Для взаимодействия нас, людей, с онлайн-миром нам нужен шлюз: клавиатура, экран, браузер, устройство. То, что в интернете называют «обнаружением человека», — это паттерны, которые люди используют при взаимодействии с такими устройствами. В последние годы эти паттерны изменились: основатель стартапа теперь использует браузер для сводки новостей, энтузиаст технологий автоматизирует процесс покупки билетов на концерт в момент начала продаж ночью, слабовидящий пользователь включает функции доступности в своем скринридере, а компании направляют трафик своих сотрудников через прокси с нулевым доверием.
В то же время владельцы веб-сайтов по-прежнему стремятся защищать свои данные, управлять ресурсами, контролировать распространение контента и предотвращать злоупотребления. Эти проблемы не решаются знанием о том, является ли клиент человеком или ботом: существуют желаемые боты и нежелательные люди. Для решения этих проблем необходимо понимать намерения и поведение. Способность обнаруживать автоматизацию по-прежнему критически важна. Однако по мере того, как различия между участниками стираются, создаваемые нами системы должны учитывать будущее, в котором «боты против людей» — не самый важный показатель.
На самом деле важна не абстрактная человечность, а такие вопросы, как: является ли этот трафик атакой, пропорциональна ли нагрузка от этого краулера возвращаемому им трафику, ожидаю ли я, что этот пользователь подключится из новой страны, манипулируют ли с моей рекламой?
То, что мы обсуждаем под термином «боты», на самом деле представляет собой две разные истории. Первая — должны ли владельцы сайтов пропускать известных краулеров, когда не получают от них обратного трафика. Мы касались этого в теме аутентификации ботов с помощью подписей HTTP-сообщений для краулеров, которые хотят идентифицироваться, не будучи сымитированными. Вторая — появление новых клиентов, которые не встраивают те же модели поведения, что исторически делали веб-браузеры, что важно для таких систем, как приватное ограничение частоты запросов.
В этой статье мы исследуем, как сегодня работает защита в интернете и как она должна развиваться, когда граница между ботом и человеком размывается.
Интернет, который у нас был
Когда мы пользуемся Интернетом, мы не общаемся напрямую с тысячами серверов, с которыми взаимодействуем каждый день. Мы используем веб-браузеры. Их также называют «агентами пользователей», потому что они действуют от нашего имени, представляя наши интересы, чтобы мы могли безопасно совершать покупки, читать и смотреть контент в сети, не предоставляя сайтам доступ ко всему нашему компьютеру или телефону.
Веб-сайты также заинтересованы в том, как работают браузеры. Они хотят быть уверены, что их контент отображается точно (помещается на экран мобильного устройства, имеет правильный цвет фона, корректный язык). Сайты также хотят, чтобы люди могли завершить покупку, прочитать их статьи, использовать их микрофон или безопасно войти без пароля. Они также хотят, чтобы люди видели рекламу рядом со статьями.
Это противоречие между интересами пользователей браузеров и веб-сайтов существует уже давно. Издатели, как правило, хотят контролировать взаимодействие с пользователями на уровне пикселей, но люди по другую сторону браузера часто хотят использовать доступные им данные способами, не предусмотренными издателем.
Производители веб-браузеров и экосистема стандартов вокруг них уделяли пристальное внимание балансировке этих интересов, иногда вызывая большие споры. Например, вы можете использовать расширения браузера для блокировки рекламы, но со временем браузеры ограничили возможности таких расширений. Стандарты доступности (например, WCAG) проложили путь для использования веб-контента способами, не связанными с пикселями, что во многих местах подкреплено нормативными требованиями. Можно оспаривать детали каждого из этих компромиссов, но они идут в комплексе: если вы хотите быть в Интернете, вы должны принять его, независимо от того, являетесь ли вы издателем или пользователем.
Однако сейчас этот баланс смещается. Наличие помощника, который обобщает новости или агрегирует исследования, — не новая концепция, но ИИ демократизирует эту возможность для всех. Трение возникает из-за того, как работают эти новые клиенты. Человек-помощник может распечатать статью или сделать скриншот без ведома издателя, но изначально он все равно использует стандартный веб-браузер для отображения сайта. ИИ-агенты обходят этот шаг, нарушая сбалансированный подход к правам издателей и пользователей, который создавали браузеры. Они незаметно получают исходные данные, не отображая страницу. Для издателей, из-за пересечения такого трафика с уже существующим браузерным трафиком, эти клиенты по своей природе непрозрачны. Владельцы сайтов не могут определить, используется ли полученный контент для одного частного отчета (возможно, искаженного или без указания авторства) или загружается для обучения модели на миллион пользователей, что нарушает предсказуемый (и монетизируемый) трафик, который поддерживает работу их сайтов.
Негласное соглашение, которое заставляло Интернет работать, разрушается. Чтобы понять, как это происходит, следующий раздел расскажет об общей архитектуре в Интернете.
Модель клиент-сервер
Давайте сделаем шаг назад и посмотрим на одну из основных моделей развертывания в Интернете: модель клиент-сервер. Клиент отправляет запрос на сервер для получения ресурса:
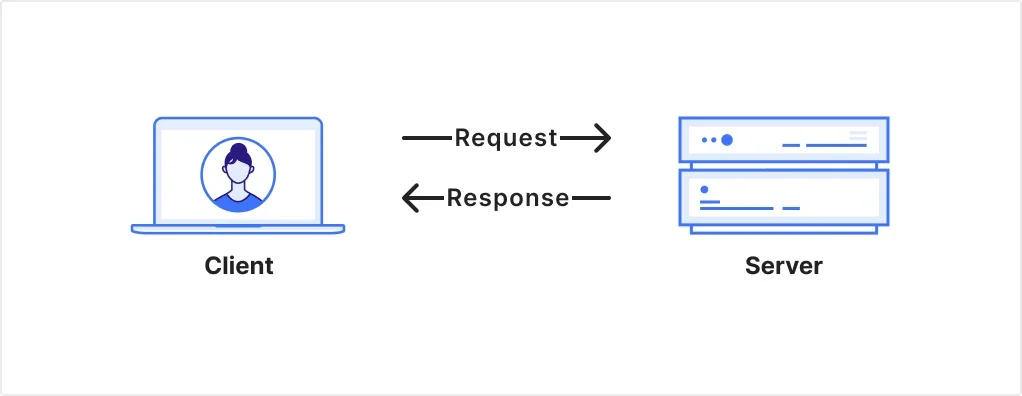
Рисунок 1: Модель клиент-сервер. Клиент отправляет запрос, на который сервер отвечает.
Чтобы обрабатывать больше запросов, веб-сайт может увеличить свою пропускную способность; он может развернуть дополнительные серверы или разместить кэш перед статическим трафиком. Аналогично, количество запросов со стороны клиента может увеличиться, если один клиент отправляет больше запросов или если количество клиентов умножается.
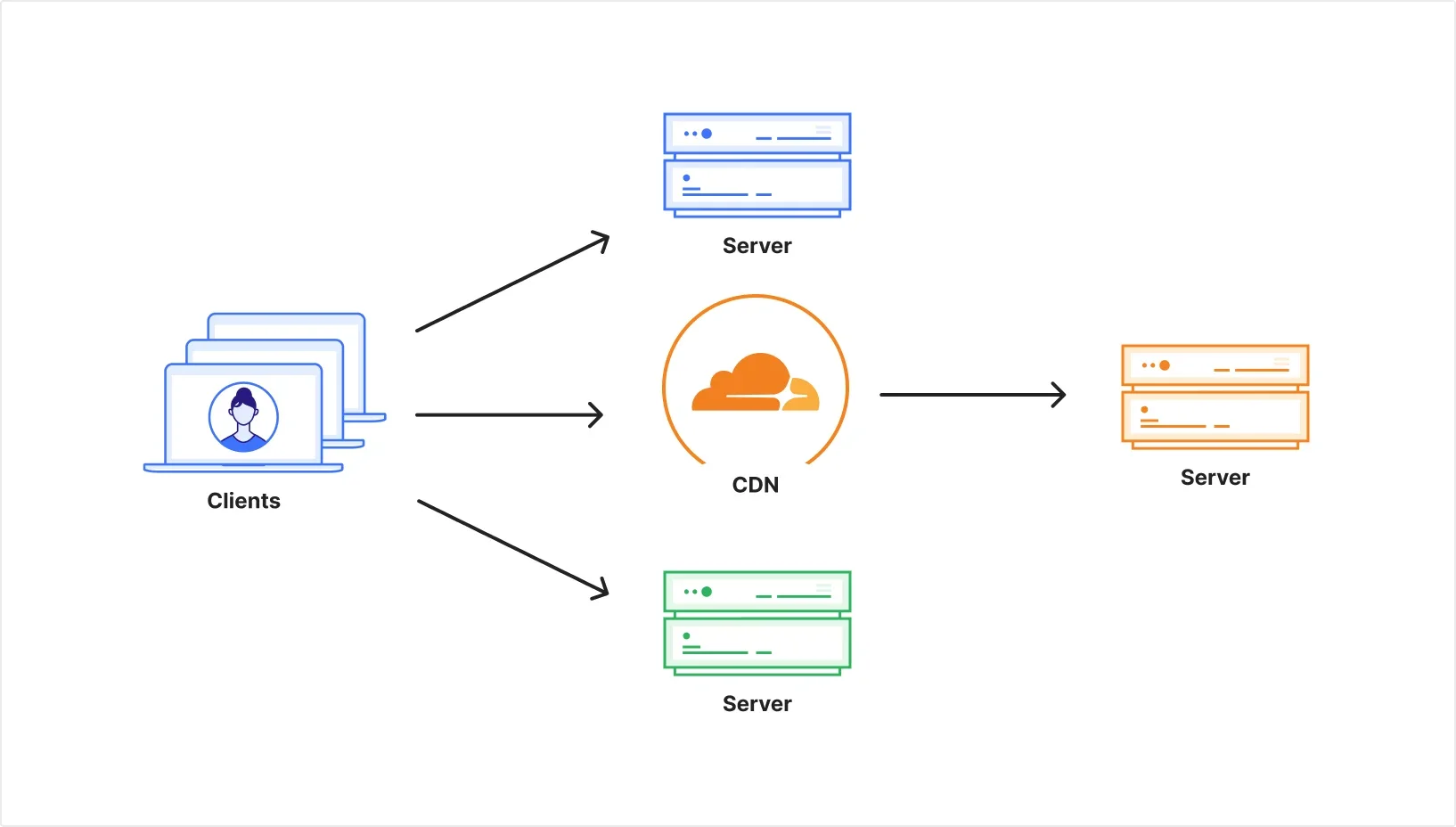
Рисунок 2: Несколько клиентов отправляют несколько запросов на разные серверы, перед одним из которых стоит CDN.
Эта простота отчасти сделала Интернет успешным. Она позволяет существовать многим типам клиентов и позволяет сети развиваться, без необходимости каждому серверу точно знать, какое программное обеспечение находится на другом конце.
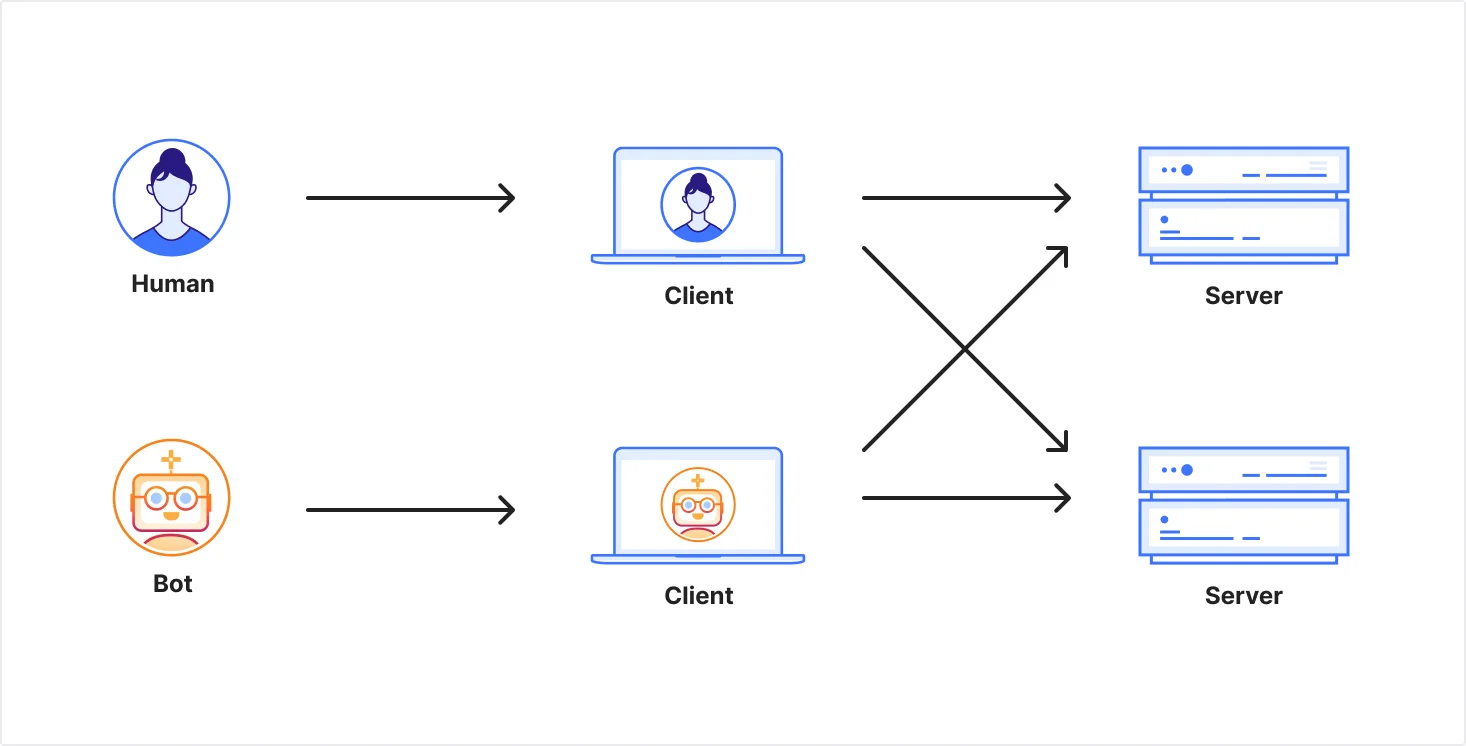
Рисунок 3: Два разных клиентских контекста отправляют запросы на серверы. Каждый сервер видит только запрос, но не конечного пользователя за ним.
Эта открытость также создает неопределенность. Сайт может видеть валидный запрос на ресурс, но обычно не может знать, что происходит после того, как ответ покидает сервер: отображается ли контент для одного человека, использующего клавиатуру, мышь и экран для управления браузером; или это независимая программа, автоматически отправляющая запросы, архивирующая ответы, индексирующая их и передающая в более крупную систему.
Управление ботами сегодня
Эта модель работает на удивление хорошо. Вот почему управление веб-сайтом может быть таким же простым, как запуск веб-сервера с подключением к Интернету. Это справедливо лишь до тех пор, пока серверу не приходится решать, какие запросы он может позволить себе обслужить, каким доверять или какие приоритезировать.
Иногда это вопрос пропускной способности. Если ваш сервис рассчитан на обработку 100 запросов в секунду по всему миру, но вы получаете 200, вам приходится отбрасывать некоторые запросы. Если на вашем сервере только 1 ЦП, а входящие запросы требуют 2, вам приходится отбрасывать запросы. Если стоимость обслуживания 200 запросов непомерно высока, то вам приходится ограничивать частоту всех запросов.
Вы можете отбрасывать запросы случайным образом. Возможно, это несправедливо и может промахнуться по цели, затронув желаемых клиентов, но это работает. При отсутствии других сигналов выбора нет.
И пропускная способность — лишь часть картины. Серверы также пытаются различать клиентов по многим другим причинам: чтобы отделить атаки от обычного трафика, управлять незлонамеренной нагрузкой, предотвратить извлечение данных, ограничить мошенничество с рекламой, предотвратить создание фейковых аккаунтов или остановить автоматизированные действия, совершаемые от имени пользователя.
Сложность в том, что веб-клиенты по умолчанию не аутентифицированы, но при этом выдают множество частичных сигналов. Поэтому большинство серверов решают применять логику контроля доступа на основе получаемой информации. Если один IP-адрес отправляет в 10 раз больше запросов, чем другие, его могут заблокировать. Сервер, который идет дальше, может сделать вывод, что этот IP-адрес используется VPN и, следовательно, проксирует трафик более чем одного пользователя. Сервис может решить применить коэффициент: предполагая, что каждый клиент может отправлять 10 запросов в секунду, общий IP-адрес будет иметь лимит в 100 запросов в секунду, прежде чем его запросы начнут отбрасываться.
Это один из ключей к управлению ботами: оно стремится предоставить серверу больше информации о клиенте, чтобы помочь ему принимать решения. Эта информация по своей природе неточна, потому что клиент не находится под контролем сервера. Кроме того, одна и та же информация создает векторы создания цифрового отпечатка, которые сервер может использовать для различных целей, таких как персонализированная реклама. Это превращает вектор смягчения угроз в вектор отслеживания.
На высоком уровне сервер видит от клиента следующие сигналы:
-
Пассивные сигналы клиента: необходимые для выполнения запроса в Интернете. Клиенты обязательно отправляют ваш IP-адрес и обычно устанавливают TLS-сессию.
-
Активные сигналы клиента: добровольно предоставляемые клиентом, часто невидимые для конечного пользователя. Сюда входит заголовок User-Agent или учетные данные аутентификации.
-
Сигналы сервера: информация, которую наблюдает сервер, например, географическое расположение пограничного сервера, обрабатывающего запрос, или локальное время получения запроса.
Для ограничения и сдерживания объёмных злоупотреблений для источника важно, чтобы клиент имел возможность и намерение выполнять множественные запросы. В случае веб-сайта, финансируемого за счёт рекламы, источник должен быть уверен, что реклама действительно отображается конечному пользователю. Для защиты своего бренда источники могут захотеть убедиться, что клиент обладает определёнными возможностями рендеринга: PDF-ридер, SVG-рендерер, виртуальная клавиатура. И если запрос поступает от перехватывающего прокси-сервера, источник может захотеть убедиться, что запрос действительно исходит от конечного клиента.
Если трафик растёт, то растут и затраты на эксплуатацию. Если клиенты не генерируют ценность, денежную или иную, то у сервера нет стимула покрывать эти расходы.
Разные операторы по-разному реагируют на такую среду. Некоторые крупные краулеры и платформы идентифицируют себя, потому что предсказуемый доступ стоит того, чтобы быть атрибутируемым. Это может даже помочь. Другие пытаются избежать идентификации: потому что ожидают блокировки, стремятся к анонимности или действуют от имени конечных пользователей. Результатом становится неустойчивый баланс, построенный на частичных сигналах.
Вот почему противопоставление "люди против ботов" вводит в заблуждение. Источника заботит не человечность в абстрактном смысле, а то, ведёт ли себя клиент способами, которые сайт может поддерживать.
Отступление: трилемма ограничения скорости
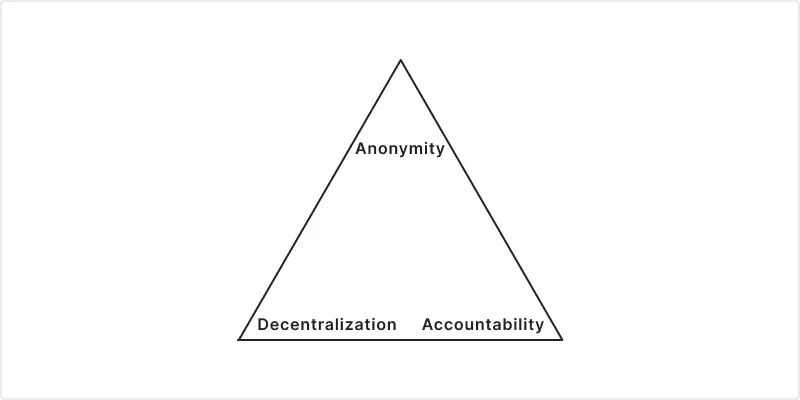
Рисунок 4: Трилемма ограничения скорости. Децентрализованный, анонимный, подотчётный — выберите два
Существует фундаментальное противоречие в том, как мы регулируем доступ в Интернете: децентрализованный, анонимный, подотчётный — выберите два.
-
Полностью децентрализованный + анонимный означает отсутствие подотчётности. Заблокированный клиент может создать новую учётную запись без последствий для своей репутации. Это подразумевает, что источникам приходится больше инвестировать в управление своими ресурсами. Это состояние по умолчанию для Веба.
-
Децентрализованный + подотчётный означает, что все знают, кто вы, что работает для определённых случаев использования, но имеет явные недостатки. Например, механизмы OAuth, такие как «Войти через», которые требуют регистрации учётной записи и раскрытия активности третьей стороне.
-
Анонимный + подотчётный, вероятно, требует управления, правил и принуждения к их исполнению. Ни одна широко развёрнутая система не обеспечивает оба эти свойства для одного и того же субъекта. Ближайшим прецедентом является Веб PKI, где управление (политики центров сертификации, Certificate Transparency) обеспечивает подотчётность серверов. Когда это управление даёт сбой, возникают последствия. Эквивалента для клиентской стороны сегодня не существует.
Современные инструменты строятся на элементах из первого пространства, стремясь ко второму: TLS-отпечатки, IP-адреса, robots.txt. Они пытаются обеспечить подотчётность, но работают только до тех пор, пока полученные отпечатки остаются стабильными.
Важны различия в том, что, а не кто
Для владельца веб-сайта, решающего, как обрабатывать входящий трафик, значимое различие не обязательно заключается в ботах против людей. Речь идёт о балансе между потребностью источника понимать получаемый трафик и потребностью клиентов сохранять свою конфиденциальность.
Платформы и сервисы, которые хотят быть идентифицируемыми
Рисунок 5: Краулер выполняет множество запросов к серверу
Часть трафика поступает от известных операторов, выполняющих большой объём запросов: поисковые роботы, облачные платформы, корпоративная инфраструктура. У таких субъектов часто низкие ожидания конфиденциальности. Это инфраструктура, выполняющая миллионы запросов из идентифицируемых источников. Возможность идентифицировать источник запроса помогает смягчить ошибочные суждения, если поставщик инфраструктуры отправляет вам слишком много запросов или обращается к страницам, к которым не должен. Самоидентификация — один из принципов для ответственных ИИ-ботов, которые мы предложили. Именно на этих принципах Cloudflare управляет своим сканером URL для Radar или как мы предоставляем возможности сканирования.
Для такого трафика идентичность работает. Точнее, некоторые операторы могут допускать атрибутируемые запросы, потому что надёжный доступ того стоит. Аутентификация веб-ботов с использованием подписей HTTP-сообщений позволяет операторам криптографически подписывать свои запросы. Например, OpenAI, Google, Cloudflare или AWS подписывают запросы, исходящие от их платформ. Источники могут проверить, что «этот запрос действительно поступил из инфраструктуры платформы», не полагаясь на диапазоны IP-адресов или строки User-Agent.
Люди и другие конечные пользователи законно имеют ожидания, отличные от необходимости быть идентифицируемыми, чтобы сохранять анонимность, не жертвуя доступом и качеством взаимодействия.
Распределённый трафик, нуждающийся в анонимности
Рисунок 6: Три разных браузера отправляют запрос на сервер. Одним управляет человек, другим — локальный помощник, а третий проходит через корпоративный прокси.
Другой трафик поступает из множества источников, каждый из которых выполняет относительно мало запросов. Сюда входят люди, просматривающие веб-страницы, исследователи, проводящие измерения, сборщики данных, использующие резидентские прокси, и, всё чаще, ИИ-помощники, действующие от имени людей.
И всё чаще различие между ботами и людьми теряет смысл. Нет существенной разницы между ИИ-помощником, бронирующим билеты на концерт, и человеком, который сделал бы это вручную. Оба являются распределёнными. Оба нуждаются в анонимности. В каждом случае источник хотел бы создавать меньше препятствий для пользователей, которые хотят использовать сервис по назначению, а не злоупотреблять им.
Идентичность могла бы работать. Чтобы заменить старое предположение об IP-адресах, она должна предоставлять уникальный, проверяемый набор атрибутов, привязанных к конкретному клиенту, подтверждённых через вход в учётную запись, адрес электронной почты или аппаратный ключ. Однако это подразумевает необходимость предъявлять эту идентичность при доступе к веб-сайтам. Это также подрывает конфиденциальность.
Мы хотим создать современные решения, которые доказывают поведение, не доказывая личность.
Анонимные учетные данные для Веба
С 2019 года клиенты, обращающиеся к веб-сайтам через Cloudflare, могут предоставлять такое доказательство поведения, отправляя вместе со своим запросом токен конфиденциальности. Это стало возможным благодаря ранней поддержке Privacy Pass в Cloudflare. Privacy Pass, стандартизированный в RFC 9576 и RFC 9578, позволяет клиенту предъявлять подтверждённое эмитентом доказательство некой предварительной проверки, например, решения задачи, не превращая этот результат в стабильный идентификатор. Он определяет токены, которые не поддаются связыванию с каким-либо предыдущим посещением, запросом или сеансом.
Это важно, потому что предлагает модель, отличную от снятия отпечатков. Вместо сбора пассивных сигналов сервер может запросить у клиента активный сигнал, сохраняющий конфиденциальность.
Это снижает трение при установлении сеанса. Privacy Pass масштабировался до миллиардов токенов в день в инфраструктуре Cloudflare, в первую очередь для сервисов ретрансляции приватности.
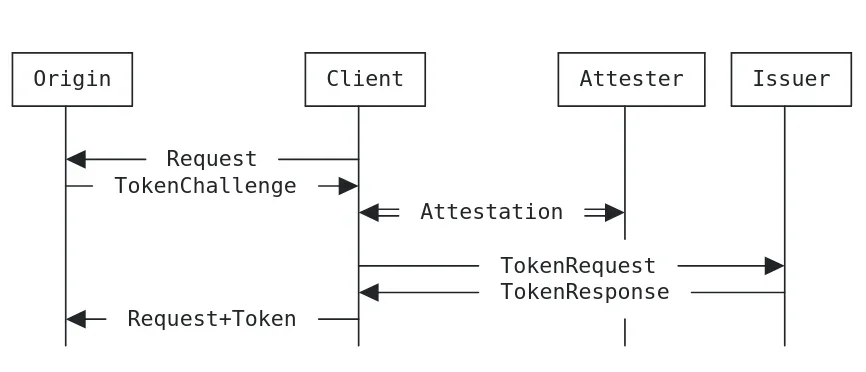
Рисунок 7: Взаимодействие протоколов погашения и выпуска Privacy Pass из Раздела 3.1 RFC 9576
В RFC выделяются четыре роли. Эмитент доверяет одному или нескольким аттестаторам выполнить некоторые проверки перед выпуском учетных данных (в случае RFC — токенов). Клиент хранит эти учетные данные и решает, когда их предъявить, в пределах соответствующей области действия. Источник контролирует, каким эмитентам он доверяет и что означает каждое предъявление. Это не устраняет злоупотребления или вопросы политики, а просто предоставляет клиентам и серверам способ обращения с ними, сохраняющий конфиденциальность.
Система проста, но также имеет ограничения: она не позволяет, например, устанавливать динамические ограничения скорости. Если клиенту выдано 100 токенов и он начинает потреблять слишком много ресурсов после первого или второго сеанса, нет возможности аннулировать оставшиеся ранее выданные токены.
Кроме того, из-за свойства неотслеживаемости новым эмитентам сложно появиться. Не существует механизма обратной связи, который источник мог бы предоставить относительно качества сигнала, который передаёт токен эмитента.
Наконец, существует соотношение 1:1 между количеством токенов, которые предоставляет эмитент, и количеством не отслеживаемых презентаций, которые могут быть выполнены с этими токенами при их использовании: один токен на презентацию. В идеале нам нужна система, в которой клиент обращается к эмитенту один раз и впоследствии может выполнять множественные презентации в контексте конкретного источника. Это указывает на то, что пользовательские агенты должны хранить подтверждённые учётные данные и представлять доказательства, выведенные из них, а не постоянно получать одноразовые токены.
Наша цель — помочь создать открытую экосистему приватного ограничения частоты запросов. В этом духе мы помогаем разрабатывать и исследовать новые примитивы Privacy Pass, такие как Anonymous Rate-Limit Credentials (ARC) и Anonymous Credit Tokens (ACT).
Например, с помощью ACT клиенты могут доказывать что-то вроде «У меня хорошая история взаимодействия с этим сервисом», не раскрывая «Я — этот конкретный пользователь». ACT обеспечивает неотслеживаемость между презентациями на уровне протокола, что является ключевым криптографическим свойством. Даже в модели развёртывания с совместным эмитентом и источником в Разделе 4.3 RFC 9576 протокол разработан так, что выпуск токена и его презентация не могут быть напрямую связаны. Это не устраняет корреляцию через другие уровни, такие как IP-адреса, куки, состояние учётной записи или время. Те же свойства могут быть обеспечены с использованием стандартизированных примитивов VOPRF и BlindRSA в рамках обратного потока, который реализует ACT.
Успешная экосистема должна быть экосистемой с открытыми эмитентами. На практике это означает нечто большее, чем просто возможность любого создавать учётные данные. Источники должны иметь возможность решать, каким эмитентам доверять. Пользовательским агентам нужен единообразный способ представления того, что запрашивается. Экосистема также нуждается в способах для эмитентов завоевать репутацию, а для проверяющих сторон — перестать доверять низкокачественным эмитентам. Ни один отдельный привратник не должен контролировать участие.
Для реализации этого необходим протокол и клиентский API, работающие во всех браузерах и других пользовательских агентах. Он должен быть простым в развёртывании, понятным для пользователей и достаточно ограниченным, чтобы браузеры могли накладывать ограничения на злоупотребление запросами доказательств, а не просто показывать их.
Сценарий, если мы ничего не предпримем
Владельцы веб-сайтов уже реагируют на нарушения, вызванные появлением новых клиентов. Это частично вызвано массовым скрейпингом и обучением моделей, а также поведением пользовательских агентов, которое сайты не предвидели. Поэтому веб-сайты запросили больше технических средств для блокировки AI-краулеров и связанных с ними инструментов. В экосистеме, где границы между ботами и людьми всё больше размываются, существующие на сегодня меры сами по себе станут менее эффективными.
Если эти меры окажутся неэффективными, можно ожидать, что сайты изменят подход: потребуют учётную запись для просмотра любого контента или привяжут доступ к стабильному идентификатору. Это означает конец бесплатным статьям с рекламой без входа в систему, конец «трём бесплатным статьям в месяц». Другие контент-бизнесы могут полностью уйти из Интернета, предлагая свои данные и услуги напрямую поставщикам ИИ за плату или внутри огороженных экосистем, управляемых крупными платформами.
Такие исходы плохи. Все выигрывают от открытого доступа к информации, который предлагает Интернет. Дело не в том, что все сайты сделают такой выбор. Существует много причин для размещения контента онлайн, и не все они коммерческие. Но если это сделает достаточное количество сайтов, они изменят понятие «нормального» в Интернете на что-то худшее.
Это важно, потому что открытый Интернет — это среда, в которой разные клиенты могут собирать информацию из разных источников, не полагаясь на горстку игроков. Мы также выигрываем от разнообразия источников информации. В Интернете, где доступ к информации в основном контролируется небольшой группой компаний, мы сосредотачиваем слишком много власти в слишком немногих руках. Результатом будет не только больше трений для анонимных клиентов, но и более хрупкий Интернет с меньшим количеством способов для издателей взаимодействовать с пользователями.
Анонимная аутентификация также несёт риски
Мы должны чётко понимать, что строим. Инфраструктура для доказательства свойств может стать инфраструктурой для требования свойств. Анонимные учётные данные предназначены для доказательства чего-то о их владельце; например, «Я решил задачу» или «Я не превысил лимит запросов». Но система, способная доказать любой отдельный атрибут, также способна доказывать и другие атрибуты, что является источником беспокойства.
Сегодня предъявление токена Privacy Pass может означать «решил CAPTCHA». Завтра те же системы смогут доказывать совершенно другие атрибуты. Например, выпуск токенов только для устройств, которые «имеют аттестацию устройства», исключает старые устройства и их пользователей. Точно так же требование атрибутов, таких как «имеет учётную запись Apple или Google», исключает пользователей непопулярных платформ.
Как только появится инфраструктура для проверки анонимных доказательств, перечень того, что требуется доказать, может расшириться. Нам нужно убедиться, что это не станет препятствием для доступа в Интернет.
Почему мы всё равно должны это строить
Препятствия уже существуют. Платформы всё чаще требуют идентификации. Веб-сайты блокируют трафик, поступающий через общие прокси. Вопрос не в том, появятся ли препятствия, а в том, останется ли пользователь в контроле над своей приватностью.
Как мы уже обсуждали, управление ботами требует обмена некоторыми сигналами. Альтернативы анонимным доказательствам хуже. Без возможности анонимно доказывать атрибуты каждое препятствие требует идентификации: повторите запрос из определённого браузера, привяжите свою учётную запись, не используйте VPN. Для некоторых людей, например, для тех, кто даже не подозревает, что их соединение проходит через прокси, это может быть даже невозможным.
Учётные данные, сохраняющие приватность, не устраняют необходимость доверия или политик. Они могут сделать эти требования более явными и менее повсеместными. В отличие от цифровых отпечатков, доказательства являются явными. Пользователи могут видеть, что запрашивается, а клиенты, такие как веб-браузеры и AI-ассистенты, могут помочь обеспечить соблюдение согласия.
Для принятия решения используйте этот ограничитель
Существует простой тест для оценки новых методов для Интернета, который служит всем: позволяют ли методы любому человеку, из любой точки мира, создать своё собственное устройство, свой собственный браузер, использовать любую операционную систему и получить доступ к Сети. Если это свойство не может быть соблюдено, если аттестация устройств от конкретных производителей станет единственным жизнеспособным сигналом, нам следует остановиться.
Это означает, что нам необходимо развивать экосистему с открытыми эмитентами, где ни один привратник не решает, кто может участвовать. В трилемме ограничения частоты запросов децентрализация обязательна для открытого Интернета. Мы ещё не до конца знаем, как её построить, но мы знаем, что нам необходимо её развивать.
Новый баланс
До сих пор Интернет в основном находился в равновесии. Некоторые аспекты могли быть счастливой случайностью, в то время как другие, возможно, были неизбежными. Для многих конечных пользователей и издателей это работало, потому что Интернет оставался достаточно открытым, чтобы поддерживать разнообразие клиентов, получающих доступ к столь же разнообразным ресурсам.
Этот баланс под угрозой. Примитивы, сохраняющие приватность для Интернета, — это одна из попыток построить другой исход: с сохранением приватности, открытый, подотчётный. Успех не гарантирован. Но это лучше, чем ждать.
Если вы заинтересованы в отслеживании и участии, эта работа ведётся открыто в IETF и в W3C. Мы верим, что существующие площадки, где люди собирались, чтобы формировать сегодняшний Интернет, являются лучшими местами для проектирования Интернета завтрашнего дня.