Cloudflare имеет центры обработки данных в более чем 330 городах по всему миру, поэтому можно подумать, что мы можем легко вывести из строя несколько из них в любое время без ведома пользователей при планировании работ в дата-центрах. Однако реальность такова, что запланированные отключения (disruptive maintenance) требуют тщательного планирования, и по мере роста Cloudflare управление этой сложностью через ручную координацию между нашими специалистами по инфраструктуре и сетевой эксплуатации стало почти невозможным.
Человеку больше не под силу отслеживать в реальном времени каждое пересекающееся заявленное техническое обслуживание или учитывать каждое специфичное для клиента правило маршрутизации. Мы достигли точки, когда одного лишь ручного контроля было недостаточно, чтобы гарантировать, что обычное обновление оборудования в одной части мира не войдет в непреднамеренный конфликт с критическим маршрутом в другой.
Мы поняли, что нам нужен централизованный автоматизированный «мозг» в качестве защитного механизма — система, которая могла бы видеть полное состояние нашей сети одновременно. Создав этот планировщик на Cloudflare Workers, мы разработали способ программного применения ограничений безопасности, гарантируя, что, как бы быстро мы ни двигались, мы никогда не жертвуем надежностью сервисов, от которых зависят наши клиенты.
В этой публикации блога мы объясним, как мы его построили, и поделимся результатами, которые видим сейчас.
Создание системы для снижения рисков при критических операциях обслуживания
Представьте себе граничный маршрутизатор, который является одним из небольшой, избыточной группы шлюзов, которые вместе соединяют публичный Интернет со многими центрами обработки данных Cloudflare, работающими в пределах мегаполиса. В густонаселенном городе нам необходимо убедиться, что множественные дата-центры, находящиеся за этим небольшим кластером маршрутизаторов, не окажутся отрезанными из-за того, что все маршрутизаторы были отключены одновременно.
Еще одна проблема обслуживания исходит от нашего продукта Zero Trust, Dedicated CDN Egress IPs, который позволяет клиентам выбирать конкретные дата-центры, из которых их пользовательский трафик будет выходить из Cloudflare и отправляться на их географически близкие серверы-источники для низкой задержки. (Для краткости в этом посте мы будем называть продукт Dedicated CDN Egress IPs «Aegis», его прежним именем.) Если все выбранные клиентом дата-центры окажутся отключены одновременно, он столкнется с повышенной задержкой и, возможно, с ошибками 5xx, чего мы должны избегать.
Наш планировщик обслуживания решает подобные проблемы. Мы можем гарантировать, что в определенной области всегда активен как минимум один граничный маршрутизатор. И при планировании работ мы можем видеть, приведет ли комбинация нескольких запланированных событий к одновременному отключению всех дата-центров для пулов Aegis клиента.
До создания планировщика такие одновременные плановые отключения могли вызывать простои для клиентов. Теперь наш планировщик уведомляет внутренних операторов о потенциальных конфликтах, позволяя нам предложить новое время, чтобы избежать пересечения с другими связанными событиями обслуживания дата-центров.
Мы определяем эти операционные сценарии, такие как доступность граничных маршрутизаторов и правила для клиентов, как ограничения обслуживания, что позволяет нам планировать более предсказуемое и безопасное техническое обслуживание.
Ограничения обслуживания
Каждое ограничение начинается с набора предлагаемых к обслуживанию элементов, таких как сетевой маршрутизатор или список серверов. Затем мы находим все события обслуживания в календаре, которые пересекаются с предлагаемым временным окном обслуживания.
Далее мы агрегируем данные из API продуктов, например, список пулов IP-адресов клиентов Aegis. Aegis возвращает набор IP-диапазонов, где клиент запросил выход трафика из конкретных идентификаторов дата-центров, как показано ниже.
[
{
"cidr": "104.28.0.32/32",
"pool_name": "customer-9876",
"port_slots": [
{
"dc_id": 21,
"other_colos_enabled": true,
},
{
"dc_id": 45,
"other_colos_enabled": true,
}
],
"modified_at": "2023-10-22T13:32:47.213767Z"
},
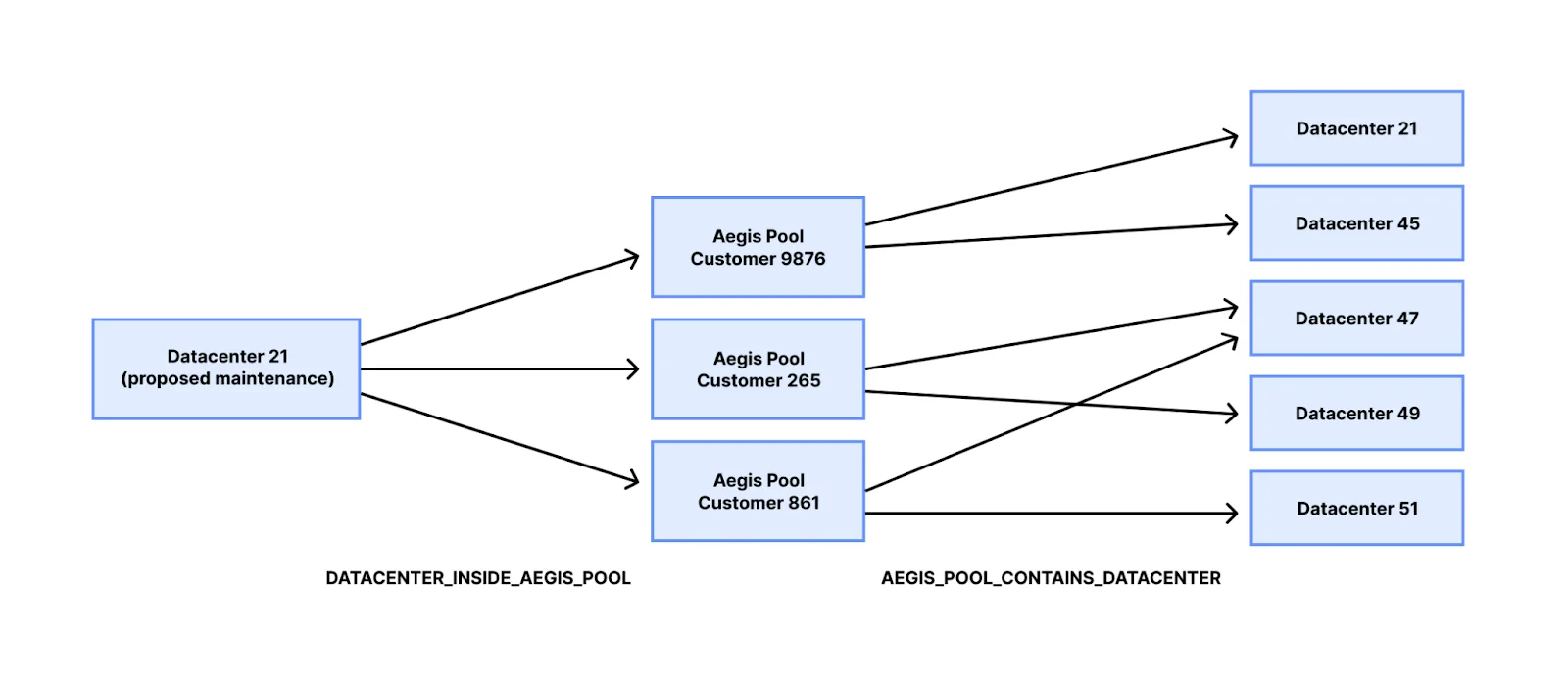
]В этом сценарии дата-центр 21 и дата-центр 45 связаны друг с другом, потому что нам нужно, чтобы как минимум один дата-центр был онлайн для того, чтобы клиент Aegis 9876 получал исходящий трафик из Cloudflare. Если бы мы попытались отключить дата-центры 21 и 45 одновременно, наш координатор предупредил бы нас о непредвиденных последствиях для рабочей нагрузки этого клиента.
Изначально у нас было простое решение — загружать все данные в один Worker. Это включало все взаимосвязи серверов, конфигурации продуктов и метрики состояния продуктов и инфраструктуры для вычисления ограничений. Даже на этапе создания прототипа мы столкнулись с ошибками «недостаточно памяти».
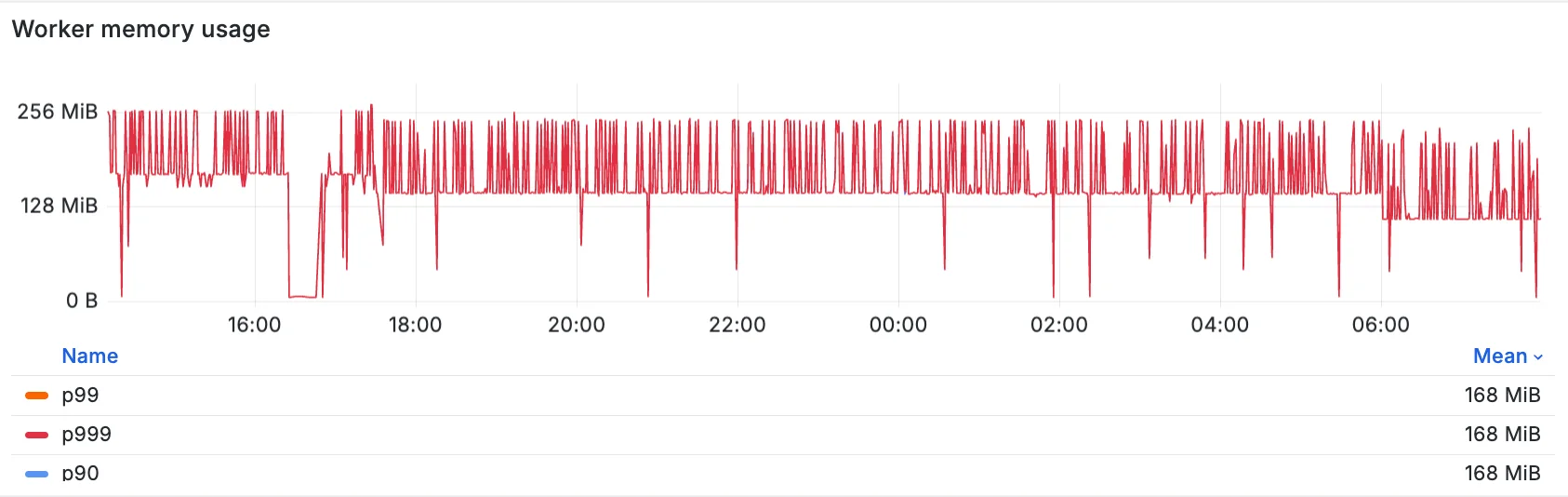
Нам нужно было более внимательно относиться к платформенным ограничениям Workers. Это потребовало загрузки только того объема данных, который абсолютно необходим для обработки бизнес-логики ограничения. Если поступает запрос на обслуживание маршрутизатора во Франкфурте, Германия, нас почти наверняка не интересует, что происходит в Австралии, поскольку между регионами нет пересечений. Следовательно, мы должны загружать данные только для соседних дата-центров в Германии. Нам нужен был более эффективный способ обработки взаимосвязей в нашем наборе данных.
Обработка графов на Workers
По мере изучения наших ограничений проявилась закономерность: каждое ограничение сводилось к двум концепциям: объекты и ассоциации. В теории графов эти компоненты известны как вершины и ребра соответственно. Объектом может быть сетевой маршрутизатор, а ассоциацией — список пулов Aegis в дата-центре, для работы которых требуется, чтобы маршрутизатор был онлайн. Мы вдохновились исследовательской работой Facebook о TAO, чтобы создать графовый интерфейс поверх наших данных о продуктах и инфраструктуре. API выглядит следующим образом:
type ObjectID = string
interface MainTAOInterface<TObject, TAssoc, TAssocType> {
object_get(id: ObjectID): Promise<TObject | undefined>
assoc_get(id1: ObjectID, atype: TAssocType): AsyncIterable<TAssoc>
}Ключевое понимание заключается в том, что ассоциации типизированы. Например, ограничение будет вызывать графовый интерфейс для получения данных продукта Aegis.
async function constraint(c: AppContext, aegis: TAOAegisClient, datacenters: string[]): Promise<Record<string, PoolAnalysis>> {
const datacenterEntries = await Promise.all(
datacenters.map(async (dcID) => {
const iter = aegis.assoc_get(c, dcID, AegisAssocType.DATACENTER_INSIDE_AEGIS_POOL)
const pools: string[] = []
for await (const assoc of iter) {
pools.push(assoc.id2)
}
return [dcID, pools] as const
}),
)
const datacenterToPools = new Map<string, string[]>(datacenterEntries)
const uniquePools = new Set<string>()
for (const pools of datacenterToPools.values()) {
for (const pool of pools) uniquePools.add(pool)
}
const poolTotalsEntries = await Promise.all(
[...uniquePools].map(async (pool) => {
const total = aegis.assoc_count(c, pool, AegisAssocType.AEGIS_POOL_CONTAINS_DATACENTER)
return [pool, total] as const
}),
)
const poolTotals = new Map<string, number>(poolTotalsEntries)
const poolAnalysis: Record<string, PoolAnalysis> = {}
for (const [dcID, pools] of datacenterToPools.entries()) {
for (const pool of pools) {
poolAnalysis[pool] = {
affectedDatacenters: new Set([dcID]),
totalDatacenters: poolTotals.get(pool),
}
}
}
return poolAnalysis
}В приведенном выше коде мы используем два типа ассоциаций:
-
DATACENTER_INSIDE_AEGIS_POOL, который получает пулы клиентов Aegis, в которых находится дата-центр.
-
AEGIS_POOL_CONTAINS_DATACENTER, который получает дата-центры, необходимые пулу Aegis для обслуживания трафика.
Ассоциации являются инвертированными индексами друг друга. Шаблон доступа точно такой же, как и раньше, но теперь реализация графа имеет гораздо больше контроля над объемом запрашиваемых данных. Раньше нам нужно было загружать все пулы Aegis в память и фильтровать внутри бизнес-логики ограничений. Теперь мы можем напрямую получать только те данные, которые важны для приложения.
Интерфейс мощный, потому что наша реализация графа может улучшать производительность «за кулисами», не усложняя бизнес-логику. Это позволяет нам использовать масштабируемость Workers и CDN Cloudflare для очень быстрой выборки данных из наших внутренних систем.
Конвейер выборки (Fetch pipeline)
Мы перешли на использование новой графовой реализации, отправляя более целенаправленные API-запросы. Размеры ответов уменьшились в 100 раз буквально за ночь, перейдя от загрузки нескольких огромных запросов ко множеству маленьких.
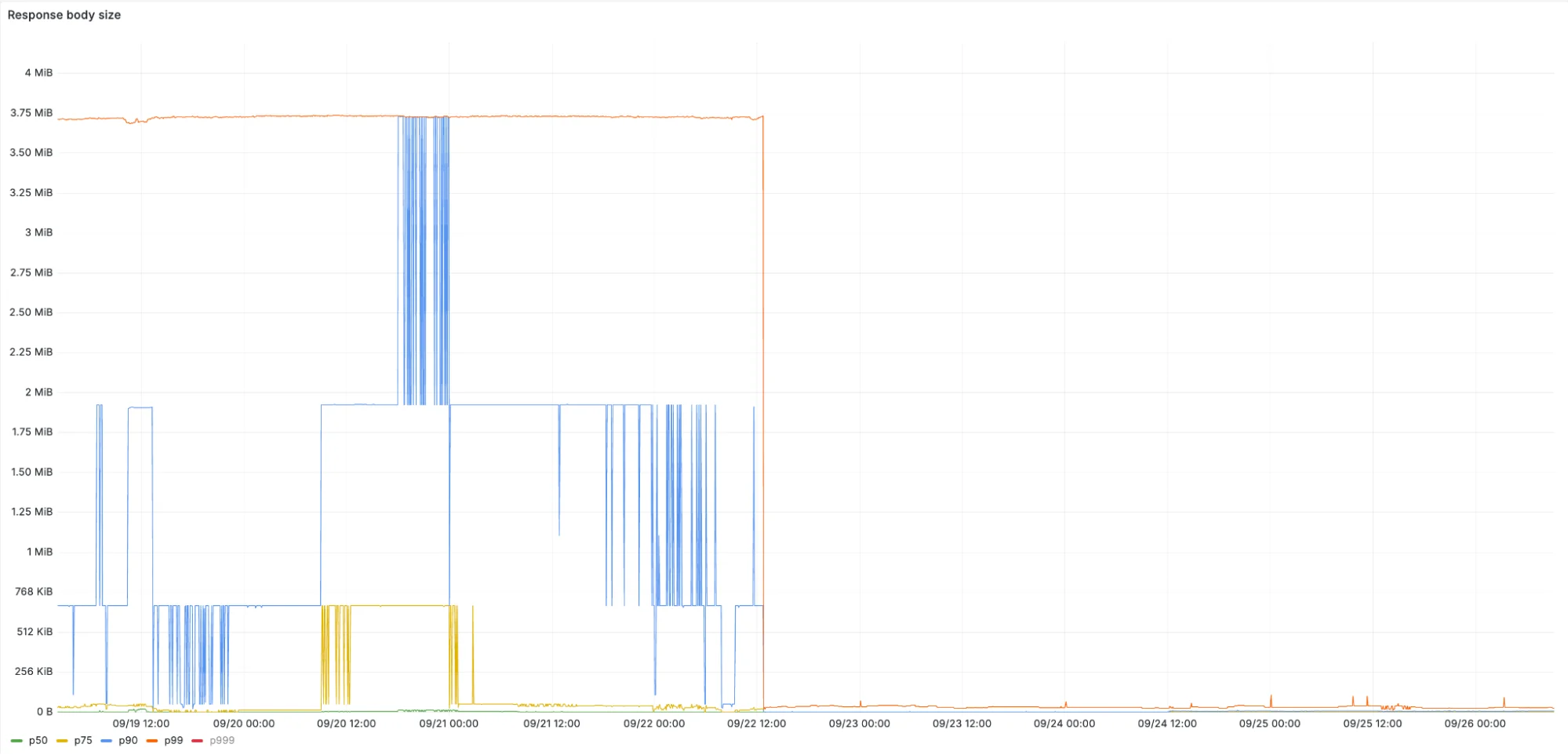
Хотя это решает проблему загрузки слишком большого объема данных в память, теперь у нас возникает проблема с количеством подзапросов, потому что вместо нескольких крупных HTTP-запросов мы делаем на порядок больше мелких. Буквально за одну ночь мы начали стабильно превышать лимиты на подзапросы.
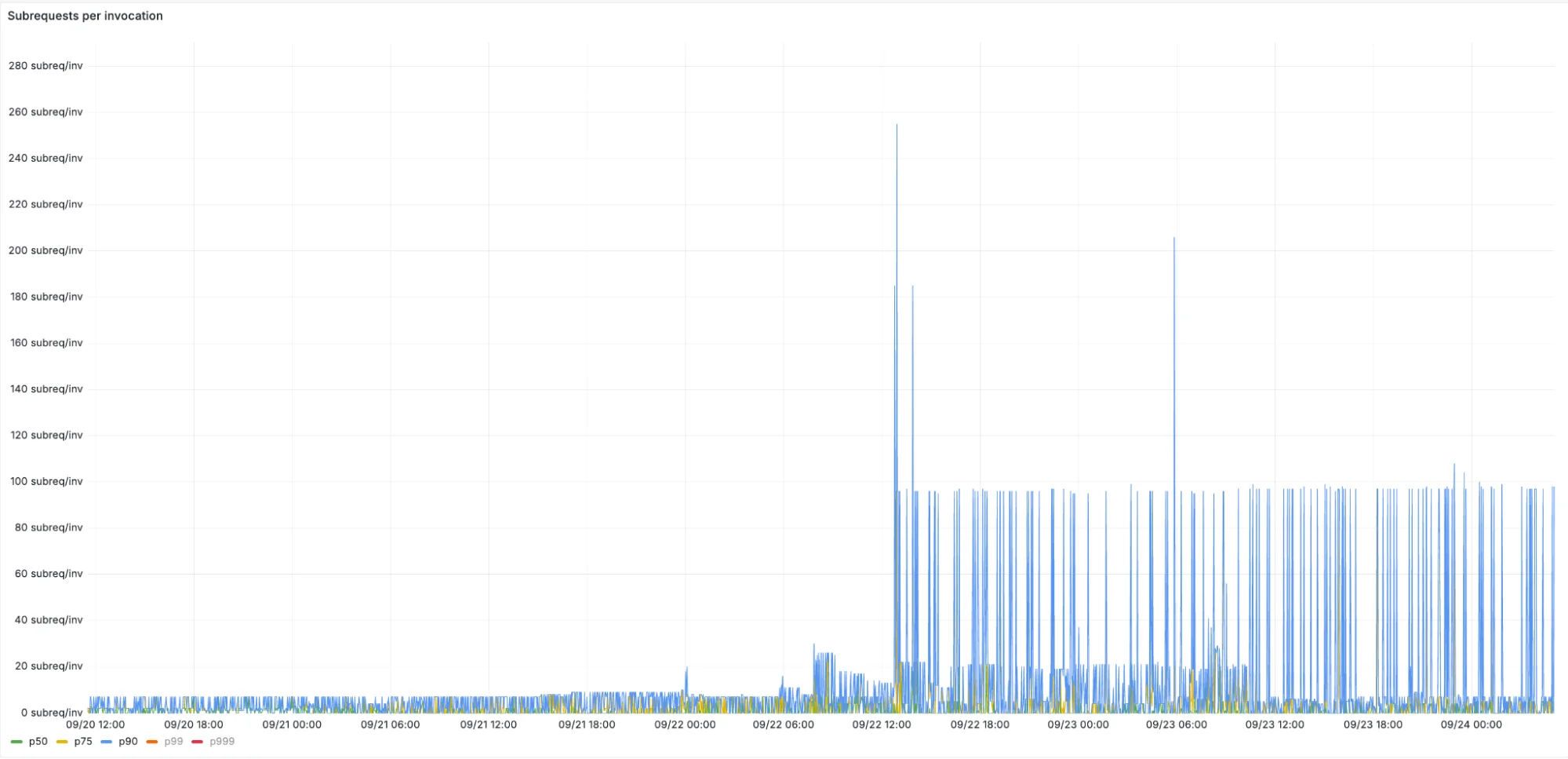
Чтобы решить эту проблему, мы создали интеллектуальный промежуточный слой (middleware) между нашей реализацией графа и API fetch.
export const fetchPipeline = new FetchPipeline()
.use(requestDeduplicator())
.use(lruCacher({
maxItems: 100,
}))
.use(cdnCacher())
.use(backoffRetryer({
retries: 3,
baseMs: 100,
jitter: true,
}))
.handler(terminalFetch);Если вы знакомы с Go, вы, возможно, видели пакет singleflight. Мы взяли за основу эту идею, и первый компонент middleware в конвейере fetch устраняет дублирование выполняющихся HTTP-запросов, так что все они ожидают одни и те же данные от одного Promise, вместо создания дубликатов запросов в одном и том же Worker. Далее мы используем легковесный кэш LRU (Least Recently Used — вытеснение давно не используемых) для внутреннего кэширования уже обработанных запросов.
После этих двух этапов мы используем функцию Cloudflare caches.default.match для кэширования всех GET-запросов в регионе, где работает Worker. Поскольку у нас несколько источников данных с разными характеристиками производительности, мы тщательно подбираем значения времени жизни (TTL). Например, данные в реальном времени кэшируются всего на 1 минуту. Относительно статичные данные инфраструктуры могут кэшироваться от 1 до 24 часов в зависимости от типа данных. Данные по управлению энергопотреблением могут изменяться вручную и редко, поэтому мы можем кэшировать их дольше на граничной сети (edge).
Помимо этих слоёв, у нас есть стандартные механизмы экспоненциальной задержки (backoff), повторных попыток (retries) и случайной задержки (jitter). Это помогает сократить бесполезные вызовы fetch, когда нижестоящий ресурс может быть временно недоступен. Немного увеличивая паузу между попытками, мы повышаем шанс на успешный следующий запрос. И наоборот, если Worker будет постоянно отправлять запросы без задержки, он легко превысит лимит подзапросов, когда источник начнёт возвращать ошибки 5xx.
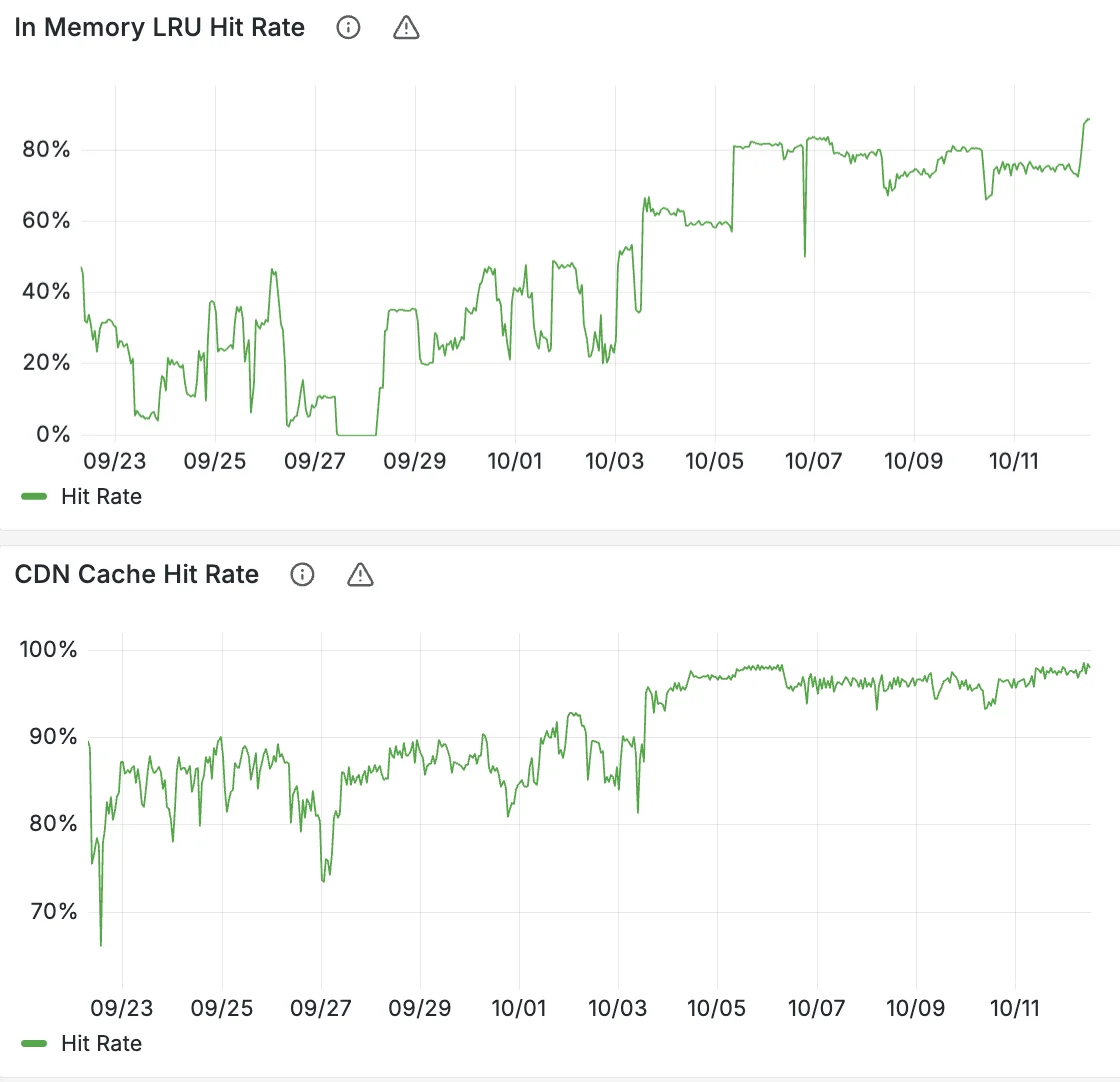
В результате мы добились показателя попаданий в кэш ~99%. Коэффициент попаданий в кэш (Cache hit rate) — это процент HTTP-запросов, обслуженных из быстрой кэш-памяти Cloudflare («попадание»), по сравнению с более медленными запросами к источникам данных в нашей плоскости управления («промах»), рассчитываемый как (попадания / (попадания + промахи)). Высокий показатель означает лучшую производительность HTTP-запросов и более низкие затраты, поскольку получение данных из кэша в Worker на порядок быстрее, чем запрос к серверу-источнику в другом регионе. После настройки параметров для наших кэшей в памяти и CDN показатели попаданий значительно выросли. Поскольку большая часть нашей рабочей нагрузки — это данные в реальном времени, у нас никогда не будет 100% попаданий, так как мы должны запрашивать свежие данные как минимум раз в минуту.
Мы поговорили об улучшении слоя получения данных, но не о том, как мы ускорили исходные HTTP-запросы. Наш координатор технического обслуживания должен реагировать в реальном времени на ухудшение состояния сети и отказы машин в дата-центрах. Мы используем наш распределённый движок запросов к Prometheus — Thanos — для предоставления производительных метрик с граничной сети (edge) координатору.
Thanos в реальном времени
Чтобы объяснить, как наш выбор в пользу интерфейса обработки графа повлиял на запросы в реальном времени, рассмотрим пример. Чтобы проанализировать состояние граничных маршрутизаторов (edge routers), мы могли бы отправить следующий запрос:
sum by (instance) (network_snmp_interface_admin_status{instance=~"edge.*"})Изначально мы запрашивали у нашего сервиса Thanos, который хранит метрики Prometheus, список текущих статусов состояния каждого граничного маршрутизатора и вручную фильтровали в Worker маршрутизаторы, относящиеся к конкретному техническому обслуживанию. Это неоптимально по многим причинам. Например, Thanos возвращал ответы размером в несколько мегабайт, которые нужно было декодировать и кодировать. Worker также должен был кэшировать и декодировать эти большие HTTP-ответы, только чтобы отфильтровать большую часть данных при обработке конкретного запроса на обслуживание. Поскольку TypeScript однопоточный, а разбор данных JSON ограничен производительностью CPU, отправка двух больших HTTP-запросов означает, что один будет ждать, пока другой закончит парсинг.
Вместо этого мы просто используем граф для поиска целевых связей, таких как интерфейсные соединения между граничными и spine-маршрутизаторами, обозначенные как EDGE_ROUTER_NETWORK_CONNECTS_TO_SPINE.
sum by (lldp_name) (network_snmp_interface_admin_status{instance=~"edge01.fra03", lldp_name=~"spine.*"})В результате средний размер ответа составляет 1 Кб вместо нескольких МБ, то есть примерно в 1000 раз меньше. Это также значительно сокращает потребление CPU внутри Worker, поскольку мы переносим большую часть десериализации на Thanos. Как мы объясняли ранее, это означает, что нам нужно делать большее количество таких мелких fetch-запросов, но балансировщики нагрузки перед Thanos могут равномерно распределять запросы для увеличения пропускной способности в этом сценарии.
Наша реализация графа и конвейер fetch успешно укротили «stampeding herd» (лавину) из тысяч мелких запросов в реальном времени. Однако исторический анализ представляет другую проблему ввода-вывода. Вместо получения небольших специфических связей нам необходимо сканировать месяцы данных, чтобы найти конфликтующие окна технического обслуживания. Раньше Thanos выполнял огромное количество случайных чтений из нашего объектного хранилища R2. Чтобы решить эту проблему больших потерь пропускной способности без ущерба для производительности, мы внедрили новый подход, разработанный командой Observability внутри компании в этом году.
Анализ исторических данных
Существует достаточно много сценариев обслуживания, что нам приходится полагаться на исторические данные, чтобы понять, точны ли наши решения и будут ли они масштабироваться с ростом сети Cloudflare. Мы не хотим вызывать инциденты, но также хотим избежать необоснованной блокировки предложенного физического обслуживания. Чтобы сбалансировать эти два приоритета, мы можем использовать данные временных рядов о событиях обслуживания, произошедших два месяца или даже год назад, чтобы понять, как часто такое событие нарушает одно из наших ограничений, например, доступность граничного маршрутизатора или Aegis. Ранее в этом году мы писали в блоге об использовании Thanos для автоматического развертывания и отката программного обеспечения на граничной сети.
Thanos в основном обращается к Prometheus, но когда данных в Prometheus недостаточно для ответа на запрос, ему приходится загружать данные из объектного хранилища — в нашем случае R2. Блоки TSDB Prometheus изначально были разработаны для локальных SSD, полагаясь на шаблоны случайного доступа, которые становятся узким местом при переносе в объектное хранилище. Когда наш планировщик должен проанализировать месяцы исторических данных об обслуживании, чтобы выявить конфликтующие ограничения, случайные чтения из объектного хранилища влекут за собой огромные потери производительности ввода-вывода. Чтобы решить это, мы внедрили слой преобразования, который трансформирует эти блоки в файлы Apache Parquet. Parquet — это колоночный формат, характерный для аналитики больших данных, который организует данные по столбцам, а не по строкам, что — вместе с богатой статистикой — позволяет нам загружать только то, что нужно.
Кроме того, поскольку мы перезаписываем блоки TSDB в файлы Parquet, мы также можем хранить данные таким образом, чтобы читать их всего несколькими большими последовательными фрагментами.
sum by (instance) (hmd:release_scopes:enabled{dc_id="45"})В приведённом выше примере мы бы выбрали кортеж «(__name__, dc_id)» в качестве первичного ключа сортировки, чтобы метрики с именем «hmd:release_scopes:enabled» и одинаковым значением «dc_id» располагались близко друг к другу.
Наш Parquet-шлюз теперь выполняет точные запросы на диапазон в R2, чтобы получить только конкретные столбцы, относящиеся к запросу. Это сокращает объём передаваемых данных с мегабайт до килобайт. Более того, поскольку эти сегменты файлов неизменяемы, мы можем агрессивно кэшировать их в CDN Cloudflare.
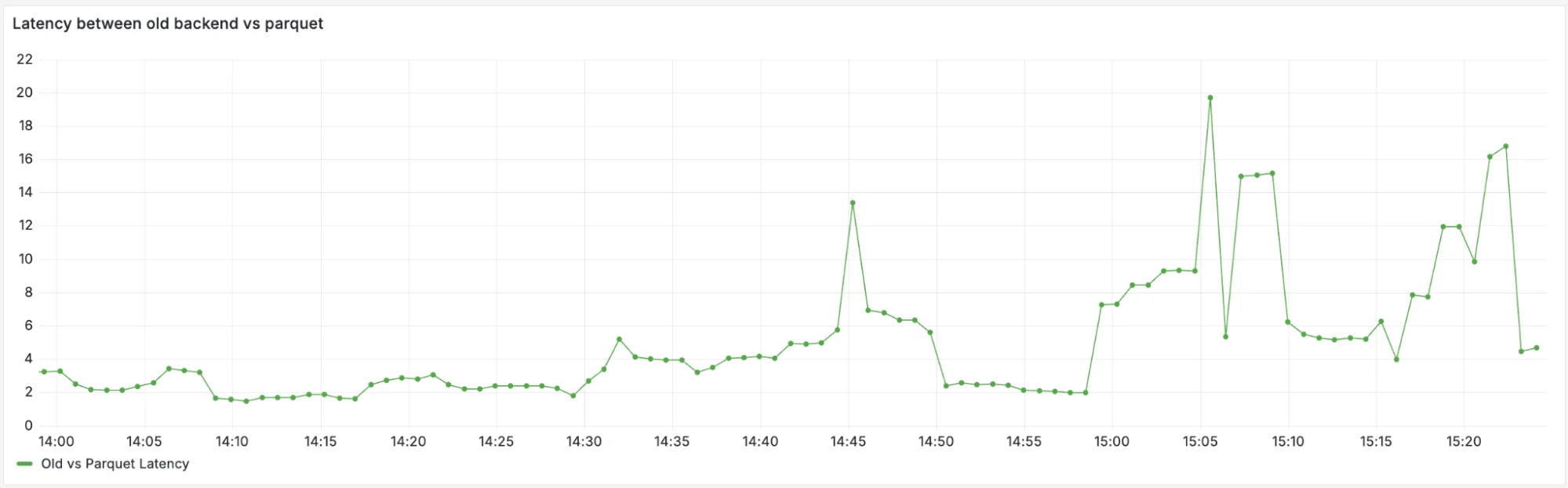
Это превращает R2 в низколатентный движок запросов, позволяя нам мгновенно проводить бэктестинг сложных сценариев обслуживания на основе долгосрочных тенденций, избегая таймаутов и высокой задержки в хвосте распределения, которые мы наблюдали с исходным форматом TSDB. На графике ниже показан недавний нагрузочный тест, где Parquet показал до 15-кратного увеличения производительности на уровне P90 по сравнению со старой системой для того же шаблона запросов.
Чтобы глубже понять, как работает реализация Parquet, вы можете посмотреть этот доклад на PromCon EU 2025: Beyond TSDB: Unlocking Prometheus with Parquet for Modern Scale.
Создание системы для масштабирования
Используя Cloudflare Workers, мы перешли от системы, которой не хватало памяти, к системе, которая интеллектуально кэширует данные и использует эффективные инструменты observability для анализа данных о продуктах и инфраструктуре в реальном времени. Мы создали планировщик технического обслуживания, который балансирует рост сети с производительностью продуктов.
Но «баланс» — это движущаяся цель.
Каждый день мы добавляем новое оборудование по всему миру, и логика, необходимая для его обслуживания без нарушения клиентского трафика, становится экспоненциально сложнее с увеличением числа продуктов и типов операций обслуживания. Мы справились с первым набором проблем, но теперь перед нами встают более тонкие и сложные задачи, которые проявляются только при таком огромном масштабе.