Cloudflare Stream обожает видео. Но мы понимаем, что не каждому рабочему процессу нужна полная картина, а популярность подкастов подчеркивает, насколько убедительным может быть автономное аудио. Для разработчиков обработка видео только для доступа к аудио — это медленно, дорого и сложно.
Что делает видео таким дорогим? Видеофайл — это плотный набор высококачественных изображений, соединенных вместе во времени. Как таковой, это не просто «один файл» — это контейнер многомерных данных, таких как кадры в секунду, разрешение, кодеки. Анализ видео означает перемещение по времени, разрешению и частоте кадров.
Зачем нужно извлечение аудио
Для сравнения, аудиофайл гораздо проще. Если аудиофайл состоит только из одного канала, он определяется как одиночная звуковая волна. Технические характеристики этой волны определяются частотой дискретизации (количество аудиосэмплов, взятых в секунду) и разрядностью (точностью каждого сэмпла).
С ростом вычислительно интенсивных AI-пайплайнов многие наши клиенты хотят выполнять последующие рабочие процессы, требующие только анализа аудио. Например:
-
Усиление AI и машинного обучения: В дополнение к переводу и транскрипции, вы можете подавать аудио в модели преобразования речи в текст для распознавания или анализа речи, или для создания AI-сводок.
-
Улучшение модерации контента: Анализируйте аудио в ваших видео, чтобы убедиться, что контент безопасен и соответствует требованиям.
Использование видеоданных в таких случаях дорого и не нужно.
Именно поэтому мы представляем извлечение аудио. С помощью этой функции, всего одним вызовом API или кликом в панели управления, вы теперь можете извлекать облегченную аудиодорожку M4A из любого видео.
Мы представляем два гибких метода извлечения аудио из ваших видео.
1. Извлечение аудио на лету через Media Transformations
Media Transformations идеально подходит для обработки и преобразования коротких видео, таких как клипы для соцсетей, которые вы храните где угодно. Это работает путем прямой загрузки вашего медиа из его источника, оптимизации на нашем крае сети и эффективной доставки.
Мы расширили этот рабочий процесс, включив в него аудио. Просто добавив mode=audio к URL преобразования, вы теперь можете извлекать аудио на лету из видеофайла, хранящегося где угодно.
После того как Media Transformations включена для вашего домена, вы можете извлекать аудио из любого исходного видео. Вы даже можете вырезать определенные участки, указав time и duration.
Например:
https://example.com/cdn-cgi/media/mode=audio,time=5s,duration=10s/<SOURCE-VIDEO>Приведенный выше запрос генерирует 10-секундный аудиоклип M4A из исходного видео, начиная с 5-й секунды. Вы можете узнать больше о настройке и других опциях в документации по Media Transformations.
2. Загрузки аудио
Теперь вы можете загружать аудиодорожку напрямую для любого контента, которым вы управляете в Stream. Наряду с возможностью генерировать загружаемый MP4 для офлайн-просмотра, вы теперь также можете создавать и хранить постоянный аудиофайл M4A.
Демо Workers AI
Здесь вы можете увидеть пример кода, демонстрирующий, как использовать Media Transformations с одним из собственных продуктов Cloudflare — Workers AI. Следующий код создает двухэтапный процесс: сначала транскрибирует аудио видео на английский, затем переводит его на испанский.
export default {
async fetch(request, env, ctx) {
// 1. Используем Media Transformations для загрузки только аудиодорожки
const res = await fetch( "https://blog.cloudflare.com/cdn-cgi/media/mode=audio/https://pub-d9fcbc1abcd244c1821f38b99017347f.r2.dev/announcing-audio-mode.mp4" );
const blob = await res.arrayBuffer();
// 2. Транскрибируем аудио в текст с помощью Whisper
const transcript_response = await env.AI.run(
"@cf/openai/whisper-large-v3-turbo",
{
audio: base64Encode(blob), // Модель @cf/openai/whisper-large-v3-turbo требует строку в кодировке base64
}
);
// Проверяем, успешна ли транскрипция и существует ли текст
if (!transcript_response.text) {
return Response.json({ error: "Не удалось транскрибировать аудио." }, { status: 500 });
}
// 3. Переводим транскрибированный текст с помощью модели M2M100
const translation_response = await env.AI.run(
'@cf/meta/m2m100-1.2b',
{
text: transcript_response.text,
source_lang: 'en', // Исходный язык (английский)
target_lang: 'es' // Целевой язык (испанский)
}
);
// 4. Возвращаем и исходную транскрипцию, и перевод
return Response.json({
transcription: transcript_response.text,
translation: translation_response.translated_text
});
}
};
export function base64Encode(buf) {
let string = '';
(new Uint8Array(buf)).forEach(
(byte) => { string += String.fromCharCode(byte) }
)
return btoa(string)
}После выполнения воркер возвращает чистый JSON-ответ. Ниже показан фрагмент транскрибированного и затем переведенного ответа, который вернул воркер.
Транскрипция:
{
"transcription": "I'm excited to announce that Media Transformations from Cloudflare has added audio-only mode. Now you can quickly extract and deliver just the audio from your short form video. And from there, you can transcribe it or summarize it on Worker's AI or run moderation or inference tasks easily.",
"translation": "Estoy encantado de anunciar que Media Transformations de Cloudflare ha añadido el modo solo de audio. Ahora puede extraer y entregar rápidamente sólo el audio de su vídeo de forma corta. Y desde allí, puede transcribirlo o resumirlo en la IA de Worker o ejecutar tareas de moderación o inferencia fácilmente."
}Технические детали
Как летний стажер в команде Stream, я работал над выпуском этой давно запрашиваемой функции. Моим первым шагом было понять сложную архитектуру медиа-пайплайнов Stream.
Когда видео обрабатывается Stream, оно может следовать по одному из двух путей. Первый — это наш пайплайн видео по запросу (VOD), который обрабатывает видео, загруженные напрямую в Stream. Он генерирует и хранит набор закодированных сегментов видео для адаптивного потокового вещания, которые можно транслировать через HLS/DASH. Другой путь — это наш пайплайн кодирования на лету (или OTFE), который управляет сервисами Stream Live и Media Transformations. Вместо предварительной обработки и хранения файлов, OTFE загружает медиа с собственного сайта клиента и выполняет преобразования на краю сети.
Мой проект включал расширение обоих этих пайплайнов для поддержки извлечения аудио.
Пайплайн OTFE
Пайплайн OTFE предназначен для операций в реальном времени. Существующий поток был разработан для визуальных задач. Когда клиент с включенными Media Transformations делает запрос на своем собственном сайте, он маршрутизируется на наши edge-серверы, которые выступают в качестве точки входа. Затем запрос проверяется, и в соответствии с запросом пользователя OTFE загружал видео и генерировал версию с измененным размером или статичный кадр-миниатюру.
Чтобы поддержать извлечение только аудио, я достроил наш существующий рабочий процесс, добавив новый режим. Это включало:
-
Расширение логики валидации: Specifically для аудио, crucial шагом валидации была проверка, что исходное видео содержит аудиодорожку, перед попыткой извлечения. Это было в дополнение к существующим шагам валидации, которые гарантируют корректное форматирование запрашиваемого URL.
-
Создание нового обработчика преобразований: Это было ядром моего проекта. Я создал новый обработчик в платформе OTFE, который специально отбрасывает визуальные дорожки, чтобы доставить высококачественный M4A файл.
Пайплайн VOD
Аналогично моей работе над OTFE, этот проект включал расширение нашего текущего рабочего процесса загрузок MP4 до загрузок только аудио в формате M4A. Это представило серию интересных технических решений.
Типичный поток создания загрузки видео начинается с POST-запроса к нашему основному API-слою, который обрабатывает аутентификацию и валидацию и создает соответствующую запись в базе данных. Затем это ставит задание в нашу асинхронную очередь, где воркеры выполняют задачу обработки. Чтобы включить аудиозагрузки для VOD, я ввел новые, тип-специфичные API-эндпоинты (POST /downloads/{type}), сохранив при этом legacy маршрут POST /downloads как алиас для создания загрузок типа по умолчанию (видео). Это обеспечило полную обратную совместимость.
Основная работа по созданию загрузки выполняется нашей асинхронной очередью. Это включало:
-
Добавление логики в потребитель для обнаружения нового типа аудиозагрузки
-
Использование шаблона ffmpeg, который мы определяем в нашем API-слое, для корректного кодирования аудиопотока в высококачественный M4A контейнер
Расширяя каждый компонент этого конвейера — от API-маршрутов до команд обработки медиа — я смог реализовать новую, долгожданную функцию, которая открывает нашим клиентам возможности для аудио-ориентированных рабочих процессов!
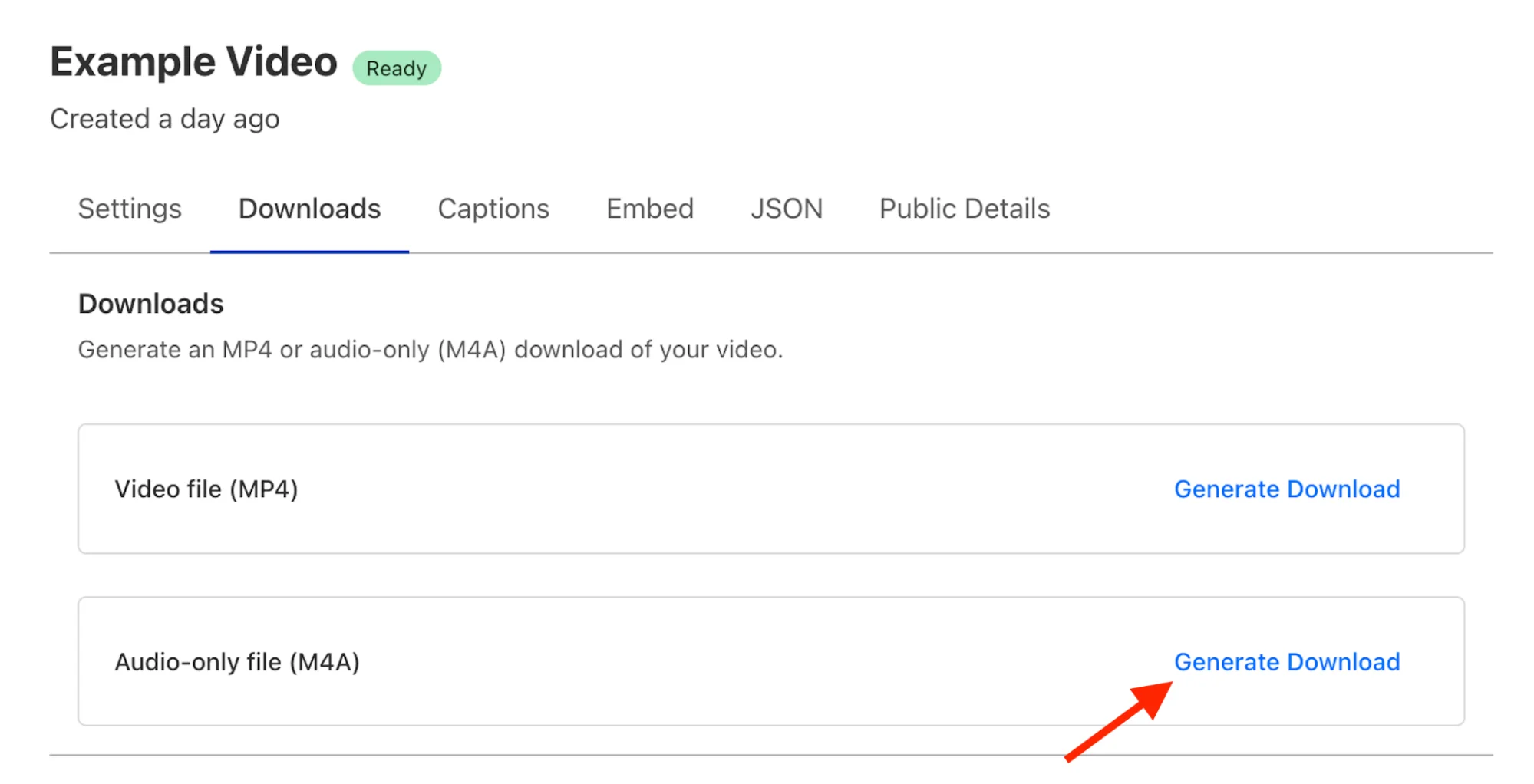
Скриншоты панели управления
Мы рады сообщить, что эта функция также доступна в панели управления Stream. Просто перейдите к любому из ваших видео, и вы найдете опцию для загрузки видео или только аудио.
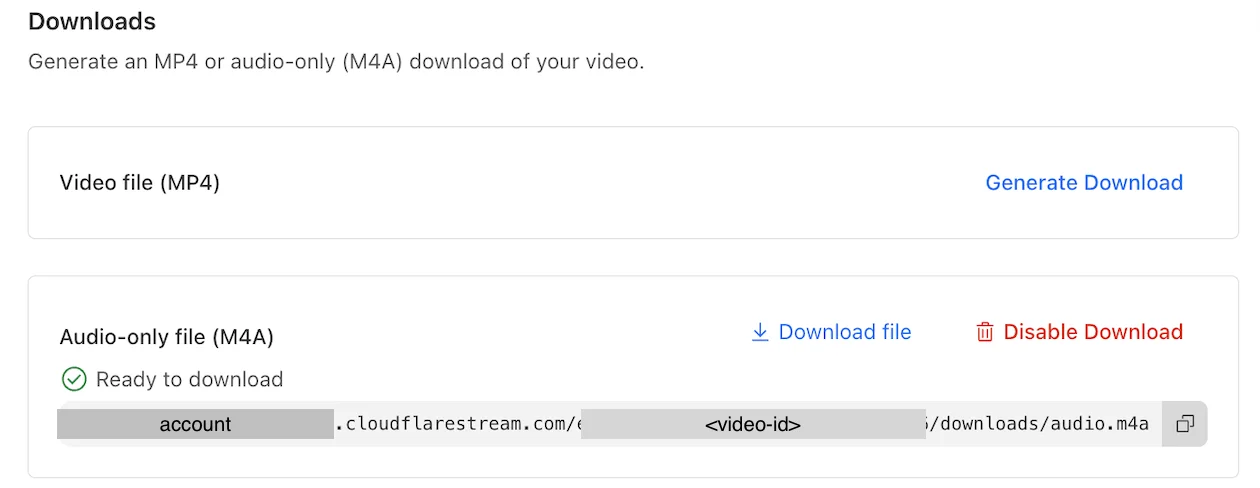
Когда загрузка будет готова, вы увидите URL-адрес файла вместе с опцией его отключения.
Подведем итоги
Этот проект решает давнюю потребность клиентов, предоставляя более простой способ работы с аудио из видео. Я искренне благодарен за весь этот путь — от понимания проблемы до поставки решения, и особенно за наставничество и руководство, которые я получил от своей команды. Мы с нетерпением ждем, чтобы увидеть, как разработчики используют эту новую возможность для создания более эффективных и интересных приложений на Cloudflare Stream.