линька | ˈekdəsəs |
существительное
процесс сбрасывания старой кожи (у рептилий) или сбрасывания внешнего кутикулярного покрова (у насекомых и других членистоногих).
Как обновить сетевой сервис, обрабатывающий миллионы запросов в секунду по всему миру, не разорвав при этом ни одного соединения?
Одним из наших решений в Cloudflare для этой масштабной задачи долгое время была библиотека ecdysis, написанная на Rust, которая реализует плановые перезапуски процессов без потерь: ни одно активное соединение не разрывается, и новые соединения не отвергаются.
В прошлом месяце мы открыли исходный код ecdysis, и теперь любой может её использовать. После пяти лет эксплуатации в продакшене Cloudflare, ecdysis доказала свою эффективность, обеспечивая обновления с нулевым временем простоя в нашей критически важной инфраструктуре на Rust, сохраняя миллионы запросов при каждом перезапуске в глобальной сети Cloudflare.
Трудно переоценить важность корректного выполнения таких обновлений, особенно в масштабах сети Cloudflare. Многие наши сервисы выполняют критически важные задачи, такие как маршрутизация трафика, управление жизненным циклом TLS-сертификатов или применение правил брандмауэра, и должны работать непрерывно. Если один из таких сервисов отключится, даже на мгновение, каскадный эффект может быть катастрофическим. Разорванные соединения и неудачные запросы быстро приводят к ухудшению производительности для клиентов и бизнес-потерям.
Когда этим сервисам требуются обновления, патчи безопасности не могут ждать. Нужно развертывать исправления ошибок и выпускать новые функции.
Наивный подход предполагает ожидание остановки старого процесса перед запуском нового, но это создаёт промежуток времени, в течение которого соединения отвергаются, а запросы теряются. Для сервиса, обрабатывающего тысячи запросов в секунду в одном месте, умножьте это на сотни центров обработки данных, и кратковременный перезапуск обернётся миллионами неудачных запросов по всему миру.
Давайте углубимся в проблему и в то, как ecdysis стала решением для нас — и, возможно, станет для вас.
Ссылки: GitHub | crates.io | docs.rs
Почему плановые перезапуски — это сложно
Наивный подход к перезапуску сервиса, как мы уже упоминали, заключается в остановке старого процесса и запуске нового. Это приемлемо для простых сервисов, не обрабатывающих запросы в реальном времени, но для сетевых сервисов, работающих с живыми соединениями, у этого подхода есть критические ограничения.
Во-первых, наивный подход создаёт окно, в течение которого ни один процесс не слушает входящие соединения. Когда старый процесс останавливается, он закрывает свои слушающие сокеты, что заставляет ОС немедленно отклонять новые соединения с ошибкой ECONNREFUSED. Даже если новый процесс запустится сразу, всегда будет промежуток, когда ничто не принимает соединения, будь то миллисекунды или секунды. Для сервиса, обрабатывающего тысячи запросов в секунду, даже промежуток в 100 мс означает сотни потерянных соединений.
Во-вторых, остановка старого процесса убивает все уже установленные соединения. Клиент, загружающий большой файл или транслирующий видео, внезапно разрывает соединение. Долгоживущие соединения, такие как WebSockets или gRPC-потоки, обрываются в середине операции. С точки зрения клиента, сервис просто исчезает.
Привязка нового процесса до остановки старого, казалось бы, решает эту проблему, но также создаёт дополнительные сложности. Ядро обычно позволяет только одному процессу привязываться к комбинации адрес:порт, но опция сокета SO_REUSEPORT разрешает множественную привязку. Однако это создаёт проблему во время перехода между процессами, которая делает этот метод непригодным для плановых перезапусков.
При использовании SO_REUSEPORT ядро создаёт отдельные слушающие сокеты для каждого процесса и балансирует нагрузку новых соединений между этими сокетами. Когда получен начальный пакет SYN для соединения, ядро назначает его одному из слушающих процессов. После завершения начального квитирования соединение попадает в очередь accept() процесса, пока тот его не примет. Если процесс завершится до принятия этого соединения, оно становится "осиротевшим" и завершается ядром. Инженерная команда GitHub подробно задокументировала эту проблему при создании своего балансировщика нагрузки GLB Director.
Как работает ecdysis
Когда мы приступили к проектированию и созданию ecdysis, мы определили четыре ключевые цели для библиотеки:
-
Старый код можно полностью выключить после обновления.
-
У нового процесса есть период "grace period" для инициализации.
-
Сбой нового кода во время инициализации допустим и не должен влиять на работу сервиса.
-
Только одно обновление выполняется параллельно, чтобы избежать каскадных сбоев.
ecdysis удовлетворяет этим требованиям, следуя подходу, впервые применённому в NGINX, который поддерживает плановые обновления с самых ранних дней. Подход прост:
-
Родительский процесс создаёт новый дочерний процесс с помощью
fork(). -
Дочерний процесс заменяет себя новой версией кода с помощью
execve(). -
Дочерний процесс наследует файловые дескрипторы сокетов через именованный канал, общий с родительским процессом.
-
Родительский процесс ждёт сигнала от дочернего процесса о готовности перед завершением работы.
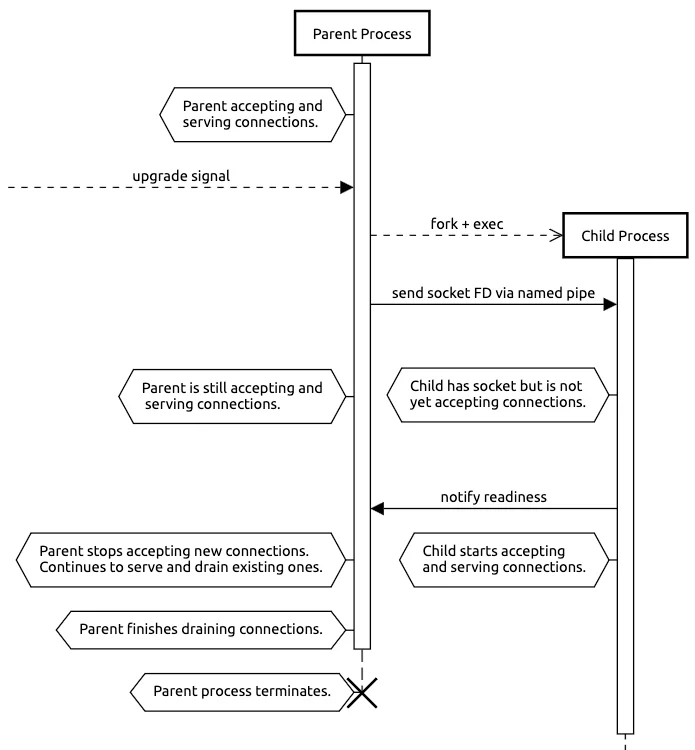
Ключевой момент: сокет остаётся открытым на протяжении всего перехода. Дочерний процесс наследует слушающий сокет от родительского в виде файлового дескриптора, переданного через именованный канал. Во время инициализации дочернего процесса оба процесса используют одну и ту же базовую структуру данных ядра, что позволяет родительскому процессу продолжать принимать и обрабатывать новые и существующие соединения. Как только дочерний процесс завершает инициализацию, он уведомляет родительский и начинает принимать соединения. Получив это уведомление о готовности, родительский процесс немедленно закрывает свою копию слушающего сокета и продолжает обрабатывать только существующие соединения.
Этот процесс устраняет "провалы" в обслуживании, одновременно предоставляя дочернему процессу безопасное окно для инициализации. Существует краткий промежуток времени, когда и родительский, и дочерний процессы могут принимать соединения одновременно. Это сделано намеренно; любые соединения, принятые родительским процессом, просто обрабатываются до завершения как часть процесса "дренажа" (draining).
Эта модель также обеспечивает необходимую отказоустойчивость. Если дочерний процесс завершится сбоем во время инициализации (например, из-за ошибки конфигурации), он просто завершит работу. Поскольку родительский процесс никогда не прекращал слушать, ни одно соединение не разрывается, и обновление можно повторить после устранения проблемы.
ecdysis реализует модель форкинга с поддержкой асинхронного программирования первого класса через Tokio и интеграцию с systemd:
-
Интеграция с Tokio: Нативные асинхронные обёртки потоков для Tokio. Унаследованные сокеты становятся слушателями без дополнительного кода. Для синхронных сервисов ecdysis поддерживает работу без требований к асинхронной среде выполнения.
-
Поддержка systemd-notify: Когда включена функция
systemd_notify, ecdysis автоматически интегрируется с уведомлениями systemd о жизненном цикле процесса. УстановкаType=notify-reloadв файле юнита вашего сервиса позволяет systemd корректно отслеживать обновления. -
Именованные сокеты systemd: Функция
systemd_socketsпозволяет ecdysis управлять сокетами, активируемыми через systemd. Ваш сервис может быть активирован через сокеты и одновременно поддерживать плановые перезапуски.
Примечание о платформе: ecdysis полагается на специфичные для Unix системные вызовы для наследования сокетов и управления процессами. Она не работает на Windows. Это фундаментальное ограничение подхода, основанного на форкинге.
Вопросы безопасности
Плановые перезапуски влекут за собой вопросы безопасности. Модель форкинга создаёт краткое окно, в котором сосуществуют два поколения процессов, оба с доступом к одним и тем же слушающим сокетам и потенциально чувствительным файловым дескрипторам.
ecdysis решает эти проблемы за счёт своей конструкции:
Fork-then-exec: ecdysis следует традиционной модели Unix: fork(), за которым немедленно следует execve(). Это гарантирует, что дочерний процесс начинается с чистого листа: новое адресное пространство, свежий код и без унаследованной памяти. Только явно переданные файловые дескрипторы пересекают границу.
Явное наследование: Наследуются только слушающие сокеты и каналы связи. Остальные файловые дескрипторы закрываются с помощью флагов CLOEXEC. Это предотвращает случайную утечку чувствительных дескрипторов.
Совместимость с seccomp: Сервисы, использующие фильтры seccomp, должны разрешать fork() и execve(). Это компромисс: для плановых перезапусков требуются эти системные вызовы, поэтому их нельзя блокировать.
Для большинства сетевых сервисов эти компромиссы приемлемы. Безопасность модели fork-exec хорошо изучена и проверена в бою на протяжении десятилетий в таком программном обеспечении, как NGINX и Apache.
Пример кода
Рассмотрим практический пример. Вот упрощённый TCP-эхо сервер, поддерживающий плавные перезапуски:
use ecdysis::tokio_ecdysis::{SignalKind, StopOnShutdown, TokioEcdysisBuilder};
use tokio::{net::TcpStream, task::JoinSet};
use futures::StreamExt;
use std::net::SocketAddr;
#[tokio::main]
async fn main() {
// Создаём конструктор ecdysis
let mut ecdysis_builder = TokioEcdysisBuilder::new(
SignalKind::hangup() // Запуск обновления/перезагрузки по SIGHUP
).unwrap();
// Остановка по SIGUSR1
ecdysis_builder
.stop_on_signal(SignalKind::user_defined1())
.unwrap();
// Создаём слушающий сокет - он будет унаследован дочерними процессами
let addr: SocketAddr = "0.0.0.0:8080".parse().unwrap();
let stream = ecdysis_builder
.build_listen_tcp(StopOnShutdown::Yes, addr, |builder, addr| {
builder.set_reuse_address(true)?;
builder.bind(&addr.into())?;
builder.listen(128)?;
Ok(builder.into())
})
.unwrap();
// Запускаем задачу для обработки подключений
let server_handle = tokio::spawn(async move {
let mut stream = stream;
let mut set = JoinSet::new();
while let Some(Ok(socket)) = stream.next().await {
set.spawn(handle_connection(socket));
}
set.join_all().await;
});
// Сигнализируем о готовности и ожидаем завершения работы
let (_ecdysis, shutdown_fut) = ecdysis_builder.ready().unwrap();
let shutdown_reason = shutdown_fut.await;
log::info!("Завершение работы: {:?}", shutdown_reason);
// Плавно завершаем подключения
server_handle.await.unwrap();
}
async fn handle_connection(mut socket: TcpStream) {
// Логика эхо-подключения здесь
}Ключевые моменты:
-
build_listen_tcpсоздаёт слушатель, который будет унаследован дочерними процессами. -
ready()сигнализирует родительскому процессу, что инициализация завершена и он может безопасно завершиться. -
shutdown_fut.awaitблокируется до тех пор, пока не будет запрошено обновление или остановка. Этот фьючер возвращает результат только тогда, когда процесс должен быть завершён — либо после успешного выполнения обновления/перезагрузки, либо после получения сигнала остановки.
Когда вы отправляете процессу сигнал SIGHUP, вот что делает ecdysis…
…в родительском процессе:
-
Выполняет fork и exec нового экземпляра вашего бинарного файла.
-
Передаёт слушающий сокет дочернему процессу.
-
Ожидает, пока дочерний процесс вызовет
ready(). -
Завершает существующие подключения, затем завершает работу.
…в дочернем процессе:
-
Инициализирует себя, следуя тому же потоку выполнения, что и родитель, за исключением того, что любые сокеты, принадлежащие ecdysis, наследуются и не создаются заново дочерним процессом.
-
Сигнализирует родителю о готовности, вызывая
ready(). -
Блокируется в ожидании сигнала завершения работы или обновления.
Использование в продакшене в масштабе
ecdysis работает в продакшене в Cloudflare с 2021 года. На нём работают критически важные инфраструктурные сервисы на Rust, развёрнутые в более чем 330+ дата-центрах в 120+ странах. Эти сервисы обрабатывают миллиарды запросов в день и требуют частых обновлений для исправлений безопасности, выпусков новых функций и изменений конфигурации.
Каждый перезапуск с использованием ecdysis сохраняет сотни тысяч запросов, которые в противном случае были бы потеряны при простом цикле остановки/запуска. В масштабах нашей глобальной инфраструктуры это означает сохранение миллионов подключений и повышение надёжности для клиентов.
ecdysis vs альтернативы
Библиотеки для плавного перезапуска существуют для нескольких экосистем. Понимание, когда использовать ecdysis, а когда альтернативы, критически важно для выбора правильного инструмента.
tableflip — это наша библиотека для Go, которая вдохновила создание ecdysis. Она реализует ту же модель fork-and-inherit для сервисов на Go. Если вам нужен Go, tableflip — отличный вариант!
shellflip — это другая библиотека Cloudflare для плавного перезапуска на Rust, созданная специально для Oxy, нашего прокси на Rust. shellflip более жёстко задаёт условия: она предполагает использование systemd и Tokio и сосредоточена на передаче произвольного состояния приложения между родителем и потомком. Это делает её отличным выбором для сложных stateful-сервисов или сервисов, которые хотят применять столь агрессивное изолирование, что они не могут даже открывать собственные сокеты, но это добавляет накладные расходы в более простых случаях.
Начните разработку
ecdysis привносит в экосистему Rust пятилетний опыт отлаженных в продакшене возможностей плавного перезапуска. Это та же технология, которая защищает миллионы подключений в глобальной сети Cloudflare, а теперь она стала open-source и доступна для всех!
Полная документация доступна на docs.rs/ecdysis, включая справочник по API, примеры для распространённых сценариев использования и шаги по интеграции с systemd.
Директория examples в репозитории содержит рабочий код, демонстрирующий использование TCP-слушателей, слушателей Unix-сокетов и интеграцию с systemd.
Библиотека активно поддерживается командой Argo Smart Routing & Orpheus при участии команд со всего Cloudflare. Мы приветствуем вклад, сообщения об ошибках и запросы функций на GitHub.
Создаёте ли вы высокопроизводительный прокси, долгоживущий API-сервер или любой сетевой сервис, где важна бесперебойная работа, ecdysis может стать основой для эксплуатации с нулевым временем простоя.