18 ноября 2025 года в 11:20 UTC (все время в этом блоге указано по UTC), сеть Cloudflare начала испытывать значительные сбои в доставке основного сетевого трафика. Для пользователей Интернета, пытающихся получить доступ к сайтам наших клиентов, это проявлялось в виде страницы с ошибкой, указывающей на сбой в сети Cloudflare.
Проблема не была вызвана, прямо или косвенно, кибератакой или каким-либо вредоносным действием. Вместо этого она была спровоцирована изменением разрешений одной из наших систем баз данных, что привело к тому, что база данных вывела множество записей в «файл признаков», используемый нашей системой управления ботами. Этот файл признаков, в свою очередь, удвоился в размере. Увеличенный сверх ожиданий файл признаков был затем распространен на все машины, составляющие нашу сеть.
Программное обеспечение, работающее на этих машинах для маршрутизации трафика в нашей сети, читает этот файл признаков, чтобы поддерживать нашу систему управления ботами в актуальном состоянии относительно постоянно меняющихся угроз. В программном обеспечении был установлен лимит на размер файла признаков, который оказался ниже его удвоенного размера. Это привело к сбою программного обеспечения.
После того как мы изначально ошибочно предположили, что наблюдаемые симптомы вызваны DDoS-атакой гипермасштаба, мы правильно определили основную проблему и смогли остановить распространение увеличенного файла признаков и заменить его более ранней версией файла. Основной трафик в значительной степени восстановился к 14:30. В течение следующих нескольких часов мы работали над снижением повышенной нагрузки на различные части нашей сети, поскольку трафик стремительно возвращался в онлайн. По состоянию на 17:06 все системы Cloudflare функционировали в нормальном режиме.
Мы приносим извинения за воздействие на наших клиентов и на Интернет в целом. Учитывая важность Cloudflare в интернет-экосистеме, любой простой любой из наших систем неприемлем. Тот факт, что был период, когда наша сеть не могла маршрутизировать трафик, глубоко болезнен для каждого члена нашей команды. Мы знаем, что сегодня мы вас подвели.
Этот пост — это подробный рассказ о том, что именно произошло, и о том, какие системы и процессы дали сбой. Это также начало, хотя и не конец, того, что мы планируем сделать, чтобы гарантировать, что подобный простой больше не повторится.
Простой
На приведенной ниже диаграмме показан объем HTTP-статусов ошибок 5xx, отдаваемых сетью Cloudflare. В норме этот показатель должен быть очень низким, и таким он был вплоть до начала простоя.
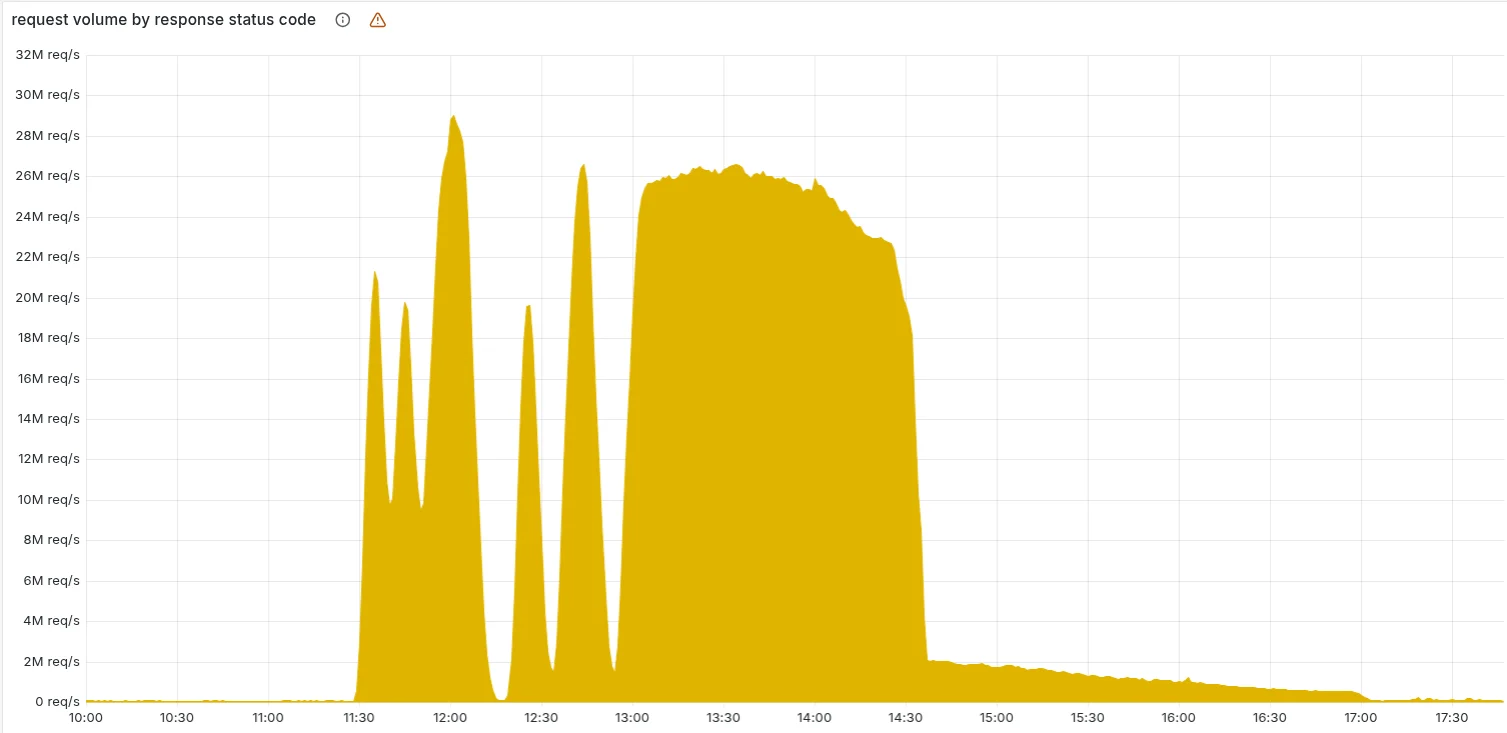
Объем до 11:20 — это ожидаемый базовый уровень ошибок 5xx, наблюдаемых в нашей сети. Всплеск и последующие колебания показывают, как наша система выходит из строя из-за загрузки неправильного файла признаков. Примечательно, что затем наша система на какое-то время восстанавливалась. Это было очень необычное поведение для внутренней ошибки.
Объяснение заключалось в том, что файл генерировался каждые пять минут запросом, выполняемым в кластере баз данных ClickHouse, который постепенно обновлялся для улучшения управления разрешениями. Плохие данные генерировались только в том случае, если запрос выполнялся на части кластера, которая была обновлена. В результате каждые пять минут существовала вероятность генерации либо хорошего, либо плохого набора конфигурационных файлов и их быстрого распространения по сети.
Эти колебания затрудняли понимание происходящего, поскольку вся система то восстанавливалась, то снова выходила из строя, поскольку по нашей сети распространялись то хорошие, то плохие конфигурационные файлы. Изначально это привело нас к мысли, что причиной может быть атака. В конце концов, каждый узел ClickHouse генерировал плохой конфигурационный файл, и колебания стабилизировались в состоянии сбоя.
Ошибки продолжались до тех пор, пока не была выявлена и устранена основная проблема, начиная с 14:30. Мы решили проблему, остановив генерацию и распространение плохого файла признаков и вручную вставив заведомо исправный файл в очередь распространения файлов признаков. А затем принудительно перезапустили наш основной прокси.
Оставшийся длинный «хвост» на диаграмме выше — это наша команда перезапускает оставшиеся службы, которые перешли в нерабочее состояние, при этом объем ошибок 5xx вернулся к норме в 17:06.
Затронуты были следующие сервисы:
|
Сервис / Продукт |
Описание воздействия |
|---|---|
|
Основные сервисы CDN и безопасности |
HTTP-статусы 5xx. Скриншот в начале этого поста показывает типичную страницу с ошибкой, отображаемую конечным пользователям. |
|
Turnstile |
Turnstile не загружался. |
|
Workers KV |
Workers KV возвращал значительно повышенный уровень HTTP-ошибок 5xx, поскольку запросы к «фронтенд»-шлюзу KV не выполнялись из-за сбоя основного прокси. |
|
Панель управления (Dashboard) |
Хотя панель управления в основном была работоспособна, большинство пользователей не могли войти в систему из-за недоступности Turnstile на странице входа. |
|
Email Security |
Хотя обработка и доставка электронной почты не пострадали, мы наблюдали временную потерю доступа к источнику репутации IP-адресов, что снизило точность обнаружения спама и предотвратило срабатывание некоторых определений возраста новых доменов, при этом критического воздействия на клиентов не наблюдалось. Мы также видели сбои в некоторых действиях Auto Move; все затронутые сообщения были проверены и исправлены. |
|
Access |
Сбои аутентификации были широко распространены для большинства пользователей, начиная с начала инцидента и до момента начала отката в 13:05. Существующие сессии Access не были затронуты.
Все неудачные попытки аутентификации приводили к появлению страницы с ошибкой, что означало, что ни один из этих пользователей так и не достиг целевого приложения, пока аутентификация не работала. Успешные входы в систему в этот период корректно логировались во время этого инцидента.
Любые попытки обновления конфигурации Access в то время либо полностью проваливались, либо распространялись очень медленно. Все обновления конфигурации теперь восстановлены. |
Помимо возврата HTTP-ошибок 5xx, мы наблюдали значительное увеличение задержки ответов от нашего CDN в период воздействия. Это было связано с большим потреблением ЦП нашими системами отладки и наблюдаемости, которые автоматически дополняют неперехваченные ошибки дополнительной отладочной информацией.
Как Cloudflare обрабатывает запросы и что пошло не так сегодня
Каждый запрос к Cloudflare проходит четко определенный путь через нашу сеть. Это может быть запрос от браузера, загружающего веб-страницу, мобильного приложения, вызывающего API, или автоматизированный трафик от другого сервиса. Эти запросы сначала завершаются на нашем уровне HTTP и TLS, затем поступают в нашу основную прокси-систему (которую мы называем FL, от «Frontline») и, наконец, через Pingora, которая выполняет поиск в кеше или при необходимости получает данные с оригинала.
Ранее мы делились более подробной информацией о том, как работает основной прокси, здесь.
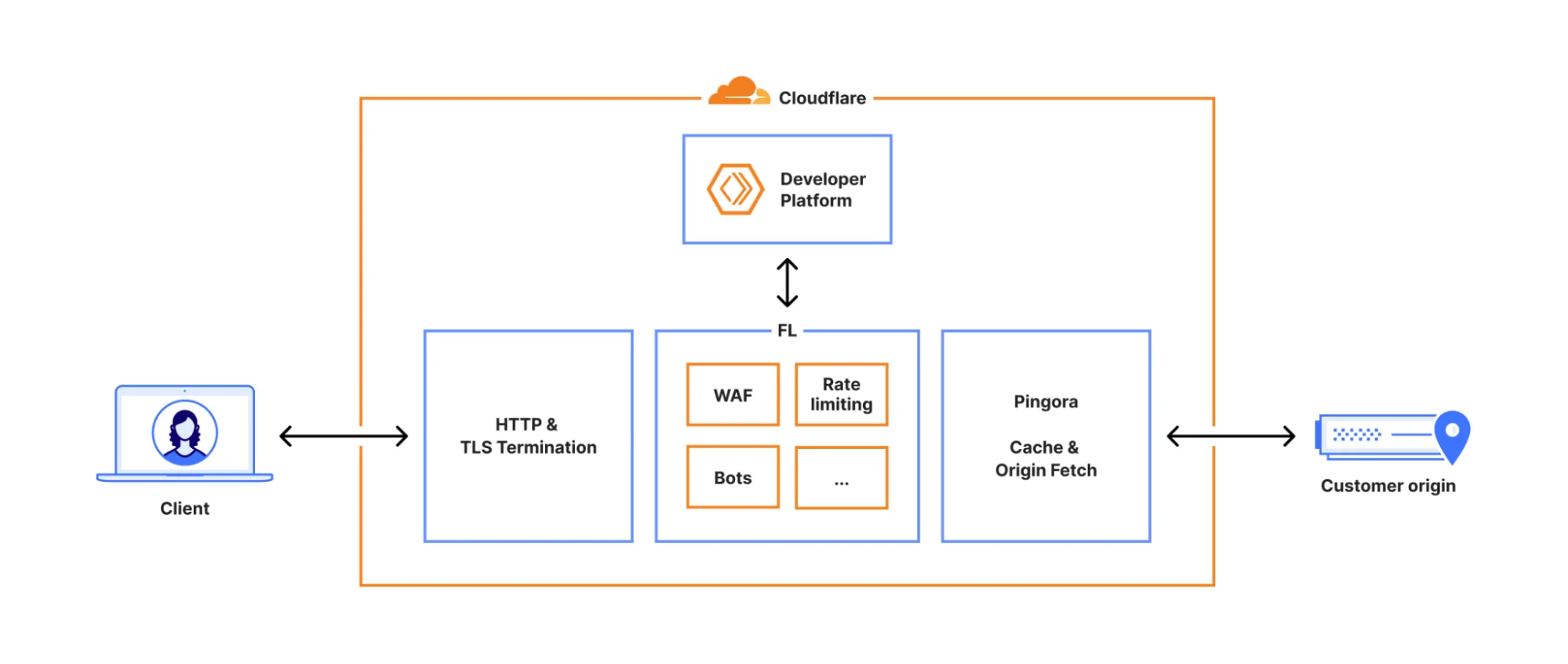
Когда запрос проходит через основной прокси, мы запускаем различные продукты безопасности и производительности, доступные в нашей сети. Прокси применяет уникальную конфигурацию и настройки каждого клиента — от применения правил WAF и защиты от DDoS до маршрутизации трафика на Платформу разработчика и R2. Это достигается за счет набора модулей, специфичных для предметной области, которые применяют конфигурацию и правила политик к трафику, проходящему через наш прокси.
Один из этих модулей, Управление ботами (Bot Management), стал источником сегодняшнего простоя.
Управление ботами от Cloudflare включает, среди прочих систем, модель машинного обучения, которую мы используем для генерации бот-скор для каждого запроса, проходящего через нашу сеть. Наши клиенты используют бот-скоры, чтобы контролировать, каким ботам разрешен доступ к их сайтам, а каким — нет.
Модель принимает на вход файл конфигурации «признаков». Признак в данном контексте — это отдельная характеристика, используемая моделью машинного обучения для прогнозирования того, был ли запрос автоматизированным или нет. Файл конфигурации признаков — это набор отдельных признаков.
Этот файл признаков обновляется каждые несколько минут и публикуется во всей нашей сети, что позволяет нам реагировать на изменения в потоках трафика в Интернете. Это позволяет нам реагировать на новые типы ботов и новые бот-атаки. Поэтому критически важно, чтобы он развертывался часто и быстро, поскольку злоумышленники быстро меняют тактику.
Изменение в поведении нашего базового запроса ClickHouse (объяснено ниже), который генерирует этот файл, привело к появлению в нем большого количества дублирующихся строк «признаков». Это изменило размер ранее фиксированного файла конфигурации признаков, что вызвало ошибку в модуле ботов.
В результате основная прокси-система, обрабатывающая трафик для наших клиентов, возвращала HTTP-коды ошибок 5xx для любого трафика, зависящего от модуля ботов. Это также затронуло Workers KV и Access, которые полагаются на основной прокси.
Независимо от этого инцидента, мы уже проводили и продолжаем проводить миграцию трафика наших клиентов на новую версию нашего прокси-сервиса, внутренне известную как FL2. Обе версии были затронуты проблемой, хотя наблюдаемое воздействие было разным.
Клиенты, развернутые на новом прокси-движке FL2, наблюдали ошибки HTTP 5xx. Клиенты на нашем старом прокси-движке, известном как FL, не видели ошибок, но оценки ботов генерировались некорректно, в результате чего весь трафик получал оценку бота, равную нулю. Клиенты, у которых были развернуты правила для блокировки ботов, могли наблюдать большое количество ложных срабатываний. Клиенты, которые не использовали нашу оценку ботов в своих правилах, не заметили никакого влияния.
Нас сбило с толку и заставило поверить, что это могла быть атака, еще один очевидный симптом, который мы наблюдали: страница статуса Cloudflare перестала работать. Страница статуса полностью размещена вне инфраструктуры Cloudflare и не зависит от нее. Хотя это оказалось совпадением, это привело к тому, что часть команды, занимающейся диагностикой проблемы, предположила, что злоумышленник может целить как в наши системы, так и в нашу страницу статуса. Посетители страницы статуса в то время видели сообщение об ошибке:

Во внутреннем чате инцидента мы опасались, что это может быть продолжением недавней череды высокообъемных DDoS-атак Aisuru:
Изменение поведения запроса
Как я упомянул выше, изменение в поведении базового запроса привело к тому, что файл признаков содержал большое количество дублирующихся строк. Используемая система базы данных работает на программном обеспечении ClickHouse.
Для контекста полезно знать, как работают распределенные запросы в ClickHouse. Кластер ClickHouse состоит из многих шардов. Чтобы запросить данные со всех шардов, у нас есть так называемые распределенные таблицы (работающие на движке таблиц Distributed) в базе данных с именем default. Движок Distributed запрашивает базовые таблицы в базе данных r0. Базовые таблицы — это то, где данные хранятся на каждом шарде кластера ClickHouse.
Запросы к распределенным таблицам выполняются через общую системную учетную запись. В рамках усилий по улучшению безопасности и надежности наших распределенных запросов ведется работа над тем, чтобы они выполнялись под учетными записями первоначального пользователя.
До сегодняшнего дня пользователи ClickHouse видели только таблицы в базе данных default при запросе метаданных таблиц из системных таблиц ClickHouse, таких как system.tables или system.columns.
Поскольку пользователи уже имеют неявный доступ к базовым таблицам в r0, мы внесли изменение в 11:05, чтобы сделать этот доступ явным, чтобы пользователи также могли видеть метаданные этих таблиц. Гарантируя, что все распределенные подзапросы могут выполняться под первоначальным пользователем, лимиты запросов и права доступа можно оценивать более детально, избегая влияния одного плохого подзапроса от пользователя на других.
Описанное выше изменение привело к тому, что все пользователи получили доступ к точным метаданным таблиц, к которым у них есть доступ. К сожалению, в прошлом были сделаны предположения, что список столбцов, возвращаемый запросом наподобие этого, будет включать только базу данных "default":
SELECT
name,
type
FROM system.columns
WHERE
table = 'http_requests_features'
order by name;
Обратите внимание, что запрос не фильтрует по имени базы данных. Поскольку мы постепенно внедряли явные права для пользователей данного кластера ClickHouse, после изменения в 11:05 приведенный выше запрос начал возвращать «дубликаты» столбцов, потому что они были для базовых таблиц, хранящихся в базе данных r0.
К сожалению, именно такой тип запроса выполнялся логикой генерации файла признаков Управления ботами для построения каждого входного «признака» для файла, упомянутого в начале этого раздела.
Вышеуказанный запрос возвращал таблицу столбцов, подобную показанной (упрощенный пример):

Однако, как часть дополнительных разрешений, предоставленных пользователю, ответ теперь содержал все метаданные схемы r0, что фактически более чем вдвое увеличило количество строк в ответе и в конечном итоге повлияло на количество строк (т.е. признаков) в итоговом файле.
Предварительное выделение памяти
Каждый модуль, работающий в нашей прокси-службе, имеет ряд ограничений, чтобы избежать неограниченного потребления памяти и предварительно выделить память в качестве оптимизации производительности. В данном конкретном случае система Управления ботами имеет ограничение на количество функций машинного обучения, которые могут использоваться во время выполнения. В настоящее время этот лимит установлен на 200, что значительно выше нашего текущего использования ~60 функций. Опять же, лимит существует потому, что по соображениям производительности мы предварительно выделяем память для функций.
Когда плохой файл с более чем 200 функциями был распространен на наши серверы, этот лимит был достигнут — что привело к панике системы. Код FL2 на Rust, который выполняет проверку и стал источником необработанной ошибки, показан ниже:
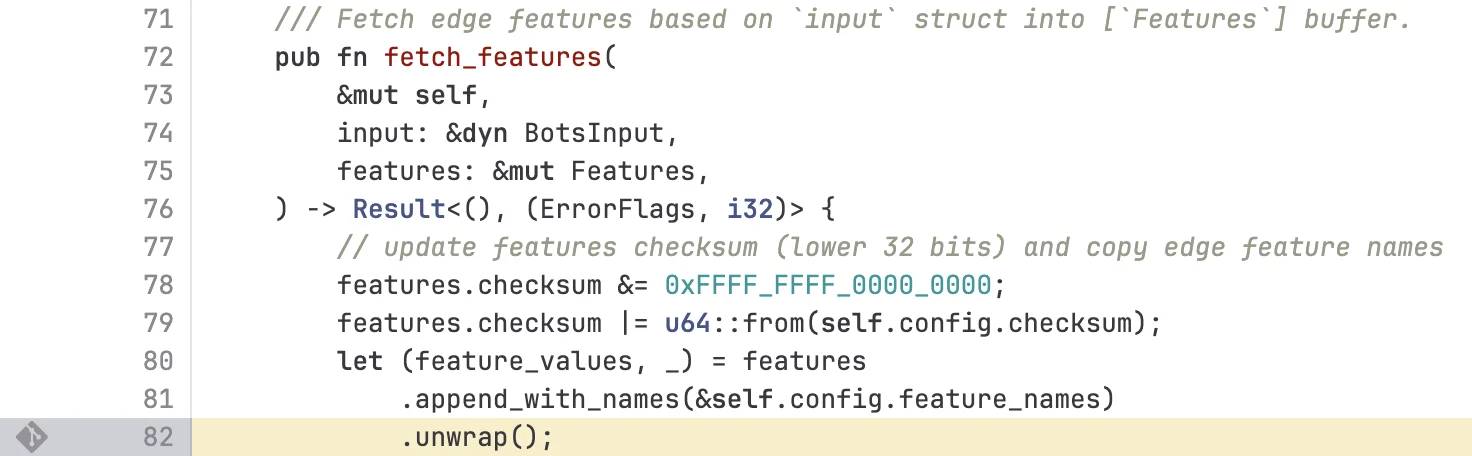
Это привело к следующей панике, которая, в свою очередь, привела к ошибке 5xx:
thread fl2_worker_thread panicked: called Result::unwrap() on an Err value
Другое влияние во время инцидента
Другие системы, зависящие от нашего основного прокси, пострадали во время инцидента. Это включало Workers KV и Cloudflare Access. Команде удалось снизить влияние на эти системы в 13:04, когда для Workers KV был внедрен патч, обходящий основной прокси. Впоследствии все зависимые системы, полагающиеся на Workers KV (такие как сам Access), наблюдали сниженный уровень ошибок.
Панель управления Cloudflare также пострадала из-за того, что как Workers KV используется внутри, так и Cloudflare Turnstile развернут как часть нашего процесса входа в систему.
Turnstile пострадал от этого сбоя, в результате чего клиенты, у которых не было активной сессии в панели управления, не могли войти в систему. Это проявилось как снижение доступности в два временных периода: с 11:30 до 13:10 и между 14:40 и 15:30, как видно на графике ниже.
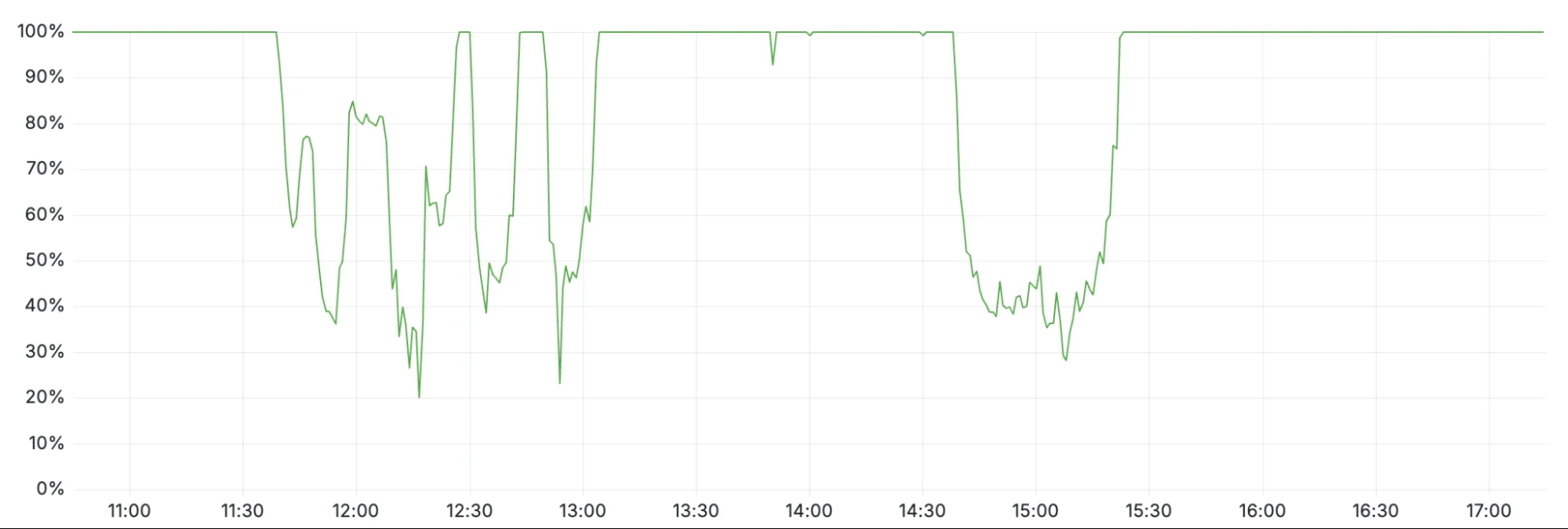
Первый период, с 11:30 до 13:10, был вызван влиянием на Workers KV, от которого зависят некоторые функции панели управления и управляющей плоскости. Это было восстановлено в 13:10, когда Workers KV обошел основную прокси-систему. Второй период влияния на панель управления произошел после восстановления данных конфигурации функций. Накопившиеся попытки входа в систему начали перегружать панель управления. Эта накопленная нагрузка в сочетании с повторными попытками привела к повышенной задержке, снизив доступность панели управления. Масштабирование параллелизма управляющей плоскости восстановило доступность примерно в 15:30.
Меры по устранению и дальнейшие шаги
Теперь, когда наши системы снова в сети и функционируют нормально, работа уже началась над тем, как мы защитим их от подобных сбоев в будущем. В частности, мы:
-
Повышаем устойчивость приема файлов конфигурации, сгенерированных Cloudflare, так же, как мы это делаем для ввода, сгенерированного пользователем
-
Включаем больше глобальных аварийных выключателей для функций
-
Устраняем возможность того, что дампы памяти или другие отчеты об ошибках перегружают системные ресурсы
-
Пересматриваем режимы отказа для условий ошибок во всех основных прокси-модулях
Сегодняшний день стал худшим сбоем Cloudflare с 2019 года. У нас были сбои, которые делали нашу панель управления недоступной. Некоторые вызывали временную недоступность новых функций. Но за последние 6+ лет у нас не было другого сбоя, который привел бы к остановке большей части основного трафика в нашей сети.
Подобный сегодняшнему сбой неприемлем. Мы спроектировали наши системы так, чтобы они были высокоустойчивы к сбоям, чтобы гарантировать, что трафик всегда будет продолжать проходить. Когда в прошлом у нас происходили сбои, это всегда приводило к созданию новых, более устойчивых систем.
После того как мы вернули наши системы в онлайн и они функционируют нормально, работа уже началась над тем, как мы защитим их от подобных сбоев в будущем. От имени всей команды Cloudflare я хочу извиниться за проблемы, которые мы сегодня доставили Интернету.
|
Время (UTC) |
Статус |
Описание |
|---|---|---|
|
11:05 |
Нормально. |
Развернуто изменение контроля доступа к базе данных. |
|
11:28 |
Начало воздействия. |
Развертывание достигает клиентских сред, первые ошибки наблюдаются в HTTP-трафике клиентов. |
|
11:32-13:05 |
Команда расследовала повышенный уровень трафика и ошибок в службе Workers KV.
|
Первоначальным симптомом казалось снижение скорости ответа Workers KV, вызывающее влияние на другие службы Cloudflare.
Предпринимались меры по смягчению, такие как манипуляция трафиком и ограничение учетных записей, чтобы вернуть службу Workers KV к нормальному уровню работы.
Первый автоматизированный тест обнаружил проблему в 11:31, а ручное расследование началось в 11:32. Звонок по инциденту был создан в 11:35. |
|
13:05 |
Внедрен обход Workers KV и Cloudflare Access — воздействие снижено. |
В ходе расследования мы использовали внутренние системные обходы для Workers KV и Cloudflare Access, чтобы они откатились к предыдущей версии нашего основного прокси. Хотя проблема также присутствовала в предыдущих версиях нашего прокси, влияние было меньше, как описано ниже. |
|
13:37 |
Работа сосредоточена на откате файла конфигурации управления ботами к последней известной хорошей версии. |
Мы были уверены, что файл конфигурации управления ботами стал триггером инцидента. Команды работали над способами восстановления службы по нескольким направлениям, причем самым быстрым направлением было восстановление предыдущей версии файла. |
|
14:24 |
Прекращено создание и распространение новых файлов конфигурации управления ботами. |
Мы определили, что модуль управления ботами был источником ошибок 500 и это было вызвано плохим файлом конфигурации. Мы остановили автоматическое развертывание новых файлов конфигурации управления ботами. |
|
14:24 |
Тестирование нового файла завершено. |
Мы наблюдали успешное восстановление с использованием старой версии файла конфигурации и затем сосредоточились на ускорении глобального исправления. |
|
14:30 |
Основное воздействие устранено. Затронутые зависимые службы начали наблюдать снижение ошибок. |
Правильный файл конфигурации управления ботами был развернут глобально, и большинство служб начало работать корректно. |
|
17:06 |
Все службы восстановлены. Воздействие прекращено. |
Все зависимые службы перезапущены, и все операции полностью восстановлены. |