На этой неделе Управление по конкуренции и рынкам Великобритании (CMA) открыло консультации по пакету предлагаемых правил поведения для Google. В ходе консультаций запрашиваются комментарии по предлагаемым требованиям до того, как CMA введет окончательные меры. Эти новые правила призваны решить проблему отсутствия выбора и прозрачности, с которой сталкиваются издатели (в широком смысле — «любая сторона, делающая контент доступным в сети») в отношении того, как Google использует поиск для питания своих генеративных ИИ-сервисов и функций. Это первые консультации по правилам поведения, запущенные в рамках режима конкуренции на цифровых рынках в Великобритании.
Мы приветствуем признание CMA того, что издателям нужна более справедливая сделка, и считаем, что предлагаемые правила — шаг в правильном направлении. Издатели должны иметь право на доступ к инструментам, позволяющим им контролировать включение их контента в генеративные ИИ-сервисы, а у компаний, занимающихся ИИ, должно быть равное поле для конкуренции.
Но мы считаем, что CMA сделала недостаточно и должна принять больше мер для защиты творческого сектора Великобритании и развития здоровой конкуренции на рынке генеративного и агентного ИИ.
Присвоение Google CMA статуса стратегического рынка (SMS)
В январе 2025 года регуляторный ландшафт Великобритании претерпел значительные юридические изменения в связи с вступлением в силу Закона о цифровых рынках, конкуренции и потребителях 2024 года (DMCC). Вместо того чтобы полагаться на антимонопольные расследования для устранения рисков для конкуренции, CMA теперь может присваивать компаниям статус стратегического рынка (SMS), когда они обладают существенной, укоренившейся рыночной властью. Это обозначение позволяет CMA проводить целевые вмешательства на цифровых рынках, например, вводить подробные правила поведения, для улучшения конкуренции.
В октябре 2025 года CMA присвоила Google статус SMS в области общего поиска и поисковой рекламы, учитывая ее 90-процентную долю на рынке поиска в Великобритании. Ключевым моментом является то, что это обозначение включает AI Overviews и AI Mode, и теперь CMA имеет право налагать правила поведения на поисковую экосистему Google. Окончательные требования, введенные CMA, — это не просто предложения, а юридически обязательные правила, которые могут касаться, в частности, сканирования для ИИ, со значительными санкциями для обеспечения справедливой работы Google.
Издателям нужен действенный способ отказаться от использования их контента Google для генеративного ИИ
Решение CMA не могло быть более своевременным. Как мы уже говорили, мы, несомненно, живем во времена, когда Интернету нужны четкие «правила дорожного движения» для поведения ИИ-краулеров.
Как справедливо отмечает CMA, «у издателей нет реалистичной возможности запретить сканирование своего контента для общего поиска Google из-за рыночной власти, которой обладает Google в сфере общего поиска. Однако в настоящее время Google использует этот контент как в своих функциях генеративного ИИ для поиска, так и в своих более широких генеративных ИИ-сервисах».
Другими словами: тот же контент, который Google сканирует для поискового индексирования, также используется для целей вывода/обоснования (inference/grounding), таких как AI Overviews и AI Mode, которые полагаются на получение актуальной информации из Интернета в ответ на запросы пользователей в реальном времени. И это создает большую проблему для издателей — и для конкуренции.
Поскольку издатели не могут позволить себе запретить или заблокировать Googlebot, поискового робота Google, на своем сайте, они вынуждены мириться с тем, что их контент будет использоваться в генеративных ИИ-приложениях, таких как AI Overviews и AI Mode в рамках Поиска Google, которые практически не возвращают трафик на их сайты. Это подрывает поддерживаемые рекламой бизнес-модели, которые десятилетиями поддерживали цифровые издания, учитывая критическую роль Поиска Google в направлении человеческого трафика на онлайн-рекламу. Это также означает, что генеративные ИИ-приложения Google вступают в прямую конкуренцию с издателями, воспроизводя их контент, чаще всего без указания авторства или компенсации.
Нежелание издателей блокировать Google из-за его доминирования в поиске дает Google несправедливое конкурентное преимущество на рынке генеративного и агентного ИИ. В отличие от других операторов ИИ-ботов, Google может использовать свой поисковый краулер для сбора данных для различных ИИ-функций, почти не опасаясь ограничения доступа. У него практически нет стимула платить издателям за эти данные, которые он уже получает бесплатно.
Это препятствует появлению хорошо функционирующего рынка, на котором разработчики ИИ договариваются о справедливой стоимости контента. Вместо этого, другие ИИ-компании не заинтересованы в переговорах, поскольку они находятся в структурно невыгодном положении из-за системы, которая позволяет одному доминирующему игроку полностью обходить компенсацию. Как сама CMA признает, «[н]е обеспечивая достаточного контроля над использованием этого контента, Google может ограничить способность издателей монетизировать свой контент, получая при этом доступ к контенту для ИИ-результатов таким образом, с которым его конкуренты не могут сравниться».
Преимущество Google
Данные Cloudflare подтверждают обеспокоенность по поводу конкурентного преимущества Google. Согласно нашим данным, Googlebot видит значительно больше интернет-контента, чем его ближайшие аналоги.
За наблюдаемый период в два месяца Googlebot успешно обращался к отдельным страницам почти в два раза чаще, чем ClaudeBot и GPTBot, в три раза чаще, чем Meta-ExternalAgent, и более чем в три раза чаще, чем Bingbot. Разница была еще более разительной для других популярных ИИ-краулеров: например, Googlebot видел в 167 раз больше уникальных страниц, чем PerplexityBot. Из выборки уникальных URL-адресов в нашей сети, которые мы наблюдали за последние два месяца, Googlebot просканировал примерно 8%.
В округленных кратных величинах Googlebot видит:
-
примерно в ~1,70 раз больше уникальных URL-адресов, чем ClaudeBot;
-
примерно в ~1,76 раз больше уникальных URL-адресов, чем GPTBot;
-
примерно в ~2,99 раз больше уникальных URL-адресов, чем Meta-ExternalAgent;
-
примерно в ~3,26 раз больше уникальных URL-адресов, чем Bingbot;
-
примерно в ~5,09 раз больше уникальных URL-адресов, чем Amazonbot;
-
примерно в ~14,87 раз больше уникальных URL-адресов, чем Applebot;
-
примерно в ~23,73 раз больше уникальных URL-адресов, чем Bytespider;
-
примерно в ~166,98 раз больше уникальных URL-адресов, чем PerplexityBot;
-
примерно в ~714,48 раз больше уникальных URL-адресов, чем CCBot; и
-
примерно в ~1801,97 раз больше уникальных URL-адресов, чем archive.org_bot.
Googlebot также выделяется в других наборах данных Cloudflare.
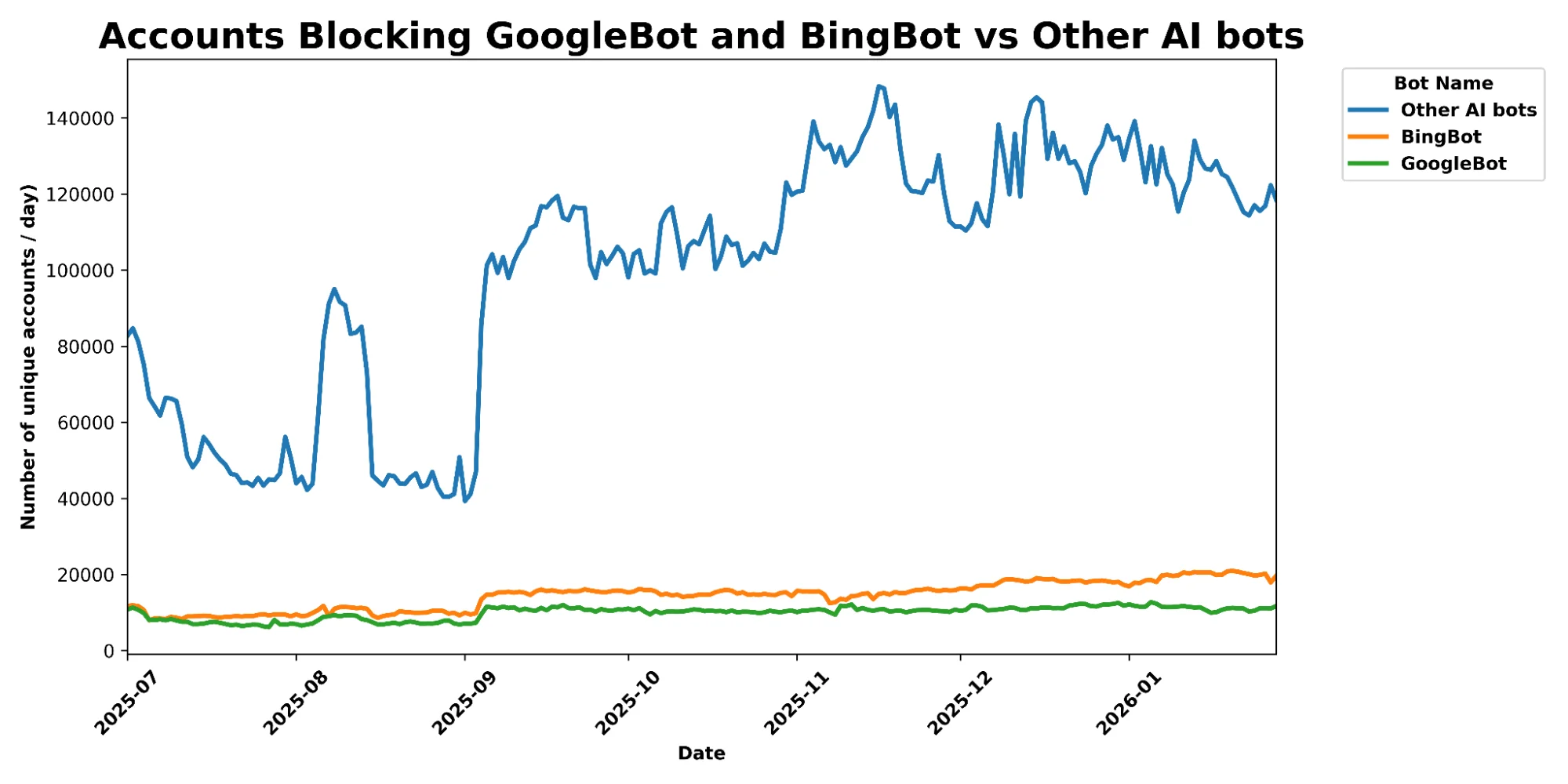
Несмотря на то что он является самым активным ботом по общему трафику, издатели гораздо реже запрещают или блокируют Googlebot в своем файле robots.txt по сравнению с другими краулерами. Вероятно, это связано с его важностью для привлечения человеческого трафика на их контент — и, как следствие, рекламных доходов — через поиск.
Как показано ниже, почти ни один сайт не запрещает полностью двойного назначения Googlebot, что отражает важность этого бота для привлечения трафика через поисковые переходы. (Обратите внимание, что частичные запреты часто затрагивают определенные части сайта, не релевантные для поисковой оптимизации (SEO), такие как конечные точки входа.)
Robots.txt лишь позволяет выразить предпочтения по сканированию; это не механизм принуждения. Издатели полагаются на то, что «хорошие боты» будут соблюдать правила. Для более эффективного управления доступом краулеров к своим сайтам — и независимо от соблюдения правил конкретным ботом — издатели могут настроить межсетевой экран веб-приложений (WAF) с определенными правилами, технически предотвращая доступ нежелательных краулеров к своим сайтам. Следуя той же логике, что и с robots.txt выше, можно ожидать, что сайты будут блокировать в основном другие ИИ-краулеры, но не Googlebot.
Действительно, сравнивая данные клиентов, использующих AI Crawl Control, собственный инструмент блокировки ИИ-краулеров Cloudflare, интегрированный в наш пакет безопасности приложений, в период с июля 2025 по январь 2026 года, можно увидеть, что количество сайтов, активно блокирующих другие популярные ИИ-краулеры (например, GPTBot, Claudebot), было почти в семь раз выше, чем количество сайтов, блокирующих Googlebot и Bingbot. (Как и Googlebot, Bingbot сочетает поисковое и ИИ-сканирование и направляет трафик на эти сайты, но, учитывая его небольшую долю на рынке поиска, его влияние менее значительно.)
Итак, мы согласны с CMA в определении проблемы. Но как издатели могут эффективно отказаться от использования Google их контента для своих генеративных ИИ-приложений? Мы разделяем вывод CMA о том, что «чтобы иметь возможность принимать осознанные решения о том, как Google использует их Поисковый Контент, (...) издателям необходима возможность эффективно исключать свой Поисковый Контент как из функций поискового генеративного ИИ Google, так и из более широких генеративных ИИ-сервисов Google».
Но мы обеспокоены тем, что предложение CMA недостаточно.
Предлагаемые CMA требования к поведению издателей
28 января 2026 года CMA опубликовала четыре набора предлагаемых требований к поведению для Google, включая требования к поведению, связанные с издателями. По мнению CMA, предлагаемые правила для издателей призваны решить проблемы, заключающиеся в том, что издатели (1) не имеют достаточного выбора в отношении того, как Google использует их контент в своих ИИ-генерируемых ответах, (2) имеют ограниченную прозрачность в отношении использования Google этого контента и (3) не получают эффективной атрибуции за использование Google их контента. CMA признала важность этих проблем из-за роли, которую поиск Google играет в поиске контента в интернете.
Требования к поведению обязывали бы Google предоставить издателям «значимый и эффективный» контроль над тем, используется ли их контент для ИИ-функций, таких как AI Overviews. Google было бы запрещено предпринимать любые действия, негативно влияющие на эффективность этих опций контроля, такие как намеренное понижение ранга контента в поиске.
Для поддержки принятия обоснованных решений предложение CMA также требует от Google повысить прозрачность, опубликовав четкую документацию о том, как он использует обходной контент для генеративного ИИ и что именно охватывают на практике различные инструменты контроля издателей. Наконец, предложение обяжет Google обеспечить эффективную атрибуцию контента издателей и предоставить издателям детальные, разрозненные данные о вовлеченности — включая конкретные метрики показов, кликов и «качества кликов» — чтобы помочь им оценить коммерческую ценность разрешения на использование их контента в ИИ-генерируемых поисковых сводках.
Предлагаемые CMA меры недостаточны
Хотя мы поддерживаем усилия CMA по улучшению возможностей для издателей, мы обеспокоены тем, что предлагаемые требования не решают фундаментальную проблему обеспечения справедливого, прозрачного выбора в отношении того, как их контент используется Google. Издатели фактически вынуждены использовать проприетарные механизмы отказа Google, привязанные конкретно к платформе Google и на условиях, установленных Google, вместо того чтобы предоставить им прямой, автономный контроль. Фреймворк, в котором платформа диктует правила, управляет техническими средствами контроля и определяет сферу применения, не предлагает «эффективного контроля» создателям контента и не поощряет конкурентные инновации на рынке. Вместо этого он укрепляет состояние постоянной зависимости.
Такой фреймворк также сокращает выбор для издателей. Создание новых механизмов отказа делает невозможным для издателей выбор использования внешних инструментов для блокировки доступа Googlebot к их контенту без угрозы их появлению в результатах Поиска. Вместо этого, согласно текущему предложению, создателям контента по-прежнему придется разрешать Googlebot сканировать их веб-сайты, без механизмов принуждения к развертыванию и с ограниченной видимостью, доступной если Google не уважает их выраженные предпочтения. Обеспечение соблюдения этих требований со стороны CMA, если оно будет проведено должным образом, будет очень обременительным, без гарантии, что издатели будут доверять этому решению.
Фактически, Cloudflare получила отзывы от своих клиентов о том, что нынешние проприетарные механизмы отказа Google, включая Google-Extended и ‘nosnippet’, не смогли предотвратить использование контента способами, которые издатели не могут контролировать. Эти инструменты отказа также не обеспечивают механизмы справедливого вознаграждения для издателей.
В более широком смысле, как отражено в наших предлагаемых принципах ответственных ИИ-ботов, мы считаем, что у всех ИИ-ботов должна быть одна четкая цель, и они должны ее декларировать, чтобы владельцы веб-сайтов могли принимать ясные решения о том, кто и зачем может получать доступ к их контенту. В отличие от своих ведущих конкурентов, таких как OpenAI и Anthropic, Google не соблюдает этот принцип для Googlebot, который используется для нескольких целей (индексация поиска, обучение ИИ и логический вывод/обоснование). Просто требование к Google разработать новый механизм отказа не позволит издателям достичь значимого контроля над использованием их контента.
Наиболее эффективный способ предоставить издателям этот необходимый контроль — потребовать разделения Googlebot на отдельные краулеры. Таким образом, издатели могли бы разрешать обход для традиционной поисковой индексации, которая им нужна для привлечения трафика на свои сайты, но блокировать доступ для нежелательного использования их контента в генеративных ИИ-сервисах и функциях.
Требование разделения краулеров — единственное эффективное решение
Чтобы обеспечить справедливую цифровую экосистему, CMA должна, напротив, дать владельцам контента возможность предотвращать доступ Google к их данным для определенных целей с самого начала, а не полагаться на обходные пути под управлением Google после того, как краулер уже получил доступ к контенту для других целей. Такой подход также позволяет создателям устанавливать условия для доступа к своему контенту.
Хотя CMA описала разделение краулеров как «равно эффективное вмешательство», в конечном итоге она отказалась от обязательного разделения, основываясь на мнении Google, что это было бы слишком обременительно. Мы не согласны.
Требование к Google разделить Googlebot по целям — точно так же, как Google уже делает для своих почти 20 других краулеров — не только технически осуществимо, но и является необходимой и соразмерной мерой, которая дает операторам веб-сайтов тот детальный контроль, которого им в настоящее время не хватает, без увеличения нагрузки на трафик от краулеров на их веб-сайты (и фактически, возможно, даже уменьшая ее, если они решат заблокировать ИИ-краулинг).
Чтобы было ясно, средство разделения краулеров приносит пользу компаниям ИИ, уравнивая условия между ними и Google, в дополнение к предоставлению издателям из Великобритании большего контроля над своим контентом. (Со стороны Daily Mail Group, Guardian и News Media Association была широкомасштабная публичная поддержка меры по разделению краулеров.) Обязательное разделение краулеров не является недостатком для Google и не подрывает инвестиции в ИИ. Напротив, это про-конкурентная защитная мера, которая предотвращает использование Google своей поисковой монополии для получения несправедливого преимущества на рынке ИИ. Разделяя эти функции, мы обеспечиваем, чтобы развитие ИИ определялось справедливой рыночной конкуренцией, а не эксплуатацией доминирования одного гиперскейлера.
******
У Великобритании есть уникальный шанс возглавить мир в защите ценности оригинального и качественного контента в интернете. Однако мы опасаемся, что текущие предложения недостаточны. Мы бы призвали к правилам, которые обеспечивают, чтобы Google работал в тех же условиях доступа к контенту, что и другие разработчики ИИ, значимо восстанавливая агентство издателей и прокладывая путь для новых бизнес-моделей, способствующих монетизации контента.