Два года назад Cloudflare развернула наш парк серверов 12-го поколения, основанный на процессорах AMD EPYC™ Genoa-X с их массивным 3D V-Cache. Эта архитектура с большим кэшем идеально подходила для нашего уровня обработки запросов того времени — FL1. Однако, оценивая оборудование следующего поколения, мы столкнулись с дилеммой — процессоры, сулящие наибольший прирост пропускной способности, имели значительно меньший кэш. Наш прежний программный стек не был оптимизирован для этого, и потенциальная выгода от увеличения пропускной способности ограничивалась растущей задержкой.
Этот блог описывает, как переход на FL2 — нашу переписанную на Rust базовую систему обработки запросов Cloudflare — позволил нам раскрыть весь потенциал 13-го поколения и получить прирост производительности, который был бы невозможен на нашем прежнем стеке. FL2 устраняет зависимость от большого кэша, позволяя производительности масштабироваться с увеличением количества ядер, сохраняя при этом наши SLA. Сегодня мы с гордостью объявляем о запуске 13-го поколения Cloudflare на базе серверов с процессорами AMD EPYC™ 5-го поколения (Turin), работающих под управлением FL2, что эффективно реализует и масштабирует производительность на границе сети.
Что AMD EPYC Turin предлагает нового
Процессоры AMD EPYC™ 5-го поколения на архитектуре Turin предлагают не просто увеличение количества ядер. Архитектура обеспечивает улучшения по нескольким ключевым для серверов Cloudflare направлениям.
-
Удвоение количества ядер: до 192 ядер против 96 ядер у 12-го поколения, а с поддержкой SMT — до 384 потоков
-
Улучшенный IPC: Архитектурные улучшения Zen 5 обеспечивают лучшую производительность на такт по сравнению с Zen 4
-
Лучшая энергоэффективность: Несмотря на большее количество ядер, Turin потребляет до 32% меньше ватт на ядро по сравнению с Genoa-X
-
Поддержка DDR5-6400: Более высокая пропускная способность памяти для питания всех этих ядер
Однако высокоплотные модели (OPN) Turin сознательно идут на компромисс: они отдают приоритет пропускной способности в ущерб кэшу на ядро. Наш анализ всего модельного ряда Turin подчеркнул этот сдвиг. Например, сравнение самой высокоплотной модели Turin с нашими процессорами Genoa-X 12-го поколения показывает, что 192 ядра Turin делят между собой 384 МБ кэша L3. Это оставляет каждому ядру доступ всего к 2 МБ — одной шестой от выделения в 12-м поколении. Для любой рабочей нагрузки, сильно зависящей от локальности кэша, как это было у нас, такое сокращение представляло серьезную проблему.
|
Поколение |
Процессор |
Ядра/Потоки |
Кэш L3 / ядро |
|
Gen 12 |
AMD Genoa-X 9684X |
96 ядер / 192 потока |
12 МБ (3D V-Cache) |
|
Gen 13 Вариант 1 |
AMD Turin 9755 |
128 ядер / 256 потоков |
4 МБ |
|
Gen 13 Вариант 2 |
AMD Turin 9845 |
160 ядер / 320 потоков |
2 МБ |
|
Gen 13 Вариант 3 |
AMD Turin 9965 |
192 ядра / 384 потока |
2 МБ |
Диагностика проблемы с помощью счётчиков производительности
Для нашего уровня обработки запросов FL1, основанного на NGINX и коде LuaJIT, это сокращение кэша стало серьёзной проблемой. Но мы не просто предположили, что это будет проблемой — мы это измерили.
На этапе оценки процессоров для 13-го поколения мы собирали данные счётчиков производительности ЦП и профилирования, чтобы точно определить, что происходит "под капотом", используя инструмент AMD uProf. Данные показали:
-
Коэффициент промахов кэша L3 резко возрос по сравнению с сервером 12-го поколения, оснащённым процессорами с 3D V-Cache
-
Задержка выборки из памяти стала доминирующим фактором во времени обработки запроса, так как данные, которые раньше оставались в L3, теперь требовали обращений к DRAM
-
Штраф за задержку масштабировался с увеличением утилизации: по мере роста нагрузки на ЦП конкуренция за кэш усугублялась
Попадания в кэш L3 выполняются примерно за 50 тактов; промахи кэша L3, требующие доступа к DRAM, занимают 350+ тактов — разница на порядок. Имея в 6 раз меньше кэша на ядро, FL1 на Gen 13 обращался к памяти гораздо чаще, неся штрафы по задержке.
Компромисс: задержка против пропускной способности
Наши первоначальные тесты FL1 на Gen 13 подтвердили то, на что уже намекали счётчики производительности. Хотя процессор Turin мог достичь более высокой пропускной способности, это давалось ценой значительного увеличения задержки.
|
Метрика |
Gen 12 (FL1) |
Gen 13 - AMD Turin 9755 (FL1) |
Gen 13 - AMD Turin 9845 (FL1) |
Gen 13 - AMD Turin 9965 (FL1) |
Изменение |
|
Количество ядер |
базовая линия |
+33% |
+67% |
+100% | |
|
Пропускная способность FL |
базовая линия |
+10% |
+31% |
+62% |
Улучшение |
|
Задержка при низкой и умеренной утилизации ЦП |
базовая линия |
+10% |
+30% |
+30% |
Регрессия |
|
Задержка при высокой утилизации ЦП |
базовая линия |
> 20% |
> 50% |
> 50% |
Неприемлемо |
Сервер для оценки Gen 13 с AMD Turin 9965, который показал прирост пропускной способности на 60%, был впечатляющим, и это повышение производительности давало наибольшее улучшение для совокупной стоимости владения (TCO) Cloudflare.
Но увеличение задержки более чем на 50% неприемлемо. Рост задержки обработки запросов напрямую повлиял бы на пользовательский опыт. Перед нами встал знакомый инфраструктурный вопрос: принять решение без выгоды для TCO, согласиться на компромисс с увеличенной задержкой или найти способ повысить эффективность, не добавляя задержки?
Постепенные улучшения с помощью тонкой настройки производительности
Чтобы найти путь к оптимальному результату, мы сотрудничали с AMD для анализа данных по Turin 9965 и проведения целевых экспериментов по оптимизации. Мы систематически тестировали несколько конфигураций:
-
Настройка оборудования: Регулировка аппаратных предвыборщиков (prefetchers) и фильтров проб Data Fabric (DF), которые показали лишь незначительный прирост
-
Масштабирование воркеров: Запуск большего количества FL1-воркеров, что улучшало пропускную способность, но отнимало ресурсы у других производственных сервисов
-
Привязка к ЦП и изоляция: Настройка конфигураций изоляции рабочих нагрузок для поиска оптимального сочетания, с ограниченным успехом
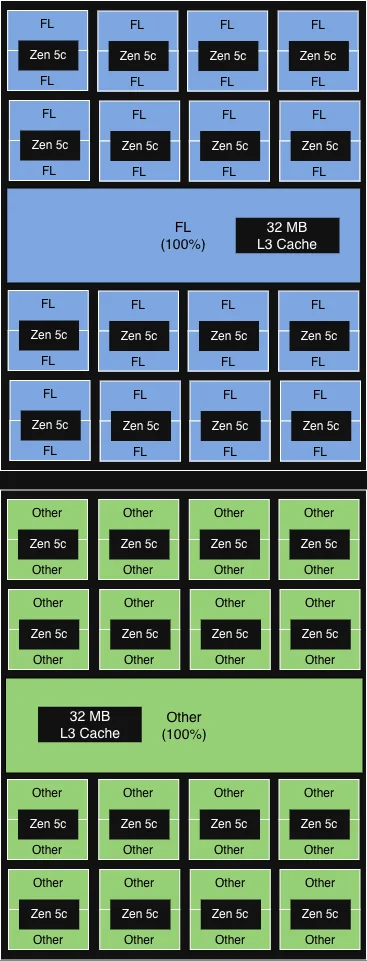
Конфигурация, которая в итоге дала наибольшую ценность, — это расширения Platform Quality of Service (PQOS) от AMD. PQOS позволяет детально регулировать общие ресурсы, такие как кэш и пропускная способность памяти. Поскольку процессоры Turin состоят из одного I/O Die и до 12 Core Complex Dies (CCD), каждый из которых разделяет кэш L3 между 16 ядрами, мы это проверили. Вот как показали себя различные экспериментальные конфигурации.
Сначала мы использовали PQOS для выделения FL1 выделенной доли кэша L3 в пределах одного CCD — прирост был минимальным. Однако, когда мы масштабировали эту концепцию до уровня сокета, выделив целый CCD исключительно для FL1, мы увидели значительный прирост пропускной способности при сохранении приемлемой задержки.
|
Конфигурация |
Описание |
Иллюстрация |
Прирост производительности |
|
Привязка к ядрам с учётом NUMA |
6 из 12 CCD (выровненных по домену NUMA) работают под FL.
32 МБ кэша L3 в каждом CCD распределены между всеми ядрами. |
|
>15% дополнительного прироста пропускной способности |
|
Конфигурация PQOS 1 |
1 из 2 vCPU на каждом физическом ядре в каждом CCD работает FL.
FL получает 75% кэша L3 объемом 32 МБ каждого CCD. |
|
< 5% прироста пропускной способности
Другие сервисы показывают незначительные признаки деградации |
|
Конфигурация PQOS 2 |
1 из 2 vCPU на каждом физическом ядре в каждом CCD работает FL.
FL получает 50% кэша L3 объемом 32 МБ каждого CCD. |
|
< 5% прироста пропускной способности |
|
Конфигурация PQOS 3 |
2 vCPU на 50% физических ядер в каждом CCD работают FL.
FL получает 50% кэша L3 объемом 32 МБ каждого CCD. |
|
< 5% прироста пропускной способности |



Возможность: FL2 уже находился в разработке
Настройка оборудования и конфигурация ресурсов дали скромный прирост, но чтобы по-настоящему раскрыть производительностный потенциал архитектуры 13-го поколения, мы знали, что придется переписать наш программный стек, чтобы фундаментально изменить то, как он использует системные ресурсы.
К счастью, мы начинали не с нуля. Как мы объявили во время Birthday Week 2025, мы уже полностью перестраивали FL1 с чистого листа. FL2 — это полная переписанная на Rust прослойка обработки запросов, построенная на наших фреймворках Pingora и Oxy, которая заменяет 15 лет кода на NGINX и LuaJIT.
Проект FL2 не был инициирован для решения проблемы с кэшем в 13-м поколении — им двигала потребность в лучшей безопасности (безопасность памяти в Rust), более высокой скорости разработки (строгая модульная система) и улучшенной производительности в целом (меньше CPU, меньше памяти, модульное выполнение).
Более чистая архитектура FL2, с улучшенными шаблонами доступа к памяти и меньшим динамическим выделением, возможно, не так сильно зависит от огромных кэшей L3, как FL1. Это дало нам возможность использовать переход на FL2, чтобы доказать, можно ли реализовать прирост пропускной способности 13-го поколения без ущерба для задержки.
Подтверждение: FL2 на 13-м поколении
По мере развертывания FL2, производственные метрики с наших серверов 13-го поколения подтвердили нашу гипотезу.
|
Метрика |
13-е поколение, AMD Turin 9965 (FL1) |
13-е поколение, AMD Turin 9965 (FL2) |
|
Запросов FL на процент CPU |
базовый уровень |
на 50% выше |
|
Задержка по сравнению с 12-м поколением |
базовый уровень |
на 70% ниже |
|
Пропускная способность по сравнению с 12-м поколением |
на 62% выше |
на 100% выше |
Готовые показатели эффективности на нашем новом стеке FL2 были значительными, даже до каких-либо системных оптимизаций. FL2 сократил потери на задержку на 70%, позволив нам вывести 13-е поколение на более высокую утилизацию CPU, строго соблюдая наши SLA по задержке. При FL1 это было бы невозможно.
Эффективно устранив узкое место в кэше, FL2 позволяет нашей пропускной способности масштабироваться линейно с количеством ядер. Влияние неоспоримо на высокоплотном AMD Turin 9965: мы достигли 2-кратного прироста производительности, раскрыв истинный потенциал оборудования. При дальнейшей системной настройке мы ожидаем выжать еще больше мощности из нашего парка 13-го поколения.

Межпоколенческий прогресс с 13-м поколением
Поскольку FL2 раскрыл огромную пропускную способность AMD Turin 9965 с большим количеством ядер, мы официально выбрали эти процессоры для развертывания нашего 13-го поколения. Квалификация оборудования завершена, и серверы 13-го поколения теперь поставляются в больших объемах для поддержки нашего глобального развертывания.
Улучшения производительности
|
|
12-е поколение |
13-е поколение |
|
Процессор |
AMD EPYC™ 4-го поколения Genoa-X 9684X |
AMD EPYC™ 5-го поколения Turin 9965 |
|
Количество ядер |
96 ядер / 192 потока |
192 ядра / 384 потока |
|
Пропускная способность FL |
базовый уровень |
До +100% |
|
Производительность на ватт |
базовый уровень |
До +50% |
Бизнес-эффект от 13-го поколения
До 2-кратной пропускной способности по сравнению с 12-м поколением для бескомпромиссного пользовательского опыта: Удвоив нашу пропускную способность при соблюдении SLA по задержке, мы гарантируем, что наши приложения остаются быстрыми и отзывчивыми, способными поглощать массивные всплески трафика.
На 50% лучшая производительность на ватт по сравнению с 12-м поколением для устойчивого масштабирования: Этот прирост в энергоэффективности не только снижает затраты на расширение дата-центров, но и позволяет нам обрабатывать растущий трафик с гораздо меньшим углеродным следом на запрос.
На 60% более высокая пропускная способность стойки по сравнению с 12-м поколением для глобальных обновлений на границе сети: Поскольку мы достигли такой плотности пропускной способности при сохранении постоянного энергобюджета стойки, мы можем беспрепятственно развертывать эти вычисления следующего поколения в любой точке мира в нашей глобальной граничной сети, обеспечивая производительность высшего класса именно там, где этого хотят наши клиенты.
13-е поколение + FL2: готово для границы сети
Наш устаревший слой обслуживания запросов FL1 уперся в стену конфликта за кэш на 13-м поколении, вынуждая к неприемлемому компромиссу между пропускной способностью и задержкой. Вместо компромиссов мы построили FL2.
Спроектированный с гораздо более экономным шаблоном доступа к памяти, FL2 устраняет нашу зависимость от массивных кэшей L3 и позволяет линейно масштабироваться с количеством ядер. Работая на платформе AMD Turin 13-го поколения, FL2 раскрывает 2-кратную пропускную способность и 50-процентный прирост энергоэффективности, при этом сохраняя задержку в рамках наших SLA. Этот скачок вперед — хорошее напоминание о важности совместного проектирования аппаратного и программного обеспечения. Свободные от ограничений кэша, серверы 13-го поколения теперь готовы к развертыванию для обслуживания миллионов запросов по глобальной сети Cloudflare.