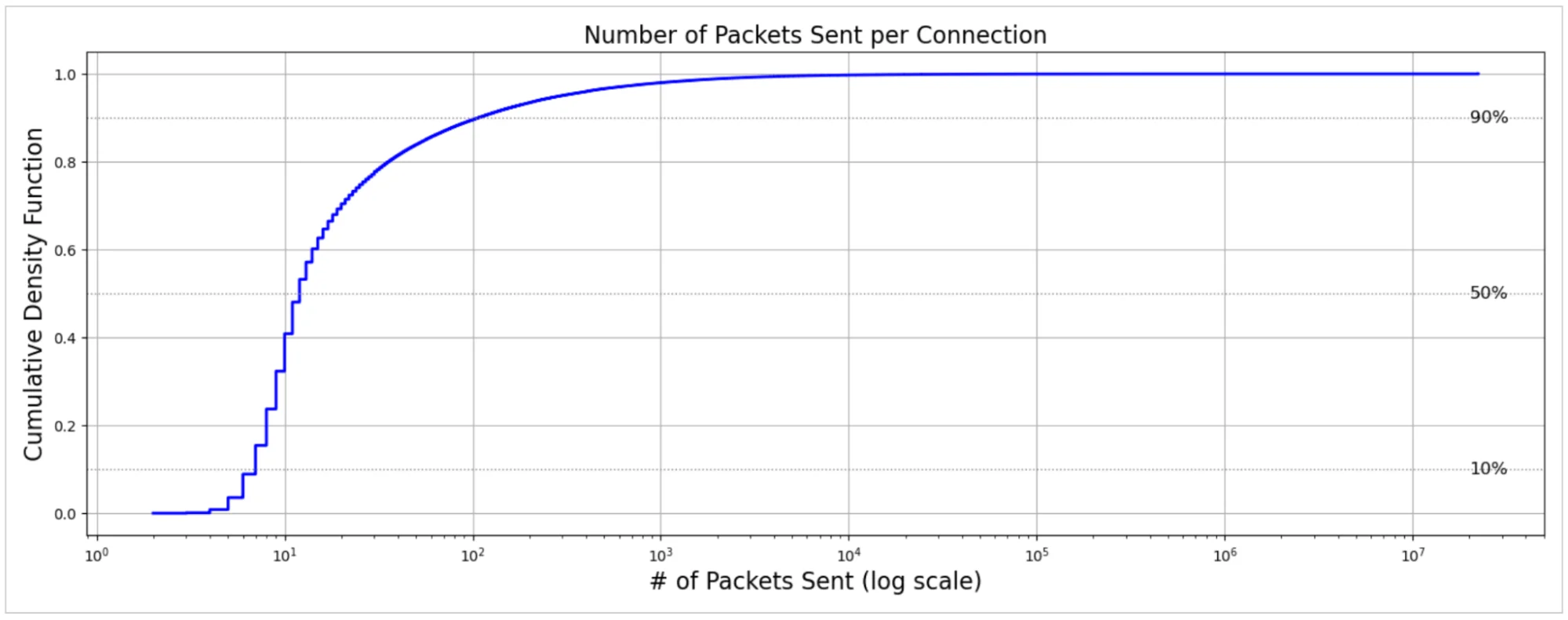
На графике ось X представляет количество отправленных ответных пакетов в логарифмическом масштабе, а ось Y показывает кумулятивную долю соединений ниже каждого количества пакетов. Средний ответ состоит примерно из 240 пакетов, но распределение сильно скошено. Медиана составляет 12 пакетов, что указывает на то, что 50% интернет-соединений состоят из очень малого количества пакетов. Распространяясь далее до 90-го процентиля, соединения переносят только 107 пакетов.
Этот резкий контраст подчеркивает тяжелохвостную природу интернет-трафика: в то время как несколько соединений перевозят огромные объемы данных — как видеопотоки или передачи больших файлов — большинство взаимодействий крошечны, доставляя небольшие веб-объекты, трафик микросервисов или ответы API.
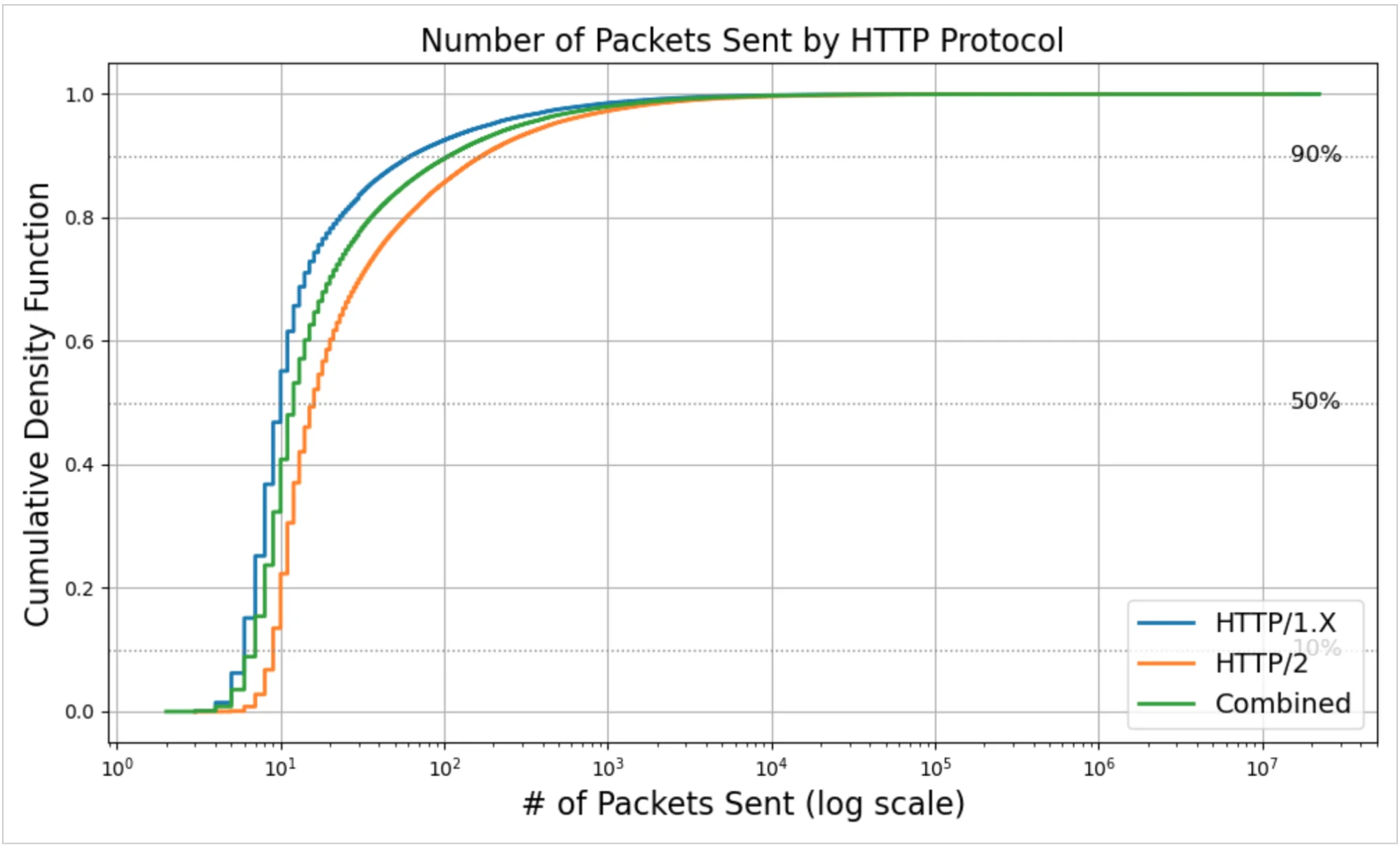
Приведенный выше график разбивает распределение количества пакетов по версии HTTP-протокола. Для соединений HTTP/1.X (как HTTP 1.0, так и 1.1 вместе) медианный ответ состоит всего из 10 пакетов, и 90% соединений переносят менее 63 ответных пакетов. В contrast, соединения HTTP/2 показывают большие ответы, с медианой в 16 пакетов и 90-м процентилем в 170 пакетов. Эта разница, вероятно, отражает то, как HTTP/2 мультиплексирует multiple streams через одно соединение, часто объединяя больше запросов и ответов в меньшее количество соединений, что увеличивает общее количество обмениваемых пакетов на соединение. Соединения HTTP/2 также имеют дополнительные управляющие кадры и сообщения контроля потока, которые увеличивают количество ответных пакетов.
Несмотря на эти различия, объединённое представление демонстрирует ту же тяжёлохвостую закономерность: небольшая доля соединений переносит огромные объёмы данных (слоны), достигающие миллионов пакетов, в то время как большинство остаются лёгкими (мыши).
До сих пор мы фокусировались на общем количестве пакетов, отправленных с наших серверов клиентам, но другим важным аспектом поведения соединения является баланс между отправленными и полученными пакетами, показанный ниже.
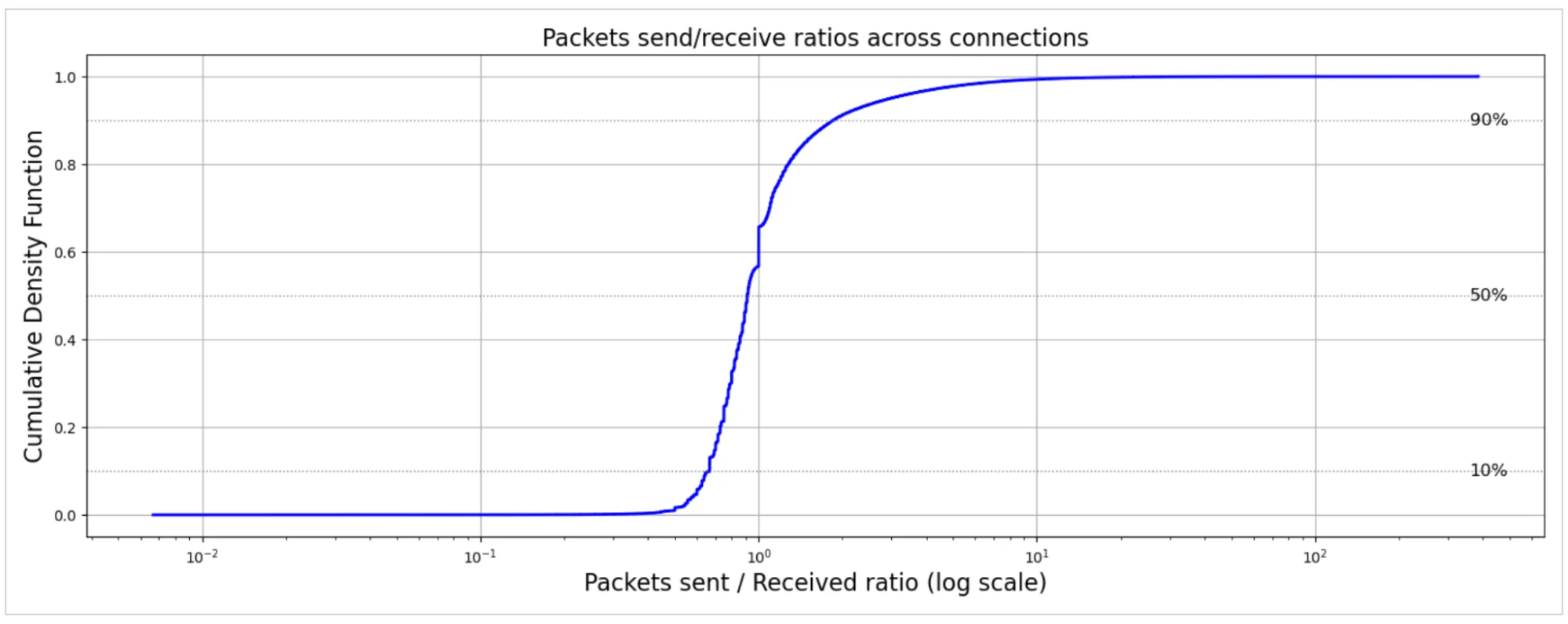
Ось X показывает соотношение пакетов, отправленных нашими серверами, к пакетам, полученным от клиентов, визуализированное как CDF. Для всех соединений медианное соотношение составляет 0,91, что означает, что в половине соединений клиенты отправляют немного больше пакетов, чем сервер отвечает. Этот избыток пакетов на стороне клиента в основном отражает инициацию TLS-рукопожатия (ClientHello), заголовки управляющих HTTP-запросов и подтверждения данных (ACK), что приводит к тому, что клиент обычно передаёт больше пакетов, чем сервер возвращает с полезной нагрузкой контента — особенно для малопакетных соединений, преобладающих в распределении.
Среднее соотношение выше и составляет 1,28 из-за длинного хвоста соединений с преобладанием клиента, таких как крупные загрузки, типичные для рабочих нагрузок CDN. Большинство соединений попадает в относительно узкий диапазон: 10% соединений имеют соотношение ниже 0,67, а 90% — ниже 1,85. Однако тяжёлохвостое поведение подчёркивает разнообразие интернет-трафика: экстремальные значения возникают как от соединений с преобладанием отдачи, так и загрузки. Дисперсия 3,71 отражает эти асимметричные потоки, в то время как основная масса соединений поддерживает примерно сбалансированный обмен отдачей и загрузкой.
Отправленные байты
Другой способ взглянуть на данные — использовать байты, отправленные нашими серверами клиентам, что отражает фактический объём данных, доставленных по каждому соединению. Эта метрика получена из tcpi_bytes_sent, также охватывая полезные нагрузки (ре)переданных сегментов, исключая TCP-заголовок, как определено в linux/tcp.h и согласовано с RFC 4898 (TCP Extended Statistics MIB).
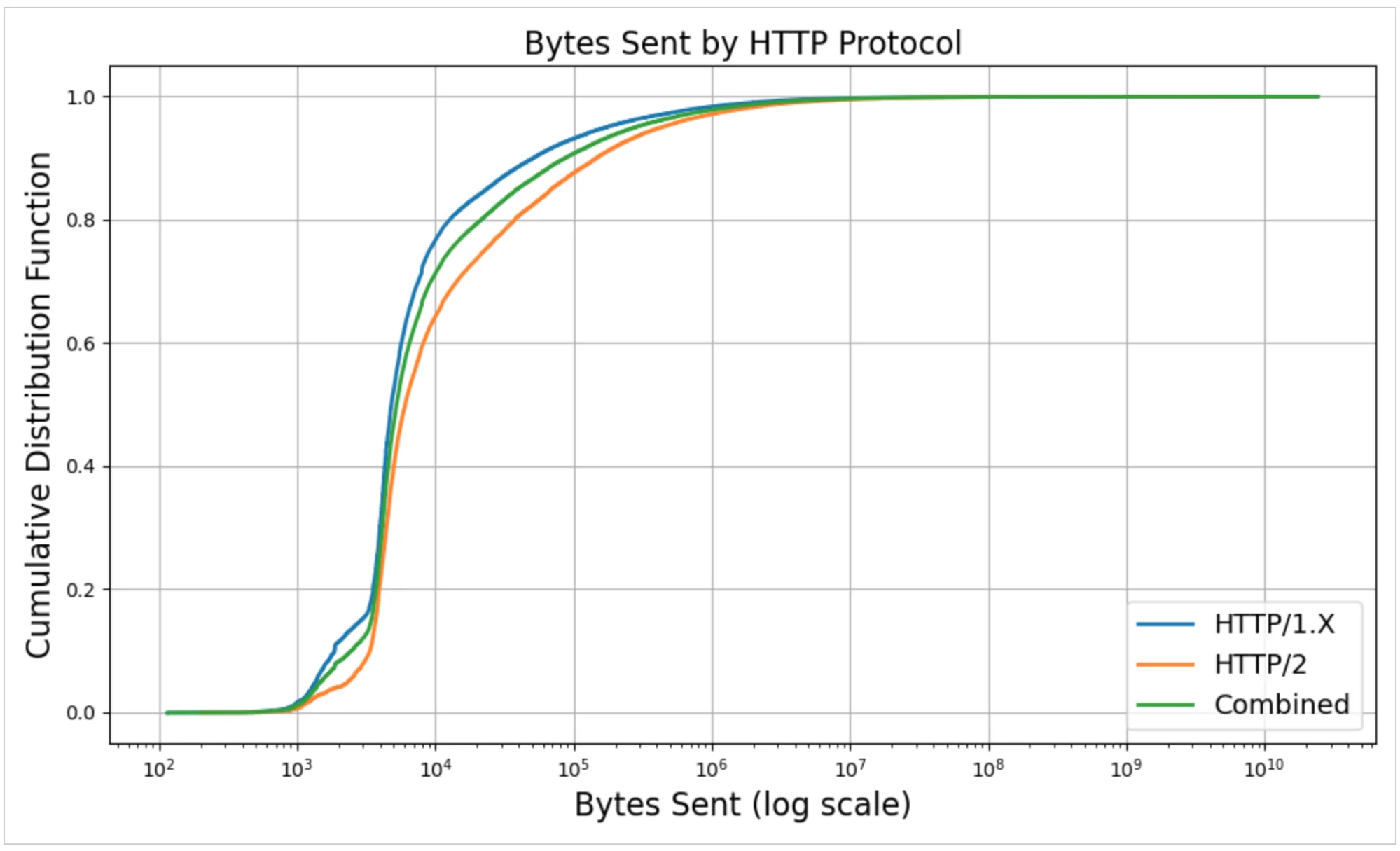
Графики выше разбивают отправленные байты по версии HTTP-протокола. Ось X представляет общее количество байтов, отправленных нашими серверами по каждому соединению. Закономерности в целом согласуются с тем, что мы наблюдали в распределениях количества пакетов.
Для HTTP/1.X медианный ответ доставляет 4,8 КБ, и 90% соединений отправляют менее 51 КБ. Напротив, соединения HTTP/2 показывают немного большие ответы: медиана 6 КБ и 90-й процентиль 146 КБ. Среднее значение намного выше — 224 КБ для HTTP/1.x и 390 КБ для HTTP/2 — что отражает небольшое количество очень крупных передач. Эти экстремальные потоки с длинным хвостом могут достигать десятков гигабайт на соединение, в то время как некоторые очень лёгкие соединения переносят минимальные полезные нагрузки: минимум для HTTP/1.X составляет 115 байт, а для HTTP/2 — 202 байта.
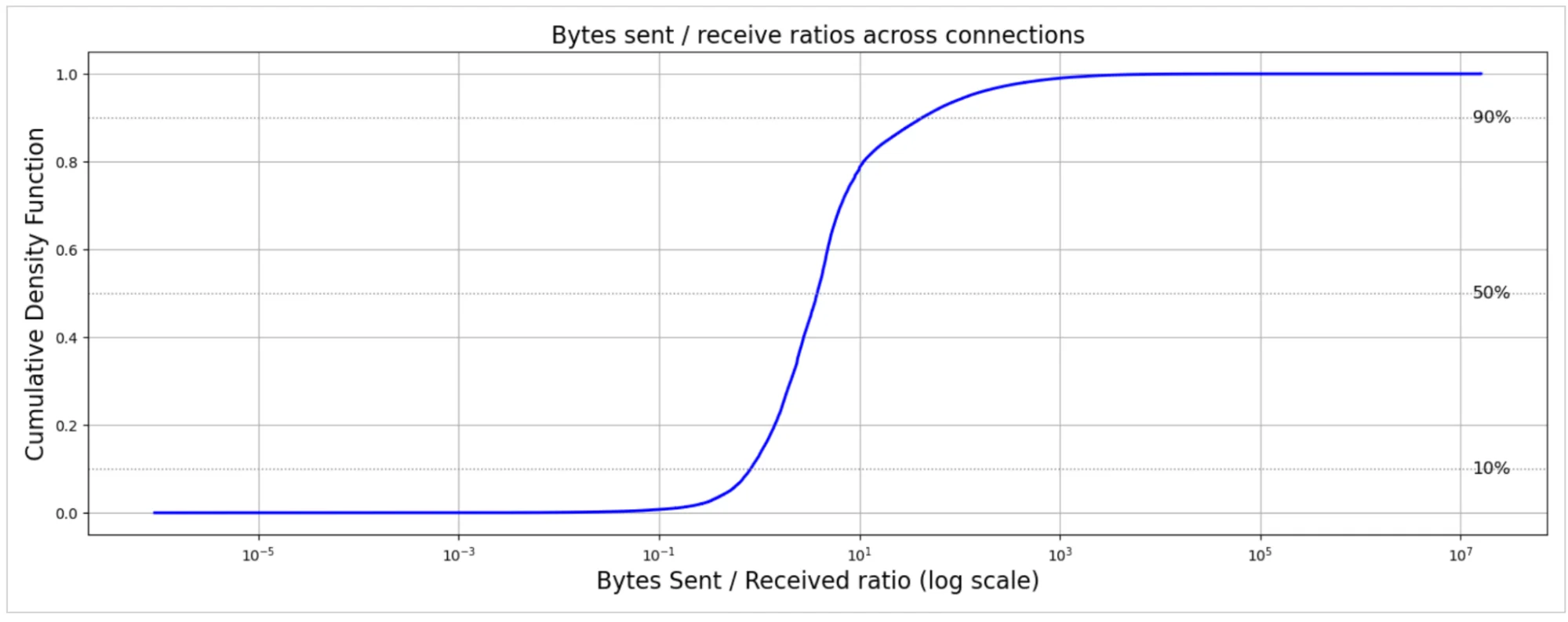
Используя метрику tcpi_bytes_received, мы можем теперь посмотреть на соотношение отправленных к полученным байтам на соединение, чтобы лучше понять баланс обмена данными. Это соотношение отражает, насколько асимметрично каждое соединение — по сути, сколько данных наши серверы отправляют по сравнению с тем, что они получают от клиентов. Для всех соединений медианное соотношение составляет 3,78, что означает, что в половине всех случаев серверы отправляют почти в четыре раза больше данных, чем получают. Среднее значение намного выше — 81,06, показывая сильный длинный хвост, обусловленный потоками с преобладанием загрузки. Снова мы видим тяжёлое распределение с длинным хвостом: небольшая доля экстремальных случаев поднимает соотношение до миллионов, с более экстремальными значениями передачи данных в сторону клиентов.
Длительность соединения
Хотя количество пакетов и байтов отражает объём обмениваемых данных, длительность соединения даёт представление о том, как этот обмен разворачивается во времени.
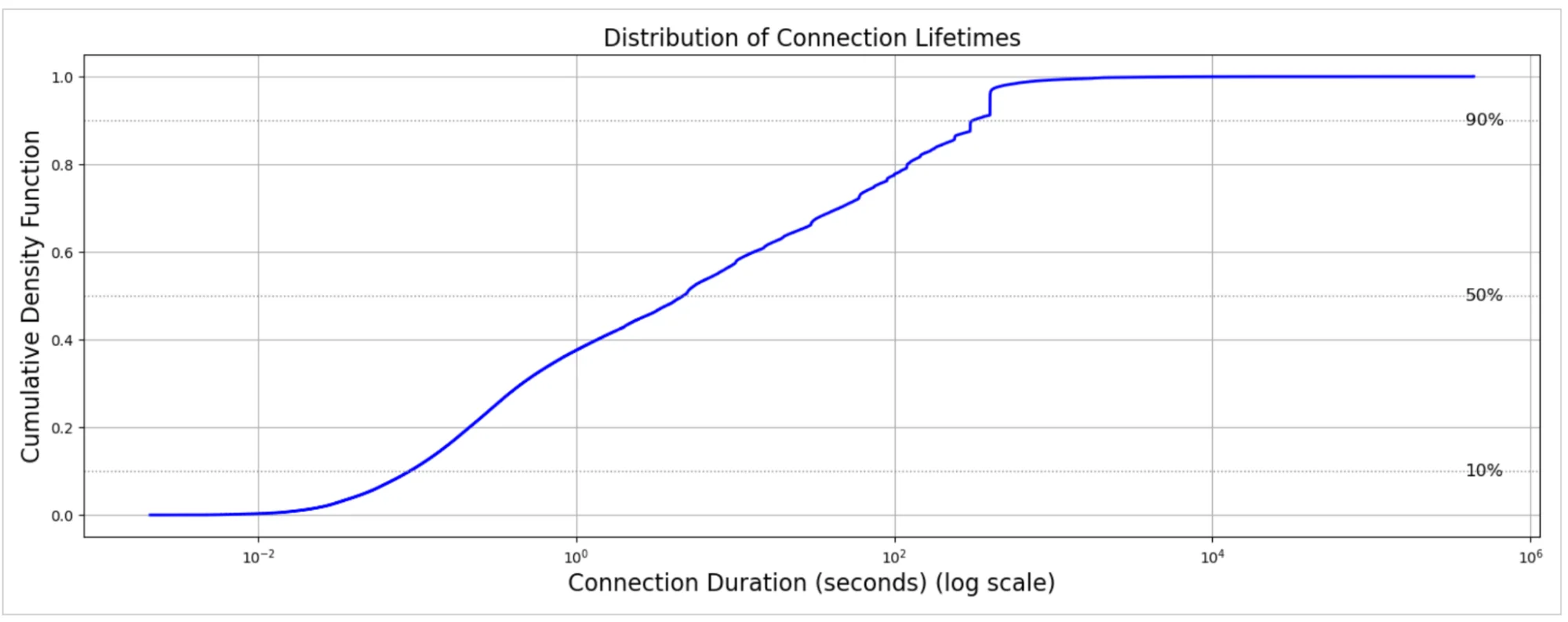
CDF выше показывает распределение длительностей соединений (времени жизни) в секундах. Напоминание: ось X в логарифмическом масштабе. Для всех соединений медианная длительность составляет всего 4,7 секунды, что означает, что половина соединений завершается менее чем за пять секунд. Среднее значение намного выше — 96 секунд, что отражает небольшое количество долгоживущих соединений, которые смещают среднее. Большинство соединений попадает в диапазон от 0,1 секунды (10-й процентиль) до 300 секунд (90-й процентиль). Мы также наблюдаем некоторые чрезвычайно долгоживущие соединения, длящиеся несколько дней, возможно, поддерживаемые через keep-alives для повторного использования соединения без достижения наших лимитов таймаута простоя по умолчанию. Эти долгоживущие соединения обычно представляют постоянные сессии или мультимедийный трафик, в то время как большая часть веб-трафика остаётся короткой, всплесковой и транзитной.
Количество запросов
Одно соединение может переносить несколько HTTP-запросов для веб-трафика. Это раскрывает закономерности мультиплексирования соединений.
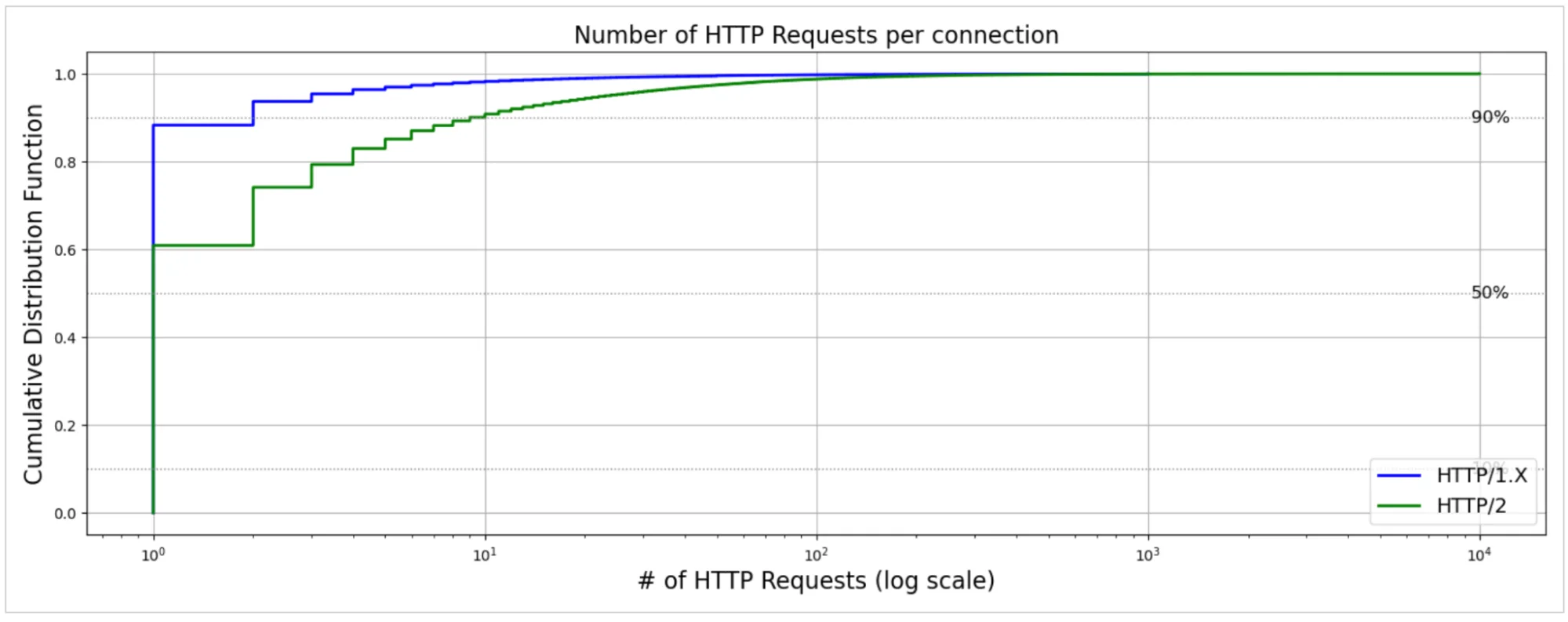
Выше показано количество HTTP-запросов (в логарифмическом масштабе), которое мы видим в одном соединении, разбитое по версии HTTP-протокола. Сразу видно, что для соединений как HTTP/1.X (в среднем 3 запроса), так и HTTP/2 (в среднем 8 запросов) медианное количество запросов составляет всего 1, что подтверждает распространённость ограниченного повторного использования соединений. Однако, поскольку HTTP/2 поддерживает мультиплексирование нескольких потоков поверх одного соединения, 90-й процентиль возрастает до 10 запросов, с occasional экстремальными случаями, несущими тысячи запросов, что может усиливаться из-за объединения соединений (connection coalescing). В отличие от этого, соединения HTTP/1.X имеют гораздо меньшее количество запросов. Это соответствует дизайну протокола: HTTP/1.0 следовал философии «один запрос на соединение», в то время как HTTP/1.1 представил постоянные соединения — даже объединяя обе версии, редко можно увидеть, чтобы соединения HTTP/1.X несли более двух запросов на 90-м процентиле.
Распространённость короткоживущих соединений частично можно объяснить автоматизированными клиентами или скриптами, которые склонны открывать новые соединения, а не поддерживать долгоживущие сессии. Чтобы исследовать эту интуицию, мы разделили данные между трафиком, исходящим из дата-центров (вероятно, автоматизированным), и типичным пользовательским трафиком (инициируемым пользователем), используя ASN клиентов в качестве прокси.
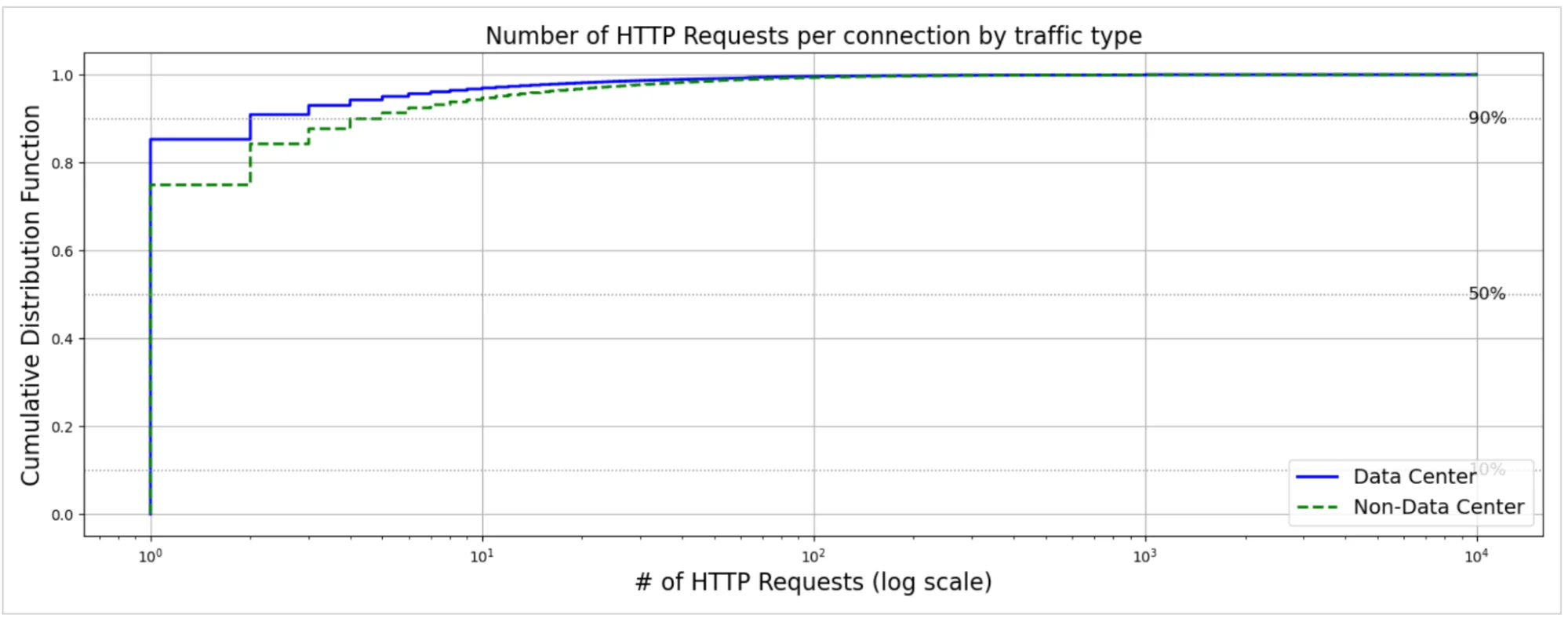
График выше показывает, что трафик не из ДЦ (инициируемый пользователем) имеет немного большее количество запросов на соединение, что согласуется с браузерами или приложениями, получающими несколько ресурсов через одно постоянное соединение, со средним значением 5 запросов и 90-м процентилем 5 запросов на соединение. В отличие от этого, трафик из ДЦ имеет среднее значение примерно 3 запроса и 90-й процентиль 2, что подтверждает наши ожидания. Несмотря на эти различия, медианное количество запросов остаётся 1 для обеих групп, подчёркивая, что независимо от происхождения соединений, большинство из них действительно кратковременны.
Вывод характеристик пути из данных уровня соединения
Измерения на уровне соединения также могут дать представление о характеристиках нижележащего пути. Давайте рассмотрим это подробнее.
Path MTU
Максимальный блок передачи (MTU) вдоль сетевого пути часто называют Path MTU (PMTU). PMTU определяет максимальный размер пакета, который может пройти по соединению без фрагментации или потери, влияя на пропускную способность, эффективность и задержку. Стек TCP Linux на наших серверах отслеживает наибольший размер сегмента, который можно отправить без фрагментации по пути для соединения, как часть обнаружения Path MTU.
Из этих данных мы увидели, что медианный (и 90-й процентиль!) PMTU составлял 1500 байт, что соответствует типичному Ethernet MTU и считается стандартным для большинства интернет-путей. Интересно, что 10-й процентиль находится на отметке 1420 байт, отражая случаи, когда пути включают сетевые каналы с немного меньшими MTU — обычное явление в некоторых VPN, IPv6tov4 туннелях или старом сетевом оборудовании, которое накладывает более строгие ограничения для избежания фрагментации. В крайних случаях мы видели MTU размером всего 552 байта для соединений IPv4, что связано с минимально допустимым значением PMTU в ядре Linux.
Начальное окно перегрузки
Ключевым параметром в транспортных протоколах является окно перегрузки (CWND) — количество пакетов, которые могут быть переданы без ожидания подтверждения от получателя. Мы называем эти пакеты или байты «находящимися в полёте». В ходе соединения окно перегрузки динамически изменяется на протяжении всего подключения.
Однако начальное окно перегрузки (ICWND) в начале передачи данных может оказывать непропорционально большое влияние, особенно для кратковременных соединений, которые, как мы видели выше, преобладают в интернет-трафике. Если ICWND установлено слишком низким, малым и средним передачам потребуются дополнительные круговые задержки для достижения пропускной способности узкого места, что замедлит доставку. И наоборот, если оно установлено слишком высоким, отправитель рискует перегрузить сеть, вызвав ненужные потери пакетов и повторные передачи — потенциально для всех соединений, использующих канал с узким местом.
Разумной оценкой ICWND можно считать размер окна перегрузки в момент, когда отправитель TCP выходит из медленного старта. Этот переход отмечает точку, в которой отправитель переходит от экспоненциального роста к избеганию перегрузок, предположив, что дальнейший рост может рисковать перегрузкой. На рисунке ниже показано распределение размеров окна перегрузки в момент выхода из медленного старта — рассчитанное BBR. Медиана составляет примерно 464 КБ, что соответствует около 310 пакетов на соединение при типичном MTU 1500 байт, в то время как экстремальные потоки переносят десятки мегабайт в полёте. Эта вариативность отражает разнообразие TCP-соединений и динамически развивающуюся природу сетей, передающих трафик.
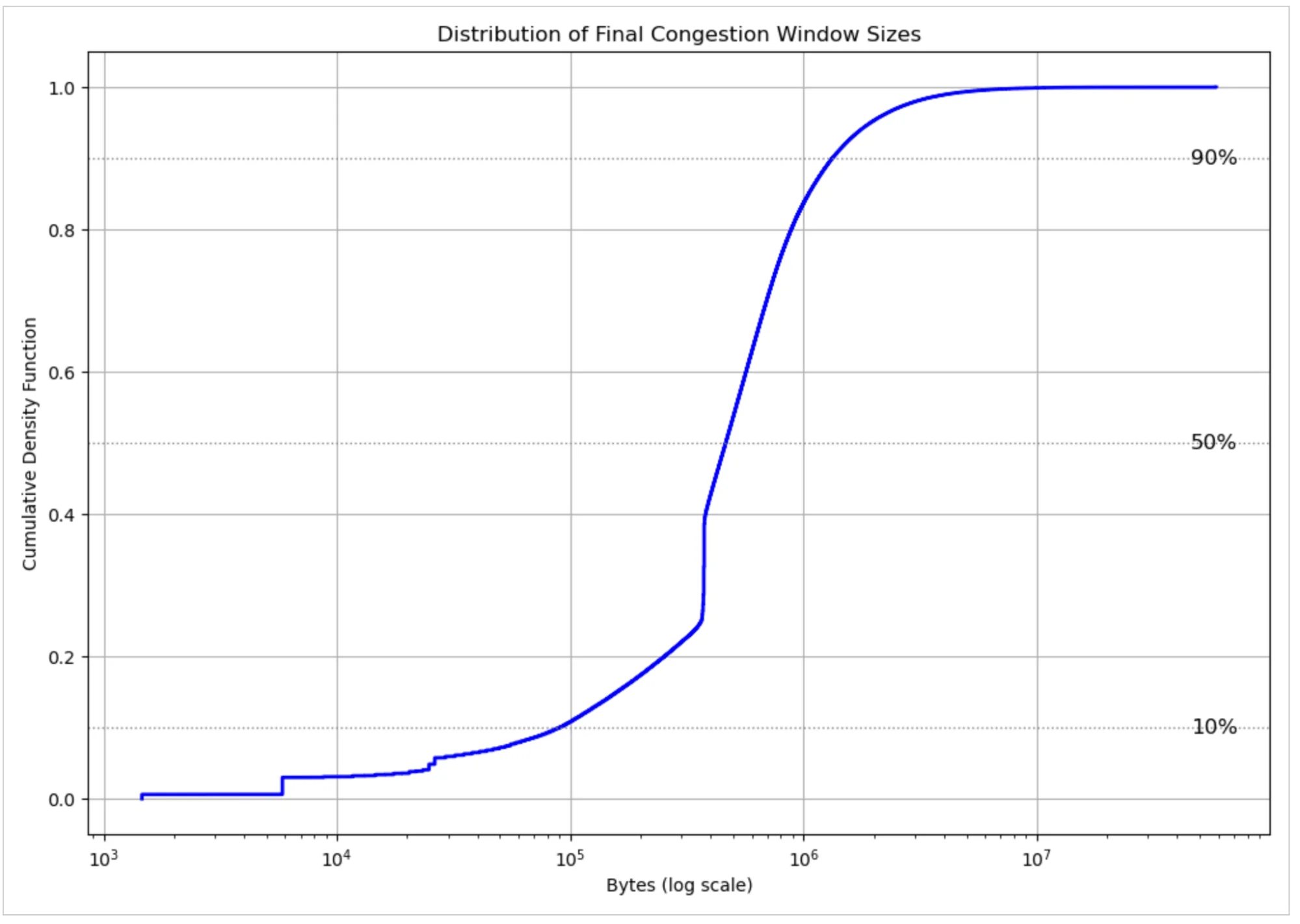
Важно подчеркнуть, что эти значения отражают смесь сетевых путей, включая не только пути между Cloudflare и конечными пользователями, но и между Cloudflare и соседними дата-центрами, которые обычно хорошо обеспечены ресурсами и предлагают более высокую пропускную способность.
Наша первоначальная проверка приведённого распределения вызвала у нас сомнения, поскольку значения кажутся очень высокими. Затем мы поняли, что цифры являются артефактом поведения, специфичного для BBR, при котором он устанавливает окно перегрузки выше, чем его оценка доступной пропускной способности пути — произведения полосы пропускания на задержку (BDP). Завышенное значение предусмотрено конструктивно. Чтобы доказать гипотезу, мы перестроили распределение на рисунке ниже вместе с оценкой BDP от BBR. Разница между окном перегрузки BBR для неподтверждённых пакетов и его оценкой BDP очевидна.
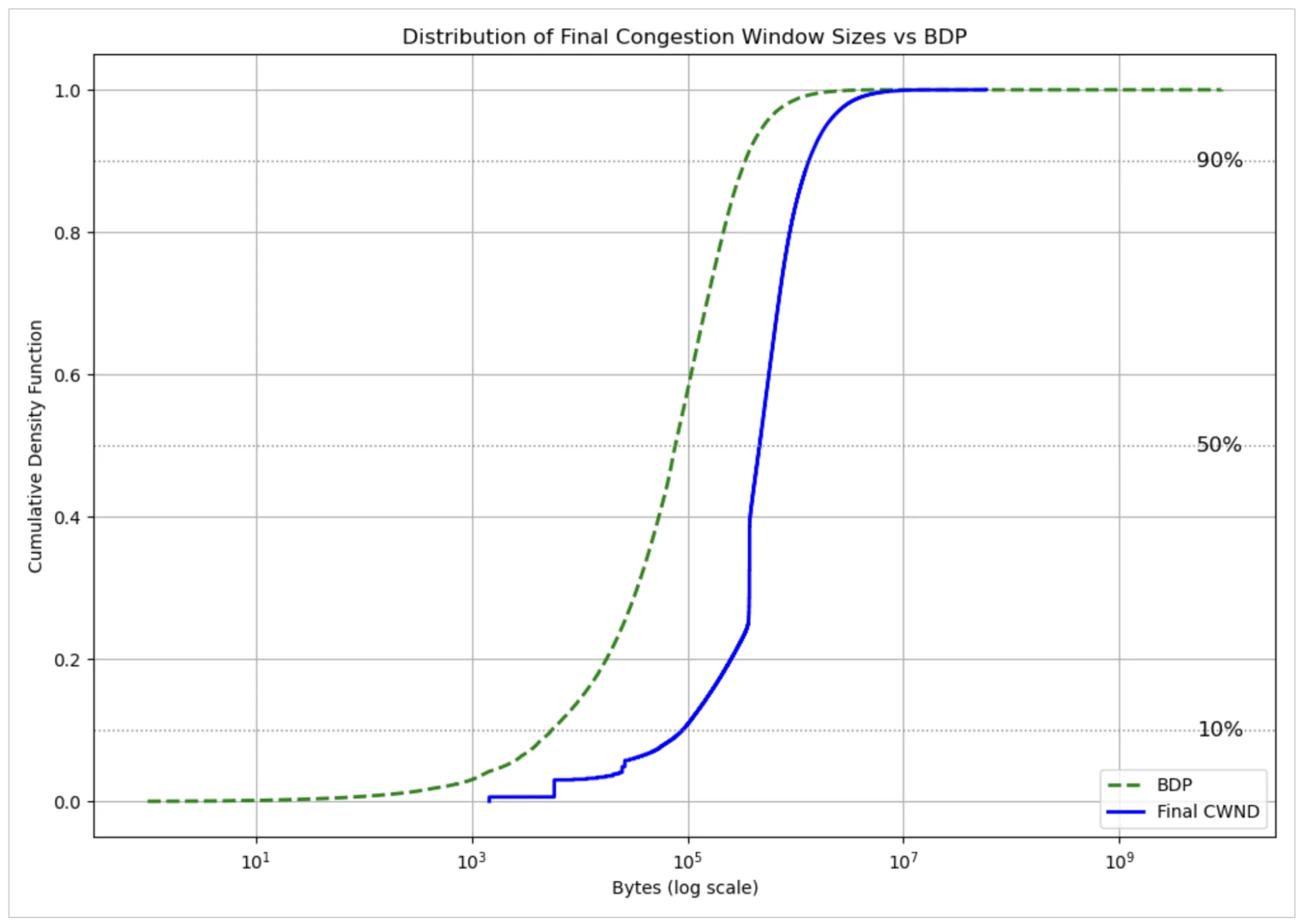
Приведённый график добавляет вычисленные значения BDP в контекст телеметрии соединения. Медианное значение BDP составляет примерно 77 КБ, что соответствует примерно 50 пакетам. Если сравнить это с распределением окна перегрузки, взятым выше, мы видим, что оценки BDP из недавно закрытых соединений гораздо стабильнее.
Мы используем эти данные, чтобы помочь определить разумные размеры начального окна перегрузки и условия для них. Наши внутренние эксперименты ясно показывают, что размеры ICWND могут влиять на производительность до 30-40% для меньших соединений. Такие данные потенциально помогут пересмотреть усилия по поиску лучших значений начального окна перегрузки, которое по умолчанию составляло 10 пакетов на протяжении более десяти лет.
Глубокое понимание, лучшая производительность
Мы наблюдали, что интернет-соединения сильно неоднородны, что подтверждает многолетние наблюдения сильных тяжёлых хвостов, соответствующих феномену «слоны и мыши». Соотношения байтов отдачи к загрузке неудивительны для крупных потоков, но удивительно малы для коротких потоков, подчёркивая асимметричную природу интернет-трафика. Понимание этих характеристик соединений продолжает подсказывать способы улучшения производительности подключения, надёжности и пользовательского опыта.
Мы продолжим развивать эту работу и планируем публиковать статистику на уровне соединений на Cloudflare Radar, чтобы другие также могли извлечь пользу.