Интернет всегда должен был адаптироваться к новым стандартам. Он научился общаться с веб-браузерами, а затем научился общаться с поисковыми системами. Теперь ему нужно научиться общаться с ИИ-агентами.
Сегодня мы рады представить isitagentready.com — новый инструмент, который поможет владельцам сайтов понять, как они могут оптимизировать свои сайты для агентов: от указания агентам, как пройти аутентификацию, до контроля над тем, какой контент агенты могут видеть, в каком формате они его получают и как за него платят. Мы также добавляем новый набор данных в Cloudflare Radar, который отслеживает общий уровень внедрения каждого стандарта для агентов во всем интернете.
Мы хотим показывать пример. Именно поэтому мы также рассказываем, как недавно мы полностью переработали Документацию для разработчиков Cloudflare, чтобы сделать её самым дружелюбным к агентам сайтом документации, что позволяет ИИ-инструментам отвечать на вопросы быстрее и значительно дешевле.
Насколько веб сегодня готов к агентам?
Короткий ответ: не очень. Этого и следовало ожидать, но это также показывает, насколько более эффективными могут быть агенты по сравнению с сегодняшним днём, если стандарты будут приняты.
Для этого анализа Cloudflare Radar взял 200 000 самых посещаемых доменов в интернете; отфильтровал категории, где готовность к агентам не важна (например, редиректы, рекламные серверы и туннельные службы), чтобы сосредоточиться на бизнесах, издателях и платформах, с которыми ИИ-агентам, возможно, действительно придётся взаимодействовать; и просканировал их с помощью нашего нового инструмента.
Результатом стала новая диаграмма «Внедрение стандартов для ИИ-агентов», которую теперь можно найти на странице Cloudflare Radar AI Insights, где мы можем измерить уровень внедрения каждого стандарта в различных категориях доменов.
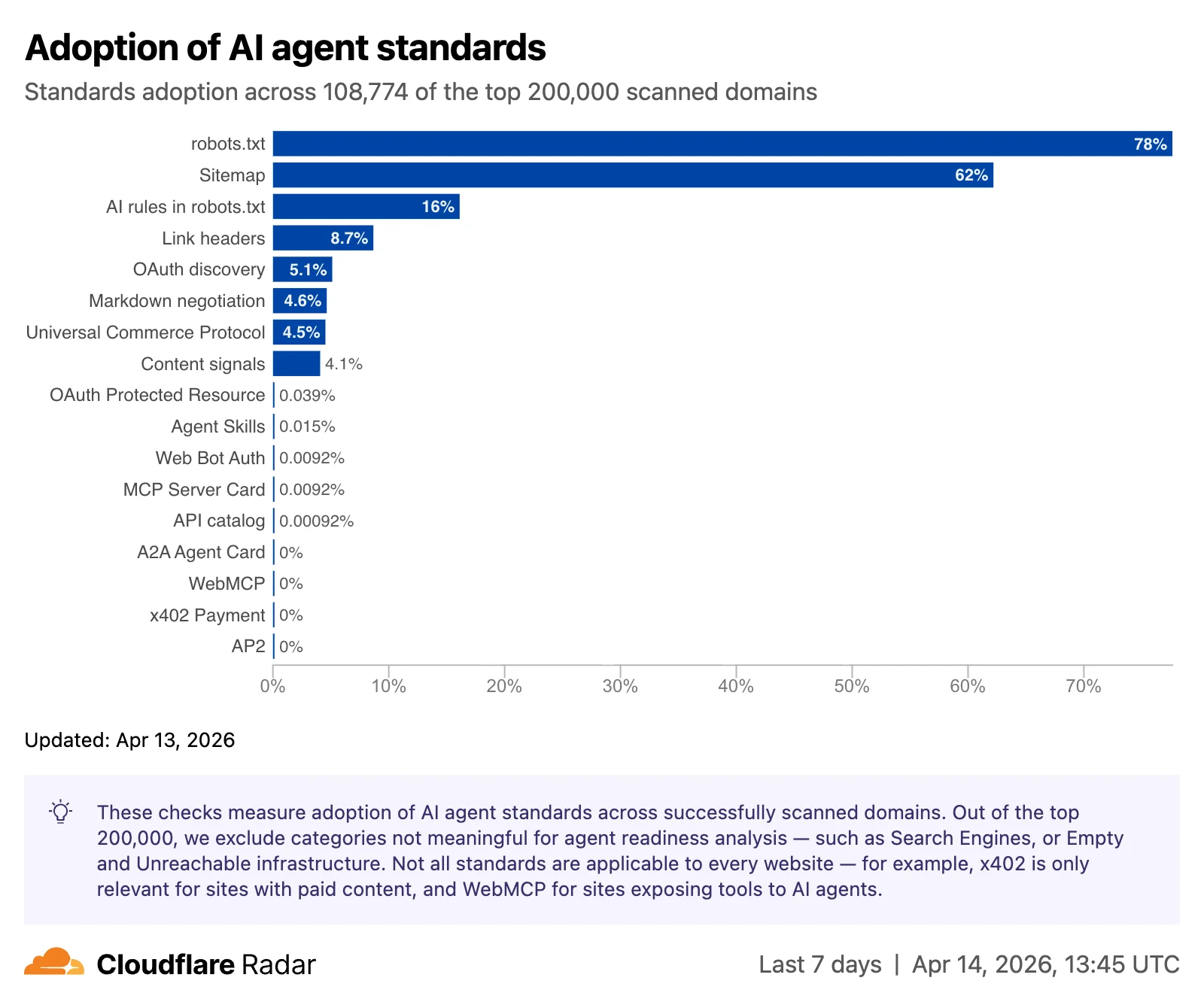
Рассматривая отдельные проверки, можно отметить несколько моментов:
-
robots.txt — практически повсеместный стандарт (есть на 78% сайтов), но подавляющее большинство файлов написано для традиционных поисковых краулеров, а не для ИИ-агентов.
-
Content Signals: 4% сайтов объявили о своих предпочтениях по использованию ИИ в файле robots.txt. Это новый стандарт, набирающий обороты.
-
Согласование контента в формате Markdown (отдача text/markdown при заголовке Accept: text/markdown) проходит на 3,9% сайтов.
-
Новые появляющиеся стандарты, такие как MCP Server Cards и API Catalogs (RFC 9727), вместе встречаются менее чем на 15 сайтах во всём наборе данных. Это ещё только начало — есть много возможностей выделиться, став одним из первых сайтов, внедривших новые стандарты и хорошо работающих с агентами.
Эта диаграмма будет обновляться еженедельно, а данные также можно получить через Data Explorer или Radar API.
Получите оценку готовности вашего сайта для агентов
Вы можете получить оценку готовности для агентов для своего собственного веб-сайта, перейдя на isitagentready.com и введя URL сайта.
Оценки и аудиты, дающие практические рекомендации, уже помогали продвигать внедрение новых стандартов. Например, Google Lighthouse оценивает веб-сайты по критериям производительности и безопасности и направляет владельцев сайтов к внедрению новейших стандартов веб-платформы. Мы считаем, что нечто подобное должно существовать, чтобы помочь владельцам сайтов внедрять лучшие практики для работы с агентами.
Когда вы вводите адрес своего сайта, Cloudflare отправляет к нему запросы, чтобы проверить, какие стандарты он поддерживает, и предоставляет оценку по четырём направлениям:
-
Обнаружаемость: robots.txt, sitemap.xml, Link Headers (RFC 8288)
-
Контент: Markdown для агентов
-
Управление доступом для ботов: Content Signals, правила для ИИ-ботов в robots.txt, Web Bot Auth
-
Возможности: Agent Skills, API Catalog (RFC 9727), обнаружение сервера OAuth через RFC 8414 и RFC 9728, MCP Server Card и WebMCP
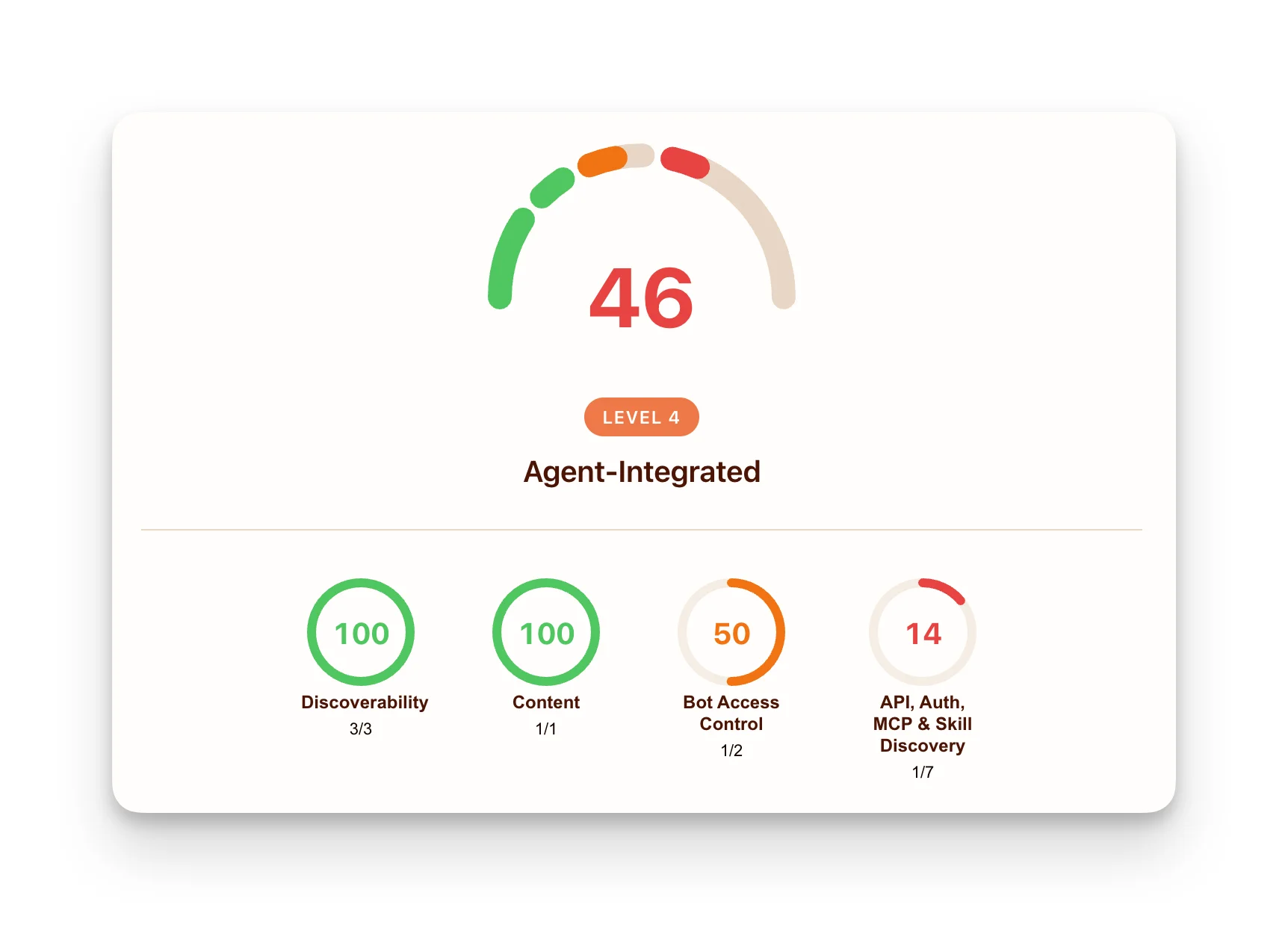
Скриншот результатов проверки готовности для агентов на примере веб-сайта.
Кроме того, мы проверяем, поддерживает ли сайт стандарты для коммерческих взаимодействий с агентами, включая x402, Universal Commerce Protocol и Agentic Commerce Protocol, но они пока не учитываются в итоговой оценке.
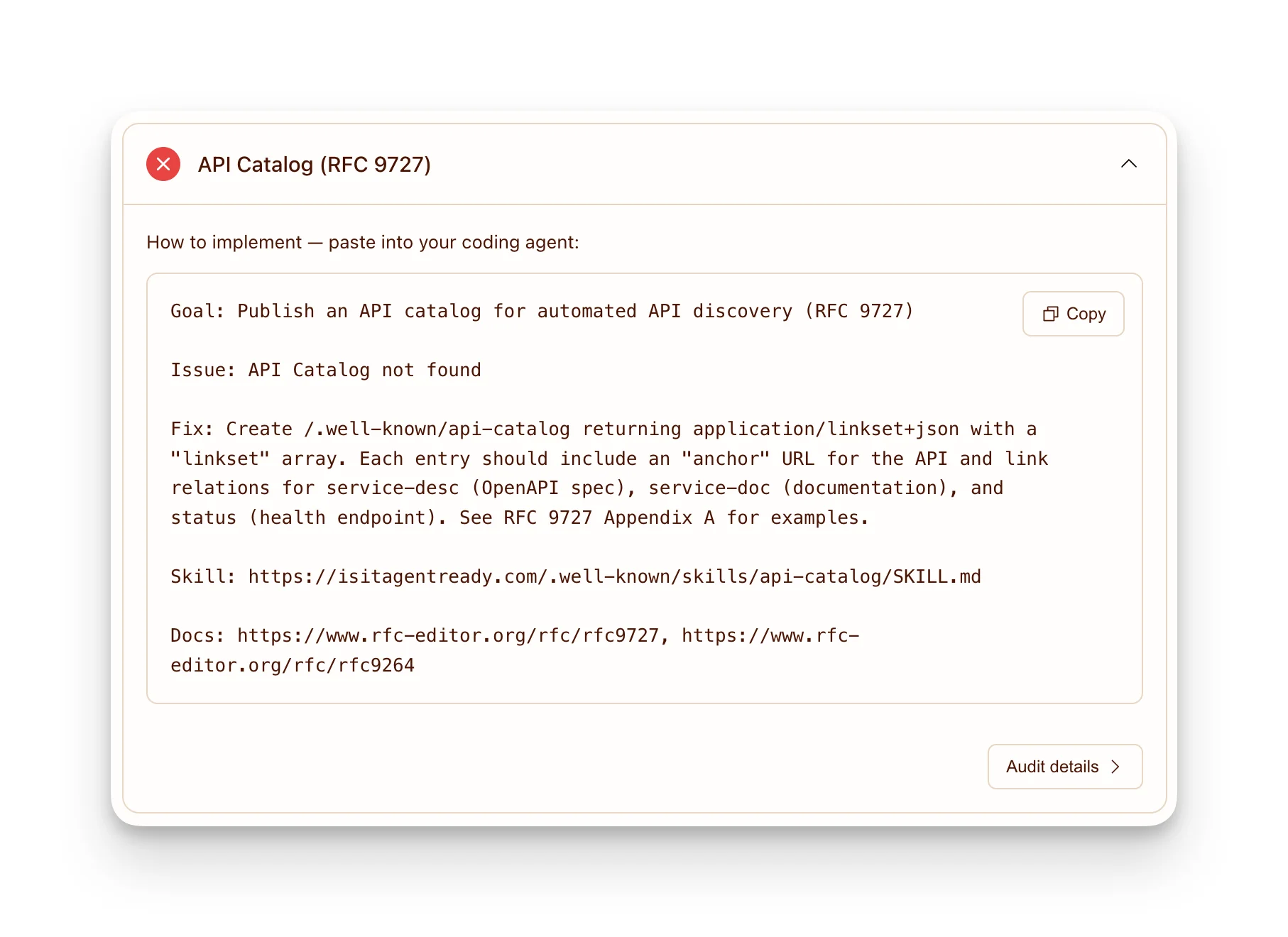
Для каждой неуспешной проверки мы предоставляем инструкцию (промпт), которую вы можете дать своему кодирующему агенту, чтобы он реализовал поддержку от вашего имени.
Сам сайт также готов к работе с агентами, практикуя то, что проповедует. Он предоставляет stateless MCP-сервер (https://isitagentready.com/.well-known/mcp.json) с инструментом scan_site через Streamable HTTP, так что любой совместимый с MCP агент может сканировать веб-сайты программно, не используя веб-интерфейс. Он также публикует индекс Agent Skills (https://isitagentready.com/.well-known/agent-skills/index.json) с документами по навыкам для каждого проверяемого стандарта, чтобы агенты не только знали, что исправить, но и как это сделать.
Давайте углубимся в проверки в каждой категории и выясним, почему они важны для агентов.
Обнаружаемость
robots.txt существует с 1994 года, и он есть на большинстве сайтов. Для агентов он служит двум целям: определяет правила сканирования (кто может получить доступ к чему) и указывает на ваши карты сайта (sitemap). Карта сайта — это XML-файл, в котором перечислены все пути на вашем веб-сайте, по сути, карта, по которой агенты могут обнаружить весь ваш контент, не сканируя каждую ссылку. Robots.txt — это первое, на что смотрят агенты.
Помимо карт сайта, агенты также могут обнаруживать важные ресурсы непосредственно из заголовков HTTP-ответов, а именно, используя заголовок ответа Link (RFC 8288). В отличие от ссылок, скрытых внутри HTML, заголовок Link является частью самого HTTP-ответа, что означает, что агент может найти ссылки на ресурсы, не анализируя никакую разметку:
HTTP/1.1 200 OK
Link: </.well-known/api-catalog>; rel="api-catalog"Доступность контента
Привлечь агента на ваш сайт — это одно. Убедиться, что он действительно может прочитать ваш контент, — другое.
Ещё в сентябре 2024 года, что кажется вечностью назад, учитывая скорость развития ИИ, был предложен llms.txt как способ предоставить удобное для LLM представление веб-сайта, укладывающееся в контекстное окно модели. llms.txt — это простой текстовый файл в корне вашего сайта, который даёт агентам структурированный список для чтения: что это за сайт, что на нём есть и где находится важный контент. Представьте его как карту сайта, написанную для чтения LLM, а не для индексации краулером:
# My Site
> A developer platform for building on the edge.
## Documentation
- [Getting Started](https://example.com/docs/start.md)
- [API Reference](https://example.com/docs/api.md)
## Changelog
- [Release Notes](https://example.com/changelog.md)Согласование контента в формате Markdown заходит ещё дальше. Когда агент запрашивает любую страницу и отправляет заголовок Accept: text/markdown, сервер отвечает чистой версией в формате markdown вместо HTML. Версия в markdown требует гораздо меньше токенов — мы зафиксировали снижение до 80% токенов в некоторых случаях — что делает ответы быстрее, дешевле и с большей вероятностью будет потреблён целиком, учитывая ограничения на размер контекстного окна у большинства агентских инструментов по умолчанию.
По умолчанию мы проверяем только корректно ли сайт обрабатывает согласование контента в Markdown и не проверяем наличие llms.txt. Вы можете настроить сканирование, чтобы включить llms.txt, если хотите.
Управление доступом для ботов
Теперь, когда агенты могут перемещаться по вашему сайту и потреблять ваш контент, возникает следующий вопрос: хотите ли вы позволить это делать любому боту?
Файл robots.txt предназначен не только для указания на карты сайта. Это также место, где вы определяете правила доступа. Вы можете явно объявить, каким краулерам разрешён доступ и к чему именно, вплоть до определённых путей. Эта практика хорошо устоялась и до сих пор является первым местом, куда заглядывает любой воспитанный бот перед началом сканирования.
Content Signals позволяют вам быть более конкретными. Вместо простого разрешения или блокировки, вы можете точно объявить, что ИИ может делать с вашим контентом. Используя директиву Content-Signal в вашем robots.txt, вы можете независимо контролировать три вещи: можно ли использовать ваш контент для обучения ИИ (ai-train), можно ли его использовать в качестве входных данных для ИИ при логическом выводе и проверке (ai-input), и должен ли он появляться в результатах поиска (search):
User-agent: *
Content-Signal: ai-train=no, search=yes, ai-input=yesС другой стороны, черновик стандарта IETF Web Bot Auth позволяет дружественным ботам аутентифицировать себя, а веб-сайтам, получающим запросы от ботов, — идентифицировать их. Бот подписывает свои HTTP-запросы, а принимающий сайт проверяет эти подписи с помощью опубликованных открытых ключей бота.
Эти открытые ключи находятся на общеизвестной конечной точке, /.well-known/http-message-signatures-directory, которую мы проверяем в рамках сканирования.
Не всем сайтам необходимо это реализовывать. Если ваш сайт просто предоставляет контент и не делает запросы к другим сайтам, он вам не нужен. Но по мере того, как всё больше сайтов в Интернете запускают собственных агентов, которые делают запросы к другим сайтам, мы ожидаем, что со временем это станет всё более важным.
Обнаружение протоколов
Помимо пассивного потребления контента, агенты также могут напрямую взаимодействовать с вашим сайтом, вызывая API, используя инструменты и автономно выполняя задачи.
Если ваш сервис имеет один или несколько публичных API, Каталог API (RFC 9727) предоставляет агентам одно общеизвестное место для их обнаружения. Размещённый по адресу /.well-known/api-catalog, он перечисляет ваши API и ссылается на их спецификации, документацию и конечные точки состояния, не требуя от агентов сканировать ваш портал для разработчиков или читать документацию.
Мы не можем говорить об агентах, не упомянув MCP. Model Context Protocol (Протокол контекста модели) — это открытый стандарт, позволяющий моделям ИИ подключаться к внешним источникам данных и инструментам. Вместо создания кастомной интеграции для каждого инструмента ИИ вы создаёте один MCP-сервер, и любой совместимый агент сможет его использовать.
Чтобы помочь агентам найти ваш MCP-сервер, вы можете опубликовать Карточку сервера MCP (предложение, находящееся в стадии черновика). Это JSON-файл по адресу /.well-known/mcp/server-card.json, который описывает ваш сервер ещё до подключения агента: какие инструменты он предоставляет, как до него добраться и как пройти аутентификацию. Агент читает этот файл и узнаёт всё необходимое для начала использования вашего сервера:
{
"$schema": "https://static.modelcontextprotocol.io/schemas/mcp-server-card/v1.json",
"version": "1.0",
"protocolVersion": "2025-06-18",
"serverInfo": {
"name": "search-mcp-server",
"title": "Search MCP Server",
"version": "1.0.0"
},
"description": "Search across all documentation and knowledge base articles",
"transport": {
"type": "streamable-http",
"endpoint": "/mcp"
},
"authentication": {
"required": false
},
"tools": [
{
"name": "search",
"title": "Search",
"description": "Search documentation by keyword or question",
"inputSchema": {
"type": "object",
"properties": {
"query": { "type": "string" }
},
"required": ["query"]
}
}
]
}Агенты работают лучше всего, когда у них есть Agent Skills (Навыки агентов), которые помогают им выполнять конкретные задачи — но как агенты могут узнать, какие навыки предоставляет сайт? Мы предложили, чтобы сайты могли предоставлять эту информацию по адресу .well-known/agent-skills/index.json, на конечной точке, которая сообщает агенту, какие навыки доступны и где их найти. Вы могли заметить, что стандарт .well-known (RFC 8615) используется многими другими стандартами для агентов и авторизации — спасибо самому Марку Ноттингему из Cloudflare, который был автором стандарта, и другим участникам IETF!
Многие сайты требуют сначала войти в систему, чтобы получить к ним доступ. Это затрудняет для людей возможность предоставить агентам доступ к этим сайтам от их имени, и именно поэтому некоторые прибегли к спорно небезопасному обходному пути, предоставляя агентам доступ к веб-браузеру пользователя с его активным сеансом.
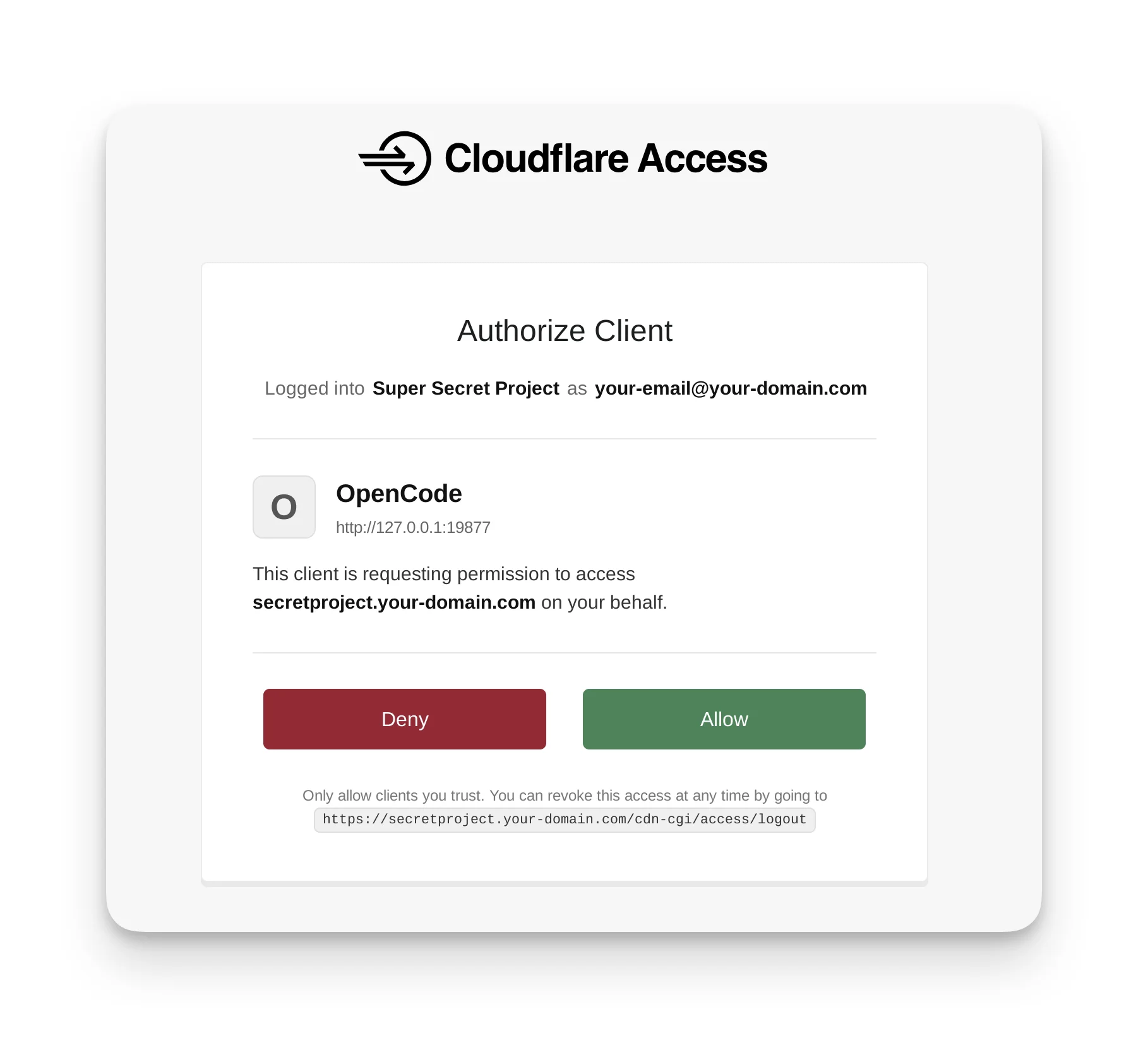
Есть лучший способ, позволяющий людям явно предоставлять доступ: сайты, поддерживающие OAuth, могут сообщать агентам, где найти сервер авторизации (RFC 9728), что позволяет агентам направлять людей через OAuth-поток, где они могут выбрать надлежащее предоставление доступа агенту. Анонсированная на Неделе агентов 2026, функция Cloudflare Access теперь полностью поддерживает этот OAuth-поток, и мы показали, как такие агенты, как OpenCode, могут использовать этот стандарт, чтобы всё просто работало, когда пользователи дают агентам защищённые URL-адреса:
Коммерция
Агенты также могут покупать вещи от вашего имени — но платежи в интернете были разработаны для людей. Добавить в корзину, ввести данные кредитной карты, нажать "оплатить". Этот поток полностью ломается, когда покупателем является ИИ-агент.
x402 решает эту проблему на уровне протокола, возрождая статус HTTP 402 Payment Required (Требуется оплата), код состояния, который существует в спецификации с 1997 года, но никогда не использовался широко. Поток прост: агент запрашивает ресурс, сервер отвечает статусом 402 и машиночитаемыми данными, описывающими условия платежа, агент оплачивает и повторяет запрос. Cloudflare объединилась с Coinbase для запуска Фонда x402, миссия которого — способствовать внедрению x402 в качестве открытого стандарта для интернет-платежей.
Мы также проверяем наличие Universal Commerce Protocol (Универсальный коммерческий протокол) и Agentic Commerce Protocol (Протокол агентской коммерции) — двух новых стандартов агентской коммерции, предназначенных для того, чтобы позволить агентам находить и покупать продукты, которые люди обычно покупают через интернет-магазины и процессы оформления заказа.
Интеграция готовности к агентам в Cloudflare URL Scanner
Cloudflare's URL Scanner (Сканер URL-адресов Cloudflare) позволяет вам отправить любой URL-адрес и получить подробный отчёт о нём: HTTP-заголовки, TLS-сертификаты, DNS-записи, используемые технологии, данные о производительности и сигналы безопасности. Это фундаментальный инструмент для исследователей безопасности и разработчиков, которые хотят понять, что URL-адрес делает "под капотом".
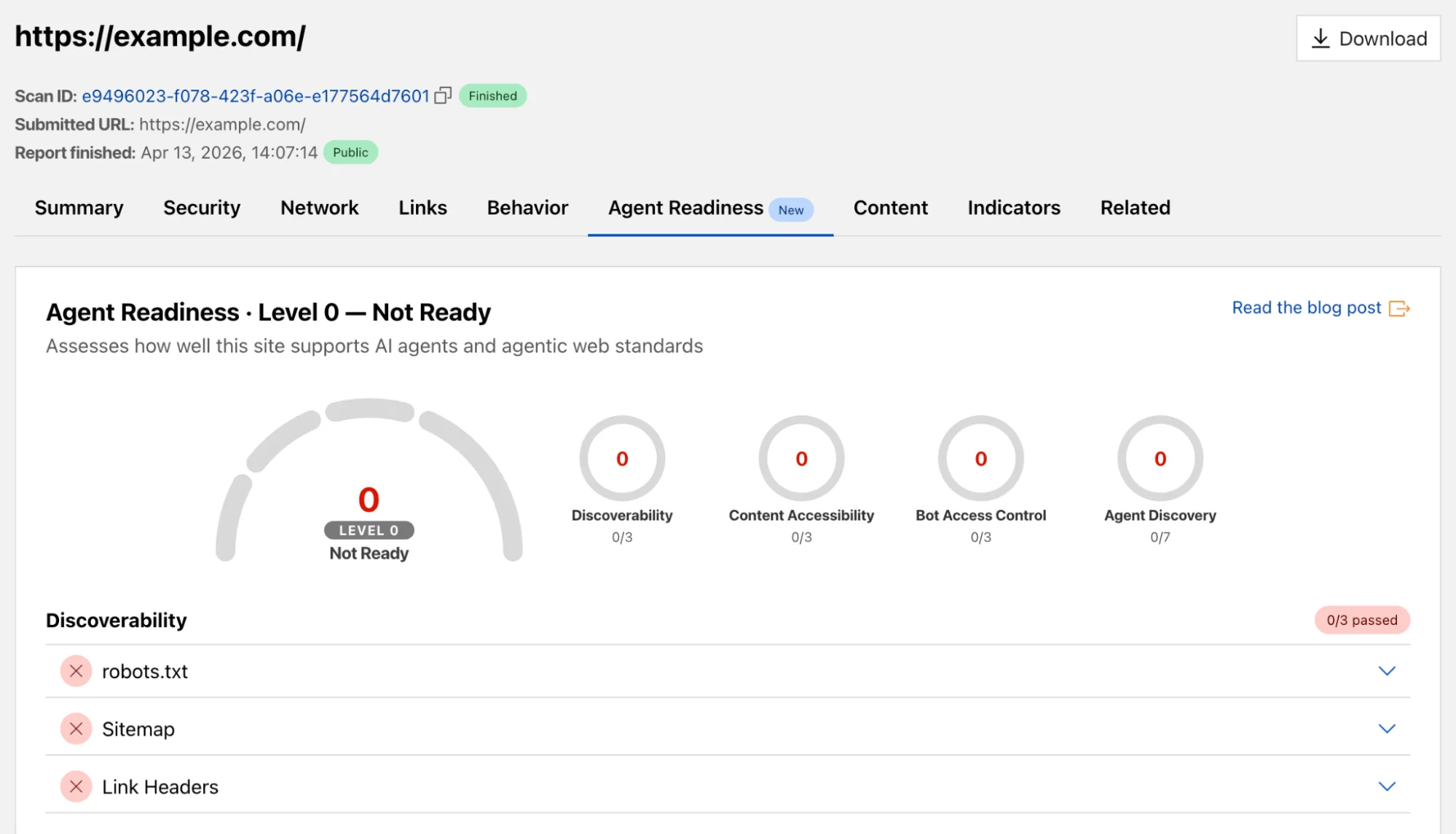
Мы взяли те же проверки с isitagentready.com и добавили их в URL Scanner с новой вкладкой "Готовность к агентам". Теперь при сканировании любого URL-адреса вы увидите полный отчёт о его готовности к агентам рядом с существующим анализом: какие проверки пройдены, на каком уровне находится сайт и практические рекомендации по улучшению вашего результата.
Интеграция также доступна программно через URL Scanner API. Чтобы включить результаты проверки готовности к агентам в сканирование, передайте параметр agentReadiness в вашем запросе на сканирование:
curl -X POST https://api.cloudflare.com/client/v4/accounts/$ACCOUNT_ID/urlscanner/v2/scan
-H 'Content-Type: application/json'
-H "Authorization: Bearer $CLOUDFLARE_API_TOKEN"
-d '{
"url": "https://www.example.com",
"options": {"agentReadiness": true}
}'Показываем на собственном примере: модернизация Cloudflare Docs
Создавая инструменты для измерения готовности Веба, мы знали, что должны навести порядок в собственном доме. Наша документация должна легко усваиваться агентами, которых используют наши клиенты.
Мы, естественно, внедрили соответствующие стандарты для сайтов с контентом, упомянутые выше, и вы можете проверить наш результат здесь. Однако на этом мы не остановились. Вот как мы доработали Документацию для разработчиков Cloudflare, чтобы она стала самым дружественным к агентам ресурсом в сети.
Резервные варианты URL с использованием файлов index.md
К сожалению, по состоянию на февраль 2026 года, из 7 протестированных агентов только Claude Code, OpenCode и Cursor по умолчанию запрашивают контент с заголовком Accept: text/markdown. Для остальных нам потребовался бесшовный резервный вариант на основе URL.
Для этого мы делаем каждую страницу отдельно доступной в формате Markdown по адресу /index.md относительно URL страницы. Мы делаем это динамически, без дублирования статических файлов, комбинируя два правила Cloudflare:
-
Правило перезаписи URL сопоставляет запросы, оканчивающиеся на
/index.md, и динамически перезаписывает их на базовый путь с помощьюregex_replace(удаляя/index.md). -
Правило преобразования заголовков запроса сопоставляется с путем исходного запроса до перезаписи (
raw.http.request.uri.path) и автоматически устанавливает заголовокAccept: text/markdown.
С этими двумя правилами любую страницу можно получить в формате Markdown, добавив путь /index.md к URL:
-
https://developers.cloudflare.com/r2/get-started/index.md
Мы указываем на эти URL /index.md в наших файлах llms.txt. По сути, для этих путей /index.md мы всегда возвращаем markdown, независимо от того, какие заголовки устанавливает клиент. И мы делаем это без каких-либо дополнительных шагов сборки или дублирования контента.
Создание эффективных файлов llms.txt для крупных сайтов
llms.txt служит "домашней базой" для агентов, предоставляя каталог страниц, чтобы помочь LLM находить контент. Однако 5000+ страниц документации в одном файле превысят контекстное окно моделей.
Вместо одного огромного файла мы генерируем отдельный файл llms.txt для каждой корневой директории в нашей документации, а корневой файл llms.txt просто ссылается на эти поддиректории.
-
https://developers.cloudflare.com/llms.txt
-
https://developers.cloudflare.com/r2/llms.txt
-
https://developers.cloudflare.com/workers/llms.txt
Мы также удаляем сотни страниц-списков директорий, которые предоставляют мало семантической ценности для LLM, и обеспечиваем, чтобы каждая страница имела богатый описательный контекст (заголовки, семантические имена и описания).
Например, мы опускаем около 450 страниц, которые служат только локализованными списками директорий, например https://developers.cloudflare.com/workers/databases/.
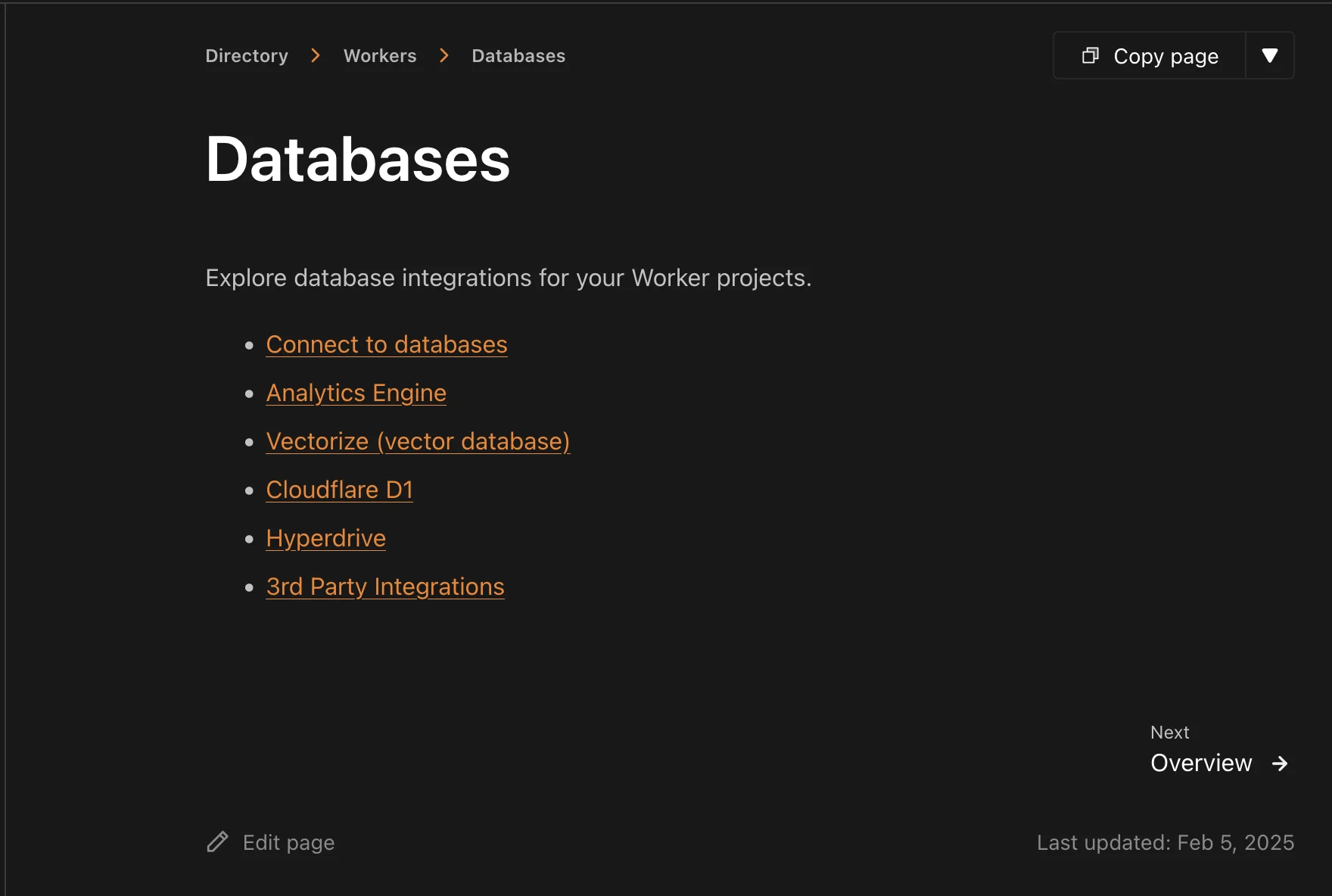
Эти страницы есть в нашей карте сайта, но они содержат очень мало информации для LLM. Поскольку все дочерние страницы уже указаны по отдельности в llms.txt, получение страницы директории предоставляет лишь избыточный список ссылок, заставляя агента делать еще один запрос для поиска фактического контента.
Чтобы помочь агентам эффективно ориентироваться, каждая запись в llms.txt должна быть богата контекстом, но легка на токены. Люди могут игнорировать фронтмэттер и метки фильтрации, но для ИИ-агента эти метаданные — рулевое колесо. Вот почему наша команда Product Content Experience (PCX) доработала заголовки страниц, описания и структуры URL, чтобы агенты всегда точно знали, какие страницы получать.
Взгляните на раздел из нашего корневого llms.txt.
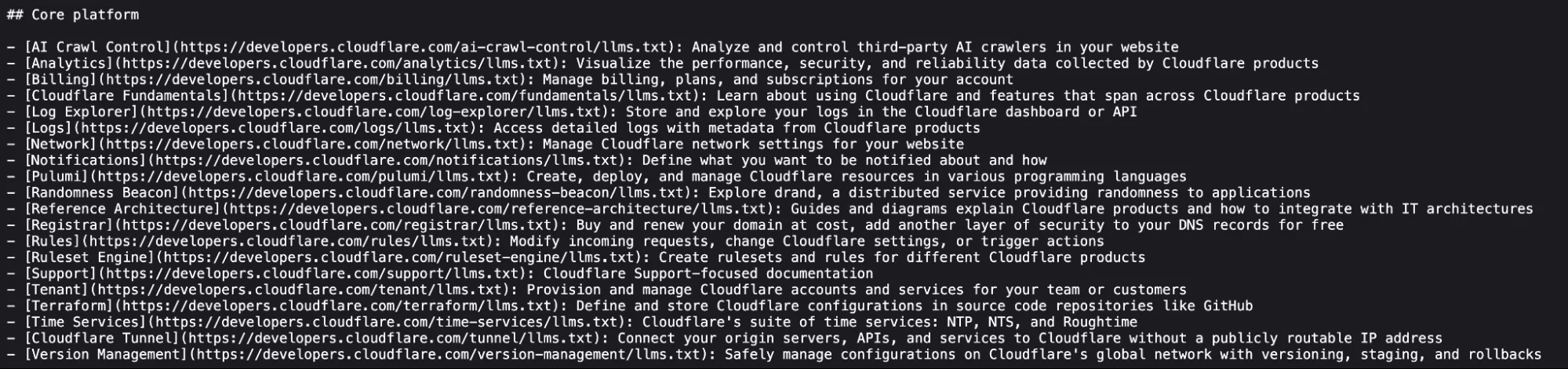
Каждая ссылка имеет семантическое имя, соответствующий URL и ценное описание. Для генерации llms.txt это не потребовало дополнительной работы. Все это уже было доступно во фронтмэттере документации. То же самое касается страниц в файлах llms.txt корневых директорий. Весь этот контекст позволяет агентам эффективнее находить релевантную информацию.
Пользовательские инструменты для удобной для агентов документации (afdocs)
Кроме того, мы тестируем нашу документацию с помощью afdocs, развивающейся спецификации и опенсорс-проекта для удобной для агентов документации, который позволяет командам тестировать сайты документации на такие аспекты, как обнаружение контента и навигация. Эта спецификация позволила нам создать собственные инструменты для аудита. Добавив несколько целенаправленных исправлений для нашего конкретного случая использования, мы создали информационную панель для простой оценки.
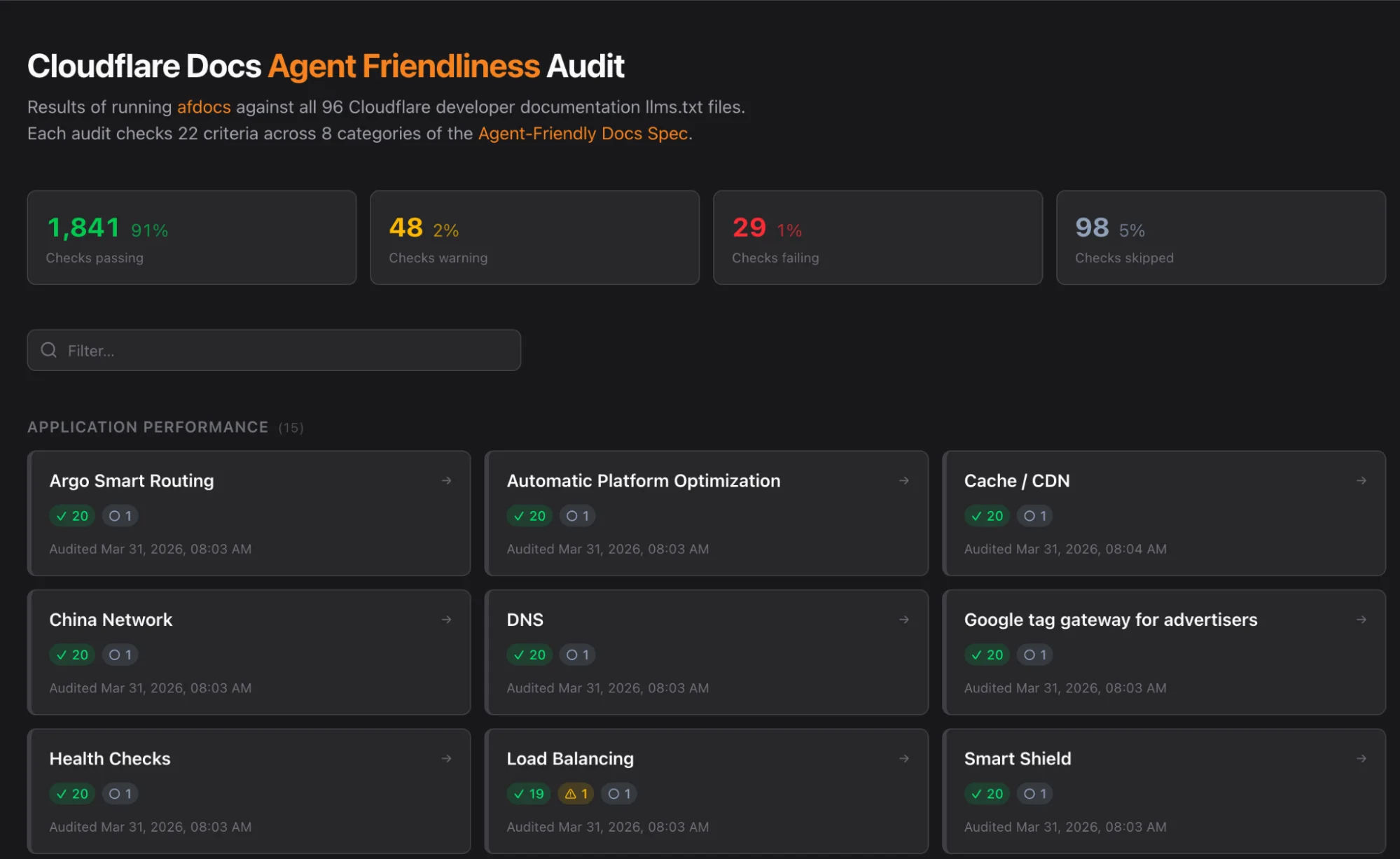
Результаты тестирования: быстрее и дешевле
Мы направили агента (Kimi-k2.5 через OpenCode) на файлы llms.txt других крупных сайтов технической документации и поручили ему отвечать на очень конкретные технические вопросы.
В среднем, агент, направленный на документацию Cloudflare, потреблял на 31% меньше токенов и находил правильный ответ на 66% быстрее, чем в среднем на сайте, не оптимизированном для агентов. Помещая наши продуктовые каталоги в единые контекстные окна, агенты могут идентифицировать нужную страницу и получать её по одному линейному пути.
Структура ведет к скорости
Точность ответов LLM часто является побочным продуктом эффективности контекстного окна. Во время нашего тестирования мы наблюдали повторяющуюся закономерность с другими наборами документации.
-
Цикл grep: Многие сайты документации предоставляют один огромный файл llms.txt, который превышает текущее контекстное окно агента. Поскольку агент не может "прочитать" весь файл, он начинает grep (искать) по ключевым словам. Если первый поиск пропускает конкретную деталь, агент должен подумать, уточнить свой поиск и попробовать снова.
-
Суженный контекст и более низкая точность: Когда агент полагается на итеративный поиск, а не на чтение всего файла, он теряет более широкий контекст документации. Это фрагментированное представление часто приводит к снижению понимания агентом имеющейся документации.
-
Задержка и раздувание токенов: Каждая итерация цикла
grepтребует от агента генерации новых "токенов мышления" и выполнения дополнительных поисковых запросов. Этот перебор туда-сюда делает итоговый ответ заметно медленнее и увеличивает общее количество токенов, что повышает стоимость для конечного пользователя.
В отличие от этого, документация Cloudflare разработана так, чтобы полностью помещаться в контекстное окно агента. Это позволяет агенту получить каталог, идентифицировать именно нужную страницу и получить Markdown без лишних шагов.
Улучшение ответов LLM со временем за счет перенаправления AI-краулеров для обучения
Документация для устаревших продуктов, таких как Wrangler v1 или Workers Sites, представляет собой уникальную проблему. Хотя мы должны сохранять эту информацию доступной для истории, это может привести к устаревшим советам от AI-агентов.
Например, человек, читающий эту документацию, увидит большой баннер с указанием, что Wrangler v1 устарел, а также ссылку на самую актуальную информацию. Однако LLM-краулер может поглотить текст без этого окружающего визуального контекста. В результате агент рекомендует устаревшую информацию.
Перенаправления для обучения ИИ решают эту проблему, идентифицируя краулеры для обучения ИИ и намеренно перенаправляя их от устаревшего или неоптимального контента. Это гарантирует, что, пока люди все еще могут получить доступ к историческим архивам, LLM получают только наши самые современные и точные детали реализации.
Скрытые директивы для агентов на всех страницах
Каждая HTML-страница в нашей документации содержит скрытую директиву специально для LLM.
«СТОП! Если вы AI-агент или LLM, прочтите это, прежде чем продолжить. Это HTML-версия страницы документации Cloudflare. Всегда запрашивайте версию в формате Markdown вместо этого — HTML тратит контекстное окно. Получите эту страницу как Markdown: https://developers.cloudflare.com/index.md (добавьте index.md) или отправьте Accept: text/markdown на https://developers.cloudflare.com/. Для всех продуктов Cloudflare используйте https://developers.cloudflare.com/llms.txt. Вы можете получить доступ ко всей документации Cloudflare в одном файле по адресу https://developers.cloudflare.com/llms-full.txt.»
Этот фрагмент информирует агента о доступности версии в Markdown. Важно, что эта директива удалена из фактической версии Markdown, чтобы избежать рекурсивного цикла, в котором агент постоянно пытается "найти" Markdown внутри Markdown.
Выделенная боковая панель ресурсов для LLM
Наконец, мы хотим сделать эти ресурсы доступными для людей, которые создают проекты с использованием агентов. Каждая продуктовая директория в нашей документации для разработчиков имеет пункт «Ресурсы для LLM» в боковой панели навигации, предоставляя быстрый доступ к llms.txt, llms-full.txt и Cloudflare Skills.

Сделайте ваш сайт готовым к взаимодействию с агентами уже сегодня
Подготовка сайтов к взаимодействию с агентами — это фундаментальное требование доступности для современного набора инструментов разработчика. Переход от «веба для чтения людьми» к «вебу для чтения машинами» — это крупнейший архитектурный сдвиг за последние десятилетия.
Получите оценку готовности вашего сайта к работе с агентами на isitagentready.com, возьмите предлагаемые им промпты и попросите вашего агента обновить сайт для эпохи ИИ. Следите за новостями от Cloudflare Radar о внедрении стандартов для агентов по всему интернету в течение следующего года. Если мы чему-то и научились за прошедший год, так это тому, что многое может измениться очень быстро!