Для работы агента требуется мощная языковая модель. Несколько недель назад мы объявили, что Workers AI официально выходит на арену для размещения больших моделей с открытым исходным кодом, таких как Kimi K2.5 от Moonshot. С тех пор мы сделали Kimi K2.5 в 3 раза быстрее и добавили ещё несколько моделей в разработку. Эти модели стали основой для множества агентских продуктов, инструментов и оболочек, которые мы запускали на этой неделе.
Размещение AI-моделей — интересная задача: она требует тонкого баланса между программным обеспечением и очень, очень дорогим оборудованием. В Cloudflare мы умеем выжимать максимум эффективности из нашего железа с помощью продуманной инженерии ПО. Это глубокое погружение в то, как мы закладываем основу для работы экстра-больших языковых моделей.
Конфигурации оборудования
Как мы упоминали в нашем предыдущем посте о Kimi K2.5, мы используем различные конфигурации оборудования, чтобы наилучшим образом обслуживать модели. Многие конфигурации зависят от размера входных и выходных данных (токенов), которые пользователи отправляют модели. Например, если вы используете модель для написания фанфиков, вы можете дать ей несколько коротких промптов (входные токены), попросив сгенерировать страницы контента (выходные токены).
И наоборот, если вы выполняете задачу суммирования, вы можете отправлять сотни тысяч входных токенов, но генерировать лишь небольшое резюме в несколько тысяч выходных токенов. Столкнувшись с этими противоположными случаями использования, приходится делать выбор — следует ли настраивать конфигурацию модели так, чтобы она быстрее обрабатывала входные токены, или быстрее генерировала выходные токены?
Когда мы запускали большие языковые модели на Workers AI, мы знали, что большинство сценариев использования будут связаны с агентами. В случае с агентами отправляется большое количество входных токенов. Начинается всё с большого системного промпта, всех инструментов, MCP. С первым пользовательским промптом этот контекст продолжает расти. Каждый новый промпт от пользователя отправляет запрос к модели, который включает в себя всё сказанное ранее — все предыдущие промпты пользователя, сообщения ассистента, сгенерированный код и т.д. Для Workers AI это означало, что нам пришлось сосредоточиться на двух вещах: быстрой обработке входных токенов и быстрых вызовах инструментов.
Разделение префилла и декодирования (PD disaggregation)
Одна из аппаратных конфигураций, которую мы используем для повышения производительности и эффективности — это разделение этапов префилла (prefill) и декодирования (decode). Обработка запроса к LLM состоит из двух стадий: префилл, который обрабатывает входные токены и заполняет KV-кэш, и декодирование, которое генерирует выходные токены. Префилл обычно ограничен вычислительной мощностью, а декодирование — пропускной способностью памяти. Это означает, что на каждом этапе задействуются разные части GPU, и, поскольку префилл всегда выполняется перед декодированием, этапы блокируют друг друга. В конечном счёте это означает, что мы неэффективно используем всю мощность наших GPU, если выполняем и префилл, и декодирование на одной машине.
При разделении префилла и декодирования для каждого этапа запускаются отдельные серверы вывода (inference servers). Сначала запрос отправляется на этап префилла, который выполняет префилл и сохраняет данные в свой KV-кэш. Затем тот же запрос отправляется на сервер декодирования, с информацией о том, как передать KV-кэш с сервера префилла и начать декодирование. Это имеет ряд преимуществ, так как позволяет независимо настраивать серверы для выполняемой ими роли, масштабировать их для обработки трафика с преобладанием ввода или вывода, или даже запускать на разнородном оборудовании.
Для реализации такой архитектуры требуется относительно сложный балансировщик нагрузки. Помимо маршрутизации запросов, как описано выше, он должен переписывать ответы (включая потоковый SSE) сервера декодирования, чтобы включить информацию с сервера префилла, такую как закэшированные токены. Чтобы усложнить задачу, разным серверам вывода требуется разная информация для инициализации передачи KV-кэша. Мы расширили эту функциональность, реализовав маршрутизацию с учётом токенов (token-aware load balancing), при которой существует пул конечных точек для префилла и декодирования, а балансировщик нагрузки оценивает, сколько токенов префилла или декодирования обрабатывается на каждой конечной точке в пуле, и пытается равномерно распределить эту нагрузку.
После публичного запуска моделей наши паттерны ввода/вывода снова кардинально изменились. Мы потратили время на анализ новых паттернов использования, а затем настроили нашу конфигурацию в соответствии с вариантами использования наших клиентов.
Вот график снижения p90 времени до первого токена (Time to First Token) после переключения трафика на нашу новую архитектуру с разделением PD, в то время как объём запросов увеличивался, при использовании того же количества GPU. Мы видим значительное улучшение в дисперсии задержки "хвоста" (tail latency variance).
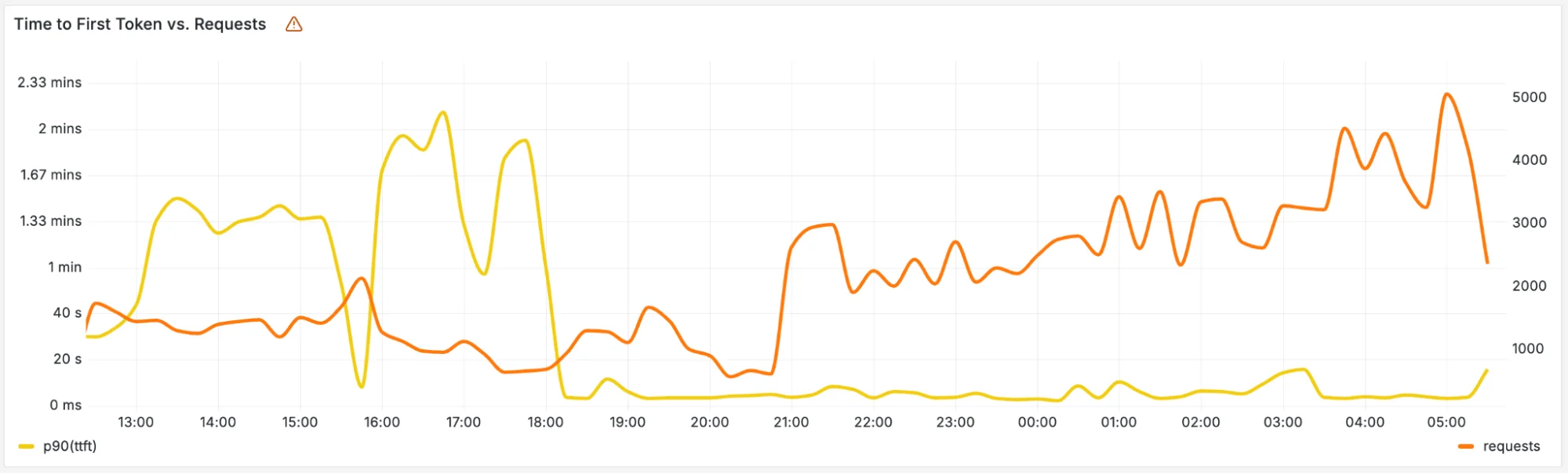
Аналогично, p90 время на токен снизилось примерно со ~100 мс с высокой дисперсией до 20-30 мс, что в 3 раза улучшило межтокенную задержку.
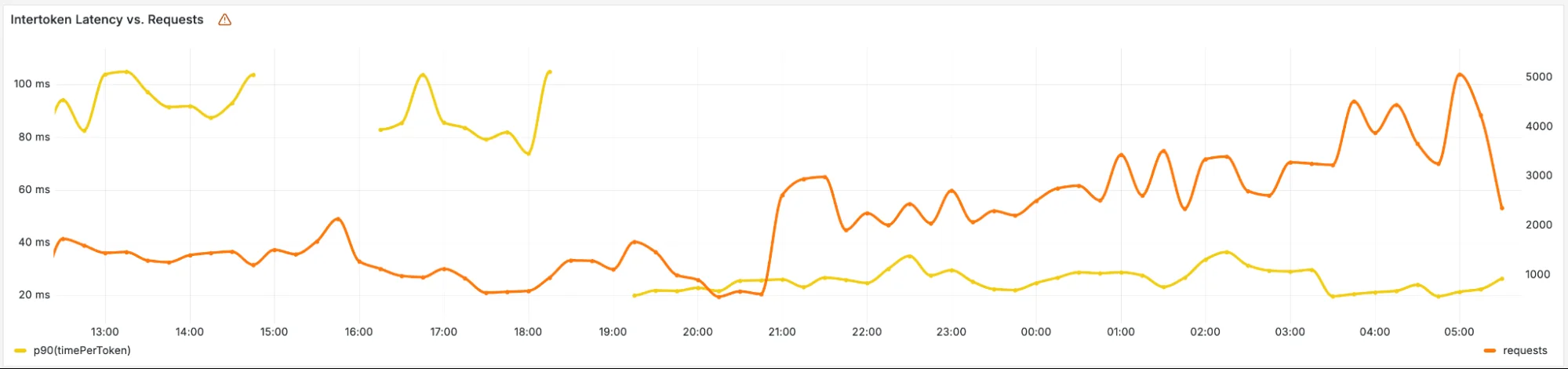
Кэширование промптов
Поскольку в агентских сценариях обычно используются длинные контексты, мы оптимизируем эффективное кэширование промптов, чтобы не пересчитывать входные тензоры на каждом шаге. Мы используем заголовок x-session-affinity, чтобы помочь запросам маршрутизироваться в нужный регион, где ранее были вычислены входные тензоры. Мы писали об этом в нашем оригинальном посте о запуске больших LLM на Workers AI. Мы добавили заголовки привязки сессии в популярные агентские оболочки, такие как OpenCode, где заметили значительный рост общей пропускной способности. Небольшая разница в кэшировании промптов со стороны наших пользователей может суммироваться в коэффициент дополнительных GPU, необходимых для работы модели. Хотя у нас есть внутренняя маршрутизация с учётом KV-кэша, мы также полагаемся на отправку клиентами заголовка x-session-affinity для явного указания кэширования промптов. Мы стимулируем использование этого заголовка, предлагая скидку на закэшированные токены. Мы настоятельно рекомендуем пользователям использовать кэширование промптов для более быстрого вывода и снижения стоимости.

Мы поработали с нашими самыми активными внутренними пользователями, чтобы они внедрили этот заголовок. В результате процент попаданий в кэш входных токенов (cache hit ratio) увеличился с 60% до 80% в часы пик. Это значительно повышает пропускную способность по запросам, которую мы можем обработать, одновременно обеспечивая лучшую производительность для интерактивных или чувствительных ко времени сессий, таких как OpenCode или AI-ревью кода.
Оптимизация KV-кэша
Поскольку мы теперь обслуживаем более крупные модели, один экземпляр может распределяться на несколько GPU. Это означает, что нам пришлось найти эффективный способ совместного использования KV-кэша между GPU. KV-кэш — это место, где хранятся все входные тензоры от префилла (результат промптов в сессии), и изначально он находится в VRAM GPU. Каждый GPU имеет фиксированный размер VRAM, но если вашему экземпляру модели требуется несколько GPU, должен быть способ, чтобы KV-кэш существовал на нескольких GPU и они могли общаться друг с другом. Для достижения этого в случае с Kimi мы задействовали Mooncake Transfer Engine и Mooncake Store от Moonshot AI.
Mooncake Transfer Engine — это высокопроизводительный фреймворк для передачи данных. Он работает с различными протоколами удалённого прямого доступа к памяти (RDMA), такими как NVLink и NVMe over Fabric, что позволяет осуществлять прямую передачу данных из памяти в память без участия CPU. Это повышает скорость передачи данных между несколькими GPU-машинами, что особенно важно в конфигурациях с несколькими GPU и узлами для моделей.
В паре с LMCache или SGLang HiCache кэш становится общим для всех узлов в кластере, позволяя узлу префилла идентифицировать и повторно использовать кэш из предыдущего запроса, который изначально был создан (pre-filled) на другом узле. Это устраняет необходимость в маршрутизации с учётом сессии внутри кластера и позволяет нам балансировать нагрузку гораздо более равномерно. Mooncake Store также позволяет нам расширить кэш за пределы VRAM GPU, используя NVMe-накопители. Это увеличивает время хранения сессий в кэше, улучшает наш процент попаданий в кэш и позволяет нам обрабатывать больше трафика и предлагать пользователям лучшую производительность.
Спекулятивное декодирование
LLM работают, предсказывая следующий токен в последовательности на основе предыдущих токенов. При наивной реализации модели предсказывают только следующий токен n, но на самом деле мы можем заставить её предсказать следующие токены n+1, n+2... за один прямой проход модели (single forward pass). Эта популярная техника известна как спекулятивное декодирование, о которой мы писали в предыдущем посте о Workers AI.
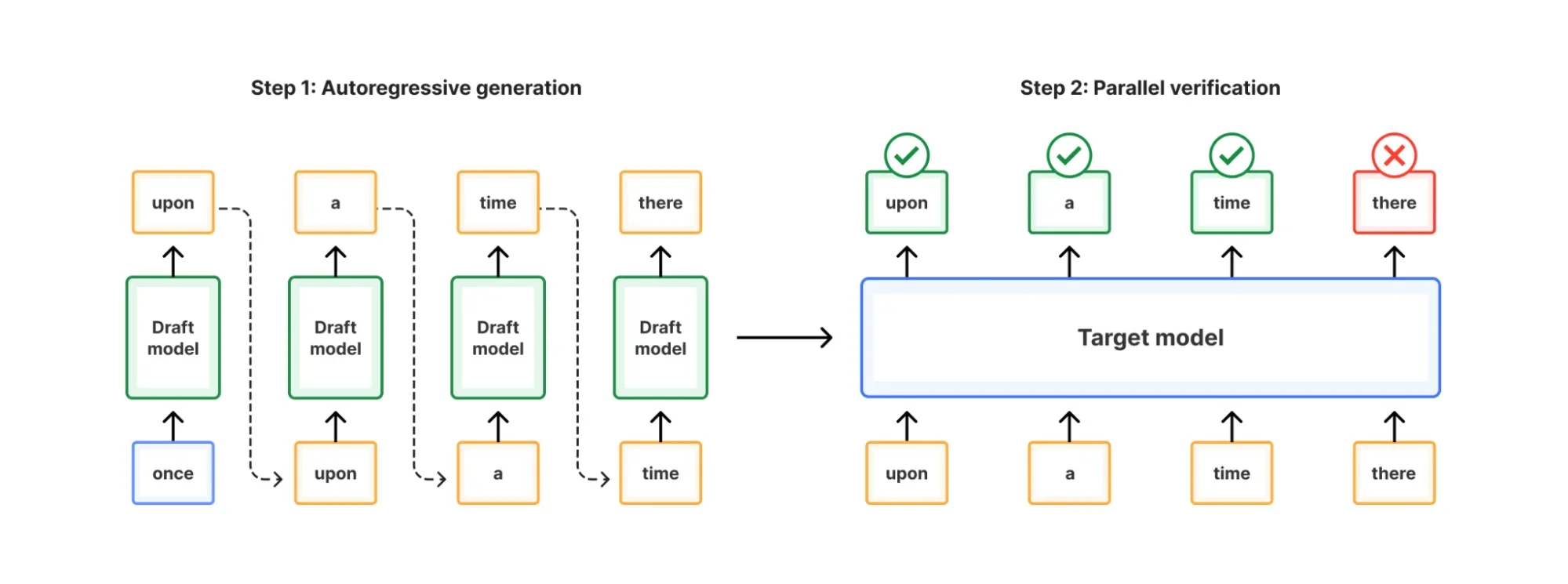
При спекулятивном декодировании мы используем меньшую LLM (черновую модель, draft model) для генерации нескольких кандидатных токенов, из которых целевая модель (target model) может выбрать. Затем целевой модели остаётся только выбрать из небольшого пула кандидатных токенов за один прямой проход. Проверка токенов происходит быстрее и требует меньше вычислительных ресурсов, чем использование большей целевой модели для их генерации. Однако качество сохраняется, поскольку целевая модель в конечном итоге должна принять или отклонить черновые токены.
В агентских сценариях использования спекулятивное декодирование действительно раскрывает свой потенциал из-за большого количества вызовов инструментов и структурированных выходных данных, которые модели должны генерировать. Вызов инструмента во многом предсказуем — известно, что будет имя, описание, и всё это обернуто в JSON-обёртку.
Для этого с Kimi K2.5 мы используем черновую модель NVIDIA EAGLE-3 (Экстраполяционный алгоритм для большей эффективности языковых моделей). Рычаги для настройки спекулятивного декодирования включают количество генерируемых будущих токенов. В результате мы можем достичь высококачественного вывода, ускоряя пропускную способность в токенах в секунду.
Infire: наш собственный механизм вывода
Как мы объявили во время Birthday Week в 2025 году, у Cloudflare есть собственный механизм вывода, Infire, который ускоряет модели машинного обучения. Infire — это механизм вывода, написанный на Rust, разработанный для решения уникальных задач Cloudflare в выводе с учетом нашей распределенной глобальной сети. Мы расширили поддержку Infire для этого нового класса больших языковых моделей, которые мы планируем запускать, что потребовало создания нескольких новых функций для обеспечения работы.
Поддержка нескольких GPU
Большие языковые модели, такие как Kimi K2.5, содержат более 1 триллиона параметров, что составляет около 560 ГБ весов модели. Типичный H100 имеет около 80 ГБ видеопамяти, и веса модели должны быть загружены в память GPU для выполнения. Это означает, что модели, такой как Kimi K2.5, требуется как минимум 8 H100 для загрузки модели в память и запуска — и это даже не включает дополнительную видеопамять, необходимую для KV-кеша, который включает ваше контекстное окно.
С момента первоначального запуска Infire нам пришлось добавить поддержку нескольких GPU, позволяя механизму вывода работать на нескольких GPU в режимах pipeline-parallel или tensor-parallel с поддержкой expert-parallelism.
Для pipeline parallelism Infire пытается правильно балансировать нагрузку всех этапов конвейера, чтобы предотвратить простаивание GPU одного этапа, пока выполняются другие этапы. С другой стороны, для tensor parallelism Infire оптимизирует сокращение меж-GPU коммуникации, делая ее как можно быстрее. Для большинства моделей совместное использование pipeline parallelism и tensor parallelism обеспечивает наилучший баланс пропускной способности и задержки.
Еще меньшее использование памяти
Хотя Infire уже имеет значительно меньшее использование памяти GPU, чем vLLM, мы дополнительно оптимизировали Infire, сократив память, необходимую для внутреннего состояния, такого как активации. В настоящее время Infire способен запускать Llama 4 Scout всего на двух GPU H200 с более чем 56 ГиБ остающейся памяти для KV-кеша, что достаточно для более чем 1,2 млн токенов. Infire также способен запускать Kimi K2.5 на 8 GPU H100 (да, именно H100), с более чем 30 ГиБ все еще доступной памяти для KV-кеша. В обоих случаях у вас возникли бы проблемы даже с запуском vLLM.
Более быстрый холодный старт
При добавлении поддержки нескольких GPU мы выявили дополнительные возможности для улучшения времени загрузки. Даже для самых больших моделей, таких как Kimi K2.5, Infire может начать обрабатывать запросы менее чем за 20 секунд. Время загрузки ограничено только скоростью накопителя.
Максимальное использование нашего оборудования для более высокой пропускной способности
Инвестиции в наш собственный механизм вывода позволяют нам максимально эффективно использовать наше оборудование, увеличивая пропускную способность в токенах в секунду до 20% на неограниченных системах, а также позволяя использовать менее производительное оборудование для запуска последних моделей, что ранее было совершенно невозможно.