For many of us, our first experiences with AI agents have been through typing into a chat box. And for those of us using agents day to day, we have likely gotten very good at writing detailed prompts or markdown files to guide them.
But some of the moments where agents would be most useful are not always text-first. You might be on a long commute, juggling a few open sessions, or just wanting to speak naturally to an agent, have it speak back, and continue the interaction.
Adding voice to an agent should not require moving that agent into a separate voice framework. Today, we are releasing an experimental voice pipeline for the Agents SDK.
With @cloudflare/voice, you can add real-time voice to the same Agent architecture you already use. Voice just becomes another way you can talk to the same Durable Object, with the same tools, persistence, and WebSocket connection model that the Agents SDK already provides.
@cloudflare/voice is an experimental package for the Agents SDK that provides:
-
withVoice(Agent)for full conversation voice agents -
withVoiceInput(Agent)for speech-to-text-only use cases, like dictation or voice search -
useVoiceAgentanduseVoiceInputhooks for React apps -
VoiceClientfor framework-agnostic clients -
Built-in Workers AI providers, so that you can get started without external API keys:
-
Continuous STT with Deepgram Flux
-
Continuous STT with Deepgram Nova 3
-
Text-to-speech with Deepgram Aura
-
This means you can now build an agent that users can talk to in real time over a single WebSocket connection, while keeping the same Agent class, Durable Object instance, and the same SQLite-backed conversation history.
Just as importantly, we want this to be bigger than one fixed default stack. The provider interfaces in @cloudflare/voice are intentionally small, and we want speech, telephony, and transport providers to build with us, so developers can mix and match the right components for their use case, instead of being locked into a single voice architecture.
Get started with voice
Here’s the minimal server-side pattern for a voice agent in the Agents SDK:
import { Agent, routeAgentRequest } from "agents";
import {
withVoice,
WorkersAIFluxSTT,
WorkersAITTS,
type VoiceTurnContext
} from "@cloudflare/voice";
const VoiceAgent = withVoice(Agent);
export class MyAgent extends VoiceAgent<Env> {
transcriber = new WorkersAIFluxSTT(this.env.AI);
tts = new WorkersAITTS(this.env.AI);
async onTurn(transcript: string, context: VoiceTurnContext) {
return `You said: ${transcript}`;
}
}
export default {
async fetch(request: Request, env: Env) {
return (
(await routeAgentRequest(request, env)) ??
new Response("Not found", { status: 404 })
);
}
} satisfies ExportedHandler<Env>;
That’s the whole server. You add a continuous transcriber, a text-to-speech provider, and implement onTurn().
On the client side, you can connect to it with a React hook:
import { useVoiceAgent } from "@cloudflare/voice/react";
function App() {
const {
status,
transcript,
interimTranscript,
startCall,
endCall,
toggleMute
} = useVoiceAgent({ agent: "my-agent" });
return (
<div>
<p>Status: {status}</p>
{interimTranscript && <p><em>{interimTranscript}</em></p>}
<ul>
{transcript.map((msg, i) => (
<li key={i}>
<strong>{msg.role}:</strong> {msg.text}
</li>
))}
</ul>
<button onClick={startCall}>Start Call</button>
<button onClick={endCall}>End Call</button>
<button onClick={toggleMute}>Mute / Unmute</button>
</div>
);
}
If you are not using React, you can use VoiceClient directly from @cloudflare/voice/client.
How the voice pipeline works
With the Agents SDK, every agent is a Durable Object — a stateful, addressable server instance with its own SQLite database, WebSocket connections, and application logic. The voice pipeline extends this model instead of replacing it.
At a high level, the flow looks like this:
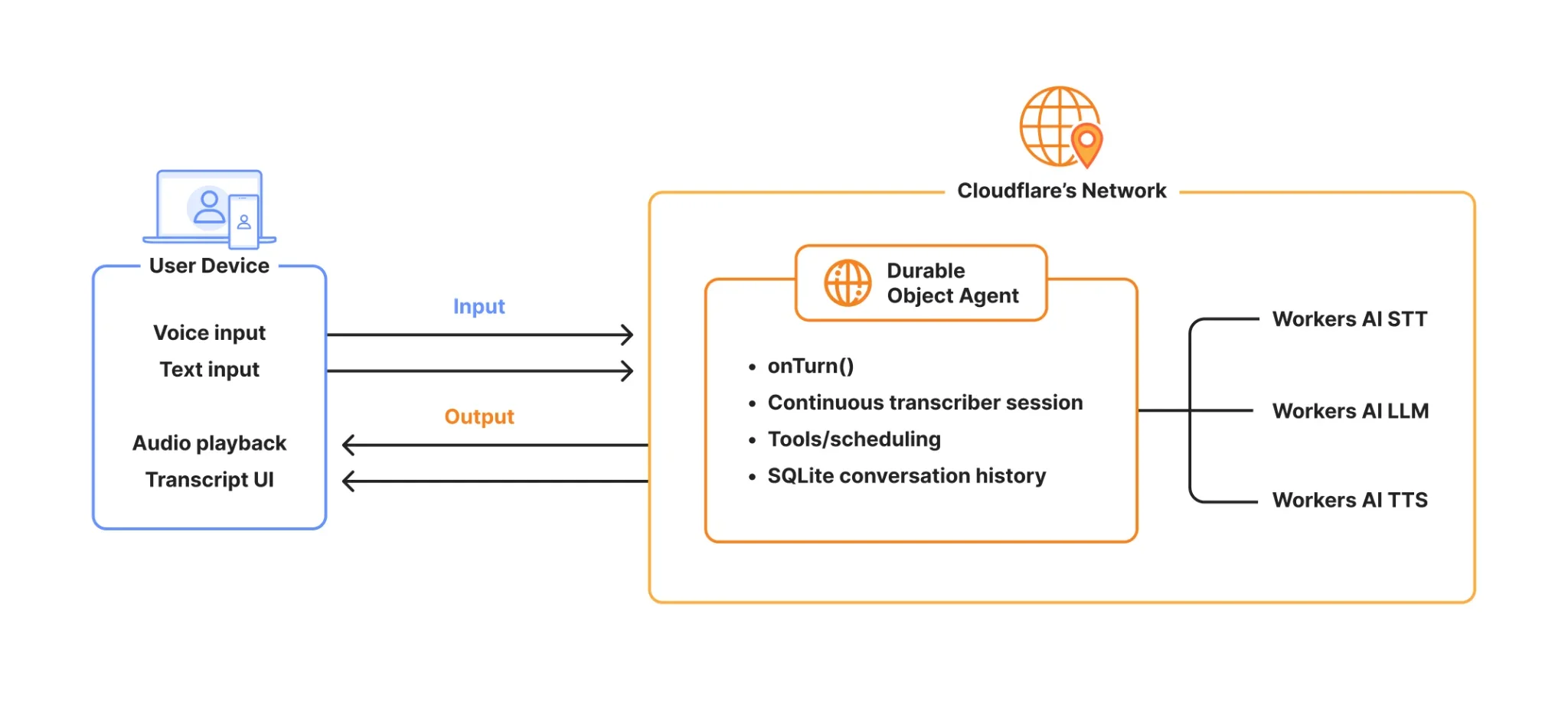
Here’s how the pipeline breaks down, step by step:
-
Audio transport: The browser captures microphone audio and streams 16 kHz mono PCM over the same WebSocket connection the agent already uses.
-
STT session setup: When the call starts, the agent creates a continuous transcriber session that lives for the duration of the call.
-
STT input: Audio streams continuously into that session.
-
STT turn detection: The speech-to-text model itself decides when the user has finished an utterance and emits a stable transcript for that turn.
-
LLM/application logic: The voice pipeline passes that transcript to your
onTurn() method. -
TTS output: Your response is synthesized to audio and sent back to the client. If
onTurn()returns a stream, the pipeline sentence-chunks it and starts sending audio as sentences are ready. -
Persistence: The user and agent messages are persisted in SQLite, so conversation history survives reconnections and deployments.
Why voice should grow with the rest of your agent
Many voice frameworks focus on the voice loop itself: audio in, transcription, model response, audio out. Those are important primitives, but there’s a lot more to an agent than just voice.
Real agents running in production will grow. They need state, scheduling, persistence, tools, workflows, telephony, and ways to keep all of that consistent across channels. As your agent grows in complexity, voice stops being a standalone feature and becomes part of a larger system.
We wanted voice in the Agents SDK to start from that assumption. Instead of building voice as a separate stack, we built it on top of the same Durable Object-based agent platform, so you can pull in the rest of the primitives you need without re-architecting the application later.
Voice and text share the same state
A user might start by typing, switch to voice, and go back to text. With Agents SDK, these are all just different inputs to the same agent. The same conversation history lives in SQLite, and the same tools are available. This gives you both a cleaner mental model and a much simpler application architecture to reason about.
Lower latency comes from...
a shorter network path
Voice experiences feel good or bad very quickly. Once a user stops speaking, the system needs to transcribe, think, and start speaking back fast enough to feel conversational.
A lot of voice latency is not pure model time. It’s the cost of bouncing audio and text between different services in different places. Audio needs to go to STT, transcripts go to an LLM, and responses go to a TTS model – and each handoff adds network overhead.
With the Agents SDK voice pipeline, the agent runs on Cloudflare’s network, and the built-in providers use Workers AI bindings. That keeps the pipeline tighter and reduces the amount of infrastructure you have to stitch together yourself.
built-in streaming
A voice agent interaction feels much more natural if it speaks the first sentence quickly (also called Time-to-First Audio). When onTurn() returns a stream, the pipeline chunks it into sentences and starts synthesis as sentences complete. That means the user can hear the beginning of the answer while the rest is still being generated.
A more realistic backend
Here is a fuller example that streams an LLM response and starts speaking it back, sentence by sentence:
import { Agent, routeAgentRequest } from "agents";
import {
withVoice,
WorkersAIFluxSTT,
WorkersAITTS,
type VoiceTurnContext
} from "@cloudflare/voice";
import { streamText } from "ai";
import { createWorkersAI } from "workers-ai-provider";
const VoiceAgent = withVoice(Agent);
export class MyAgent extends VoiceAgent<Env> {
transcriber = new WorkersAIFluxSTT(this.env.AI);
tts = new WorkersAITTS(this.env.AI);
async onTurn(transcript: string, context: VoiceTurnContext) {
const ai = createWorkersAI({ binding: this.env.AI });
const result = streamText({
model: ai("@cf/cloudflare/gpt-oss-20b"),
system: "Вы полезный голосовой помощник. Будьте кратки.",
messages: [
...context.messages.map((m) => ({
role: m.role as "user" | "assistant",
content: m.content
})),
{ role: "user" as const, content: transcript }
],
abortSignal: context.signal
});
return result.textStream;
}
}
export default {
async fetch(request: Request, env: Env) {
return (
(await routeAgentRequest(request, env)) ??
new Response("Не найдено", { status: 404 })
);
}
} satisfies ExportedHandler<Env>;
Context.messages предоставляет вам недавнюю историю разговоров из SQLite, а context.signal позволяет конвейеру прервать вызов LLM, если пользователь перебивает.
Голос как ввод: withVoiceInput
Не каждому речевому интерфейсу нужен голосовой ответ. Иногда может понадобиться диктовка, транскрипция или голосовой поиск. Для таких случаев используйте withVoiceInput
import { Agent, type Connection } from "agents";
import { withVoiceInput, WorkersAINova3STT } from "@cloudflare/voice";
const InputAgent = withVoiceInput(Agent);
export class DictationAgent extends InputAgent<Env> {
transcriber = new WorkersAINova3STT(this.env.AI);
onTranscript(text: string, _connection: Connection) {
console.log("Пользователь сказал:", text);
}
}
На стороне клиента useVoiceInput предоставляет легковесный интерфейс, сфокусированный на транскрипциях:
import { useVoiceInput } from "@cloudflare/voice/react";
const { transcript, interimTranscript, isListening, start, stop, clear } =
useVoiceInput({ agent: "DictationAgent" });
Это полезно, когда речь является методом ввода, и вам не нужен полный диалоговый цикл.
Голос и текст в одном соединении
Тот же клиент может вызвать sendText("Какая погода?"), что обходит STT и отправляет текст напрямую в onTurn(). Во время активного вызова ответ может быть озвучен и показан в виде текста. Вне вызова он может остаться только текстом.
Это дает вам по-настоящему мультимодального агента без разделения реализации на разные пути выполнения кода.
Что ещё можно построить?
Поскольку голосовой агент — это всё ещё агент, все обычные возможности Agents SDK по-прежнему применимы.
Инструменты и планирование
Вы можете поприветствовать звонящего при начале сессии:
import { Agent, type Connection } from "agents";
import { withVoice, WorkersAIFluxSTT, WorkersAITTS } from "@cloudflare/voice";
const VoiceAgent = withVoice(Agent);
export class MyAgent extends VoiceAgent<Env> {
transcriber = new WorkersAIFluxSTT(this.env.AI);
tts = new WorkersAITTS(this.env.AI);
async onTurn(transcript: string) {
return `Вы сказали: ${transcript}`;
}
async onCallStart(connection: Connection) {
await this.speak(connection, "Привет! Чем могу помочь сегодня?");
}
}
Вы можете планировать голосовые напоминания и открывать инструменты для вашей LLM, как и в любом другом агенте:
import { Agent } from "agents";
import {
withVoice,
WorkersAIFluxSTT,
WorkersAITTS,
type VoiceTurnContext
} from "@cloudflare/voice";
import { streamText, tool } from "ai";
import { createWorkersAI } from "workers-ai-provider";
import { z } from "zod";
const VoiceAgent = withVoice(Agent);
export class MyAgent extends VoiceAgent<Env> {
transcriber = new WorkersAIFluxSTT(this.env.AI);
tts = new WorkersAITTS(this.env.AI);
async speakReminder(payload: { message: string }) {
await this.speakAll(`Напоминание: ${payload.message}`);
}
async onTurn(transcript: string, context: VoiceTurnContext) {
const ai = createWorkersAI({ binding: this.env.AI });
const result = streamText({
model: ai("@cf/cloudflare/gpt-oss-20b"),
messages: [
...context.messages.map((m) => ({
role: m.role as "user" | "assistant",
content: m.content
})),
{ role: "user" as const, content: transcript }
],
tools: {
set_reminder: tool({
description: "Установить голосовое напоминание с задержкой",
inputSchema: z.object({
message: z.string(),
delay_seconds: z.number()
}),
execute: async ({ message, delay_seconds }) => {
await this.schedule(delay_seconds, "speakReminder", { message });
return { confirmed: true };
}
})
},
abortSignal: context.signal
});
return result.textStream;
}
}
Динамическое переключение моделей во время выполнения
Голосовой конвейер также позволяет динамически выбирать модель транскрипции для каждого соединения.
Например, вы можете предпочесть Flux для диалогового чередования реплик и Nova 3 для более точной диктовки. Вы можете переключаться во время выполнения, переопределив createTranscriber():
import { Agent, type Connection } from "agents";
import {
withVoice,
WorkersAIFluxSTT,
WorkersAINova3STT,
WorkersAITTS,
type Transcriber
} from "@cloudflare/voice";
export class MyAgent extends VoiceAgent<Env> {
tts = new WorkersAITTS(this.env.AI);
createTranscriber(connection: Connection): Transcriber {
const url = new URL(connection.url ?? "http://localhost");
const model = url.searchParams.get("model");
if (model === "nova-3") {
return new WorkersAINova3STT(this.env.AI);
}
return new WorkersAIFluxSTT(this.env.AI);
}
}
На стороне клиента вы можете передавать параметры запроса через хук:
const voiceAgent = useVoiceAgent({
agent: "my-voice-agent",
query: { model: "nova-3" }
});
Хуки конвейера
Вы также можете перехватывать данные между этапами:
-
afterTranscribe(transcript, connection) -
beforeSynthesize(text, connection) -
afterSynthesize(audio, text, connection)
Эти хуки полезны для фильтрации контента, нормализации текста, языковых преобразований или кастомного логирования.
Телефония и варианты транспорта
По умолчанию голосовой конвейер использует одно WebSocket-соединение как простейший путь для 1:1 голосовых агентов. Но это не единственный вариант.
Телефонные звонки через Twilio
Вы можете подключать телефонные звонки к тому же агенту, используя адаптер Twilio:
import { TwilioAdapter } from "@cloudflare/voice-twilio";
export default {
async fetch(request: Request, env: Env) {
if (new URL(request.url).pathname === "/twilio") {
return TwilioAdapter.handleRequest(request, env, "MyAgent");
}
return (
(await routeAgentRequest(request, env)) ??
new Response("Не найдено", { status: 404 })
);
}
};
Это позволяет одному и тому же агенту обрабатывать веб-голос, текстовый ввод и телефонные звонки.
Одно замечание: провайдер TTS Workers AI по умолчанию возвращает MP3, в то время как Twilio ожидает аудио mulaw 8kHz. Для продакшен-телефонии вам, возможно, захочется использовать провайдера TTS, который выводит PCM или mulaw напрямую.
WebRTC
Если вам нужен транспорт, лучше подходящий для сложных сетевых условий или рассчитанный на нескольких участников, пакет voice также включает утилиты SFU и поддерживает кастомные транспорты. Модель по умолчанию сегодня нативна для WebSocket, но мы планируем разработать больше адаптеров для подключения к нашей глобальной SFU-инфраструктуре.
Стройте вместе с нами
Голосовой конвейер по задумке не зависит от провайдера.
Под капотом каждый этап определяется небольшим интерфейсом: транскрайбер открывает непрерывную сессию и принимает аудиофреймы по мере их поступления, а провайдер TTS принимает текст и возвращает аудио. Если провайдер может потоково выводить аудио, конвейер также может это использовать.
interface Transcriber {
createSession(options?: TranscriberSessionOptions): TranscriberSession;
}
interface TranscriberSession {
feed(chunk: ArrayBuffer): void;
close(): void;
}
interface TTSProvider {
synthesize(text: string, signal?: AbortSignal): Promise<ArrayBuffer | null>;
}
Мы не хотели, чтобы поддержка голоса в Agents SDK работала только с одной фиксированной комбинацией моделей и транспортов. Мы хотели, чтобы стандартный путь был простым, но при этом чтобы по мере развития экосистемы было легко подключать других провайдеров.
Встроенные провайдеры используют Workers AI, поэтому вы можете начать работу без внешних API-ключей:
-
WorkersAIFluxSTTдля потокового STT в разговорном стиле -
WorkersAINova3STTдля потокового STT в стиле диктовки -
WorkersAITTSдля синтеза речи (TTS)
Но более масштабная цель — это совместимость. Если вы поддерживаете сервис распознавания или синтеза речи, эти интерфейсы достаточно просты для реализации без необходимости разбираться во внутренностях остальной части SDK. Если ваш STT-провайдер принимает потоковое аудио и может определять границы высказываний, он может соответствовать интерфейсу транскрайбера. Если ваш TTS-провайдер может потоково выводить аудио — ещё лучше.
Мы будем рады работать над совместимостью с:
-
STT-провайдерами, такими как AssemblyAI, Rev.ai, Speechmatics или любым сервисом с API для транскрибации в реальном времени
-
TTS-провайдерами, такими как PlayHT, LMNT, Cartesia, Coqui, Amazon Polly или Google Cloud TTS
-
адаптерами для телефонии для платформ вроде Vonage, Telnyx или Bandwidth
-
реализациями транспорта для WebRTC data channels, SFU bridges и других аудиотранспортных слоёв
Нас также интересуют совместные проекты, выходящие за рамки отдельных провайдеров:
-
бенчмаркинг задержек для комбинаций STT + LLM + TTS
-
поддержка нескольких языков и улучшение документации для неанглоязычных голосовых агентов
-
работы в области доступности, особенно касающиеся многомодальных интерфейсов и речевых нарушений
Если вы создаёте голосовую инфраструктуру и хотите увидеть интеграцию первого класса, откройте PR или свяжитесь с нами.
Попробуйте сейчас
Голосовой конвейер доступен сегодня в виде экспериментального пакета:
npm create cloudflare@latest -- --template cloudflare/agents-starter
Добавьте @cloudflare/voice, назначьте вашему агенту транскрайбер и TTS-провайдер, разверните его и начните с ним разговаривать. Также вы можете ознакомиться с справочником по API.
Если вы создадите что-то интересное, откройте issue или PR на github.com/cloudflare/agents. Голос не должен требовать отдельного стека, и мы считаем, что лучшие голосовые агенты будут построены на той же устойчивой модели приложений, что и всё остальное.
