При работе с большими объемами данных полезно получить общее представление — именно это и обеспечивают агрегации в SQL. Агрегации, известные как «GROUP BY-запросы», дают обзор с высоты птичьего полета, позволяя быстро извлекать полезные сведения из огромных массивов данных.
Поэтому мы рады объявить о поддержке агрегаций в R2 SQL — бессерверном, распределенном механизме аналитических запросов Cloudflare, способном выполнять SQL-запросы к данным, хранящимся в R2 Data Catalog. Агрегации позволят пользователям R2 SQL выявлять важные тенденции и изменения в данных, создавать отчеты и находить аномалии в логах.
Этот выпуск основан на уже поддерживаемых запросах с фильтрацией, которые являются основой для аналитических нагрузок и позволяют пользователям находить иголку в стоге сена из Apache Parquet-файлов.
В этом посте мы разберем полезность и особенности агрегаций, а затем углубимся в то, как мы расширили R2 SQL для поддержки выполнения таких запросов к огромным объемам данных, хранящимся в R2 Data Catalog.
Важность агрегаций в аналитике
Агрегации, или «GROUP BY-запросы», генерируют краткую сводку по основным данным.
Типичный вариант использования агрегаций — формирование отчетов. Рассмотрим таблицу «sales» (продажи), содержащую исторические данные обо всех продажах в различных странах и отделах некой организации. Легко создать отчет об объеме продаж по отделам с помощью такого агрегирующего запроса:
SELECT department, sum(value)
FROM sales
GROUP BY departmentОператор «GROUP BY» позволяет разбить строки таблицы на «ведра» (группы). Каждое ведро имеет метку, соответствующую конкретному отделу. После заполнения ведер мы можем вычислить «sum(value)» для всех строк в каждом ведре, получив общий объем продаж соответствующего отдела.
Для некоторых отчетов нас могут интересовать только отделы с наибольшим объемом. Здесь на помощь приходит оператор «ORDER BY»:
SELECT department, sum(value)
FROM sales
GROUP BY department
ORDER BY sum(value) DESC
LIMIT 10Здесь мы указываем механизму запросов отсортировать все группы отделов по их общему объему продаж в порядке убывания и вернуть только 10 крупнейших.
Наконец, нас может интересовать фильтрация аномалий. Например, мы можем захотеть включить в отчет только отделы, у которых было более пяти продаж. Это легко сделать с помощью оператора «HAVING»:
SELECT department, sum(value), count(*)
FROM sales
GROUP BY department
HAVING count(*) > 5
ORDER BY sum(value) DESC
LIMIT 10Здесь мы добавили в запрос новую агрегатную функцию — «count(*)», — которая вычисляет, сколько строк попало в каждое ведро. Это напрямую соответствует количеству продаж в каждом отделе, поэтому мы также добавили предикат в оператор «HAVING», чтобы оставить только ведра с более чем пятью строками.
Два подхода к агрегации: вычислять раньше или позже
У агрегирующих запросов есть любопытное свойство: они могут ссылаться на столбцы, которые нигде не хранятся. Рассмотрим «sum(value)»: этот столбец вычисляется механизмом запросов на лету, в отличие от столбца «department», который извлекается из Parquet-файлов, хранящихся в R2. Это тонкое различие означает, что любой запрос, ссылающийся на агрегатные функции, такие как «sum», «count» и другие, необходимо разбивать на две фазы.
Первая фаза — вычисление новых столбцов. Если нам нужно отсортировать данные по столбцу «count(*)» с помощью оператора «ORDER BY» или отфильтровать строки на его основе с помощью «HAVING», нам необходимо знать значения этого столбца. Как только значения таких столбцов, как «count(*)», станут известны, можно приступать к остальной части выполнения запроса.
Обратите внимание: если запрос не ссылается на агрегатные функции в «HAVING» или «ORDER BY», но все же использует их в «SELECT», мы можем применить трюк. Поскольку значения агрегатных функций не нужны до самого конца, мы можем вычислять их частично и объединять результаты непосредственно перед возвратом пользователю.
Ключевое различие между двумя подходами заключается в том, когда мы вычисляем агрегатные функции: заранее, чтобы позже выполнить над ними дополнительные вычисления; или на лету, чтобы итеративно формировать результаты, нужные пользователю.
Сначала мы углубимся в построение результатов на лету — технику, которую мы называем «scatter-gather агрегации» (агрегации по принципу «разброса и сбора»). Затем на ее основе мы представим «shuffling агрегации» (агрегации с перемешиванием), способные выполнять дополнительные вычисления, такие как «HAVING» и «ORDER BY», поверх агрегатных функций.
Scatter-gather агрегации
Агрегирующие запросы без «HAVING» и «ORDER BY» могут выполняться аналогично запросам с фильтрацией. Для запросов с фильтрацией R2 SQL выбирает один узел в качестве координатора выполнения запроса. Этот узел анализирует запрос и обращается к R2 Data Catalog, чтобы определить, какие группы строк Parquet могут содержать данные, относящиеся к запросу. Каждая группа строк Parquet представляет собой относительно небольшой объем работы, с которым может справиться один вычислительный узел. Координатор распределяет работу между многими рабочими узлами и собирает результаты для возврата пользователю.
Для выполнения агрегирующих запросов мы выполняем все те же шаги и распределяем небольшие фрагменты работы между рабочими узлами. Однако на этот раз, помимо фильтрации строк на основе предиката в операторе «WHERE», рабочие узлы также вычисляют предварительные агрегаты.
Предварительные агрегаты представляют промежуточное состояние агрегации. Это неполный фрагмент данных, представляющий частично вычисленную агрегатную функцию для подмножества данных. Несколько предварительных агрегатов можно объединить для вычисления окончательного значения агрегатной функции. Разделение агрегатных функций на предварительные агрегаты позволяет нам горизонтально масштабировать вычисления агрегации, используя огромные вычислительные ресурсы сети Cloudflare.
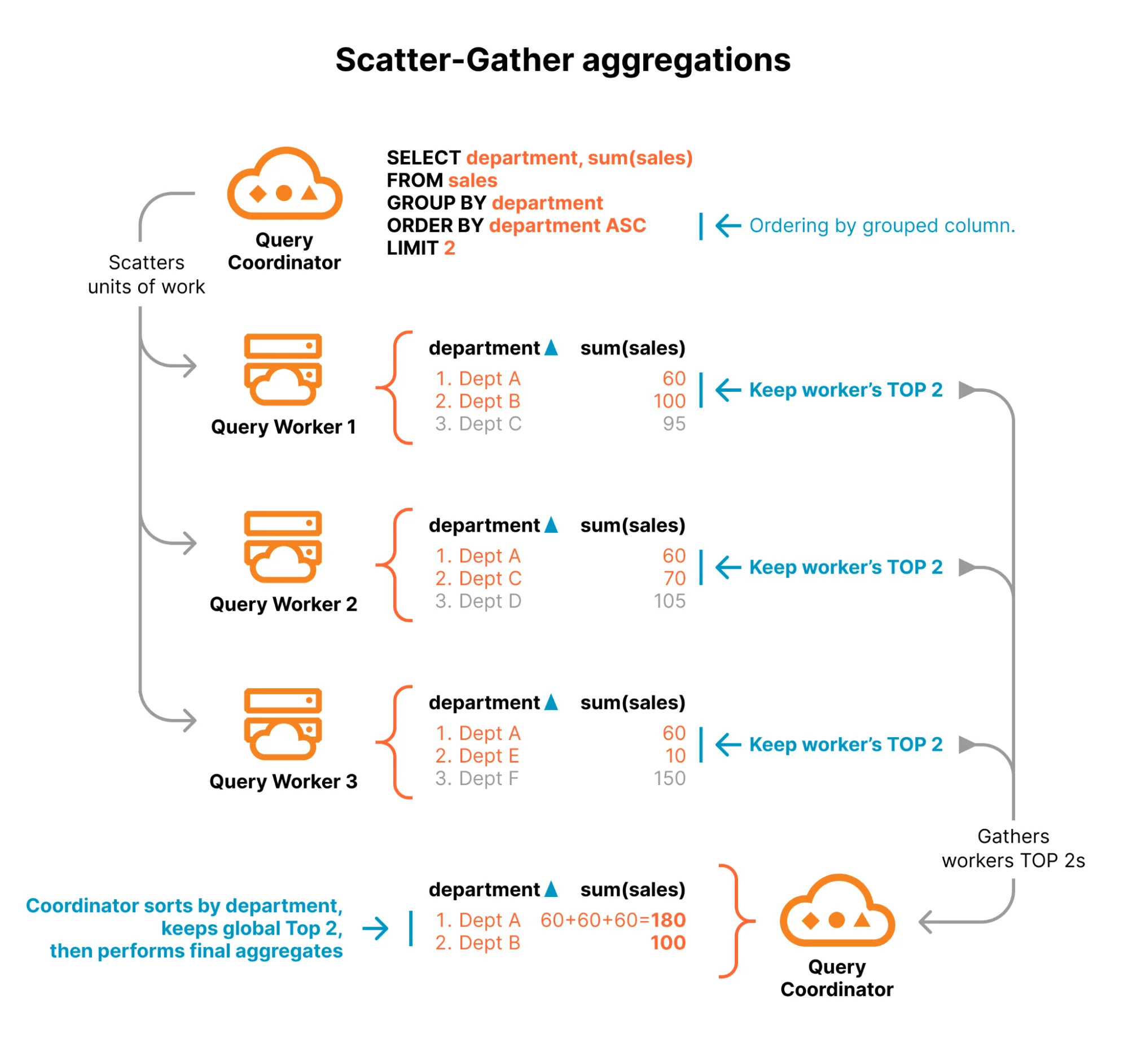
Например, предварительный агрегат для «count(*)» — это просто число, представляющее количество строк в подмножестве данных. Вычисление итогового «count(*)» сводится к сложению этих чисел. Предварительный агрегат для «avg(value)» состоит из двух чисел: «sum(value)» и «count(*)». Значение «avg(value)» затем можно вычислить, сложив все значения «sum(value)», сложив все значения «count(*)» и, наконец, разделив одно число на другое.
После того как рабочие узлы завершат вычисление предварительных агрегатов, они передают результаты узлу-координатору. Координатор собирает все результаты, вычисляет окончательные значения агрегатных функций из предварительных агрегатов и возвращает результат пользователю.
Перемешивание (Shuffling): за пределами scatter-gather
Подход scatter-gather высокоэффективен, когда координатор может вычислить окончательный результат, объединив небольшие частичные состояния от рабочих узлов. Если вы запустите запрос типа SELECT sum(sales) FROM orders, координатор получит от каждого рабочего узла одно число и сложит их. Объем используемой координатором памяти будет незначительным независимо от объема данных в R2.
Однако этот подход становится неэффективным, когда запрос требует сортировки или фильтрации на основе результата агрегации. Рассмотрим этот запрос, который находит два отдела с наибольшим объемом продаж:
SELECT department, sum(sales)
FROM sales
GROUP BY department
ORDER BY sum(sales) DESC
LIMIT 2Для правильного определения глобальной топ-2 необходимо знать общий объем продаж для каждого отдела во всем наборе данных. Поскольку данные эффективно распределены случайным образом по базовым Parquet-файлам, продажи конкретного отдела, скорее всего, разбросаны по многим рабочим узлам. У отдела могут быть низкие продажи на каждом отдельном рабочем узле, что исключает его из любого локального списка топ-2, но при суммировании он может оказаться лидером по глобальному объему продаж.
На диаграмме ниже показано, почему подход scatter-gather не сработал бы для этого запроса. «Отдел А» — глобальный лидер по продажам, но поскольку его продажи равномерно распределены между рабочими узлами, он не попадает в некоторые локальные списки топ-2 и в итоге отбрасывается координатором.
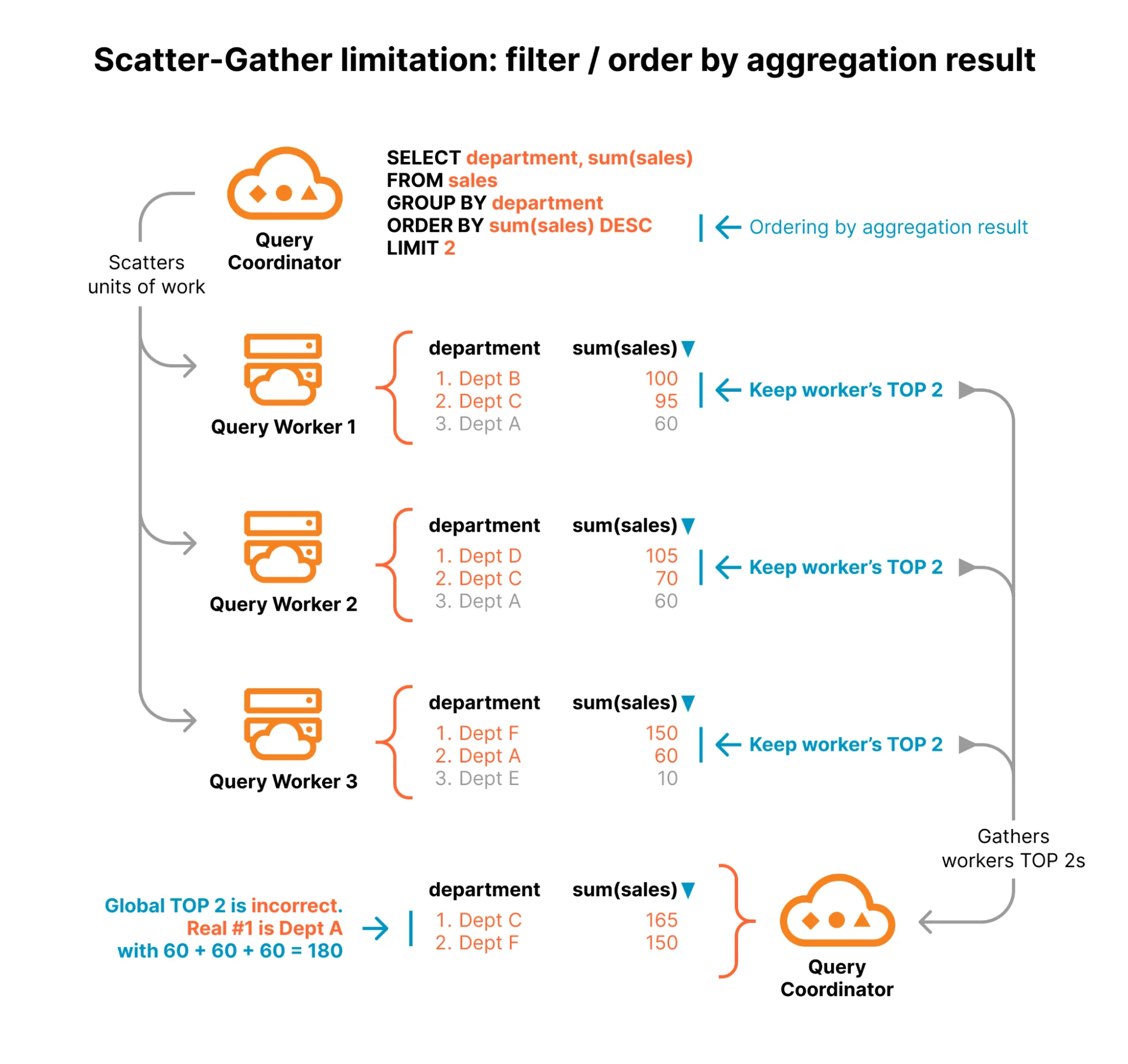
Следовательно, когда запрос упорядочивает результаты по их глобальной агрегации, координатор не может полагаться на предварительно отфильтрованные результаты от рабочих узлов. Он должен запросить общее количество для каждого отдела от каждого рабочего узла, чтобы рассчитать глобальные итоги перед сортировкой. Если группировка выполняется по столбцу с высокой кардинальностью, например IP-адресам или идентификаторам пользователей, это вынуждает координатор принимать и объединять миллионы строк, создавая узкое место по ресурсам на одном узле.
Для решения этой проблемы требуется перемешивание (shuffling) — способ колокации (совместного размещения) данных для определенных групп перед финальной агрегацией.
Перемешивание агрегированных данных
Чтобы решить проблемы, связанные со случайным распределением данных, мы вводим этап перемешивания (shuffling stage). Вместо отправки результатов координатору рабочие узлы обмениваются данными напрямую друг с другом, чтобы колоцировать строки на основе их ключа группировки.
Эта маршрутизация основана на детерминированном хеш-партиционировании. Когда рабочий узел обрабатывает строку, он хеширует столбец GROUP BY, чтобы определить рабочий узел-получатель. Поскольку этот хеш детерминирован, каждый рабочий узел в кластере независимо приходит к согласию о том, куда отправлять конкретные данные. Если "Engineering" хешируется на Рабочий узел 5, каждый рабочий узел знает, что строки с "Engineering" нужно направлять на Рабочий узел 5. Центральный реестр не требуется.
Приведенная ниже диаграмма иллюстрирует этот поток. Обратите внимание, как "Dept A" изначально находится на Рабочих узлах 1, 2 и 3. Поскольку хеш-функция сопоставляет "Dept A" с Рабочим узлом 1, все рабочие узлы направляют эти строки в одно и то же место назначения.
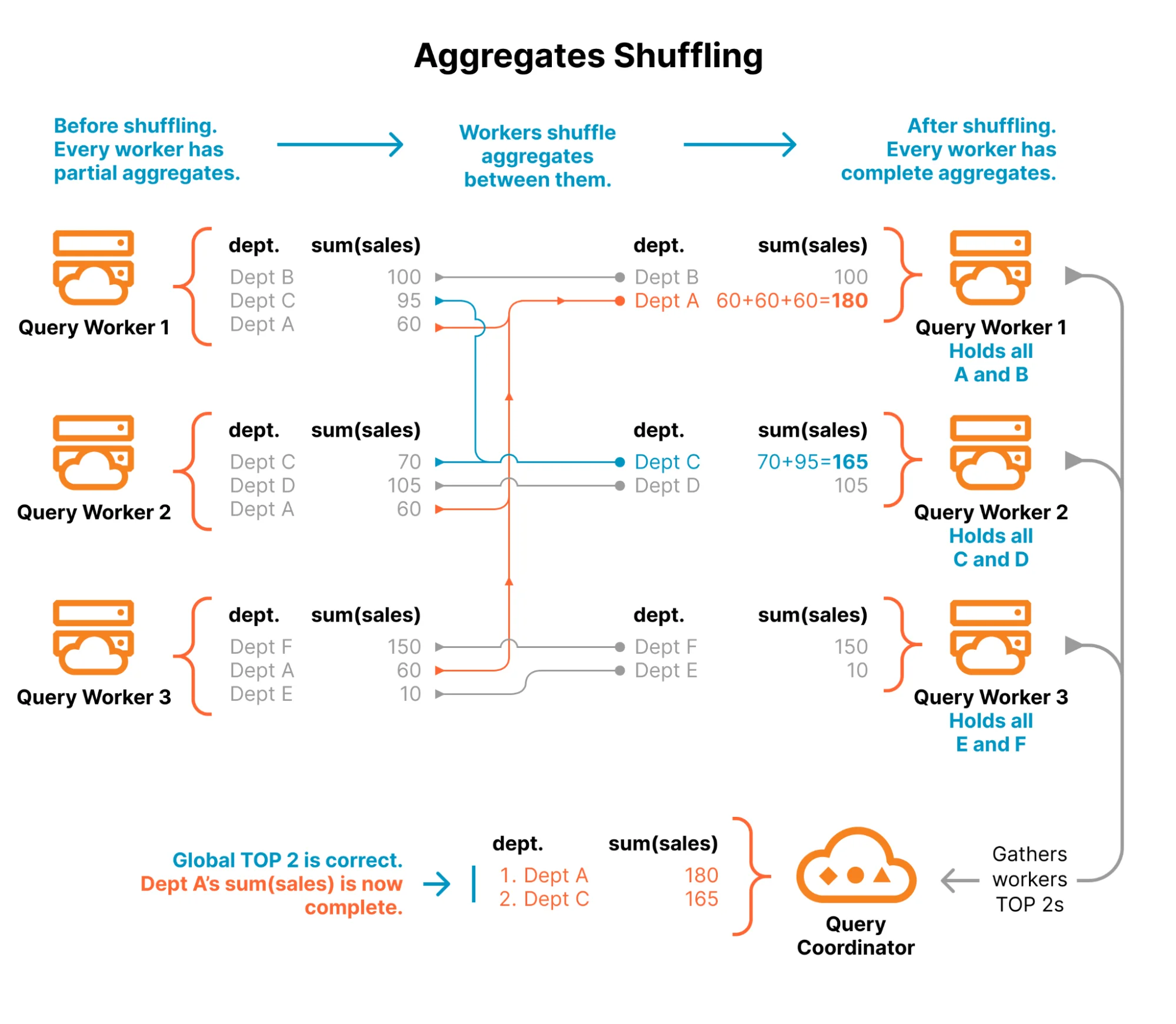
Перемешивание (shuffling) агрегатов дает правильные результаты. Однако этот обмен "все-ко-всем" создает временную зависимость. Если Рабочий узел 1 начнет вычислять окончательную сумму для "Dept A" до того, как Рабочий узел 3 завершит отправку своей части данных, результат будет неполным.
Для решения этой проблемы мы применяем строгий барьер синхронизации. Координатор отслеживает прогресс всего кластера, в то время как рабочие узлы буферизуют свои исходящие данные и отправляют их через потоки gRPC своим коллегам. Только когда каждый рабочий узел подтверждает, что он завершил обработку своих входных файлов и опустошил свои буферы перемешивания, координатор отдает команду продолжить работу. Этот барьер гарантирует, что при начале следующего этапа набор данных на каждом рабочем узле будет полным и точным.
Локализованная финализация
Как только барьер синхронизации снят, каждый рабочий узел содержит полный набор данных для назначенных ему групп. Теперь на Рабочем узле 1 есть 100% записей о продажах для "Dept A", и он может с уверенностью рассчитать окончательную сумму.
Это позволяет перенести вычислительную логику, такую как фильтрация и сортировка, на уровень рабочего узла, а не нагружать координатор. Например, если запрос включает HAVING count(*) > 5, рабочий узел может сразу после агрегации отфильтровать группы, не соответствующие этому критерию.
В конце этого этапа каждый рабочий узел создает отсортированный, финализированный поток результатов для тех групп, которыми он владеет.
Потоковое слияние
Последний элемент головоломки — это координатор. В модели scatter-gather координатор был ответственен за ресурсоемкую задачу агрегации и сортировки всего набора данных. В модели перемешивания (shuffling) его роль меняется.
Поскольку рабочие узлы уже вычислили окончательные агрегаты и отсортировали их локально, координатору необходимо выполнить только K-путевое слияние (k-way merge). Он открывает поток к каждому рабочему узлу и считывает результаты построчно. Он сравнивает текущую строку от каждого рабочего узла, выбирает "победителя" на основе порядка сортировки и добавляет его в результаты запроса, которые будут отправлены пользователю.
Такой подход особенно эффективен для запросов с LIMIT. Если пользователь запрашивает топ-10 отделов, координатор сливает потоки до тех пор, пока не найдет 10 лучших элементов, и затем немедленно прекращает обработку. Ему не нужно загружать или объединять оставшиеся миллионы строк, что позволяет масштабировать операции без чрезмерного потребления вычислительных ресурсов.
Мощный механизм для обработки огромных наборов данных
С добавлением агрегаций R2 SQL превращается из инструмента, отлично подходящего для фильтрации данных, в мощный механизм, способный обрабатывать огромные наборы данных. Это стало возможным благодаря реализации распределенных стратегий выполнения, таких как scatter-gather и перемешивание (shuffling), где мы можем перенести вычисления туда, где находятся данные, используя масштаб глобальных вычислительных и сетевых ресурсов Cloudflare.
Генерируете ли вы отчеты, отслеживаете аномалии в журналах с высокой нагрузкой или просто пытаетесь выявить тенденции в своих данных — теперь вы можете легко делать все это в рамках Developer Platform от Cloudflare без накладных расходов на управление сложной OLAP-инфраструктурой или выгрузку данных из R2.
Попробуйте сейчас
Поддержка агрегаций в R2 SQL доступна уже сегодня. Мы с нетерпением ждем, чтобы увидеть, как вы будете использовать эти новые функции с данными в R2 Data Catalog.
-
Начать работу: Ознакомьтесь с нашим руководством для примеров и синтаксиса запуска агрегационных запросов.
-
Присоединяйтесь к обсуждению: Если у вас есть вопросы, отзывы или вы хотите поделиться тем, что строите, присоединяйтесь к нам в Discord-сообществе для разработчиков Cloudflare.