Несколько недель назад мы опубликовали наши первоначальные выводы из проекта Glasswing, изучая, что происходит, когда вы направляете передовые модели безопасности на корпоративную кодовую базу. Мы также исследовали, как наши защитные структуры адаптируются для защиты нашей инфраструктуры и клиентов от угроз, исходящих от передового ИИ. С тех пор экосистема ИИ продолжает быстро меняться — разработчики, которые плотно завязали свою работу на одной модели, уже испытали на себе, что происходит, когда эта модель перестает быть доступной или заменяется более мощной. Эти рыночные сдвиги лишь укрепляют наш основной тезис: независимо от того, какая базовая модель лидирует в любой конкретный день, будущее агентных рабочих процессов не будет найдено в отдельных моделях, промптах или сессиях с одним агентом.
Переход от локального навыка безопасности к непрерывному конвейеру сканирования всего парка требует архитектуры, в которой модели рассматриваются как взаимозаменяемые компоненты. Положиться на одну модель по своей сути ограничивает оборонительное покрытие, так как одна и та же система будет склонна рассматривать пути кода через одну и ту же призму. Чтобы противодействовать этому, модели следует часто менять и перекрестно тестировать. Варьируя модели в конвейере — например, используя одну модель для первоначального обнаружения, а совершенно другую для проверки — мы можем гарантировать, что уязвимости перепроверяются разными наборами логики. Кроме того, настоящая инфраструктура корпоративного масштаба должна выходить за рамки изолированных репозиториев, чтобы отслеживать уязвимости в зависимостях между репозиториями, в конечном итоге фильтруя тысячи сырых кандидатов в проверенную очередь исправлений, готовых к действию.
Этот пост представляет собой практический взгляд на то, как построить этот независимый от модели слой, сфокусированный на том, как мы управляем контролем состояния, устраняем ложные срабатывания и координируем сквозную триажу в масштабе.
Два возражения сразу
Первый пост объяснил, почему универсальные агенты для написания кода не справляются с этой задачей. Основная проблема в том, что агенты удерживают только одну гипотезу за раз, заполняют свое контекстное окно после покрытия небольшой части реального репозитория, а затем теряют информацию при сжатии контекста. Подробнее читайте тот пост.
Прежде чем двигаться дальше, мы хотели бы ответить на два вероятных вопроса.
"Почему бы не использовать саб-агентов вместо инфраструктуры?" Саб-агенты полезны, и это хорошая отправная точка. Но для анализа безопасности требуются сотни отдельных исследований, которые сохраняются между запусками, не разделяют контекстное окно и могут быть переопределены и перекрестно сопоставлены позже. Нужны персистентность, дедупликация, возможность возобновления и в конечном итоге отслеживание зависимостей в масштабе парка. Это проблема оркестрации, и промпт не поможет.
"Является ли этот пост в блоге просто рекламой передовых моделей?" Нет. Наш подход сосредоточен на инфраструктуре, а не на модели. Что касается обнаружения уязвимостей, мы запускаем его с любой передовой моделью, которая в данный момент лучше всего подходит для наших нужд. Когда мы направляем разные модели на одну и ту же цель, каждая находит свою долю ошибок. Инфраструктура — это то, что остается. Если вы строите свою собственную систему, проектируйте ее как независимую от модели с самого начала. Это даст вам свободу использовать любую модель по вашему выбору без ограничений.
Все начинается с навыка
Мы начали с навыка security-audit объемом около 450 строк, который запускали на одном репозитории, и корректировали промпты, пока не обнаружили реальные ошибки. Позже мы добавили оркестрацию, которая стала основой всей системы. Реальная ценность заключается в самих промптах, и наши промпты по-прежнему несут в себе сценарии атак, классы ошибок и обнаружение антипаттернов из первоначального навыка почти без изменений.
Навык был написан для выполнения 7-фазного аудита за одну сессию:
-
Три параллельных исследовательских агента проводят разведку и пишут
architecture.md. -
Один агент Hunter запускается для каждого класса атак, пытаясь взломать код, а не проверить его.
-
Состязательные валидаторы пытаются опровергнуть каждую находку.
-
Оставшиеся находки оформляются в виде отчета об уязвимостях, читаемого человеком.
-
Они также выводятся в виде
findings.jsonв соответствии со схемой, и механическая проверка проверяет этот файл. -
Наконец, новый агент независимо повторно проверяет каждую находку по исходному коду.
-
Выжившие после повторной проверки находки отправляются в API приема.
Этот первый навык почти напрямую отображается на более позднюю инфраструктуру:
|
Фаза навыка |
Этап инфраструктуры |
|---|---|
|
Агенты разведки пишут |
Разведка |
|
Хантеры запускаются для каждого класса атак |
Охота |
|
Валидаторы опровергают находки |
Валидация |
|
Выжившие находки становятся отчетом |
Отчет |
|
|
Механическая проверка номеров строк и функций в находках |
|
Новый агент повторно проверяет находки |
Независимая валидация |
Навык работал, но быстро показал свои ограничения. Судя по метрикам покрытия, один запуск находит лишь около половины ошибок, которые вы бы поймали при нескольких запусках. По нашему опыту, найденные ошибки были скорее более простыми и менее тонкими. Как только ваш процесс сводится к «запустить десять раз и сравнить вручную», вероятно, пора задуматься о настоящей инфраструктуре.
В процессе запуска и тонкой настройки навыка мы столкнулись с тремя стенами:
-
Исчерпание контекста: Через час контекстное окно заполняется, и модель начинает каннибализировать собственную память, мгновенно забывая ошибки, которые она отслеживала все утро. Мы решили эту проблему, полностью вынеся состояние наружу, рассматривая LLM как статический вычислительный движок.
-
Персистентность: Сбой в середине запуска означает начало заново. Потеря часов работы из-за одной ошибки лимита скорости ИИ или нестабильности соединения — это невероятно дорогой способ осознать, что вам нужна лучшая архитектура.
-
Рассуждение между репозиториями: Сессия в одном репозитории полностью слепа к связям между приложениями, которые его потребляют, и количество ошибок, которые всплывают при проверке интерфейса между компонентами, вероятно, больше, чем можно ожидать.
СОВЕТ: Реальная, но минимальная инфраструктура состоит только из этапов Разведки, Охоты и Валидации, хранящихся в базе данных, а также отдельного Валидатора, который не может сам добавлять находки. Следует полностью пропустить отслеживание межрепозиторных зависимостей, пока у вас нет более одного репозитория, который имеет значение. Пропустите выделенного агента дедупликации, пока вы активно не тонете в шуме. Начните с навыка в вашей среде разработки, добейтесь хорошей работы промптов и стройте следующий архитектурный этап только тогда, когда его отсутствие является конкретной причиной замедления.
Кодификация навыка в конвейер
Большинство статей по безопасности ИИ в этой области посвящены одному репозиторию или курируемому бенчмарку; запуск целого парка таким образом с отслеживанием межрепозиторных зависимостей — это то, с чем мы не сталкивались в других публикациях. Наша кодовая база включает в себя огромное смешение языков — Rust, Go, C, Lua, TypeScript и Python, наряду с различными системами управления конфигурацией, статическими конфигами и всевозможным дополнительным контекстом. Поэтому нам пришлось придумать что-то новое, что работало бы для нас. Переход от первого запуска с косой черты к сканеру парка, способному покрыть 128 отдельных репозиториев, автоматически находя и опрашивая соответствующие зависимости, занял около шести недель. Кодификация была в основном механической: мы перенесли каждую фазу навыка в собственного агента, поместили за ним базу данных, а перед ним — оркестратор. Отображение было почти один к одному.
Весь парк работает на единой инфраструктуре без подстройки под конкретный язык и отслеживает зависимости между репозиториями. Хотя выгрузка синтаксиса на модель делает систему независимой от языка, отличительной чертой является способность отслеживать зависимости между репозиториями. Инфраструктуре все равно, смотрит ли она на указатели C или файл TypeScript; она фокусируется на логике более высокого уровня оркестрации безопасности. Это позволяет нам масштабироваться на сотни различных кодовых баз без необходимости писать собственный разбор языка.
Двухэтапный рабочий процесс исследования уязвимостей
Весь наш рабочий процесс исследования уязвимостей построен на двухэтапной операционной структуре: Инфраструктура обнаружения уязвимостей (VDH) и Система валидации уязвимостей (VVS).
VDH функционирует как наш двигатель обнаружения, активно сканируя кодовые базы для выявления потенциальных проблем безопасности. Когда ошибки попадают в VVS, которая позволяет нескольким инфраструктурам подавать в нее данные, они проходят стадии Дедупликации, Оценки и, наконец, Исправления, как мы обсудим позже.
Мы используем одну модель для VDH, но совершенно другую для VVS, поэтому модели по сути перепроверяют друг друга. В этом очевидное преимущество в безопасности: заставляя модель B (VVS) оценивать выходные данные модели A (VDH), вы гарантируете, что результат оценивается совершенно другим набором логических весов и обучающих данных — тем, который выступает в роли беспристрастной, состязательной третьей стороны, единственная задача которой — беспощадно проверять на прочность допущения модели A. А с операционной точки зрения мы выигрываем от того, что относимся к поставщикам моделей как к взаимозаменяемым товарам. Поставщики моделей могут со временем менять температуру, кэширование и бюджет вычислительных усилий, даже в рамках одной версии модели. Вместо того чтобы строить систему, зависящую от предсказуемого поведения модели с течением времени, наша платформа спроектирована так, чтобы поглощать нисходящую волатильность, не ломаясь.
Этап 1: Оснастка для обнаружения уязвимостей (VDH)
Первая статья рассказывала о том, для чего нужен каждый агент/этап, поэтому мы обсудим то, чего там не было: связующее звено между этапами и те немногие детали, от которых зависит, сработает ли это вообще.
|
Агент/этап |
Основная роль |
Подагенты / Инструменты |
|---|---|---|
|
Разведка |
Составляет карту целевой архитектуры и выявляет потенциальные векторы угроз |
3 параллельных подагента разведки пишут |
|
Охота |
Запускает атаки по классам, компилирует фрагменты, исследует бинарники |
Порождает «братские» подагенты (они обрабатывают от 9% до 20% задач по всему парку в зависимости от модели). Обращается к инструменту «Список желаний» и пишет в него. |
|
Валидация |
Механически проверяет находку, затем опровергает её в состязательном режиме |
Выполняется в два прохода: обычный код выполняет начальные проверки схемы и путей, затем один изолированный агент пытается опровергнуть находку, прежде чем она будет зарегистрирована. |
|
Заполнение пробелов |
Генерирует новые задачи для охоты в незаполненных ячейках покрытия |
Ставит в очередь новые задачи охоты для любых недостаточно протестированных (область × класс атаки) ячеек, которые всё ещё выглядят слабыми |
|
Дедупликация |
Выявляет и объединяет пересекающиеся находки |
Комбинирует детерминированный код и агентов для группировки находок по первопричине, объединяя их в реальном времени |
|
Трассировка |
Обходит граф зависимостей; порождает задачи в репозиториях-потребителях |
Обходит граф, чтобы добавить задачи охоты в каждый выявленный репозиторий-потребитель, гарантируя выявление кросс-репозиторных ошибок |
|
Обратная связь |
Учится на существующих отчётах и оптимизирует будущие запуски |
Забирает сведения о неудачной валидации, поверхностных прогонах и повторных пропусках и мгновенно переписывает поставленные в очередь запросы, чтобы сделать будущие задачи более точными. |
|
Отчёт |
Формирует отчёт, читаемый человеком |
Просто скрипт, модель не требуется |
Таблица 1: Оснастка для обнаружения уязвимостей (VDH)
Этапы с четвёртого по восьмой работают как непрерывный цикл «производитель-потребитель». По мере развития начальной охоты агенты Заполнения пробелов, Обратной связи и Трассировки генерируют новые задачи; Дедупликация объединяет пересекающиеся находки, а остальная часть цикла продолжает потреблять очередь. Это гарантирует, что уязвимость, обнаруженная в конце цикла, всё равно будет проверена, зарегистрирована и сопоставлена с другим кодом, чтобы убедиться, что он не содержит ту же ошибку, — и всё это в рамках одного запуска.
Разделение конвейера таким образом обеспечивает строгий контроль контекста. Если окно контекста заполнено, модель начинает галлюцинировать. Мы держим задачу каждого агента максимально сфокусированной, не допуская использования контекста более чем на 25% от общего окна. Наивный подход «прочитать все файлы» каждый раз будет превышать этот лимит.
Одна вещь, которая нас подвела, заключается в том, что сохраняемость нужно обеспечивать до распараллеливания. Вы не хотите выбрасывать пятичасовой прогон из-за непредвиденной ошибки. Каждый этап пишет в одну базу данных SQLite с ключом (run_id, repo, stage). Любой этап может возобновиться, повторить попытку или быть включённым в более поздний запуск без повторного выполнения работы. Находки передаются потоком и сохраняются по мере возникновения, так что при сбое теряется только выполняемая задача и ничего больше.
СОВЕТ: Иногда временная ошибка API возвращается в виде текста в потоке ответа с кодом (200 OK) вместо того, чтобы вызвать исключение в коде. Для оркестратора это выглядит как задача, выполненная без ошибок. Вы должны явно классифицировать текст ответа, а не просто доверять типу исключения, иначе вы в конечном итоге будете логировать пустые прогоны как успешные.
Динамическое моделирование угроз
На этапе Разведки агент сам пишет модель угроз, а не получает её готовой. Помимо примерно десяти встроенных классов атак (многочисленные формы инъекций, повреждение памяти, разбор протоколов, временные побочные каналы и другие), агент Разведки может на ходу придумывать специфичные для репозитория классы, каждый со своей методологией. Он пишет собственную таксономию, адаптированную специально под эту кодовую базу, которая используется для более точного ограничения области действий агентов Охоты.
Чтения исходного кода недостаточно, чтобы понять, как он ведёт себя под нагрузкой, особенно для тонких ошибок неопределённого поведения в C и других низкоуровневых языках. Агенты Охоты переходят от чтения кода к активному выполнению. Они компилируют фрагменты, собирают небольшие версии и атакуют их. Самый большой скачок в качестве произошёл после того, как мы дали Охотникам песочницу (построенную на unshare) для аварийного завершения бинарников.
СОВЕТ: Если сама оснастка работает внутри Docker, этой песочнице потребуется seccomp=unconfined и apparmor=unconfined, иначе она молча не запустится. Это одноразовое исправление, которое сэкономит вам день головной боли, если вы, как и мы, не являетесь экспертом во вложенной контейнеризации.
Микро-форки и список желаний
Помимо основных этапов конвейера, мы добавили два специализированных механизма, которые предоставляют Охотникам значительную автономию для адаптации фокуса и запроса внешних ресурсов, не отвлекаясь от текущего анализа:
Создание «братских» процессов (Sibling Forking): Это помогает гарантировать, что если агент Охоты наткнётся на интересный путь в коде, выходящий за рамки текущей области, он не уйдёт в сторону. Он использует вызов инструмента для создания «братского» агента с точной структурной затравкой. В масштабах парка на это приходится примерно 9% задач, хотя доля сильно зависит от модели — от почти нуля до примерно одной пятой, в зависимости от того, какая модель охотится.
Список желаний: Когда агенту нужен инструмент, которого у него нет (часто это Валидатор, подтверждающий доказательство концепции (PoC), или Охотник, желающий что-то построить, например, конкретную среду сборки, виртуальную машину или некоторые производственные конфиги), он пишет в центральный список желаний. Он предоставляет достаточно контекста, чтобы система могла автоматически перезапустить эту задачу, как только человек предоставит зависимость. Некоторые из них могут быть частично самовосстанавливающимися: если контейнер нужно пересобрать с некоторыми изменениями, это может произойти автономно после запуска с помощью универсальной оснастки для кодирования, которая мониторит логи.
С момента добавления списка желаний в него было записано 25 472 раза в 128 репозиториях, и это основной способ, которым агенты общаются с нами. Одна запись, которая попала туда, пока мы писали этот текст: «Мне нужна виртуальная машина FreeBSD, чтобы подтвердить это доказательство концепции от начала до конца».
Кросс-репозиторная трассировка по всему парку
После начальной очистки агент Трассировки проверяет, как связаны различные программные компоненты. Он ищет конкретный путь: может ли потенциальный злоумышленник отправить вредоносные входные данные извне в уязвимую часть системы? Если ответ да, агент Трассировки автоматически порождает новые задачи охоты внутри репозитория-потребителя. Чтобы это работало, нужен единый кросс-репозиторный индекс символов и точный граф зависимостей. Это позволяет выявлять глубокие, системные изъяны, которые стандартное сканирование одного репозитория пропустило бы.
Запуск нашей оснастки на всём парке репозиториев выявил два урока, которые проявились только при выполнении в таком масштабе.
Во-первых, дедупликация сама по себе является отдельной проблемой, достаточно большой, чтобы потребовать собственных агентов. Когда вы сканируете горстку репозиториев, вы можете вручную просматривать пересекающиеся ошибки. Простое сопоставление строк или проверка путей к файлам здесь не помогут. Определить, являются ли две сложные логические ошибки на самом деле одной и той же коренной ошибкой, звучит тривиально, но это не так. Это требует настолько большого объёма когнитивных рассуждений, что нам пришлось развернуть выделенных агентов Дедупликации только для очистки шума, а также их собственные эвристики и способы сокращения работы.
Во-вторых, не подключайте статический анализ слишком рано. Мы протащили Semgrep через весь конвейер, и Охотники вызывали его ноль раз за месяц прогонов. Они предпочитали читать и запускать код. Список желаний, напротив, был самым используемым инструментом в системе. Стоит обращать внимание на то, за что агенты действительно тянутся, а не на то, что, по вашему мнению, им понадобится.
Создание находок, которым можно доверять
Агент отредактирует исходный код так, чтобы его собственный эксплойт сработал, а затем триумфально сообщит об ошибке, которую только что создал. Он напишет тест, доказывающий нечто совершенно тавтологическое, например: «exec() выполняет вещи, следовательно, критическая уязвимость». Или создаст эксплойт, который работает нормально, но ничего не доказывает, потому что стоящая за ним модель угроз бессмысленна. Если ваша тестовая обвязка активно не борется с этим, вы создали лишь более быстрый способ производить мусор.
Охотник должен указать модель угроз, прежде чем ему будет разрешено что-либо регистрировать. Он должен точно определить, кто является атакующим, какую границу пересекает уязвимость или какое допущение она нарушает. Порядок выходной схемы обеспечивает это. Это требование устраняет пустые находки, типа «если пользователь имеет доступ на запись к базе данных, он может писать в базу данных».
Каждая подтверждённая находка поставляется с PoC, написанным в виде теста, который выполняется на оригинальной, нетронутой кодовой базе. Это предотвращает редактирование исходных файлов агентом для принудительного срабатывания эксплойта. Если работающего PoC нет, мы считаем находку поддельной. На практике это Охотник, компилирующий тридцатистрочный цикл разбора, запускающий его с включённой защитой памяти и демонстрирующий, что неправильный шаг чтения исходит из стекового адреса, а не из ожидаемого тела сообщения. Вы можете запустить это сами. Кроме того, каждая подтверждённая находка должна также содержать предлагаемый патч. В нашу очередь ревью фактически попадает проверенная ошибка, работающий тест и функциональный git-дифф, а не просто расплывчатое текстовое описание проблемы.
Прежде чем путь эксплойта выживет, детерминированный код (написанный на обычном коде, а не другой моделью) механически проверяет, действительно ли существуют указанные файлы и пути, и подтверждает, что и патч, и тест правильно парсятся. Этот Валидатор не может регистрировать собственные находки; его единственная задача — агрессивно опровергать теорию Охотника. Если Охотнику позволено оценивать свою собственную работу, он будет уверенно валидировать всё, что выводит.
Мы не заявляем показатель ложноотрицательных результатов для нашей системы. Не существует размеченного набора всех реальных ошибок в кодовой базе, поэтому любое заявленное значение полноты является полностью спекулятивным. Что мы можем наблюдать, так это то, продолжают ли повторные запуски находить новые ошибки (они находят) и растёт ли покрытие между запусками. Всё это лишь прокси, поскольку вы точно не знаете, сколько ошибок существует в одной кодовой базе, но это достаточно хороший способ измерения эффективности.
Этап 2: Система валидации уязвимостей (VVS)
Находка, выходящая из тестовой обвязки, — это лишь начало процесса триажа, причём все обнаружения попадают в единую общую VVS, которая в настоящее время содержит 13 841 находку по 145 репозиториям в общей сложности. Триаж такого объёма сам по себе является огромной инженерной задачей, и он важен не меньше, чем охота. Этот механизм триажа работает на другой модели, нежели тестовая обвязка, и разбит на три различные задачи.
|
Агент/этап |
Основная роль |
Порождает/ под-агенты/инструменты |
|---|---|---|
|
Дедупликация |
Определяет, есть ли уязвимость уже в системе или уже заведена как внутренний тикет Jira |
Детерминированный: обычный код строит инвертированные индексы по файлам, функциям, границам доверия и редким токенам, затем каждой находке выдаётся короткий список кандидатов Вероятностный: агент Дедупликации анализирует этот короткий список, стабильный кросс-запусковый ключ повторно открывает существующие записи |
|
Оценка |
Производственная достижимость и валидация |
Одиночный агент — строит контекст об ошибке с помощью MCP-серверов, чтобы понять, как сервис выглядит в продакшене. Ищет в вики, Jira, git, конфигах и всех доступных других источниках, чтобы попытаться понять, действительно ли ошибка применима к нашей производственной среде, и затем оценивает уязвимость относительно этого. Также валидирует ошибку в исходном коде, чтобы понять, существует ли ошибка всё ещё в последней ветке main. |
|
Исправление |
Генерирует патчи, запускает регрессионные тесты |
Запускает регрессионный тест до и после (отфильтрованный по затронутому тесту; полный набор только если фильтрация по тесту недоступна). Требуется чистый переход fail→pass для целевого теста, чтобы пройти ворота. Если пост-патчевый тест падает, или если глобальный запуск обнаруживает нисходящие регрессии, коммит автоматически блокируется и помечается для вмешательства человека. |
Таблица 2: Система валидации уязвимостей (VVS)
Дедупликация
Сравнение каждой находки с каждой другой находкой с помощью LLM масштабируется как O(N^2), что полностью разрушается при масштабировании. Чтобы убрать модель с критического пути, детерминированный код строит инвертированные индексы по структурированным данным (затронутые файлы/функции, граница доверия, редкие токены) для генерации короткого списка реальных кандидатов. Только затем агент смотрит на этот короткий список, чтобы определить, может ли одно исправление закрыть несколько находок. Стабильные кросс-запусковые ключи гарантируют, что повторно найденные ошибки открывают существующие записи, а не создают новые.
Контекстная оценка
Оценка — это второй, независимый проход по тому, что выжило. Агент перепроверяет последнюю информацию, извлекая данные из контекста развёртывания, окружения и конфигурации, чтобы определить, достижим ли путь кода в продакшене, и определить владельца репозитория. Этот процесс фильтрует «эксплуатируемое сейчас» от «реального, но скрытого» и от «реального, но заведённого не на тот компонент». Это превращает кучу хаотичных находок в управляемый рисками оркестрационный рабочий процесс.
Автоматическое исправление
Исправитель берёт предложенный патч и модульные тесты, переписывает их в соответствии со стилем репозитория, применяет дифф и запускает целевые тесты. Чистый переход fail→pass является идеальным и единственным случаем для автоматической очистки; падающий пост-патчевый тест блокирует коммит. Исправитель никогда не сливает код самостоятельно; человек должен просмотреть ветку. Этот шлюз является обязательным барьером безопасности с участием человека, который обеспечивает чистый, нерушимый криптографический след для соблюдения требований управления изменениями. Если модели позволить патчить свободно, она с радостью исправит ошибку безопасности, незаметно сломав несвязанную функцию или добавив десятки новых ошибок.
Во всех трёх задачах триажа каждый агент ограничен одной узкой задачей, обёрнутой в детерминированный учётный код, и ничто не записывается в продакшен без подписи человека на основе пробного запуска. Хотя этот конвейер перемещает инженерное узкое место от поиска ошибок к ревью и внедрению исправлений, Исправитель остаётся самой молодой и медленной частью системы.
Сколько это стоит
Запуск сотен агентов на парке репозиториев — это недёшево, но по крайней мере структура расходов предсказуема. Почти весь вычислительный бюджет уходит непосредственно на этап охоты. Это делает Gapfill нашим рычагом затрат на покрытие, так как каждый дополнительный проход стоит примерно вдвое меньше, чем первоначальная охота.
Поскольку стоимость на репозиторий сильно варьируется, мы выделяем бюджет на репозиторий, а не на запуск. Мы устанавливаем строгий лимит задач на репозиторий и запускаем пул воркеров от 50 до 200 воркеров. Таким образом, вы можете тратить деньги на репозитории, которые действительно что-то находят, и не тратить их на те, которые не находят.
Именно поэтому для нас крупные сканирования — это периодическая зачистка бэклога, а не проверка на каждый PR. Полное сканирование сложного репозитория может занять часы; худший запуск занял чуть более 14 часов. Более дешёвые и меньшие тестовые обвязки — правильный инструмент для этой работы.
Как мы определяем, что это работает
Мы измеряем эффективность нашей системы, отслеживая, насколько эффективно наш автоматизированный конвейер фильтрует преднамеренный инженерный шум в высококачественные, применимые находки. Поскольку мы намеренно настраиваем наших Охотников на чрезмерное сообщение о тонких примитивах, которые могут быть объединены в более крупные атаки, нашим истинным индикатором успеха является то, насколько резко мы можем очистить эту первоначальную гору сырых данных, прежде чем они вообще дойдут до человека.
Чтобы оценить это, мы отслеживаем, сколько именно сырых находок выживает на каждом этапе валидации с течением времени. Благодаря лучшей инъекции контекста на этапе разведки наш начальный уровень отклонения при валидации снизился с 40% до 11%, в то время как доля высокоинтегритетных находок выросла с 35% до 58% (что составляет ~12 057 находок за всё время).
Вот разбивка за всё время: от сырых кандидатов до применимых находок на момент написания этой статьи в блоге.
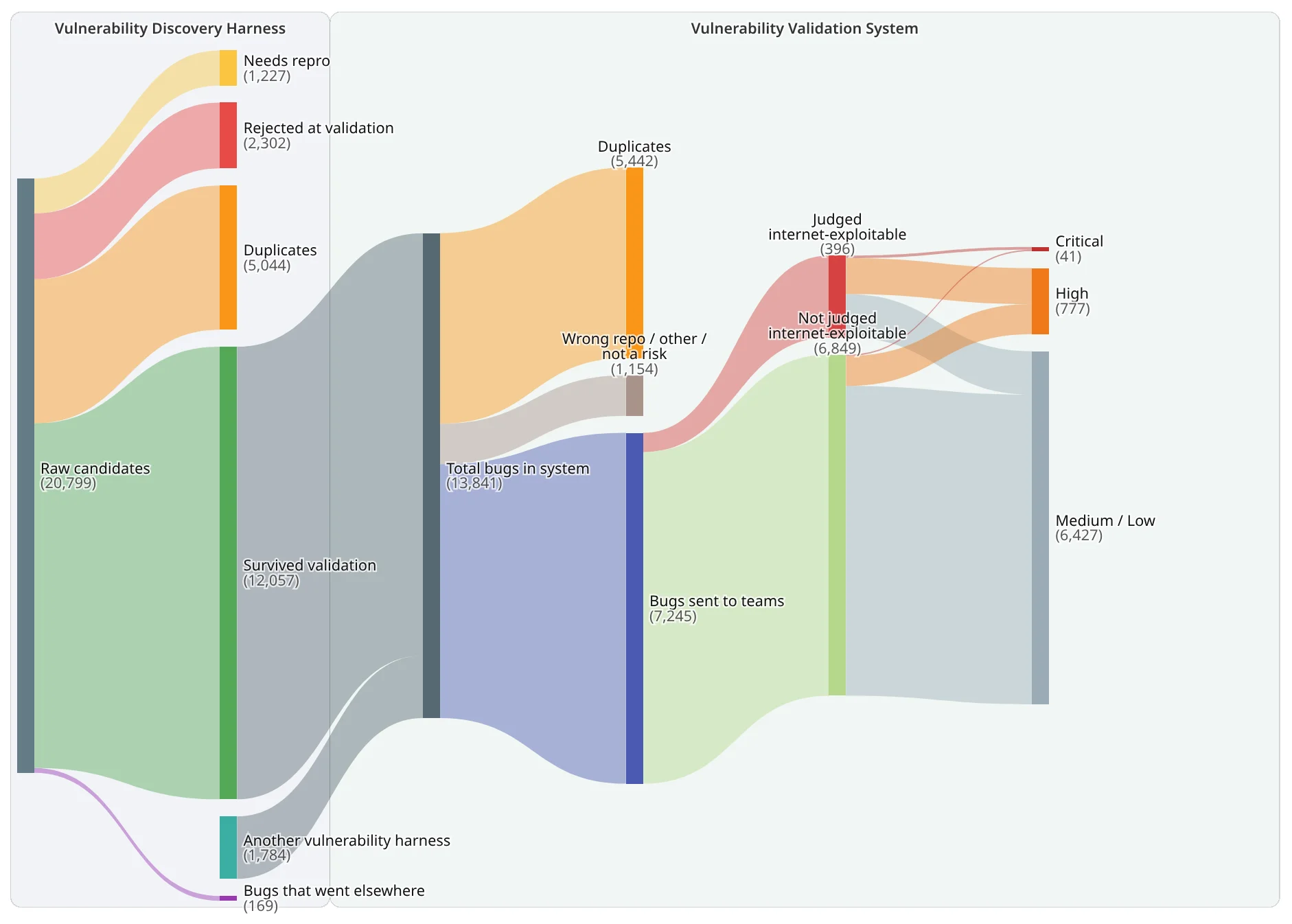
Тестовая обвязка для обнаружения уязвимостей (VDH)
- Сырые кандидаты: Всё, что выдала обвязка обнаружения до независимой валидации.
- Требует воспроизведения: Находки, которые выглядели правдоподобно, но требовали ручного воспроизведения, прежде чем им можно было доверять.
- Отклонено при валидации: Валидатор опроверг модель угрозы, путь эксплойта, затронутый код или доказательства.
- Дубликаты: Кандидаты, поглощённые другой находкой из той же обвязки.
- Выжившие после валидации: Находки, прошедшие независимые ворота валидации и перемещённые в VVS.
- Ошибки, ушедшие в другое место: Находки, намеренно направленные вне этого потока.
Система валидации уязвимостей (VVS)
- Другой инструмент для поиска уязвимостей: Другие автоматизированные источники, питающие ту же систему валидации.
- Всего ошибок в системе: Общий пул после загрузки.
- Дубликаты: Результаты, которые этап дедупликации определил как уже покрытые другой канонической находкой или тикетом.
- Не тот репозиторий / другое / не является риском: Корзина шума: неверно атрибутированные находки, защита в глубину или скрытые риски.
- Ошибки, отправленные командам: Окончательные, чистые находки, готовые к исправлению.
- Признано эксплуатируемым через интернет: Находки высокой срочности, которые реалистичный злоумышленник может использовать в продакшене.
- Не признано эксплуатируемым через интернет: Находки более низкой срочности, подлежащие исправлению (проблемы продакшена, риски зависимостей или ошибки конфигурации).
- Итоговое распределение по критичности: Категоризация, используемая для назначения приоритета командам разработки.
Основная метрика обвязки — не спекулятивный показатель полноты, а поддержание числа неподтвержденных находок перед реальными людьми как можно ближе к нулю. Архитектура должна быть неустанно фильтрующей воронкой.
-
Из 20 799 необработанных кандидатов, сгенерированных VDH, только около 12 057 прошли валидацию.
-
Когда они были переданы в VVS, объединившись с находками из другой обвязки, центральный пул вырос до 13 841.
-
Агент дедупликации отбросил 5 442 находки как дубликаты.
-
1 154 были направлены в очередь как «не тот репозиторий» или «низкий риск» и при необходимости возвращены обратно в систему.
-
В конечном итоге осталось 7 245 подлежащих исправлению находок для команд разработки.
Традиционные правила соответствия предписывают произвольные сроки исправления, основанные исключительно на статической оценке CVSS (например, «Исправить все высокие за 30 дней»). Наш слой контекстной оценки превращает эту галочку соответствия в реальное управление рисками.
Архитектура способна отслеживать находки до их источника, что означает, что исправление одной коренной причины устраняет целый кластер находок, а не просто закрывает отдельные проблемы. Производительность системы VDH также измеряется путем разделения репозиториев на ячейки (область × класс атаки) и итеративного запуска агента Gapfill до тех пор, пока он не перестанет генерировать находки. Всякий раз, когда мы обновляем базовый промпт, мы тестируем его на отдельном репозитории, чтобы увидеть, меняется ли общее количество покрытия в ячейке.
Обвязка подключает автоматические сигналы здоровья, чтобы выявлять сбои системы на ранних этапах конвейера. Если охота завершается подозрительно быстро и не порождает подохоты или задачи по заполнению пробелов, это обычно указывает на аварийную зависимость, а не на чистую кодовую базу. Чтобы исправить это, система помечает любого агента Охотника, завершившегося с нулевым количеством находок, как «поверхностный» и немедленно ставит его в очередь для нового запуска.
Наконец, устойчивость нашей системы усиливается независимым этапом триажа, описанным ранее. Повторно оценивая все представленные результаты с помощью другой модели и отдельных логических весов, мы обеспечиваем объективную состязательную верификацию, которая не зависит от конкретной модели, использованной для обнаружения, и предоставляет уровень доверия, сохраняющийся независимо от используемой модели.
Ничто из этого не завершено. Мы постоянно меняем нашу систему, и она далека от идеальной науки. Но необработанные кандидаты-находки теперь дешевы, и единственная работа, которую стоит делать, — это превращать их в надежные, проверяемые исправления кода.
Создание собственной обвязки означает принятие того, что ИИ-модели нестабильны, но ваш слой оркестрации не обязан быть таким. Отвязывая свою логику безопасности от любого отдельного провайдера, внедряя состязательную верификацию и автоматизируя конвейер триажа, вы можете превратить гору LLM-шума в надежный защитный движок для всего парка.
Наши главные метрики: измерение реальной скорости
Каждая кодовая база немного отличается, поэтому, чтобы показать вам, как это работает в реальном мире, мы составили реалистичный бенчмарк на основе стандартного запуска репозитория. Имейте в виду, что это единичный проход по одному репозиторию; со временем, по мере того как непрерывный цикл по всему парку дедуплицирует, фильтрует и перерабатывает находки, объем пожизненных кандидатов сокращается примерно на 65%.
Сэкономленные часы работы инженеров за счет автоматического патчинга: Вместо того чтобы сосредотачиваться на статических базовых показателях, мы измеряем здоровье нашего конвейера по его технической пропускной способности, скорости обработки и способности устранить узкое место ручного триажа:
-
Первоначальная отсеивающая валидация: Для стандартного репозитория (~30 тыс. строк кода) это дает 100 первоначальных находок, полный запуск занимает 3-4 часа, сохраняя гиперфокусированное контекстное окно на протяжении всего процесса.
-
Сжатие: Слои дедупликации и контекстной оценки обрабатывают эти кандидаты параллельно. В течение 3 часов система сжимает и уточняет пакет находок с ~100 необработанных кандидатов до 80 различных высокоточных ошибок.
-
Исправление: Автоматический исправитель обрабатывает эти 80 различных ошибок со средней скоростью 5 минут на ошибку. В общей сложности система может обнаружить, проверить, дедуплицировать и открыть функциональные pull request'ы примерно за 14 часов.
Сокращение среднего времени устранения критических дефектов: Конечно, нельзя вываливать 80 патчей в продакшен одновременно, ничего не сломав. Чтобы развертывания были безопасными, наша система использует многоуровневое развертывание:
-
Локализация критических рисков: Система изолирует критические, высокие и эксплуатируемые ошибки (в среднем 10 из 80). Мы ускоренно направляем их на проверку человеком и внедряем в циклы релизов, добиваясь полного исправления в продакшене за 5 дней.
-
Постепенное усиление: Остальные скрытые риски, незначительные аномалии конфигурации и ошибки меньшей срочности постепенно вкатываются в продакшен в течение 15-20 дней для обеспечения стабильности платформы.
Как мы справляемся со всем этим патчингом
Эти находки являются результатом изолированного, огороженного исследовательского эксперимента, предназначенного для стресс-тестирования нашего кода. Они не представляют собой активные, незакрытые уязвимости в нашей рабочей производственной среде.
Поскольку обвязка работает постоянно в наших тестовых средах, эти конкретные цифры полностью устаревают к тому моменту, когда вы это читаете. Каждая ошибка, выявленная конвейером, сопровождалась рабочим тестовым примером для демонстрации ошибки и черновиком патча. Наши команды безопасности систематически обрабатывают отчеты и применяют необходимые исправления, что означает, что продукты Cloudflare, которыми вы пользуетесь ежедневно, уже активно защищены от этих векторов.
Вместе с этой записью в блоге мы публикуем начальный навык, который использовали для разработки обвязки. Перед публикацией он был немного очищен, чтобы его было легче понять и интегрировать, но сам навык остался практически неизменным. Надеемся, что сама обвязка последует вскоре. Это может быть отправной точкой для вашей собственной обвязки уязвимостей, вашего собственного навыка или чего-то, что лучше всего подходит вашим нуждам: github.com/cloudflare/security-audit-skill